好久没写博客了,今天一个简单的契机,记录一下如何简单的使用循环神经网络和它的扩展方法来做一个简单的序列预测。这段时间一直在用GRU做一些网络架构的设计,但是自己写的方法一直不工作,误差很大,又没有在网上找到比较现成或者直观的代码可以直接复现,比较头疼,今天刷到b站一个up做的视频Pytorch简单案例带你学会使用LSTM,GRU,讲的深入浅出,很用心很详细,跑了一遍感慨万千,记录一下过程和心得。
目标很简单,输入序列"hello",gt是"olhol",这里没有直接对独热码进行预测,而是做了一个embedding,先把四个字母('h', 'e', 'l', 'o')从4维转到10维,然后再进循环网络。
python
char_box = ['e', 'h', 'l', 'o']
char_hello = [1, 0, 2, 2, 3]
char_ohlol = [3, 1, 2, 3, 2]考虑到char_hello作为输入转tensor要维度扩展,所以得从5给view到5, 1,通过一下方式将列表转tensor:
python
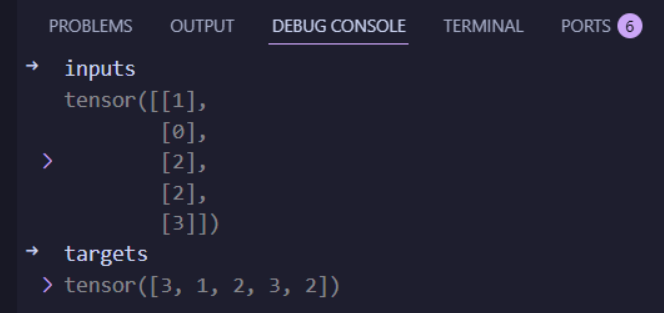
inputs = torch.tensor(char_hello).view(5, 1)
targets = torch.tensor(char_ohlol)转换结果很直观,inputs.shape是torch.Size(5, 1),targets.shape是torch.Size(5)
然后定义三个网络,这里没有太多要注意的,用什么网络就把其它的注释掉,注意输入的input_dim是输入编码的数量,'h', 'e', 'l', 'o'一共四个字母,就是4。而embedding_dim是编码后升维的维度,这里我们简单升到10维,让它等于10。hidden_size本质是可以随意定义的,但是目前我们的三个循环神经网络都是1层,所以隐层维度就是输出维度,和输入维度相匹配,也是4。如果num_layers超过1,那就可以考虑给hidden_size升高维度,不过记得要接一个线性层Linear转回输出维度。
python
class noNameNet(nn.Module):
def __init__(self, input_dim, embedding_dim, hidden_size, num_layers):
super(noNameNet, self).__init__()
self.emb = nn.Embedding(num_embeddings=input_dim, embedding_dim=embedding_dim)
self.rnn = nn.RNN(input_size=embedding_dim, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
self.lstm = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
self.gru = nn.GRU(input_size=embedding_dim, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
def forward(self, inputs): # inputs shape is [5, 1]
inputs_embeded = self.emb(inputs) # inputs_embeded.shape is [5, 1, 10]
inputs_embeded = inputs_embeded.permute(1, 0, 2) # inputs_embeded.shape is [1, 5, 10]
# # RNN, 其中hidden shape is [batch_size, num_layers, hidden_size]
# hidden = torch.zeros(self.rnn.num_layers, inputs_embeded.size(0), self.rnn.hidden_size)
# outputs, hidden = self.rnn(inputs_embeded, hidden) # outputs.shape is [1, 5, 4]
# # LSTM, 输入门,输出门和遗忘门
# hidden = torch.zeros(num_layers, inputs_embeded.size(0), hidden_size)
# cell = torch.zeros(num_layers, inputs_embeded.size(0), hidden_size)
# outputs, (hidden, cell) = self.lstm(inputs_embeded, (hidden, cell))
# GRU, 只需要输入们和输出门
hidden = torch.zeros(self.rnn.num_layers, inputs_embeded.size(0), self.rnn.hidden_size)
outputs, hidden = self.gru(inputs_embeded, hidden)
return outputs.view(-1, outputs.size(-1)) # [1, 5, 4] -> [5, 4]最后进到主函数,因为输入数据实在太简单,如果随机初始化的话,收敛花费的epoch是不一致的,这里就设置的大一些,最后整个网络肯定会在接收hello后准确输出ohlol的:
python
if __name__ == '__main__':
input_size = 4
embedding_dim = 10
hidden_size = 4
num_layers = 1
model = noNameNet(input_size, embedding_dim, hidden_size, num_layers)
loss_fn = nn.CrossEntropyLoss()
optim = torch.optim.Adam(model.parameters(), lr=1e-3)
epoch = 4000
for i in range(epoch):
print(f'---epoch {i+1} training loop start---')
model.train()
outputs = model(inputs) # outputs.shape is [5, 4]
result = outputs.argmax(axis=1)
for idx in result:
print(char_box[idx], end='')
print()
print(f"outputs is {outputs.shape}")
print(f"result is {result.shape}")
loss = loss_fn(outputs, targets)
optim.zero_grad()
loss.backward()
optim.step()
print(f"{i+1} training loop finished!, loss is {loss.item()}")
print("Training completed!")我这边大概迭代了90个epoch就能正确得到结果了。