目录
[1. 了解DMA内部的构成](#1. 了解DMA内部的构成)
[2. DMA2 的 Memory to Memory 的数据流](#2. DMA2 的 Memory to Memory 的数据流)
[3. 通道选择](#3. 通道选择)
[4. 仲裁器](#4. 仲裁器)
[5. FIFO 与 Burst](#5. FIFO 与 Burst)
[FIFO 结构:](#FIFO 结构:)
[Burst 介绍](#Burst 介绍)
[为什么要使用 Burst 防止CPU打断DMA的传输?](#为什么要使用 Burst 防止CPU打断DMA的传输?)
[Burst 的作用:](#Burst 的作用:)
[FIFO 阈值与 Burst 配置](#FIFO 阈值与 Burst 配置)
深入理解 DMA控制器 的内部架构图及其构成
本文会涉及ARM系统与总线架构,对系统架构部分不了解的可以配合下面这篇文章阅读:
ARM处理器总线架构解析:iCode、D-code、S-Bus与总线矩阵
1. 了解DMA内部的构成
-
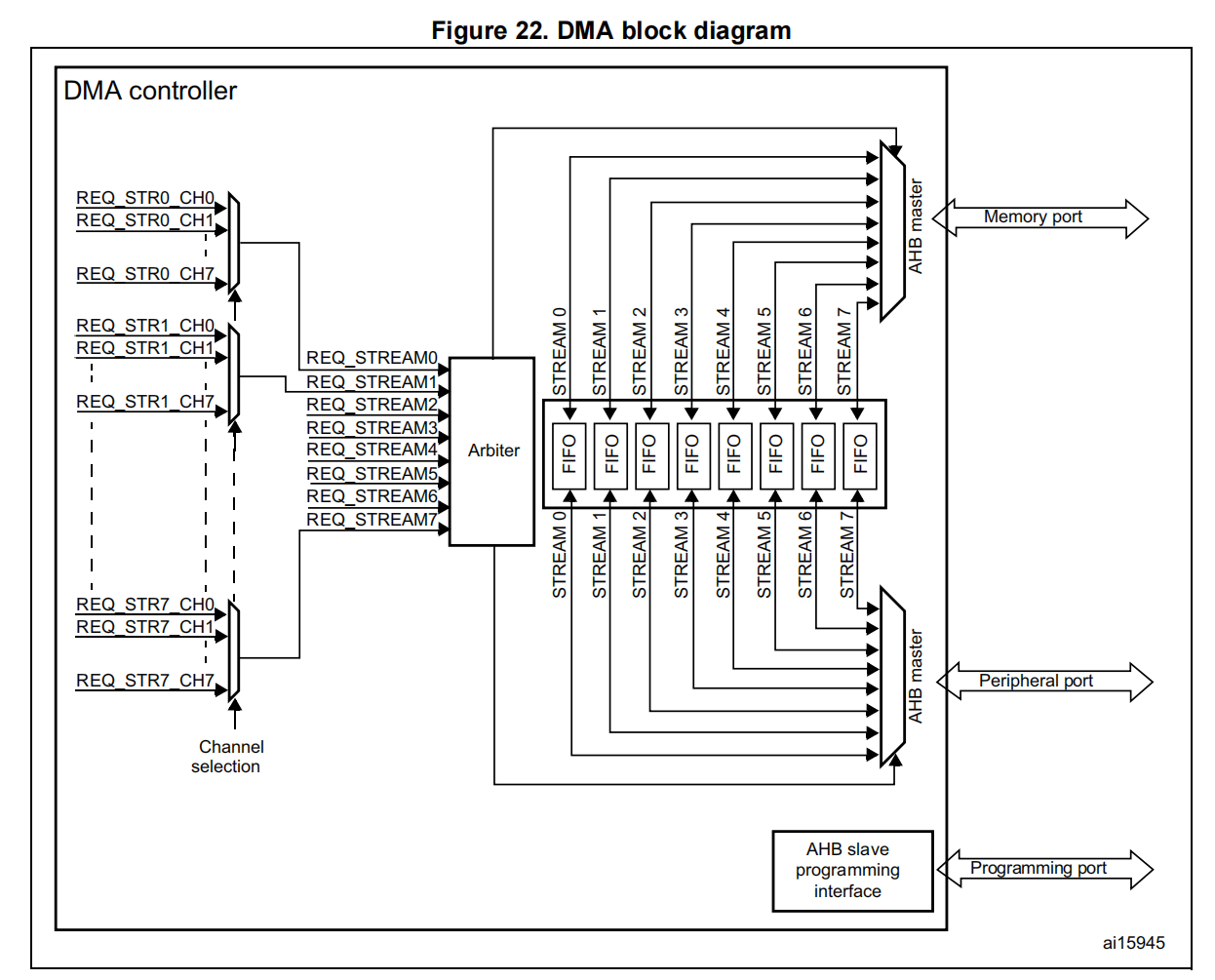
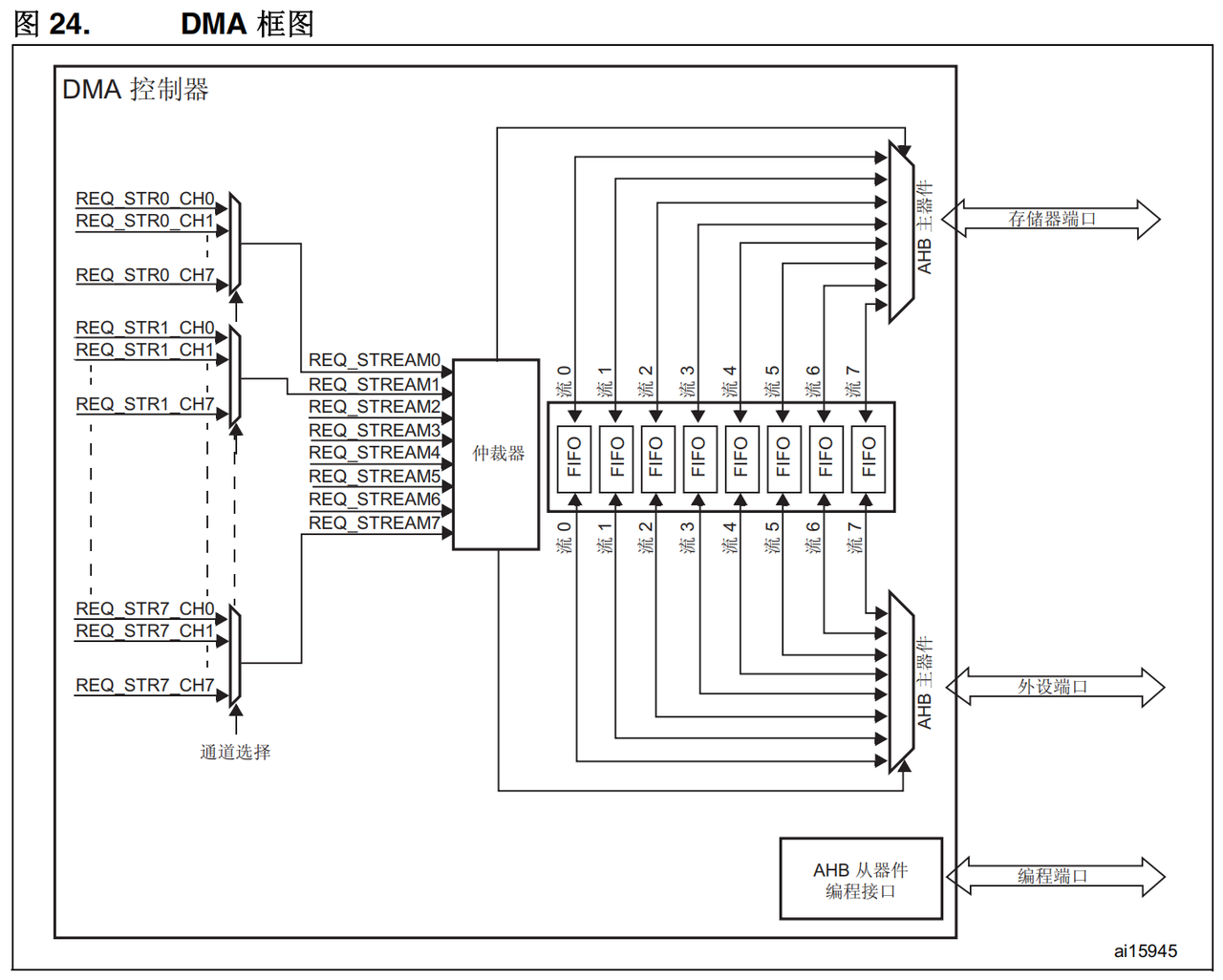
DMA控制器在MCU内部是一个AMBA advcanced high-performance bus (AHB) Master。
-
DMA控制器和AHB有三个接口:
-
一个Slave接口(用于CPU对它进行编程)
-
两个Master接口,允许将DMA去开启两个AHB总线上两个从设备之间的信号通信。
-
-
每个 DMA 都具有8个Streams
-
每个Stream都只能单向传输
-
Steam可被配置的模式
-
从内存到外设
-
从外设到内存
-
从内存到内存
-
-
-
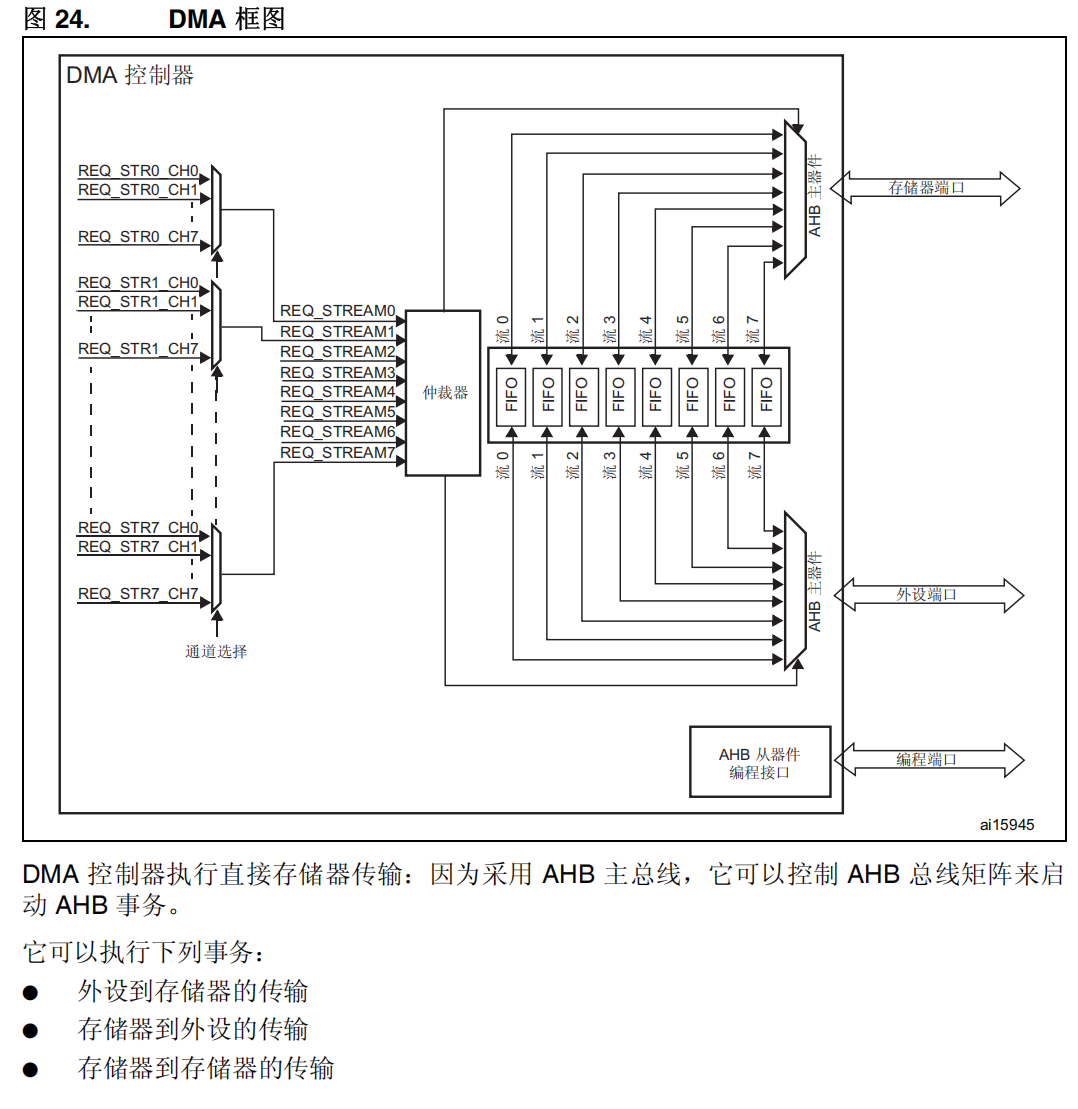
DMA 控制器提供两个 AHB 主(mastrer)端口:AHB 存储器端口 (用于连接存储器)和 AHB 外设端口 (用于连接外设)。但是,要执行存储器到存储器的传输,AHB 外设端口必须也能访问存储器。
-
