文章目录
- 前期工作
- 理论基础
- 方向
- 代码源
- 开始工作
- [base paper 数据源(https://github.com/shijiebei2009/CEC-Corpus)](#base paper 数据源)
- 转载一个代码
前期工作
聚焦在把 LLM/神经网络 + 符号 / 逻辑 / 因果 + 时空 + 知识图谱这几块统一起来的工作
| 题目 | 核心贡献 / 与你"四维知识图谱"(节点+因果边+空间+时间+推理接口)关系 |
|---|---|
| NeuSTIP: A Neuro-Symbolic Model for Link and Time Prediction in Temporal Knowledge Graphs (Singh, Kaur, Gaur, Mausam, 2023) | 在 Temporal Knowledge Graph Completion (TKGC) 中,结合了规则学习(symbolic)+Embedding的方式,实现对 link prediction 和 time‐interval 预测。用 Allen 时序逻辑关系来保证规则间的时序一致性。(arXiv) |
| CEGRL-TKGR: Causal Enhanced Graph Representation Learning Framework for Temporal Knowledge Graph Reasoning (Sun et al., 2024) | 在 TKG 推理里,引入因果结构(causal representation)与混杂(confounding)区分,用因果干预的思想使模型不容易被虚假关联误导,从而更健壮地预测。对应"因果 + 时间 +图 + link prediction"那部分。(arXiv) |
| EvoKG: Jointly Modeling Event Time and Network Structure for Reasoning over Temporal Knowledge Graphs | 强调事件时间和图结构一起演化。更偏"时间动态 + 图结构"的建模。对四维图的"时间 +事件关系 +结构演化"很重要。(arXiv) |
| ChronoR: Rotation Based Temporal Knowledge Graph Embedding | 用旋转变换的方法来把 relation + time 的交互表征进实体 embeddings 中,是个在 embedding + 时间维度结合的表现型(representation-based)方法。(arXiv) |
| Temporal Causal Contrast Graph Network (TCCGN): Causal Decoupling for Temporal Knowledge Graph Reasoning | 强调将因果信号从噪声中分离出来 + 对时间语义结构的一致性对齐 + 长短期知识融合。非常贴近你想统一时空+因果+符号/embedding 的目标。(MDPI) |
| HTCCN: Temporal Causal Convolutional Networks with Hawkes Process for Extrapolation Reasoning in TKGs | 利用 Hawkes 过程来建模事实(edges)之间时间上的影响,以及 temporal convolutional model 来捕捉历史影响。偏重时间事件发生的因果/条件性依赖建模。(ACL Anthology) |
| Modeling the evolution of temporal KGs with uncertainty (WGP-NN) | 不仅预测事实,还考虑预测的不确定性;用 Gaussian Process + GNN 在连续时间域上模型结构 + 时间依赖性。对于现实系统中需要处理不确定性+时间+图结构组合很重要。([Papers with Code](https://paperswithcode.com/paper/modeling-the-evolution-of-temporal-knowledge?utm_source=chatgpt.com "Modeling the evolution of temporal knowledge graphs with uncertainty |
| Unifying Physics- and Data-Driven Modeling via Novel Causal Spatiotemporal GNN for Interpretable Epidemic Forecasting | 虽然应用在流行病预测,但它融合了物理模型(有符号/因果先验)+ST-GNN(时空图神经网络)。这正是"空间 + 时间 +因果 +图神经 / 符号先验"的一个较完整例子。(arXiv) |
理论基础
Survey /理论 /基础资源
这些是对整体领域做总结或者提供基础理论框架(可能不能下载)
Knowledge Graph Reasoning: A Neuro-Symbolic Perspective (Cheng, Sun 等, Spring 2024/2025) --- 这个讲逻辑与表示学习(representation learning)如何结合进行 KG 推理。
Neuro-symbolic AI and the Semantic Web (Hitzler, Ebrahimi, Sarker, Stepanova, ...) --- 探讨语义网 (Semantic Web/知识图谱) 在 neuro-symbolic AI 中的角色,包括符号推理与深度学习的整合。
Survey on Trustworthy Graph Neural Networks: From A Causal Perspective --- 这个 survey 将因果学习(causal representation / learning)与 GNN 结合,对可解释性、偏差、分布迁移等问题做了分类。是你构建"因果 + GNN + 图"部分的好参考。
