第二部分:Spark SQL 入门(2)-算子介绍-Scan/InMemoryTableScan
其实在开始这部分之前,我思考了很久,到底该如何把算子教给读者,如果按其他的教学文章,应该会挨个罗列并展示用途,但我就自己学习经验来说,这种方式似乎并不高效,于是我打算把算子和sql联系起来,尽量避免抽象,如果各位有什么好的建议,请不吝赐教
1. HiveTableScan-数据扫描算子
我相信各位读者对这种sql应该不会觉得困难,当然了,实际工作中就别写*了,我这里偷个懒,需要哪些字段就写哪些字段,尽量减少查询的负担,能更快一些
sql
SELECT * FROM tableA;而这句最简单的select语句其实通过spark ui查看的话,就会是下面这张图,实际的表名和字段名都粗暴打码,不影响查看算子
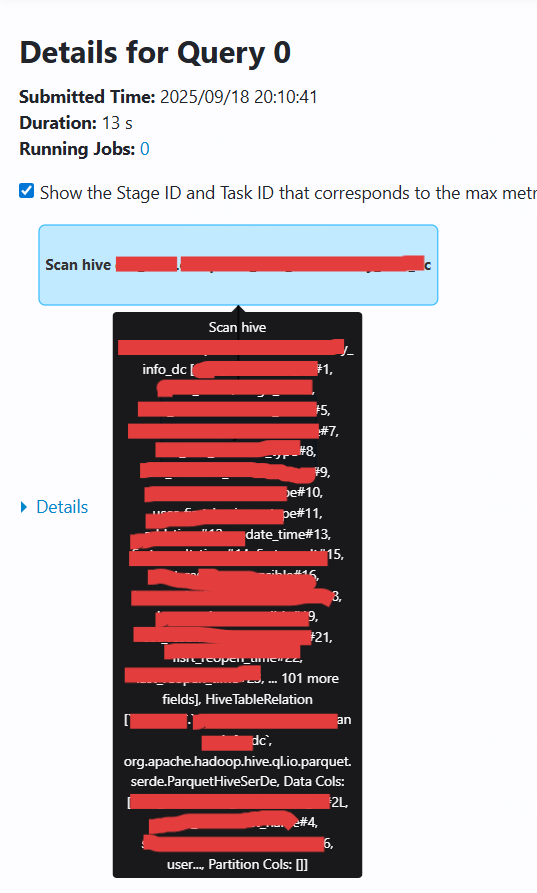
scala
//底层实际上会生成如下类型的扫描节点
val scan = sparkSession.sql("SELECT * FROM tableA")
//执行计划中会显示为:
//HiveTableScan [col1#0L, col2#1, ...], HiveTableRelation ...说明:
- 用于从 Hive 表中读取数据
- 显示所有选中字段(包括分区字段)
- 对应 `DataSourceScanExec` 或 `HiveTableScanExec` 物理算子
2. InMemoryTableScan-内存查询算子
但其实select语句还可能对应 InMemoryTableScan 阶段:
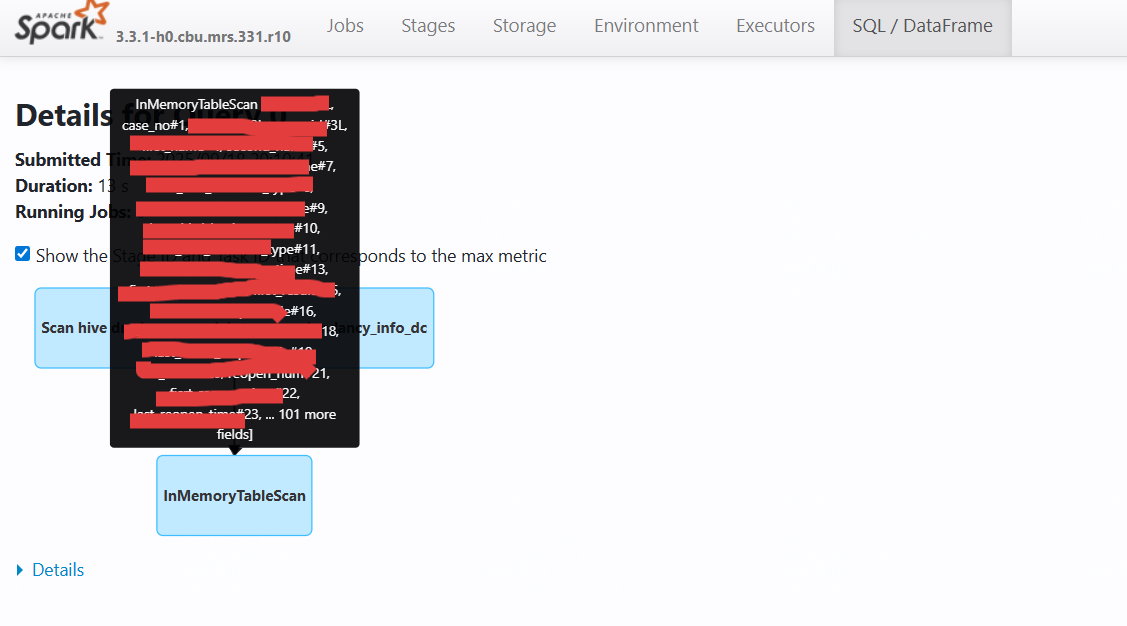
scala
// 如果该表已被缓存或物化,可能会触发内存扫描
val df = spark.table("tableA")
df.cache() // 或 persist()
df.select("*").explain()
// 执行计划中会出现:
// InMemoryTableScan [col1#0L, col2#1, ...]说明:
- 表示从 Spark 内存中读取缓存数据
- 通常出现在查询已被缓存(`cache()`/`persist()`)的表时
- 可显著提升查询性能,避免重复读取外部数据
对比:HiveTableScan vs InMemoryTableScan
| 特性 | HiveTableScan | InMemoryTableScan |
|---|---|---|
| 数据源 | Hive 外部表 | Spark 内存数据 |
| IO 开销 | 磁盘/网络 IO | 内存访问 |
| 执行速度 | 较慢 (13s) | 较快 (1s) |
| 字段处理 | 全字段扫描 | 选择性字段扫描 |
| 使用场景 | 初始数据加载 | 缓存数据重用 |
3. Filter - 数据过滤算子
sql
SELECT [部分字段]
FROM tabelB
