目录
[1. 版本查看命令](#1. 版本查看命令)
[2. 问题排查步骤](#2. 问题排查步骤)
[1. 报错信息](#1. 报错信息)
[1.1 CUDA库版本不匹配](#1.1 CUDA库版本不匹配)
[1.2 模型加载错误](#1.2 模型加载错误)
[2. 解决方法](#2. 解决方法)
[2.1 CUDA库版本不匹配](#2.1 CUDA库版本不匹配)
[2.2 模型加载错误](#2.2 模型加载错误)
[cannot load library 'libsndfile.so'](#cannot load library 'libsndfile.so')
[1. 在容器里安装 libsndfile](#1. 在容器里安装 libsndfile)
[2. 用 Conda 安装(如果你用的是 conda 环境)](#2. 用 Conda 安装(如果你用的是 conda 环境))
前言
最近使用tensorflow框架开发一个分类算法,模型训练是在A800上进行的,CUDA版本和tensorflow版本都很高,CUDA版本为12.6,tensorflow版本为2.18.1。但是模型推理需要在另外一台机器上进行,该台机器是3060的显卡,CUDA版本才11.4,tensorflow版本才2.4.0。差距很大,所以存在版本冲突的问题。
1. 版本查看命令
A800机器CUDA信息查看:
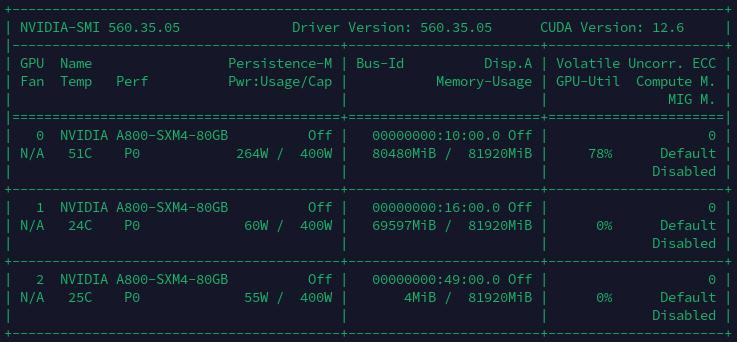
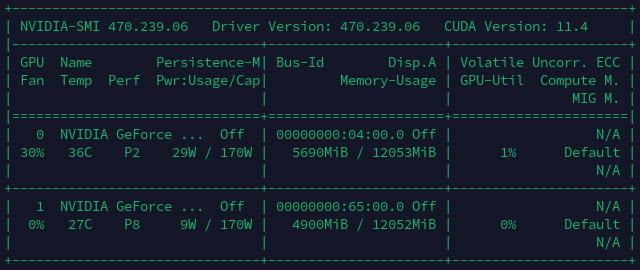
3060机器CUDA信息查看:
可以通过下述命令查看安装的tensorflow和pytorch版本是否有GPU支持。
python
# tensorflow
import tensorflow as tf
print(tf.__version__)
print("是否有GPU支持:", tf.test.is_built_with_cuda()) # True = GPU版本
print("可见GPU列表:", tf.config.list_physical_devices('GPU'))
# pytorch
import torch
print(torch.__version__) # 打印版本号
print("是否支持CUDA:", torch.cuda.is_available()) # True = 可以用GPU
print("CUDA版本:", torch.version.cuda) # 显示编译时的CUDA版本
print("cuDNN版本:", torch.backends.cudnn.version()) # cuDNN版本
print("可见GPU数量:", torch.cuda.device_count())
if torch.cuda.is_available():
print("GPU名称:", torch.cuda.get_device_name(0))2. 问题排查步骤
1. 报错信息
使用在A800上训练好的模型去3060显卡上推理时报错:
2025-09-18 15:21:25.507265: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: :/psd/lib:/usr/local/lib
2025-09-18 15:21:25.507455: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
2025-09-18 15:25:12.687190: I tensorflow/compiler/jit/xla_cpu_device.cc:41] Not creating XLA devices, tf_xla_enable_xla_devices not set
2025-09-18 15:25:12.982810: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcuda.so.1
2025-09-18 15:25:13.701148: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties:
pciBusID: 0000:04:00.0 name: NVIDIA GeForce RTX 3060 computeCapability: 8.6
coreClock: 1.777GHz coreCount: 28 deviceMemorySize: 11.77GiB deviceMemoryBandwidth: 335.32GiB/s
2025-09-18 15:25:13.701980: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 1 with properties:
pciBusID: 0000:65:00.0 name: NVIDIA GeForce RTX 3060 computeCapability: 8.6
coreClock: 1.777GHz coreCount: 28 deviceMemorySize: 11.77GiB deviceMemoryBandwidth: 335.32GiB/s
2025-09-18 15:25:13.702230: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: :/psd/lib:/usr/local/lib
2025-09-18 15:25:13.702467: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcublas.so.11'; dlerror: libcublas.so.11: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: :/psd/lib:/usr/local/lib
2025-09-18 15:25:13.702645: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcublasLt.so.11'; dlerror: libcublasLt.so.11: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: :/psd/lib:/usr/local/lib
2025-09-18 15:25:13.702811: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcufft.so.10'; dlerror: libcufft.so.10: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: :/psd/lib:/usr/local/lib
2025-09-18 15:25:13.702985: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcurand.so.10'; dlerror: libcurand.so.10: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: :/psd/lib:/usr/local/lib
2025-09-18 15:25:13.703150: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcusolver.so.10'; dlerror: libcusolver.so.10: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: :/psd/lib:/usr/local/lib
2025-09-18 15:25:13.703310: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcusparse.so.11'; dlerror: libcusparse.so.11: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: :/psd/lib:/usr/local/lib
2025-09-18 15:25:13.703466: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcudnn.so.8'; dlerror: libcudnn.so.8: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: :/psd/lib:/usr/local/lib
2025-09-18 15:25:13.703491: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1757] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
预测过程中发生错误: ('Unrecognized keyword arguments:', dict_keys('batch_shape'))
上述一共存在两个错误:
1.1 CUDA库版本不匹配
原因1:3060机器上缺少CUDA 11.0相关的库文件(libcudart.so.11.0等)
原因2:未导入相关环境变量
bash
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64:$(pwd)/lib1.2 模型加载错误
('Unrecognized keyword arguments:', dict_keys('batch_shape'))