Causal Representation Learning from Multiple Distributions: A General Setting (Kun Zhang et al.) --- 关于如何在多个分布/非平稳时间序列中恢复潜在因果变量以及它们之间的因果图。对你的"潜在因果表征 /因果潜变量"方向非常关键。
方向
"四维知识图谱"构想,下列是目前的局限与未来可能路径:
空间维度 (空间坐标/地理位置 or embedding of空间关系) 在很多 TKG / 因果 + KG 的工作里往往只关注时间 +实体 +关系,而空间(如果是实体有地理属性或者事件有地点属性)被弱化甚至忽略。要统一包括空间,需要融入 ST-GNN 等模型,或引入空间关系逻辑。
知识与逻辑推理接口:即你的 LLM/符号逻辑部分与图表示学习/因果模型之间的接口设计。目前很多方法要么"嵌入 + 学习"方式,要么"规则 /逻辑 + embedding"混合,但未必有一个可调用的、可解释的逻辑/符号推理层(尤其在复杂因果 +时空 +实体变化时)。
因果关系的发现 vs 因果推理 vs 干预:很多工作是在预测(link / event /时间)上,而真正的因果干预(如果做"如果在时间 t 执行动作 A",对未来空间-事件有什么影响)还比较少。若把 edge 视为因果边,则需要方法能处理干预 / counterfactual。
标注 /数据稀疏&不完整性:时空 + 因果 +实体丰富性的 KG 数据往往非常稀疏,实体可能新出现(inductive setting),规律可能只部分观测。如何设计模型对未知实体/未知事件有泛化能力。
可解释性与透明的逻辑 /符号规则:在系统实际使用中(比如科研、政策、医疗等)我们希望不仅有预测,还能解释"为什么会预测这个事件→事件"/"为什么这个因果关系成立"。这就要求逻辑部分/因果图部分能被人理解。
融合 LLM 的能力(语言抽象、通用知识):LLM 可以提供抽象的实体/概念/规则(比如 commonsense rules /世界知识 /语言语义),如何和 TKG + ST-GNN + 因果表征结合好,是大方向。
代码源
| 论文/项目 | PDF 可下载地址 | Github 实现 /代码仓库 | 简要备注 |
|---|---|---|---|
| NeuSTIP: A Neuro-Symbolic Model for Link and Time Prediction in Temporal Knowledge Graphs | PDF 在 EMNLP 2023 / ACL Anthology,可以下载。(ACL Anthology) | Yes --- dair-iitd/NeuSTIP (GitHub) | 包含规则学习 + 时间预测 + link prediction。数据 +代码都 release 了。(CSE IIT Delhi) |
| CEGRL-TKGR: Causal Enhanced Graph Representation Learning for Temporal Knowledge Graph Reasoning | PDF 可以从 arXiv / ACL Anthology 等处下载。(ACL Anthology) | Yes --- 仓库 shengyp/CEGRL-TKGR (GitHub) | 用因果/混杂表示 disentangle + 干预思想来提升 TKGR 的 link prediction 的健壮性。(arXiv) |
| Logic and Commonsense-Guided Temporal Knowledge Graph Completion (LCGE) | PDF 在 arXiv 上可以下载。([arXiv](https://paperswithcode.com/paper/modeling-the-evolution-of-temporal-knowledge?utm_source=chatgpt.com "Modeling the evolution of temporal knowledge graphs with uncertainty | Papers With Code")) | 是的 --- ngl567/LCGE 仓库。([arXiv](https://paperswithcode.com/paper/modeling-the-evolution-of-temporal-knowledge?utm_source=chatgpt.com "Modeling the evolution of temporal knowledge graphs with uncertainty |
| 类别 | 名称 / 论文 | PDF 链接 | GitHub / 代码 | 备注 |
|---|---|---|---|---|
| 规则提取 / Neuro-Symbolic | NeuSTIP: A Neuro-Symbolic Model for Link & Time Prediction in TKGs | ACL Anthology PDF | dair-iitd/NeuSTIP | 规则 + 神经模型,做 link & time prediction |
| LCGE: Logic & Commonsense-Guided Temporal KG Completion | arXiv PDF | ngl567/LCGE | 引入逻辑规则 + commonsense,补全 TKG | |
| Neuro-Symbolic System over KGs (survey & framework) | Semantic Web Journal | NeSymGraphs org | NeSy + KG 综述与代码合集 | |
| Temporal Knowledge Graph (TKG) | Temporal Graph Networks (TGN) | 论文 PDF | twitter-research/tgn | 动态图 / 时间事件序列建模框架 |
| RE-GCN (Reasoning over Evolving Graphs) | 论文 PDF | Official RE-GCN repo | 演化图表示,用于 TKG reasoning | |
| TKG Forecasting Evaluation (NEC repo) | Evaluation repo | TKG 预测评测工具 | ||
