本文档基于 researcher 阶段 Trace(包括 continue_to_running_research_team_trace.json、research_team_trace.json、reporter_trace.json、reporter_chatOpenAI_trace.json),系统分析 DeerFlow 在 research 执行阶段的架构、消息编排、工具链与调度闭环,并结合实际耗时/令牌特征提出优化建议。面向工程实现与运维调优读者。
时序图
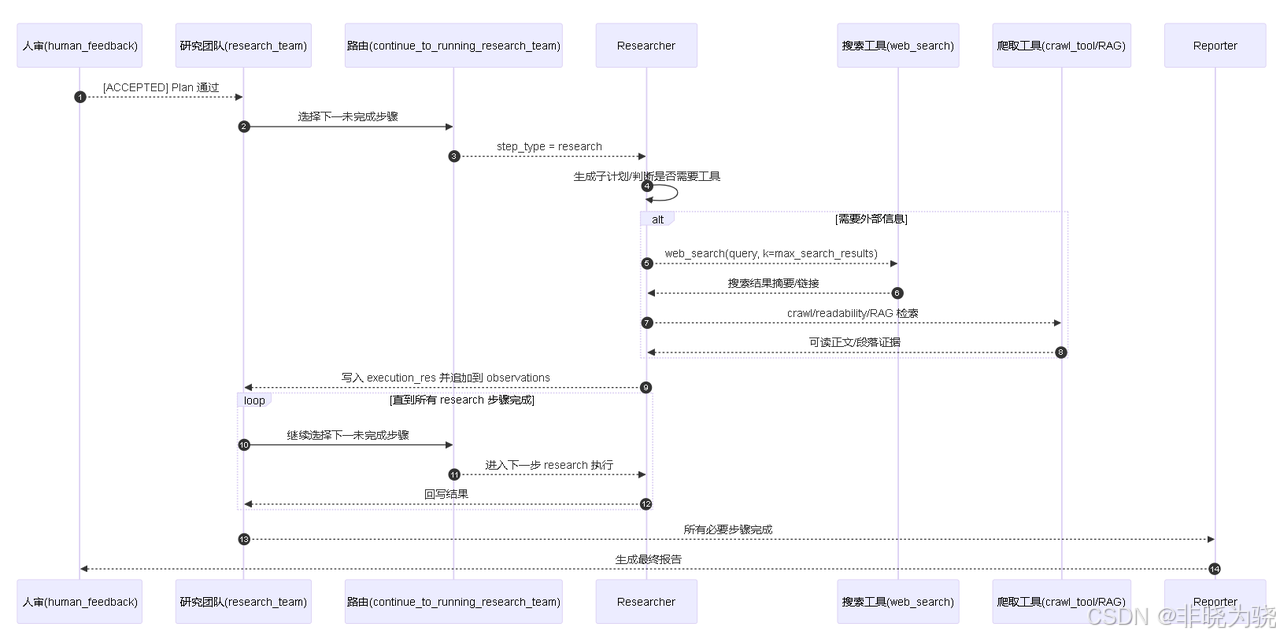
1. 研究阶段的定位与多步编排
- 在 Planner 产出
Plan且经人审[ACCEPTED]后,工作流进入research_team。系统会按current_plan.steps顺序寻找首个未完成步骤。 continue_to_running_research_team根据步骤的step_type路由:research→researcher节点;processing→coder节点。
- 你的截图表明:共 3 个 research 步骤,
researcher被多次调用;每步完成后回到research_team,再继续下一步,直至全部完成或 Planner 回收重规划。
2. 执行链路(结合 Trace)
- 高层链路:
human_feedback → research_team → continue_to_running_research_team → researcher → research_team → ... → reporter - 典型单次 researcher 内部链路:
agent → call_model → RunnableSequence → Prompt → ChatOpenAI(gpt-4.1)(思考/决策)should_continue(判定是否需要调用工具)tools → web_search(外部检索,受max_search_results约束)- 再次
agent → call_model ...(整合检索结果并生成步骤输出) - 返回
research_team,将结果写入step.execution_res
3. Researcher 的输入/输出与状态
- 输入(state 关键字段):
current_plan、observations、resources、locale。 - 组装消息要点:
- 标题:
# Research Topic+ 计划标题; - 已完成步骤:
# Completed Research Steps,用<finding>...</finding>包裹结果,便于压缩与引用; - 当前步骤:包含
Title与Description,明确采集要点; - 资源提醒(若有
resources):要求优先使用本地检索工具(RAG),并追加引用规范提醒; - 语言环境:
locale。
- 标题:
- 输出回写:将 LLM 生成文本写入当前
step.execution_res,并把该文本追加到observations,供后续步骤/Reporter 复用。
4. 工具链与扩展能力
- 默认工具:
web_search(数量由max_search_results控制)crawl_tool(可读性抽取与正文提取)
- 资源驱动检索:当
resources非空,会插入retriever_tool于工具首位,强制优先本地检索(RAG)。 - MCP(Model Context Protocol):若配置
mcp_settings,会连接多个 MCP Server 动态加载其enabled_tools并注入当前 agent;工具描述会加 "Powered by serverName" 标识,提升可观测性。 - 递归深度:
AGENT_RECURSION_LIMIT控制代理自治步数(默认 25),非法值自动回退并告警。
5. 多步循环与协同模式
research_team负责循环调度:- 找到第一个未完成步骤,按
step_type分流至researcher/coder; - 所有步骤完成或 Planner 回收后,流转
reporter。
- 找到第一个未完成步骤,按
- 职责解耦:
research仅做采集/溯源与事实性描述,不做复杂计算;processing交由coder做归并、表格对比、评分与计算。
- 观察结果滚动:已完成步骤的
execution_res作为<finding>注入下一步,形成"由浅入深"的研究链路。
6. 稳定性与容错
- 工具异常:工具层异常会被 agent 捕获并回落到 LLM 决策;建议在工具实现中对网络错误/无结果做显式提示。
- 令牌与成本:Researcher 令牌中等,Reporter 可能较大;建议 Researcher 输出"结构化要点 + 引用",降低 Reporter 重复生成成本。
- 规划不充分:若
description过泛易导致"泛搜",建议 Planner 明确信息源与量化口径。
7. 性能与成本优化(结合本次 Trace)
- 控制检索开销:
- 合理设置
max_search_results(本次 web_search ≈ 7--24s/次); - 可启用
enable_background_investigation进行首轮暖场,减少 Researcher 探索轮次。
- 合理设置
- 降低 Reporter 负载:
- 让 Researcher 输出"要点+引用+最小示例",Reporter 侧强调"表格优先 + 引用集中"。
- 工具缓存与去重:
- 对相同 URL 的
crawl_tool结果缓存; - 查询语句去重,避免重复搜索。
- 对相同 URL 的
- 递归限制:
- 简单任务时将
AGENT_RECURSION_LIMIT设置为 8--12,缩短尾延迟。
- 简单任务时将
8. 与 Planner/Reporter 的衔接要点
- Planner:在
description中具体化"信息源与指标口径",提升 Researcher 命中率与一致性。 - Reporter:鼓励表格化对比与末尾集中式引用列表,减少内文 inline 引用。