AHB 从(slave)端口用于对 DMA 控制器进行编程(它仅支持 32 位访问)。
-
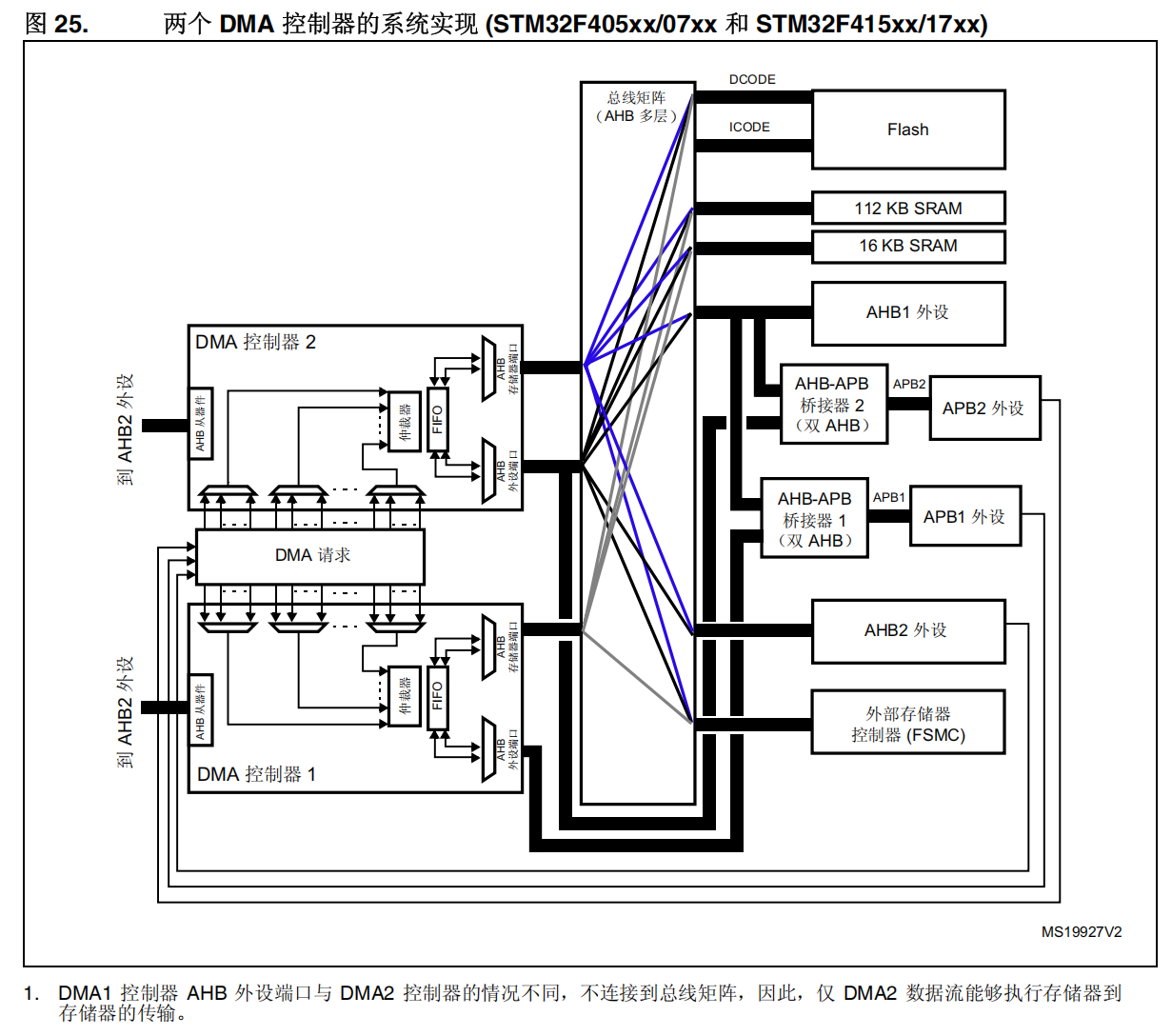
有关两个 DMA 控制器的系统实现,请参见图 25。
2. DMA2 的 Memory to Memory 的数据流
由上面的DMA框图、DMA系统实现框图以及芯片架构图可以知道,STM32F411 的 DMA2 才能实现 Memory to Memory 操作:
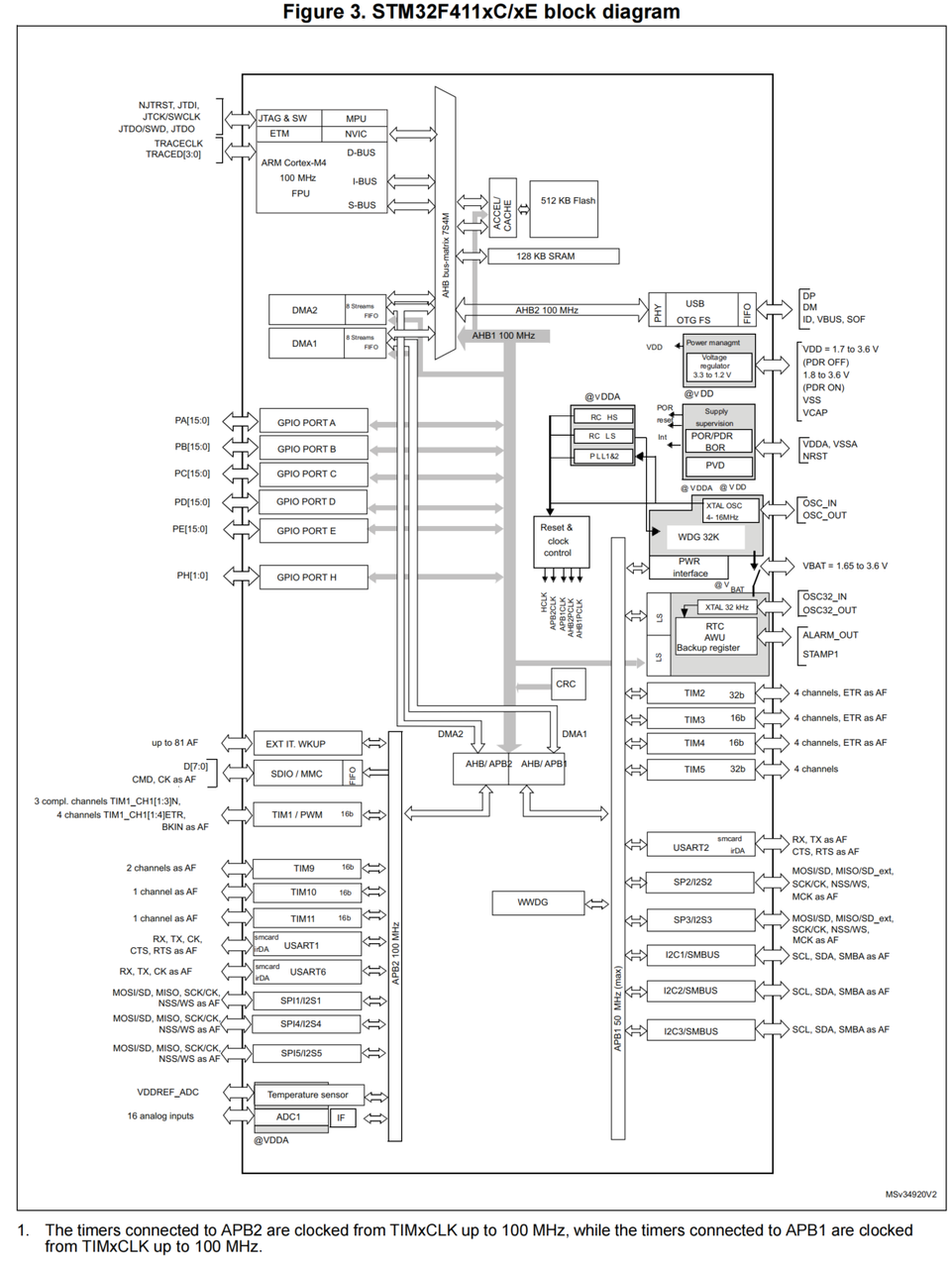
DMA上的数据流:
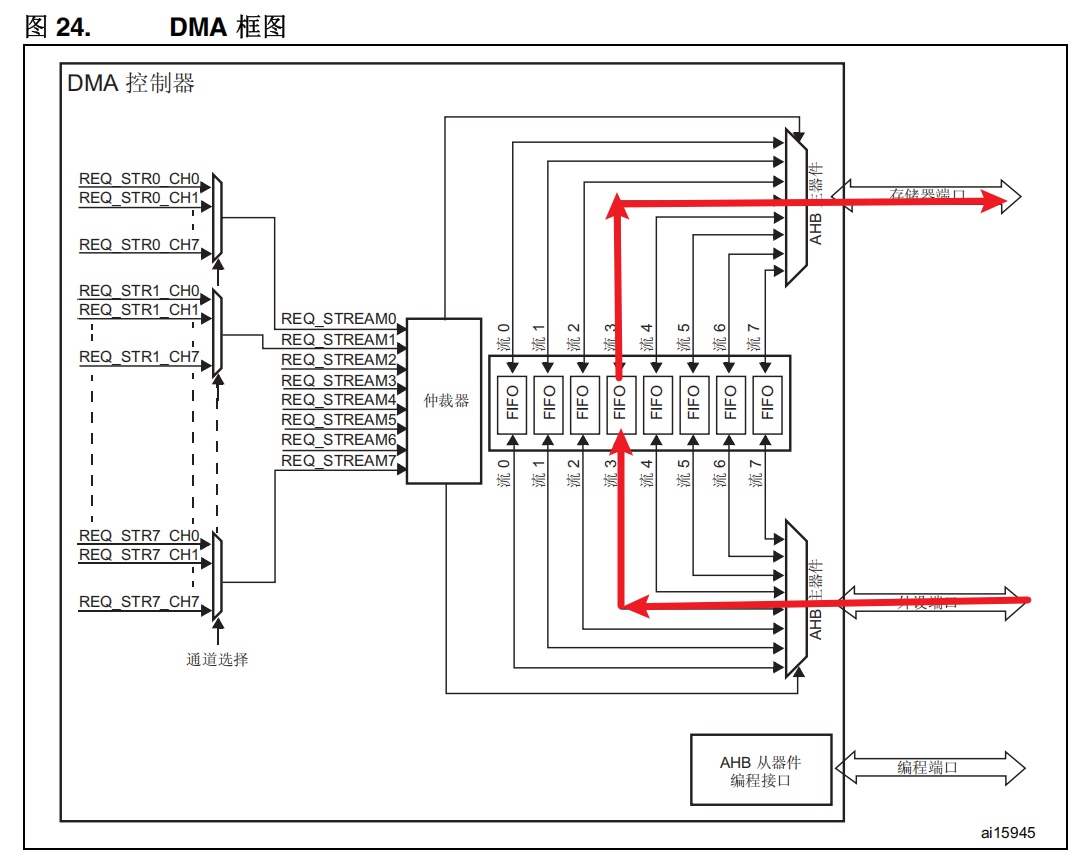
总线矩阵上的数据流:
因为DMA流的进和出是同时进行的(总线被占用时除外,数据会暂存在 FIFO 中),所以无法像下图那样同时在一条总线上进行数据的进和出,这样会导致总线被阻塞,同一时间只能进或只能出:
DMA不能这么走:
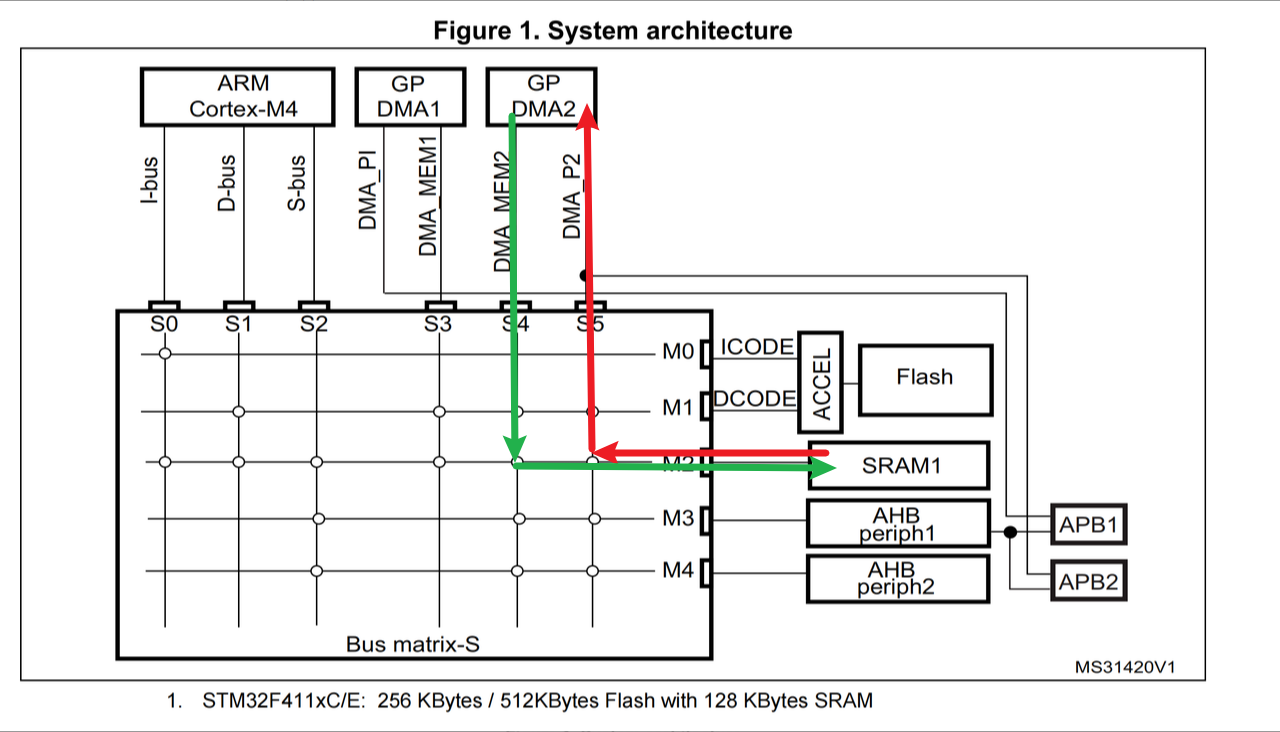