| Temporal Graph Benchmark (TGB) | arXiv PDF | TGB repo | NeurIPS benchmark,统一数据+评测 | |
| Spatio-Temporal GNN (ST-GNN) | STGCN: Spatio-Temporal GCN | arXiv PDF | hazdzz/stgcn , FelixOpolka/STGCN-PyTorch | 交通预测经典模型 |
| STGNN (variants) | 相关论文合集 | LMissher/STGNN | 多种交通/时空预测实现 | |
| PyTorch Geometric Temporal | Doc | benedekrozemberczki/pytorch_geometric_temporal | PyG 的时空扩展库,含多模型实现 | |
| 因果表征学习 (Causal Rep. Learning) | DEAR (Disentangled Causal Representation) | arXiv PDF | xwshen51/DEAR | 可辨识因果潜变量学习 |
| SCM-VAE | arXiv PDF | Akomand/SCM-VAE | 结构化因果模型 VAE | |
| BISCUIT / Causal VAE variants | Causal Gen. Modeling Survey | Akomand/Causal-Generative-Modeling-Survey | 因果生成模型综述 + 代码集合 | |
| 联合 / 应用 | Physics + Data-driven Causal ST-GNN (Epidemic Forecasting) | arXiv PDF | unifying-STGNN repo | 把物理模型 + ST-GNN 融合 |
| LLM + KG 接口 (Graphiti & others) | 实验论文 PDF | graphiti repo | LLM 作为 KG 推理接口实验 | |
| 数据集 / Benchmarks | ICEWS, GDELT, YAGO11k, Wikidata12k, EventKG | Dataset site | 各 repo 附数据脚本 | 常用于 TKGR 训练和评测 |
开始工作
基于数据源的工作
| 名称 / 项目 | 内容简介 | 用到了 CEC 吗 /用中文事件语料吗 | 有无开源或 PDF 可查 | 备注 /潜在用途 |
|---|---|---|---|---|
| 中文突发事件语料库 (CEC -- Chinese Emergency / Crisis Event Corpus) | 是上海大学语义智能实验室做的一个语料库,包括地震、火灾、交通事故、恐怖袭击、食物中毒这五类突发事件。新闻报道 + 事件标注(要素包括事件、时间、地点、参与者...)共 332 篇。(遇见数据集) | 是 --- 本身就是中文事件数据集 | 有;数据集能下载(GitHub 上/公共资源库),包含标注。(遇见数据集) | 用于事件抽取、实体识别、事件要素识别等任务,是中文事件 /中文事件知识图谱研究中的基础资源 |
| 事件知识图谱 - EventKGE(中文版本 /基于 CEC2.0 + ACE2005 + 实验) | "EventKGE 模型"在中文语料上有实验,设计事件 + 实体异构图 + 因果转移机制,把事件信息融入知识图嵌入(KGE)任务。(CSDN Blog) | 是 --- 用到了 CEC(或 CEC2.0)数据集 + ACE2005 等中文 /中英混合语料。(CSDN Blog) | 有;文章介绍 +实验结果;具体代码情况可能部分开源/个人博客介绍。(CSDN Blog) | 对事件嵌入 +实体和事件节点混合图 +因果/事件转移特性识别有意义,可以借鉴做因果边 +事件表示任务 |
| 基于因果关系知识库的因果事件图谱构建(汀丶人工智能 / 各中文技术社区) | 探讨中文文本中因果事件的抽取,构造因果知识库 / 模板 /模式库 +事件表示 +事件融合等流程。(Baidu Developer Center) | 是 --- 面向中文文本 /中文语料库 | 有;项目描述 +技术博客。有些可能只是技术计划或演示文;不确定是否有完整开源代码。(Tencent Cloud) | 可作为原型 /思路;如果做统一系统,这样的因果事件抽取 +图谱构建环节是必要的一个模块 |
| "事件知识图谱构建研究进展与趋势"(国内综述文章) | 从事件抽取、关系抽取、可信度计算、事件知识图谱构建技术 +事件推理等方面,系统回顾国内外事件知识图谱的研究状态,包括中文部分。(Secrss) | 有中文背景 /中文研究被讨论 | 综述型,有文献 +论文可查 | 用来了解中文/国内在事件知识图谱这一块的空白与挑战,非常有助于定位研究或系统设计空间 |
用 CEC 或中文事件语料做"时空 + 因果 +知识图谱 +LLM接口"这种较为统一系统的工作 还比较少,有以下几个挑战和机会:
因果边关系标注稀少
CEC 的标注主要是事件本身及其时间、地点、参与者等要素,对事件之间 因果关系 的明确标注较少/不成系统。若要做因果图谱,需要自己扩充/标注因果边。
空间属性弱 /地点标准化问题
虽然 CEC 有地点标注,但地点粒度/地理空间坐标化(经纬度等)可能不统一,需要做归一化以支持空间维度推理。
时间线 /动态性
CEC 文本是静态事件报道,事件之间随着时间有可能演化或重复,构造 temporal KG 或时空图神经网络模型,需要把多个时间点 /事件历史整合起来,这在中文事件中做得不多。
融合 LLM /逻辑 /符号规则
在中文语境中,将 LLM(中文大语言模型)结合符号逻辑/规则/因果模板,用于事件因果推理 +时空逻辑推理的系统性工作还比较缺乏。
英文的
| 名称 | 核心内容 | 涉及哪些要素(节点/实体/事件、时间、空间、因果边、图模型、符号规则/LLM 接口) | 优点 | 差距 /未覆盖部分 |
|---|---|---|---|---|