WHERE day = '20250917' AND [其他过滤条件]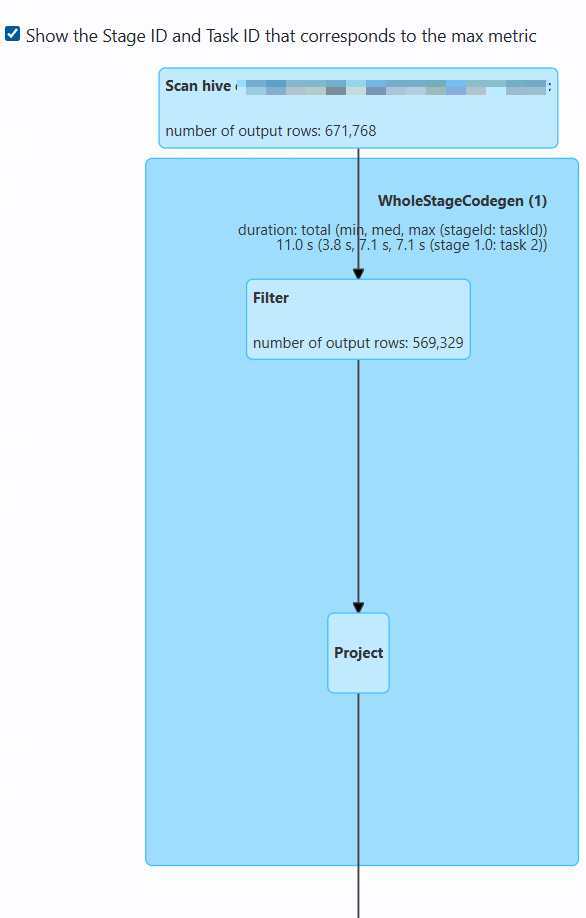
功能与性质:
- 条件过滤:根据WHERE子句中的条件过滤数据行
- 谓词下推:尽可能在数据扫描阶段提前执行过滤
- 选择率:过滤后保留的数据比例影响查询性能
执行详情:
plaintext
输入:671,768行(来自Scan阶段)
输出:569,329行
过滤率:约15.2%(过滤掉102,439行)优化机制:
- 使用统计信息优化过滤顺序(高选择率条件优先)
- 支持多种过滤条件(等于、范围、IN等)
4. Project - 字段裁剪算子
功能与性质:
- 字段选择:只选择查询中指定的列,减少数据传输量
- 表达式计算:处理SELECT中的计算表达式和函数调用
- 类型转换:处理数据类型的转换和格式化
优化机制:
- 消除不必要的字段传输
- 合并多个投影操作
- 延迟计算直到必要时
5. 完整执行流程
投影阶段 选择SELECT指定字段 执行计算表达式 类型转换 过滤阶段 应用WHERE条件 过滤不满足条件的行 Scan 阶段 读取Hive表数据 应用分区过滤
day=20250917 列裁剪
只读取需要的列 开始查询 输出: 671,768行 输出: 569,329行
过滤率: 15.2% 最终输出 查询完成
6. 性能优化建议
6.1 Scan优化
sql
-- 使用分区过滤
WHERE day = '20250917'
-- 使用列裁剪(只选择需要的列)
SELECT col1, col2 FROM table
-- 使用合适的文件格式(如Parquet)6.2 Filter优化
sql
-- 将高选择率条件放在前面
WHERE high_selectivity_condition AND low_selectivity_condition
-- 避免在过滤条件中使用复杂函数
WHERE date_column = '2025-09-18' -- 好
WHERE DATE_FORMAT(date_column, 'yyyy-MM-dd') = '2025-09-18' -- 差6.3 Project优化
sql
-- 只选择需要的字段
SELECT col1, col2 FROM table -- 好
SELECT * FROM table -- 差
-- 避免在SELECT中使用复杂计算
SELECT simple_column FROM table -- 好
SELECT complex_calculation(column) FROM table -- 可能影响性能7. 总结
通过两个简单的sql语句,了解了Spark SQL中的三个核心算子:
- Scan:负责从数据源读取数据,支持分区剪枝和列裁剪
- Filter:负责应用WHERE条件过滤数据行,支持谓词下推
- Project:负责选择最终输出的字段,支持表达式计算
希望这种将sql与算子对应起来的讲解方式,能更好的让读者理解,这一篇涉及的不论是sql还是算子都是基础款,后续会一点一点增加复杂程度