在进行 Memory to Memory 的数据搬运时,SRAM 会被看作 AHB 总线上挂载的一个外设,然后从该外设中取数据,然后从总线矩阵上搬运数据直接到SRAM:
总线矩阵上正确的数据流:
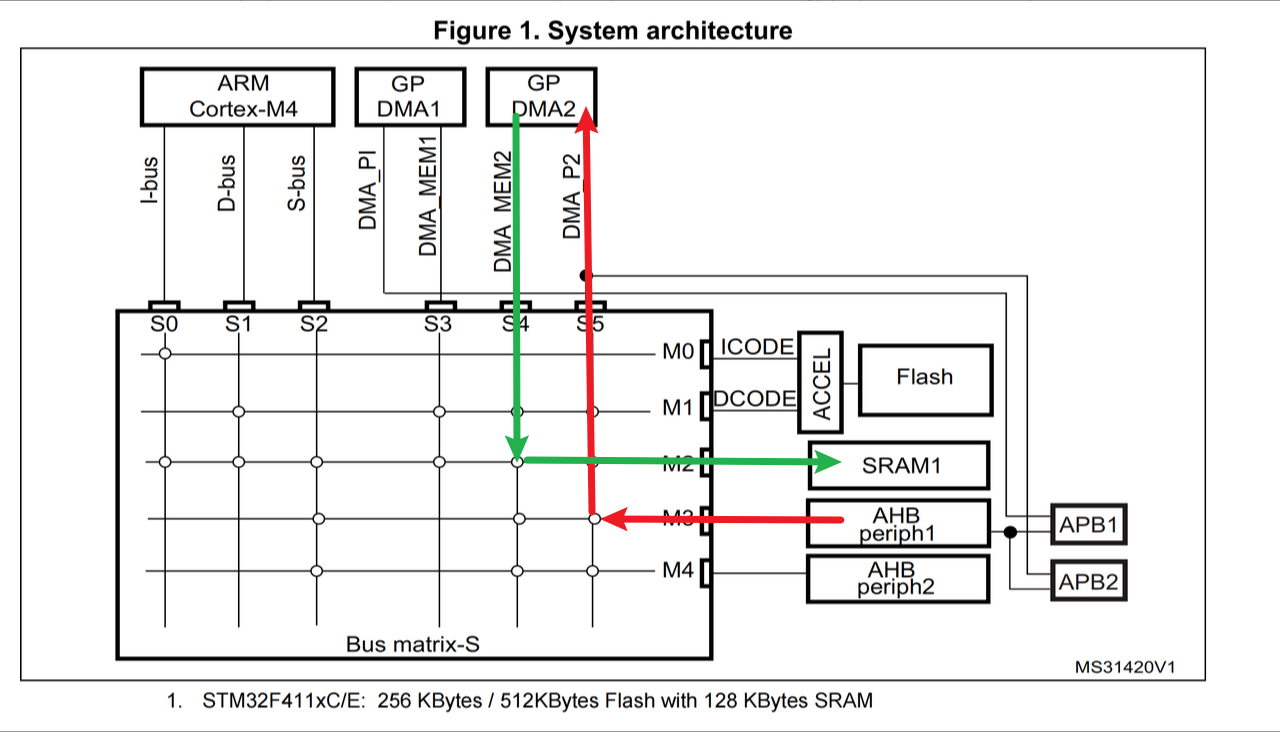
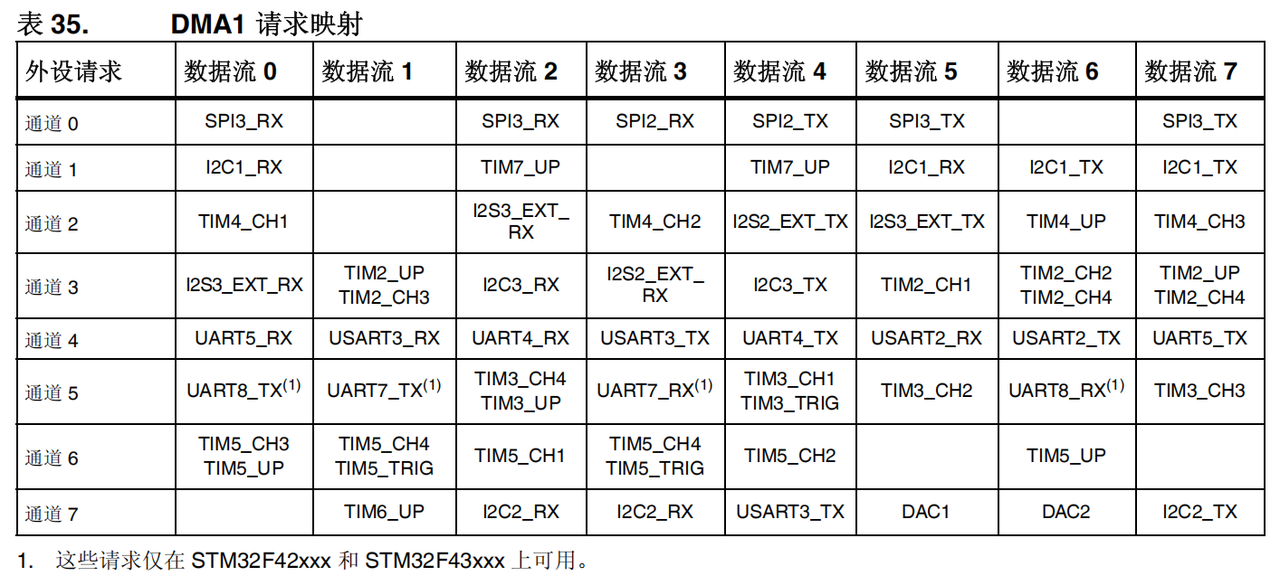
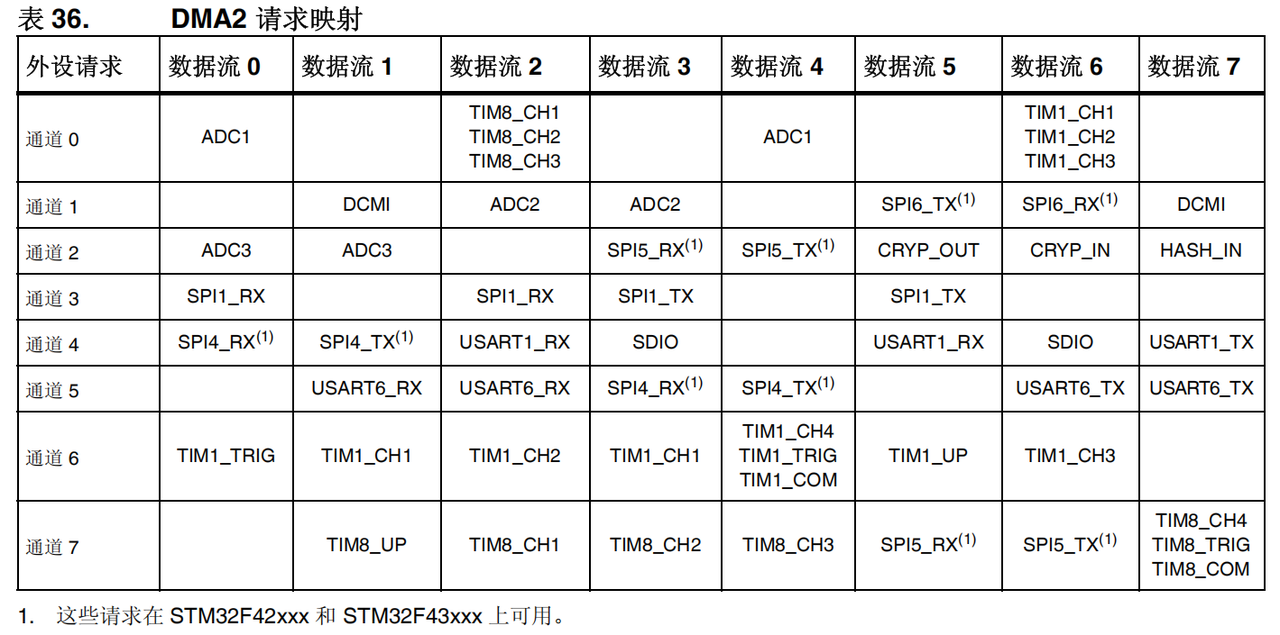
3. 通道选择
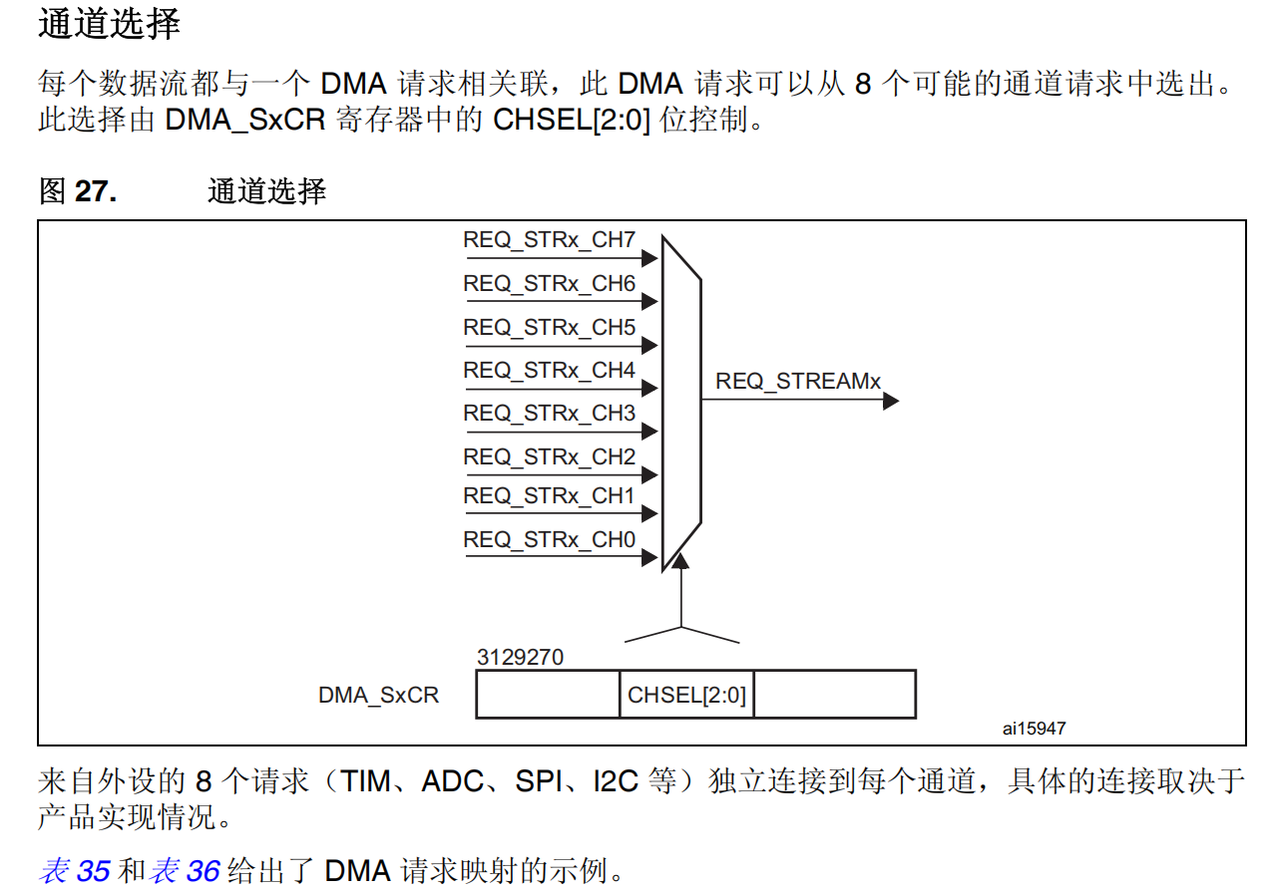
- 需要注意的是,上图中8个通道都可以产生 DMA 请求,但只会有一个触发 DMA stream 搬运,也就是说我们同一时间只能配置一个 channel ,不能同时配置两个 channel。
4. 仲裁器
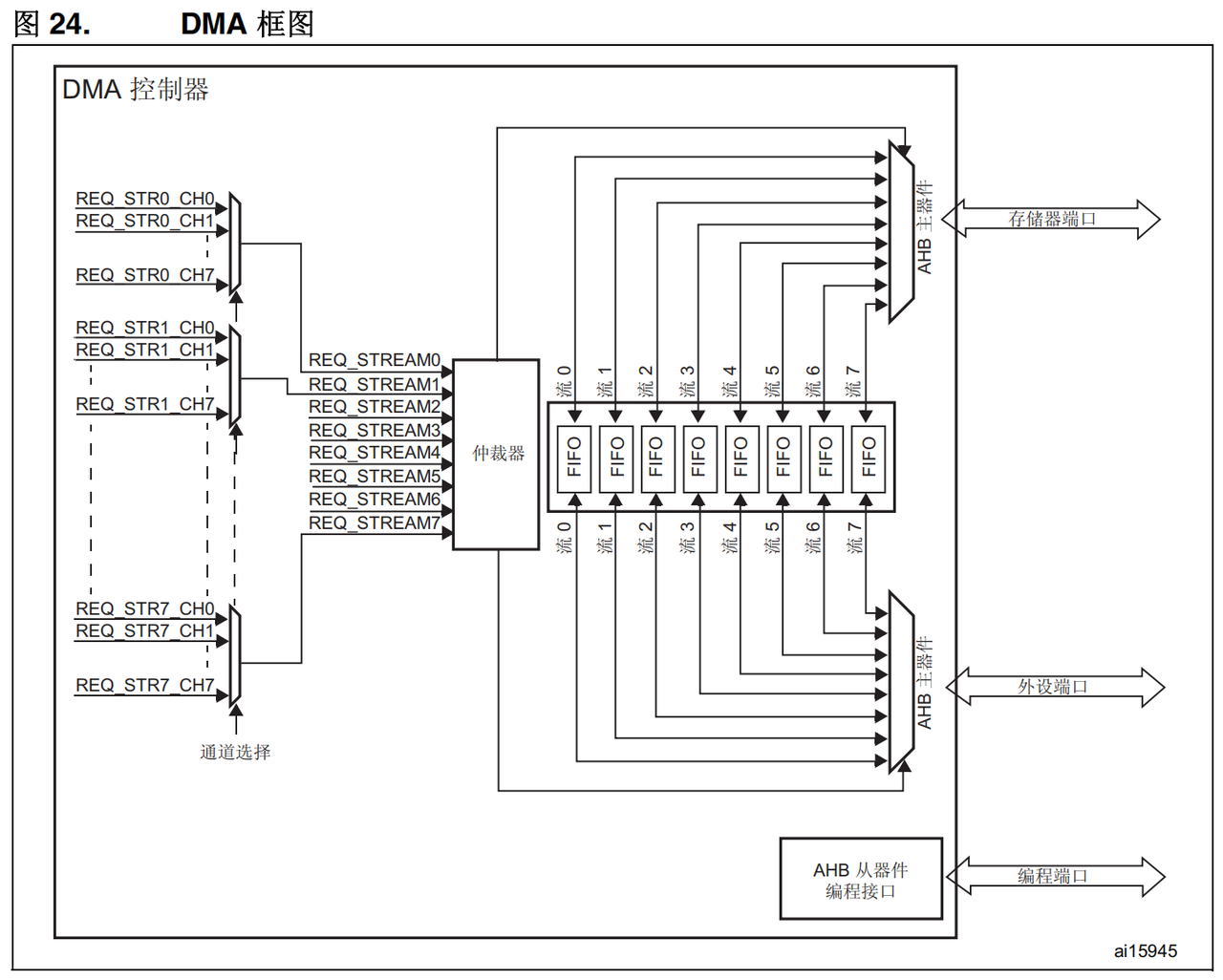
- 同一时刻下,DMA 的 8 条 stream 只能有一条 stream 在搬运数据,但是可能会有两个 stream 同时发来DMA请求,这个时候就要靠我们的仲裁器来决定谁(即哪个stream)先搬运数据了。