| CEGRL-TKGR: Causal Enhanced Graph Representation Learning for Temporal Knowledge Graph Reasoning (arXiv) | 在 Temporal KG 上做 Reasoning;把实体/关系演化表示拆成因果 vs 混杂部分,用因果表示做预测,以抵消虚假关联。 | 节点/关系/时间 / 图模型 / 因果边 / 表示学习;没有明确空间维度;也没直接用 LLM + 符号规则做推理接口。 | 因果 vs 混杂的拆分是解决虚假关系问题的重要方法; temporal KGs 上实验多,效果好。 | 未包括空间因素;符号逻辑/LLM 接口(解释/规则推理)弱;不包含地理空间坐标 /空间拓扑/空间约束等。 |
| Chain-of-History Reasoning for Temporal Knowledge Graph Forecasting (arXiv) | 这个工作把 LLM 引入 TKG 预测任务,引入了"high-order历史(Chain of History)"模块,使 LLM 可以逐步利用多个时间点/历史事实,不只是最近的,来预测未来。 | 时间 + 图模型 + LLM 接口 + 节点/实体;涉及因果性暗示(历史推理)但不是显式因果边标注/干预;空间属性通常不涉及。 | 在如何把历史(时间)系统地提供给 LLM + 图模型结合上做得不错;对现实 TKG 预测任务有改进。 | 没有空间/地理属性;因果边/符号规则部分不是非常明确;解释性/符号推理方面还有限。 |
| Causal Graphs Meet Thoughts: Enhancing Complex Reasoning in Graph-Augmented LLMs (arXiv) | 提出管道 (pipeline),在用图增强 +检索 +图遍历的时候强调 cause-effect 边,过滤 KG 以突出因果边,并使检索与 LLM 的 CoT(chain-of-thought)对齐。用于医学问答等任务。 | 节点/实体/事件 + 图模型 + 因果边 + LLM 接口 + 检索增强;时间维度可能有限;空间维度通常不覆盖。 | 在复杂推理任务(医学问答)中提升了因果一致性和可解释性;图检索 + 因果边处理比较明确。 | 时间维度和空间维度结合不强 /未强调空间;事件随时间演化 /时序依赖性做的不是完整的 temporal KS +图演化那种形式;符号逻辑规则部分可能较轻。 |
| "Back to the Future: Towards Explainable Temporal Reasoning with Large Language Models" (ACM Digital Library) | 新任务(ExpTime):给定 temporal KG 中的上下文预测未来事件,并要求 LLM 不仅做预测还要产生合理解释。构造带解释能力的数据集 +训练策略(instruction tuning),TimeLlaMA 模型。 | 时间 + 图(TKG) + LLM 接口 +解释性;节点/事件;因果边暗含于事件之间的因果 / temporal dependency;空间维度通常没明确处理。 | 在 "时间 + 解释性推理 + LLM 接口"方面做得很完整;任务设定和数据集支持较好的 temporal reasoning 和 explanation。 | 空间部分没有;因果边通常不是明确标注干预 /结构因果模型那样形式;图结构演变 +空间约束结合不强。 |
| "Learning Concept-Based Causal Transition and Symbolic Reasoning for Visual Planning" (arXiv) | 在视觉规划中,将视觉输入抽象为概念符号,加强符号推理 + 视觉因果转换模型;规划任务中需要推理未来视觉状态。 | 节点(视觉概念) + 因果转移 +符号推理 +图模型成分(从视觉状态 transition 构图) +时间依赖;空间是视觉场景(间接空间信息)存在,但不一定是地理坐标那种空间维度;LLM 接口并非直接的大语言模型为主,而是视觉 + 模型 +符号组合。 | 符号 + 因果 +时间 +图 +视觉组合,对类似你构想的"事件/实体 + 因果边 +时间 +符号推理"模式有启示;通用性/解释性较强。 | 地理空间 /空间位置维度若干情况比较弱;中文 /自然语言部分与 LLM 结合不强;事件知识图谱形式与大型实体/复杂空间关系未必涉及。 |
节点/实体/事件 --- 大部分都有。
时间维度 --- 多有时间依赖的模型(Temporal KG / TKGR /历史链 etc)。
空间维度 --- 很少有工作的空间(地理位置 or 物理空间坐标 /空间拓扑约束)被同时显式处理。
因果边 --- 有的做因果关系推理/边的显式建模,有的只是暗含或借助因果概念,但形式化/干预/counterfactual 部分少。
图模型 + 符号/LLM 接口 --- 图模型 +表示学习这部分很常见;符号规则或符号推理 + LLM 接口这种混合型也有,但往往在某些元素上比如空间维度或事件演变受限。
CEGRL-TKGR --- 可做为 temporal + 因果边 +图模型部分的基础。
Back to the Future: Explainable Temporal Reasoning with LLMs --- 时间 +解释性 +LLM 接口良好。
Causal Graphs Meet Thoughts: Enhancing Complex Reasoning in Graph-Augmented LLMs --- 符号/因果边 + 图 + LLM 接口做得不错。
Learning Concept-Based Causal Transition and Symbolic Reasoning for Visual Planning --- 虽然是视觉场景,但符号 +因果 +时间链 +图转换非常典型,可以借鉴空间维度的处理方式。
base paper 数据源
刘 炜,王 旭,张雨嘉,刘宗田. 一种面向突发事件的文本语料自动标注方法. 中文信息学报. 2017, 31(2): 76-85
论文主题与背景简述
这篇论文旨在解决突发事件中大量文本信息快速、准确的标注问题,以提升事件监测与响应的效率。突发事件的特决定了文本语料的多样性、非结构性强,人工标注繁琐且耗时,亟需一种自动化、智能化的标注方法。
研究目标
开发一种新颖的面向突发事件文本的自动标注技术
提高标注效率和准确率