这个错误的原因是模型在推理的时候遇到了不兼容的参数,和模型训练推理所使用的tensorflow版本不一致有关。
2. 解决方法
2.1 CUDA库版本不匹配
要么重新安装CUDA版本,要么使用云服务器上现成的环境。
2.2 模型加载错误
这个错误通常是因为模型保存时使用了特定版本的TensorFlow参数,而在不同版本中加载时出现兼容性问题。我尝试修改预测函数,以处理不同类型的模型对象,以及训练保存多种不同的权重格式都不能解决问题,最终还是通过安装对应的tensorflow版本解决问题。
由于tensorflow==2.4.0是非常低的版本,CUDA的要求一般是11,而目前大多数机器都是12的版本,我不想为了这个算法单独安装一遍CUDA,所以考虑在云服务器上进行训练。
云服务器:https://www.gpushare.com/store/hire?create=true
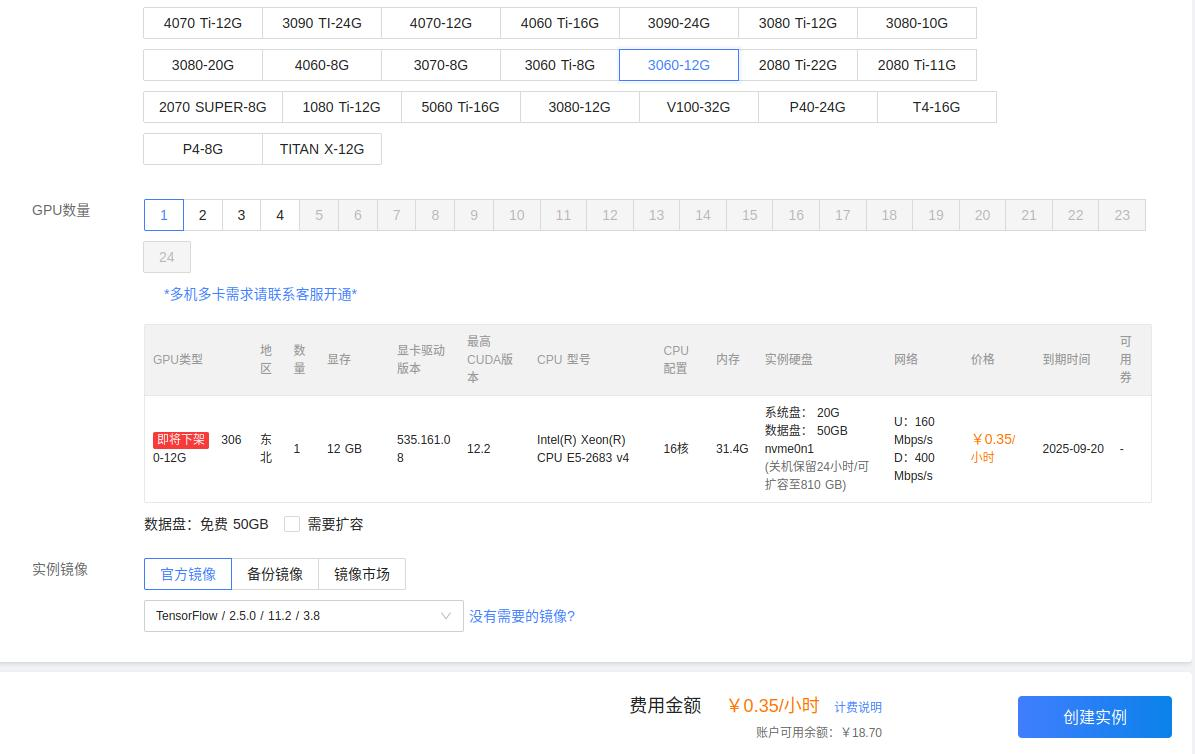
选择了tensorflow==2.5.0版本,我们主要的目的是保持训练和推理的模型参数兼容。
进入之后就可以查看环境:
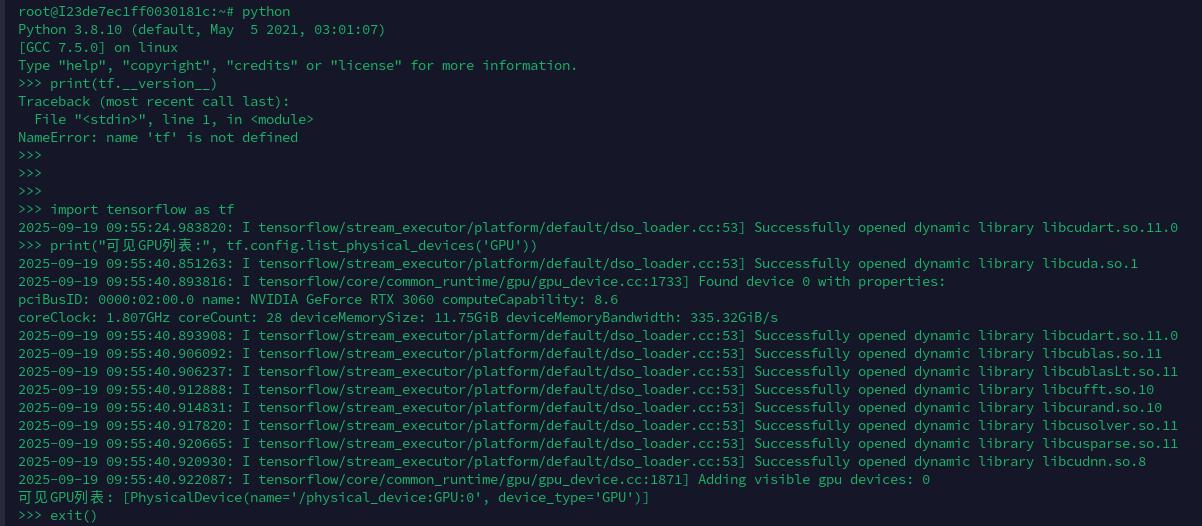
由于我开发的是音频算法,所以还需要安装 librosa 包,当前环境是没有的:
我们使用下述命令安装:
bash
pip install librosa安装完成,可能会出现一些包的版本冲突,这些可以先不管:
这个时候我们训练模型,可能会出现下述报错:
加载音频文件失败 /root/audio_code/dataset_split/train/1/controlled_leak_061_00.wav: cannot load library 'libsndfile.so': libsndfile.so: cannot open shared object file: No such file or directory
cannot load library 'libsndfile.so'
这说明容器(镜像)里缺少 libsndfile 这个库,导致 Python 的 soundfile 包(或者依赖 libsndfile 的其他库)无法加载音频文件。
解决方法有下面几种:
1. 在容器里安装 libsndfile
如果你能进入容器的 shell,直接运行:
bash
apt-get update
apt-get install -y libsndfile1有些环境可能需要开发包:
bash
apt-get install -y libsndfile1-dev2. 用 Conda 安装(如果你用的是 conda 环境)
这是本人所使用的解决方法。
bash
conda install -c conda-forge libsndfile
如果还是找不到 libsndfile.so:
Conda 安装的 libsndfile 默认会放到 .../miniconda3/lib/ 里,而不是系统的 /usr/lib 或 /usr/lib/x86_64-linux-gnu/。
有些情况下 LD_LIBRARY_PATH 没有指向 conda 的 lib 路径,导致 Python 库(比如 soundfile)调用 ctypes.util.find_library("sndfile") 找不到 libsndfile.so。
方法 1:设置环境变量
在运行 Python 之前加上:
python
export LD_LIBRARY_PATH=/usr/local/miniconda3/lib:$LD_LIBRARY_PATH方法 2:软链接 libsndfile.so
确认 conda 里已经有库:
bash
ls /usr/local/miniconda3/lib | grep sndfile通常会有类似 libsndfile.so.1.2.2。
给它建个软链接:
bash
ln -s /usr/local/miniconda3/lib/libsndfile.so.1.2.2 /usr/local/miniconda3/lib/libsndfile.so核心问题是 缺少系统库 libsndfile ,只要在镜像里安装 libsndfile1(或通过 conda 装),就能解决。
- 修改 Dockerfile(如果你要重新构建镜像)
在 Dockerfile 里加上:
bash
RUN apt-get update && apt-get install -y libsndfile1- 检查 Python 包
确保你安装了 soundfile:
bash
pip install soundfilepysoundfile 实际上是 libsndfile 的 Python 绑定,没有系统库会报错。
现在基本上可以正常使用低版本的tensorflow训练模型,同时训练的模型能够正常在3060的机器上跑了。