仲裁器 机制:

5. FIFO 与 Burst
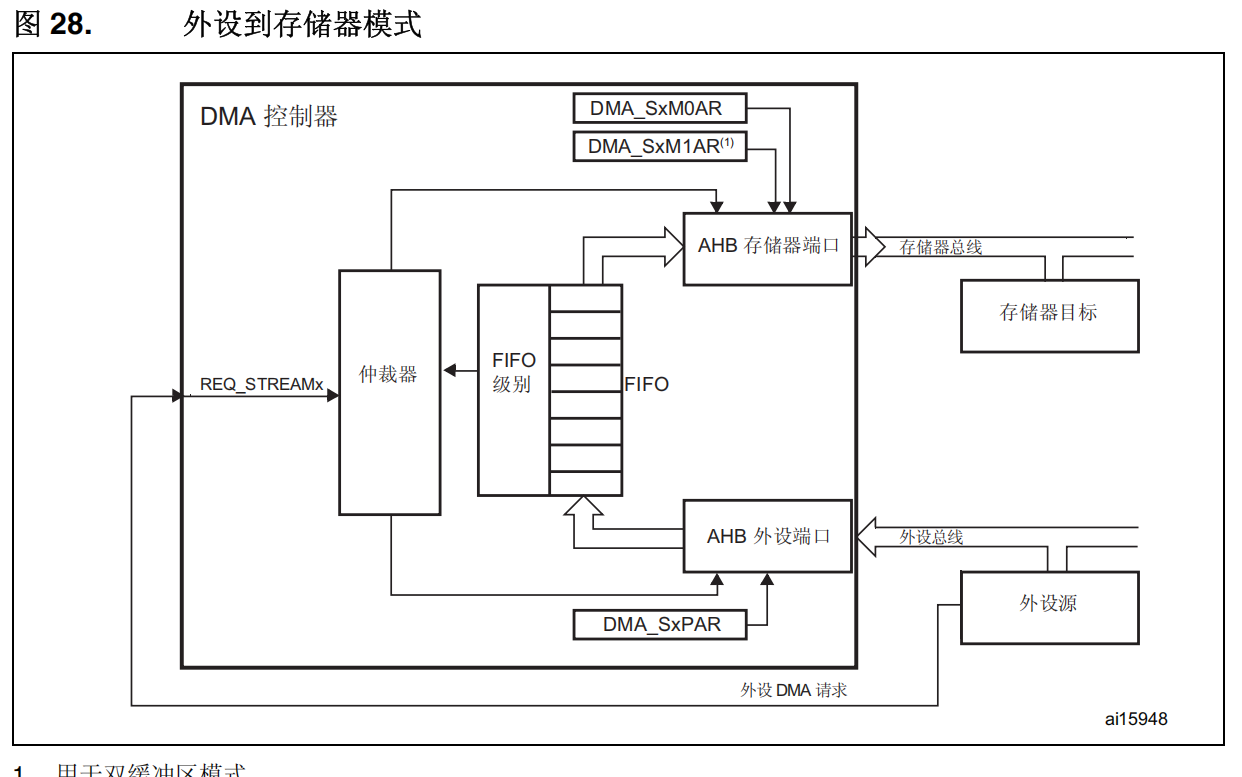
FIFO介绍
-
我们知道,AHB总线矩阵是32位的,一次可以传输 4 个字节(即一个字)大小的数据。
-
假设DMA正在从外设往存储器搬运数据,来一个字节数据我就搬运一次,需要知道,每次搬运都要打断总线上(DMA要走的那条线路)现有的数据访问,这样的DMA效率是很低的,FIFO很好的解决了这个问题,每次一个字节的数据来了,先把他存在FIFO里,然后等积攒了 4 个字节之后再搬运到存储器中,这样同样是占用总线一个周期,却搬运了 4 个字节的数据。
-
FIFO 的重要作用就是增加系统带宽的利用。这样 DMA 就会更少打断 CPU。
-
FIFO 的大小可以自己设置,这里具体要看数据手册(STM32F411 FIFO 大小为 16 字节)。
FIFO 结构:
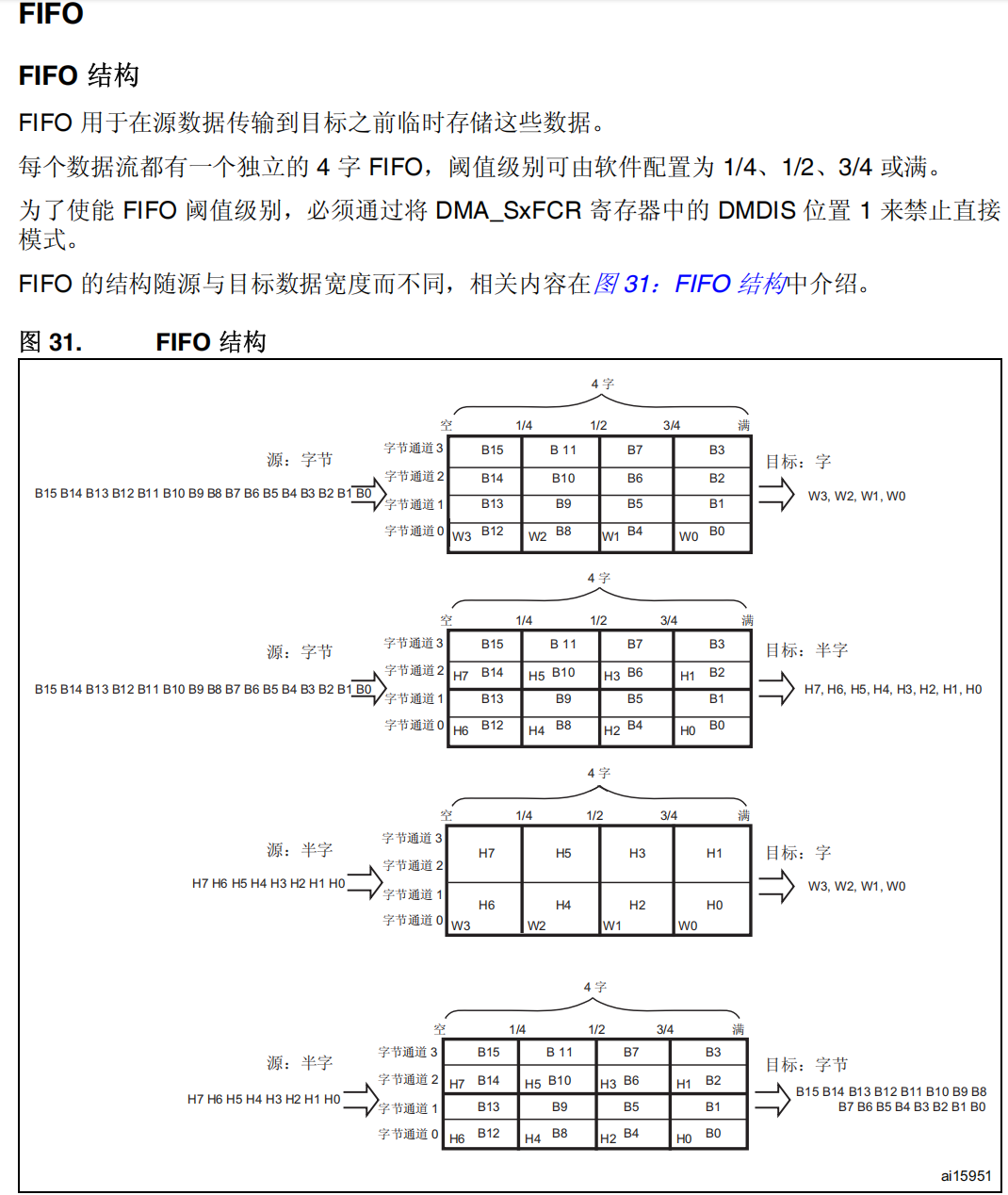
FIFO 的作用:
-