支持应急监控、信息筛查、事件分析等应用场景
研究方法总体框架
- 数据准备与预处理
收集突发事件相关的文本语料,可能涵盖新闻报道、社交媒体、现场报告等多源、多格式文本
数据清洗:去除噪声,分词、词性标注、去除停用词,确保文本的基本质量
构建样本集,标记部分数据作为"训练集"或"测试集"基础
- 关键技术与模型设计
采用自然语言处理(NLP)中常用的特征工程:词向量、关键词提取、句法依存关系等
设计特定的特征提取方案,以捕获突发事件文本中的特殊信息(地点、时间、事件类型、关键词等)
利用机器学习或深度学习模型(如条件随机场CRF、神经网络等)实现自动标注
- 自动标注流程
构建规则或基于学习的方法,将文本中的内容映射到预定义的标签空间
结合上下文信息、多层次特征进行推理,增强模型的语境理解
采用迭代训练/自适应学习方式,逐步优化标注准确率(类似自学习、自训练的思想)
- 模型训练与优化
使用已有的标注样本对模型进行训练
调整超参数、优化模型结构
通过交叉验证或K折验证确保模型的泛化能力
- 实际应用与验证
在突发事件新采集文本上进行自动标注
评估指标:准确率、召回率、F1值等
对比人工标注或其他已有工具的性能,验证方法的有效性
研究流程
| 流程步骤 | 描述 | 细节和关键技术 | 预期目标 |
|---|---|---|---|
| 数据采集 | 收集突发事件相关文本 | 来源多样化(新闻、社交、现场报告) | 丰富语料库,为模型提供素材 |
| 数据预处理 | 分词、去噪、词性标注等 | NLP预处理方法,文本标准化 | 提升后续模型准确性 |
| 特征提取 | 构建特征向量,关键词、依存关系 | 词向量(如Word2Vec/BERT)、规则特征 | 捕获事件关键特征 |
| 模型构建 | 设计适合突发事件文本的自动标注模型(CRF、深度学习) | 结合上下文、多层次特征 | 实现高效标注 |
| 模型训练 | 使用标注样本训练模型 | 采用梯度下降、正则化、迁移学习等 | 优化模型性能 |
| 自动标注 | 在新文本中应用模型 | 实时或批量处理 | 实现自动化标注 |
| 评估优化 | 反复调优模型参数 | 多指标评估,增强鲁棒性 | 提升准确率和应用效果 |
方法的创新点
针对突发事件文本的特点(高噪声、非结构化)设计特征
引入特定规则和机器学习结合的方法,增强模型适应性
利用深度学习模型捕获更复杂的语义关系
采用多源、多格式结合策略,扩展模型的泛化能力
自适应学习机制,不断提升标注质量
研究流程的深度讨论
从表面现象到本质原理:传统的文本标注多基于手工规则或静态模型,本文论文应强调"面向突发事件"的实时性和多样性,解决模型在特定环境下的鲁棒性和适应性问题。这涉及到特征的自主提取与模型的动态调整,更接近"动态认知系统"。
多层次思考与联系建立:突发事件的语言文本中,地点、时间等元素极为重要,模型需结合语境信息(如依存关系网络)实现"上下文感知"。本方法应整合实体识别、事件关系推理等多任务学习策略。
深度挖掘流程价值:此类研究的核心在于"自动、快速、准确"的边界,突破人工限制,实现"预警、监测"自动化,因此方法设计强调智能决策和反馈机制,从数据采集到模型训练、到应用部署,这个闭环流程是保障系统持续提升的关键。
数据可用性
标注可用性
其他的需要创新了
下面部分是转载的
版权声明:本文为CSDN博主「shijiebei2009」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/shijiebei2009/article/details/44538257
1、什么是本体?
本体最初是一个哲学上的概念,十多年前被引入计算机领域中作为知识表示的方法并被广泛使用。Studer给出了本体的定义:"本体是共享概念模型的明确的形式化规范说明"。本体对于探索人的认知原理、发展自然语言理解技术和人机交互技术有重要意义。但是传统的本体模型存在着一系列的不足之处,1、作为知识的表示形式,在描述多远关系的能力上存在先天不足;2、认知科学家认为,人的概念大体可分为实体和事件,之前的研究更多关注的是大脑如何描绘实体而很少关注实体与事件的更本质的区别。
2、什么是事件?
世界是运动的,运动的世界是由事件组成的。事件是可以感知的、相对独立的、运动着的存在,它不同于静态概念。事件涉及多方面的实体,或称要素,包括时间要素、地点要素、参与者要素、过程状态要素。具有共同属性事件的集合的最大闭包称为事件类,或称为动态概念。事件类之间也具有包含关系,即由每个要素的属性的包含关系组成,这是一个多格结构。
世界的运动是绝对的,静止是相对的。任何实体都可以是事件要素的构成元素,不构成事件要素的实体是不存在的。事件是随着时间变化的具体事实。事件与事件之间具有本质的内在联系。
3、事件的定义是什么?
定义1(事件) 指在某个特定的时间和环境下发生的、由若干角色参与、表现出若干动作特征的一件事情。形式上,事件可表示为e, 定义为一个六元组:e =(A , O , T, V , P , L)
其中, 事件六元组中的元素称为事件要素, 分别表示动作、对象、时间、环境、断言、语言表现。
A(动作):事件的变化过程及其特征, 是对程度、方式、方法、工具等的描述, 例如快慢、使用什么、根据什么等等。
O(对象):指事件的参与对象, 包括参与事件的所有角色, 这些角色的类型数目称为对象序列长度。对象可分别是动作的施动者(主体)和受动者(客体)。
T(时间):事件发生的时间段, 从事件发生的起点到事件结束的终点, 分为绝对时间段和相对时间段两类。
V(环境):事件发生的场所及其特征等。例如:在小池塘里游泳, 场所:小池塘, 场所特征:水中。
P(断言):断言由事件发生的前置条件、中间断言以及后置条件构成。前置条件指为进行该事件, 各要素应当或可能满足的约束条件, 它们可以是事件发生的触发条件;中间断言指事件发生过程的中间状态各要素满足的条件;事件发生后,事件各要素将引起变化或者各要素状态的变迁, 这些变化和变迁后的结果, 将成为事件的后置条件。
L(语言表现):事件的语言表现规律, 包括核心词集合、核心词表现、核心词搭配等。核心词是事件在句子中常用的标志性词汇。核心词表现则为在句子中各要素的表示与核心词之间的位置关系。核心词搭配是指核心词与其他词汇的固有的搭配。可以为事件附上不同语言种类的表现, 例如中文、英文、法文等等。
4、事件本体的定义是什么?
定义3(事件本体) 事件本体是共享的、客观存在的事件类系统模型的明确的形式化规范说明, 表示为EO。定义4(事件本体的结构) 事件本体的逻辑结构可定义为一个三元结构EO :={ECS , R , Rules}, 这里, ECS(事件类集合)是所有事件类的集合。R(事件类之间的关系集合)包括事件类之间的分类关系和非分类关系。由分类关系可构成事件类层次。非分类关系上标明关系种类名和链接强度。链接强度用区间 0, 1 之间的值来表示, 可通过学习或遗忘改变。Rules(规则)由逻辑语言表示, 可用于事件断言所不能覆盖的部分事件与事件间的转换与推理。
事件本体作为一种面向事件的知识表示方法, 更符合现实世界的存在规律和人类对现实世界的认知规律。过去的世界发生了许多的事件, 变成了今天的世界;今天的世界又将发生许多事件, 变成明天的世界。描述变化的历史, 就是描述这些发生的事件以及它们之间的关系。人类用话语文本表述,描述的只是事件及其关系的语言表现。要理解这些话语文本, 就必须知道这些事件类丰富的内容, 这些内容的绝大部分是不可能在话语文本中叙述的, 而是作为共同知识预先存在于每个交流者的头脑中。事件本体正是为计算机建造这样的共同知识。
5、CEC如何构建?
事件本体是以"事件"为认知单元,研究事件的组成以及事件之间的关系,并对事件进行归纳和概括,形成事件类,进而构建事件本体模型。研究本体,必然要先构建语料库,所以在互联网上选取了突发事件语料来进行语料的事件标注,突发事件的分类体系,包括三个层次:一级4个大类(自然灾害类N、事故灾难类A、公共卫生事件P、社会安全事件S),二级33个子类,三级94个小类。我们标注的语料库称为CEC(Chinese Emergency Corpus),主要包括五类:地震、火灾、交通事故、恐怖袭击、食物中毒。合计332篇,下载地址为:https://github.com/shijiebei2009/CEC-Corpus
6、主要标签图结构图
1、什么是本体?
本体最初是一个哲学上的概念,十多年前被引入计算机领域中作为知识表示的方法并被广泛使用。Studer给出了本体的定义:"本体是共享概念模型的明确的形式化规范说明"。本体对于探索人的认知原理、发展自然语言理解技术和人机交互技术有重要意义。但是传统的本体模型存在着一系列的不足之处,1、作为知识的表示形式,在描述多远关系的能力上存在先天不足;2、认知科学家认为,人的概念大体可分为实体和事件,之前的研究更多关注的是大脑如何描绘实体而很少关注实体与事件的更本质的区别。
2、什么是事件?
世界是运动的,运动的世界是由事件组成的。事件是可以感知的、相对独立的、运动着的存在,它不同于静态概念。事件涉及多方面的实体,或称要素,包括时间要素、地点要素、参与者要素、过程状态要素。具有共同属性事件的集合的最大闭包称为事件类,或称为动态概念。事件类之间也具有包含关系,即由每个要素的属性的包含关系组成,这是一个多格结构。
世界的运动是绝对的,静止是相对的。任何实体都可以是事件要素的构成元素,不构成事件要素的实体是不存在的。事件是随着时间变化的具体事实。事件与事件之间具有本质的内在联系。
3、事件的定义是什么?
定义1(事件) 指在某个特定的时间和环境下发生的、由若干角色参与、表现出若干动作特征的一件事情。形式上,事件可表示为e, 定义为一个六元组:e =(A , O , T, V , P , L)
其中, 事件六元组中的元素称为事件要素, 分别表示动作、对象、时间、环境、断言、语言表现。
A(动作):事件的变化过程及其特征, 是对程度、方式、方法、工具等的描述, 例如快慢、使用什么、根据什么等等。
O(对象):指事件的参与对象, 包括参与事件的所有角色, 这些角色的类型数目称为对象序列长度。对象可分别是动作的施动者(主体)和受动者(客体)。
T(时间):事件发生的时间段, 从事件发生的起点到事件结束的终点, 分为绝对时间段和相对时间段两类。
V(环境):事件发生的场所及其特征等。例如:在小池塘里游泳, 场所:小池塘, 场所特征:水中。
P(断言):断言由事件发生的前置条件、中间断言以及后置条件构成。前置条件指为进行该事件, 各要素应当或可能满足的约束条件, 它们可以是事件发生的触发条件;中间断言指事件发生过程的中间状态各要素满足的条件;事件发生后,事件各要素将引起变化或者各要素状态的变迁, 这些变化和变迁后的结果, 将成为事件的后置条件。
L(语言表现):事件的语言表现规律, 包括核心词集合、核心词表现、核心词搭配等。核心词是事件在句子中常用的标志性词汇。核心词表现则为在句子中各要素的表示与核心词之间的位置关系。核心词搭配是指核心词与其他词汇的固有的搭配。可以为事件附上不同语言种类的表现, 例如中文、英文、法文等等。
4、事件本体的定义是什么?
定义3(事件本体) 事件本体是共享的、客观存在的事件类系统模型的明确的形式化规范说明, 表示为EO。定义4(事件本体的结构) 事件本体的逻辑结构可定义为一个三元结构EO :={ECS , R , Rules}, 这里, ECS(事件类集合)是所有事件类的集合。R(事件类之间的关系集合)包括事件类之间的分类关系和非分类关系。由分类关系可构成事件类层次。非分类关系上标明关系种类名和链接强度。链接强度用区间 0, 1 之间的值来表示, 可通过学习或遗忘改变。Rules(规则)由逻辑语言表示, 可用于事件断言所不能覆盖的部分事件与事件间的转换与推理。
事件本体作为一种面向事件的知识表示方法, 更符合现实世界的存在规律和人类对现实世界的认知规律。过去的世界发生了许多的事件, 变成了今天的世界;今天的世界又将发生许多事件, 变成明天的世界。描述变化的历史, 就是描述这些发生的事件以及它们之间的关系。人类用话语文本表述,描述的只是事件及其关系的语言表现。要理解这些话语文本, 就必须知道这些事件类丰富的内容, 这些内容的绝大部分是不可能在话语文本中叙述的, 而是作为共同知识预先存在于每个交流者的头脑中。事件本体正是为计算机建造这样的共同知识。
5、CEC如何构建?