减少AHB带宽的占用,减少AHB总线的仲裁,让CPU能够在AHB总线上占用更大的带宽而不需要和DMA经常竞争总线。(DMA接收数据时可以旁路AHB总线)
-
减少溢出,在需要动态扩展内存时,DMA会暂存数据进入FIFO,给CPU执行动态扩展内存争取时间,防止溢出。
-
DMA多路Stream仲裁时,FIFO可以多路Stream缓冲,极大提高并发性。
Burst 介绍
(注:下文配图中的"突发"就是 Burst )


DMA控制器可以生成单次传输或增量突发传输,传输的节拍数为4、8或16。(这里的"节拍"的意思是以多少次传输为一组)
为了确保数据一致性,构成突发传输的每组传输都是不可分割的:AHB 传输被锁定,AHB总线矩阵的 仲裁器 在突发传输序列期间不会撤销 DMA 主设备的授权。即: CPU 在此次DMA传递完成前无法抢占AHB总线,CPU无法打断DMA传输。
举个栗子:
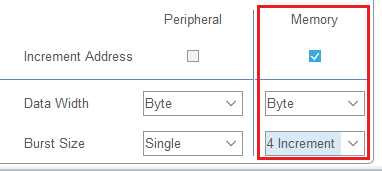
我们以上面这张图为例子讲解:Burst 会将 Burst Size * Data Width 字节的数据编为"一组",每组的传输是不可分割的,CPU无法打断。