事件本体是以"事件"为认知单元,研究事件的组成以及事件之间的关系,并对事件进行归纳和概括,形成事件类,进而构建事件本体模型。研究本体,必然要先构建语料库,所以在互联网上选取了突发事件语料来进行语料的事件标注,突发事件的分类体系,包括三个层次:一级4个大类(自然灾害类N、事故灾难类A、公共卫生事件P、社会安全事件S),二级33个子类,三级94个小类。我们标注的语料库称为CEC(Chinese Emergency Corpus),主要包括五类:地震、火灾、交通事故、恐怖袭击、食物中毒。合计332篇,下载地址为:https://github.com/shijiebei2009/CEC-Corpus
6、主要标签图结构图
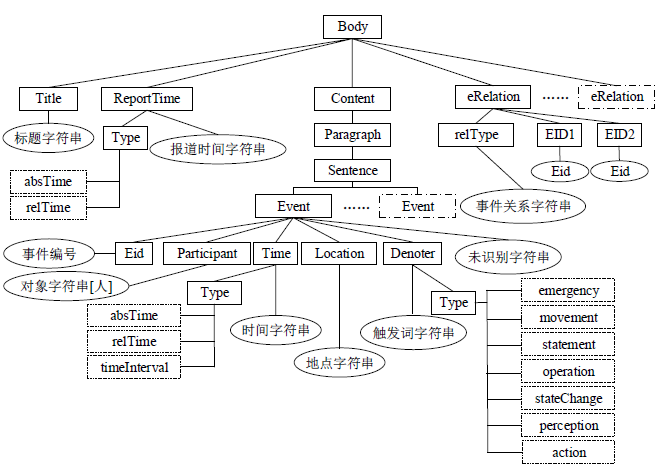
转载一个代码
作者:DashVector
链接:https://www.zhihu.com/question/433887869/answer/3505454459
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
本教程演示如何使用向量检索服务(DashVector),结合LLM大模型等能力,来打造基于垂直领域专属知识等问答服务。其中LLM大模型能力,以及文本向量生成等能力,这里基于灵积模型服务上的通义千问 API以及Embedding API来接入。背景及实现思路大语言模型(LLM)作为自然语言处理领域的核心技术,具有丰富的自然语言处理能力。但其训练语料库具有一定的局限性,一般由普适知识、常识性知识,如维基百科、新闻、小说,和各种领域的专业知识组成。导致 LLM 在处理特定领域的知识表示和应用时存在一定的局限性,特别对于垂直领域内,或者企业内部等私域专属知识。实现专属领域的知识问答的关键,在于如何让LLM能够理解并获取存在于其训练知识范围外的特定领域知识。同时可以通过特定Prompt构造,提示LLM在回答特定领域问题的时候,理解意图并根据注入的领域知识来做出回答。在通常情况下,用户的提问是完整的句子,而不像搜索引擎只输入几个关键字。这种情况下,直接使用关键字与企业知识库进行匹配的效果往往不太理想,同时长句本身还涉及分词、权重等处理。相比之下,倘若我们把提问的文本,和知识库的内容,都先转化为高质量向量,再通过向量检索将匹配过程转化为语义搜索,那么提取相关知识点就会变得简单而高效。接下来我们将基于中文突发事件语料库(CEC Corpus)演示关于突发事件新闻报道的知识问答。
整体流程
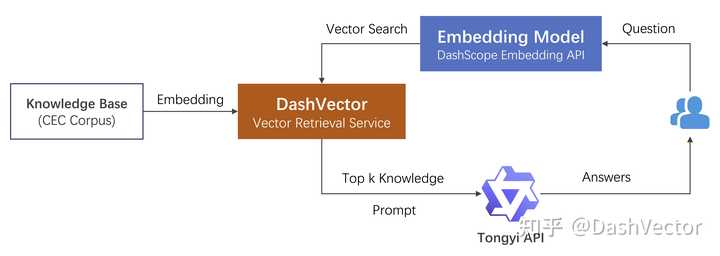 主要分为三个阶段:
主要分为三个阶段:
本地知识库的向量化。通过文本向量模型将其转化为高质量低维度的向量数据,再写入DashVector向量检索服务。这里数据的向量化我们采用了灵积模型服务上的Embedding API实现。
相关知识点的提取。将提问文本向量化后,通过 DashVector 提取相关知识点的原文。
构造 Prompt 进行提问。将相关知识点作为"限定上下文+提问" 一起作为prompt询问通义千问。
前提准备
- API-KEY 和 Cluster准备开通灵积模型服务,并获得 API-KEY。
请参考:开通DashScope并创建API-KEY。
开通DashVector向量检索服务,并获得 API-KEY。请参考:DashVector API-KEY管理。
开通DashVector向量检索服务,并创建Cluster。
获取Cluster的Endpoint,Endpoint获取请查看 Cluster详情。
说明
灵积模型服务DashScope的API-KEY与DashVector的API-KEY是独立的,需要分开获取。
- 环境准备说明需要提前安装 Python3.7 及以上版本,请确保相应的 python 版本。
pip3 install dashvector dashscope
- 数据准备
git clone https://github.com/shijiebei2009/CEC-Corpus.git
搭建步骤
说明
本教程所涉及的 your-xxx-api-key 以及 your-xxx-cluster-endpoint,均需要替换为您自己的API-KAY及CLUSTER_ENDPOINT后,代码才能正常运行。
- 本地知识库的向量化CEC-Corpus 数据集包含 332 篇突发事件的新闻报道的语料和标注数据,这里我们只需要提取原始的新闻稿文本,并将其向量化后入库。文本向量化的教程可以参考《基于向量检索服务与灵积实现语义搜索》。创建embedding.py文件,并将如下示例代码复制到embedding.py中:
bash
作者:DashVector
链接:https://www.zhihu.com/question/433887869/answer/3505454459
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
import os
import dashscope
from dashscope import TextEmbedding
from dashvector import Client, Doc
def prepare_data(path, batch_size=25):
batch_docs = []
for file in os.listdir(path):
with open(path + '/' + file, 'r', encoding='utf-8') as f:
batch_docs.append(f.read())
if len(batch_docs) == batch_size:
yield batch_docs
batch_docs = []
if batch_docs:
yield batch_docs
def generate_embeddings(news):
rsp = TextEmbedding.call(
model=TextEmbedding.Models.text_embedding_v1,
input=news
)
embeddings = [record['embedding'] for record in rsp.output['embeddings']]
return embeddings if isinstance(news, list) else embeddings[0]