上图的意思就是:DMA每次往 Memory 搬运 1 个 Byte 的数据,以每 4 次搬运为一组,每组的这 4 次搬运中间不能被CPU打断。
再来一个例子:
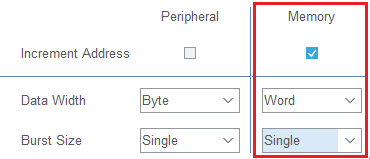
上图的意思是:DMA每次往 Memory 搬运 1 个 Word 的数据,Single 传输,每一次传输都视为一个"节拍",此时每次传输之间CPU都可以打断DMA的传输。
再再来一个例子:
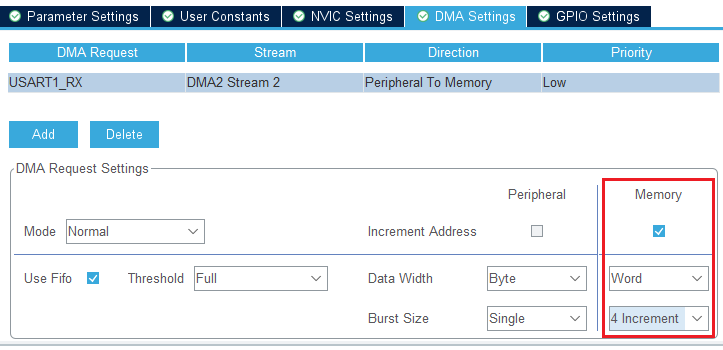
假设我们此时在用串口DMA接收,我们将FIFO配置为 "full",即 16 个字节。如果我们想要DMA往 Memory 搬运 16 字节的数据不被CPU打断,那我们可以按上面这种方法来配置,即DMA每次搬运 1 个 Word 的数据(即 4 个字节),以 4 次搬运为一个"节拍"。