if __name__ == '__main__':
dashscope.api_key = '{your-dashscope-api-key}'
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 创建集合:指定集合名称和向量维度, text_embedding_v1 模型产生的向量统一为 1536 维
rsp = client.create('news_embedings', 1536)
assert rsp
# 加载语料
id = 0
collection = client.get('news_embedings')
for news in list(prepare_data('CEC-Corpus/raw corpus/allSourceText')):
ids = [id + i for i, _ in enumerate(news)]
id += len(news)
vectors = generate_embeddings(news)
# 写入 dashvector 构建索引
rsp = collection.upsert(
[
Doc(id=str(id), vector=vector, fields={"raw": doc})
for id, vector, doc in zip(ids, vectors, news)
]
)
assert rsp在示例中,我们将 Embedding 向量和新闻报道的文稿(作为raw字段)一起存入DashVector向量检索服务中,以便向量检索时召回原始文稿。
- 知识点的提取
将 CEC-Corpus 数据集所有新闻报道写入DashVector服务后,就可以进行快速的向量检索。实现这个检索,我们同样将提问的问题进行文本向量化后,再在DashVector服务中检索最相关的知识点,也就是相关新闻报道。创建search.py文件,并将如下示例代码复制到search.py文件中。
bash
作者:DashVector
链接:https://www.zhihu.com/question/433887869/answer/3505454459
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
from dashvector import Client
from embedding import generate_embeddings
def search_relevant_news(question):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 获取刚刚存入的集合
collection = client.get('news_embedings')
assert collection
# 向量检索:指定 topk = 1
rsp = collection.query(generate_embeddings(question), output_fields=['raw'],
topk=1)
assert rsp
return rsp.output[0].fields['raw']- 构造 Prompt 向LLM(通义千问)提问在通过提问搜索到相关的知识点后,我们就可以将 "提问 + 知识点" 按照特定的模板作为 prompt 向LLM发起提问了。在这里我们选用的LLM是通义千问,这是阿里巴巴自主研发的超大规模语言模型,能够在用户自然语言输入的基础上,通过自然语言理解和语义分析,理解用户意图。可以通过提供尽可能清晰详细的指令(prompt),来获取更符合预期的结果。这些能力都可以通过通义千问API来获得。具体我们这里设计的提问模板格式为:请基于我提供的内容回答问题。内容是{},我的问题是{},当然您也可以自行设计合适的模板。创建answer.py,并将如下示例代码复制到answer.py中。
bash
from dashscope import Generation
def answer_question(question, context):
prompt = f'''请基于```内的内容回答问题。"
```
{context}
```
我的问题是:{question}。
'''
rsp = Generation.call(model='qwen-turbo', prompt=prompt)
return rsp.output.text知识问答
做好这些准备工作以后,就可以对LLM做与具体知识点相关的提问了。比如在 CEC-Corpus 新闻数据集里,有如下一篇报道。因为整个新闻数据集已经在之前的步骤里,转换成向量入库了,我们现在就可以把这个新闻报道作为一个知识点,做出针对性提问:海南安定追尾事故,发生在哪里?原因是什么?人员伤亡情况如何?,并查看相应答案。 创建run.py文件,并将如下示例代码复制到run.py文件中。
创建run.py文件,并将如下示例代码复制到run.py文件中。
bash
import dashscope
from search import search_relevant_news
from answer import answer_question
if __name__ == '__main__':
dashscope.api_key = '{your-dashscope-api-key}'
question = '海南安定追尾事故,发生在哪里?原因是什么?人员伤亡情况如何?'
context = search_relevant_news(question)
answer = answer_question(question, context)
print(f'question: {question}\n' f'answer: {answer}')可以看到,基于DashVector作为向量检索的底座,LLM大模型的知识范畴得到了针对性的扩展,并且能够对于专属的特定知识领域做出正确的回答。
写在最后
从本文的范例中,可以看到DashVector作为一个独立的向量检索服务,提供了开箱即用的强大向量检索服务能力,这些能力和各个AI模型结合,能够衍生多样的AI应用的可能。这里的范例中,LLM大模型问答,以及文本向量生成等能力,都是基于灵积模型服务上的通义千问API和Embedding API来接入的,在实际操作中,相关能力同样可以通过其他三方服务,或者开源模型社区,比如ModelScope上的各种开源LLM模型来实现。