或者我们也可以这样:DMA 每次搬运 1 个 Byte 的数据,以 16 次搬运为一个"节拍"。(但是这样DMA没有高效利用总线矩阵的带宽,降低了效率)
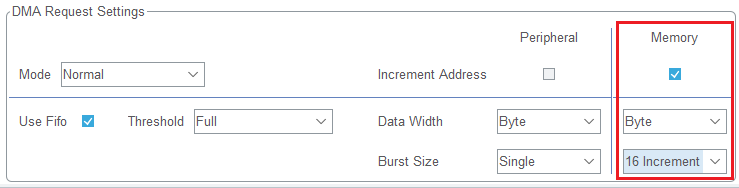
为什么要使用 Burst 防止CPU打断DMA的传输?
如果我们不使用 Burst 防止CPU打断DMA的传输,就有可能发生这样的情况:
本来 DMA 要从外设上搬运 16 个字节的数据到 SRAM,CPU 读取 SRAM 做处理,但是DMA只搬运了 12 个字节,CPU 就过来搬运数据了,DMA 只能让出总线,而 CPU 读到的 16 个字节中的后 4 个字节是随机值:
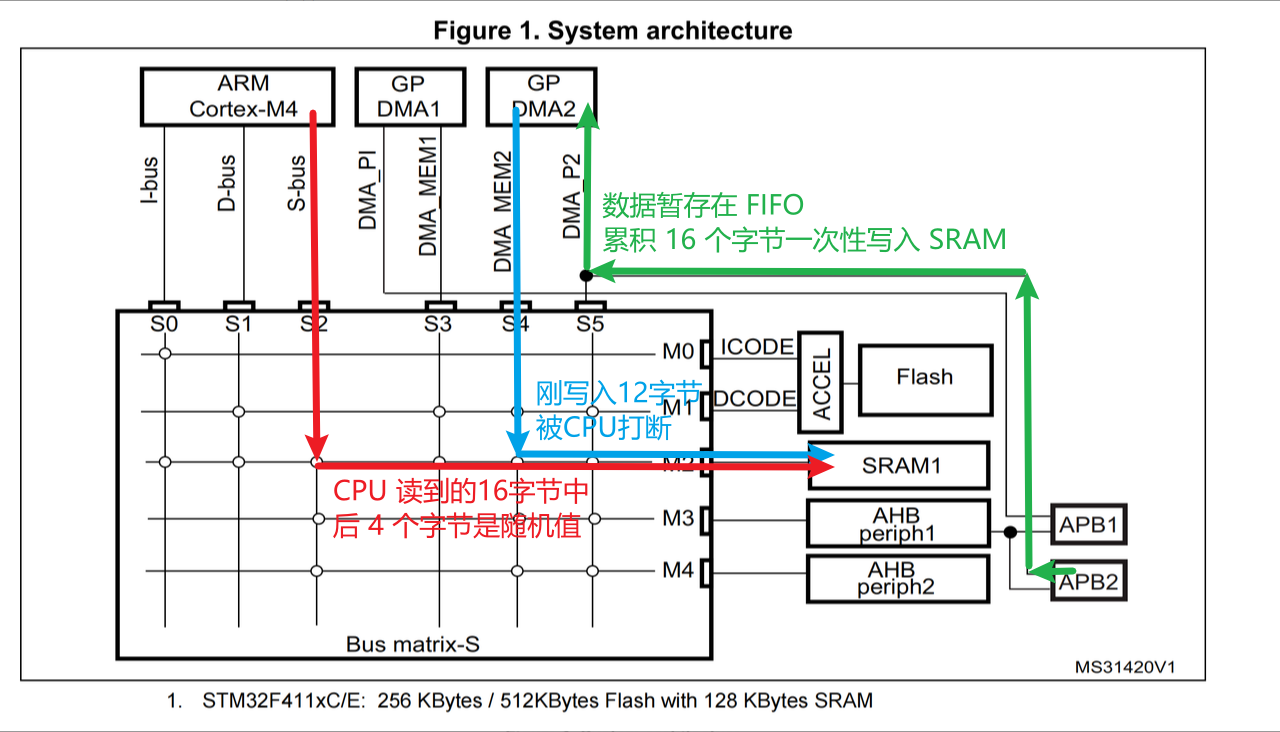
Burst 的作用:
-
Burst 能够让 DMA 对 AHB "独占访问",通过 Burst 完成了 DMA 传输的"原子操作",保护了数据完整性。
-
可以通过Burst进行多个寄存器的同时修改,在M2P时同时配置多个定时器
TIM DMA burst 输出变频 PWM 波形 - STM32团队 ST意法半导体中文论坛
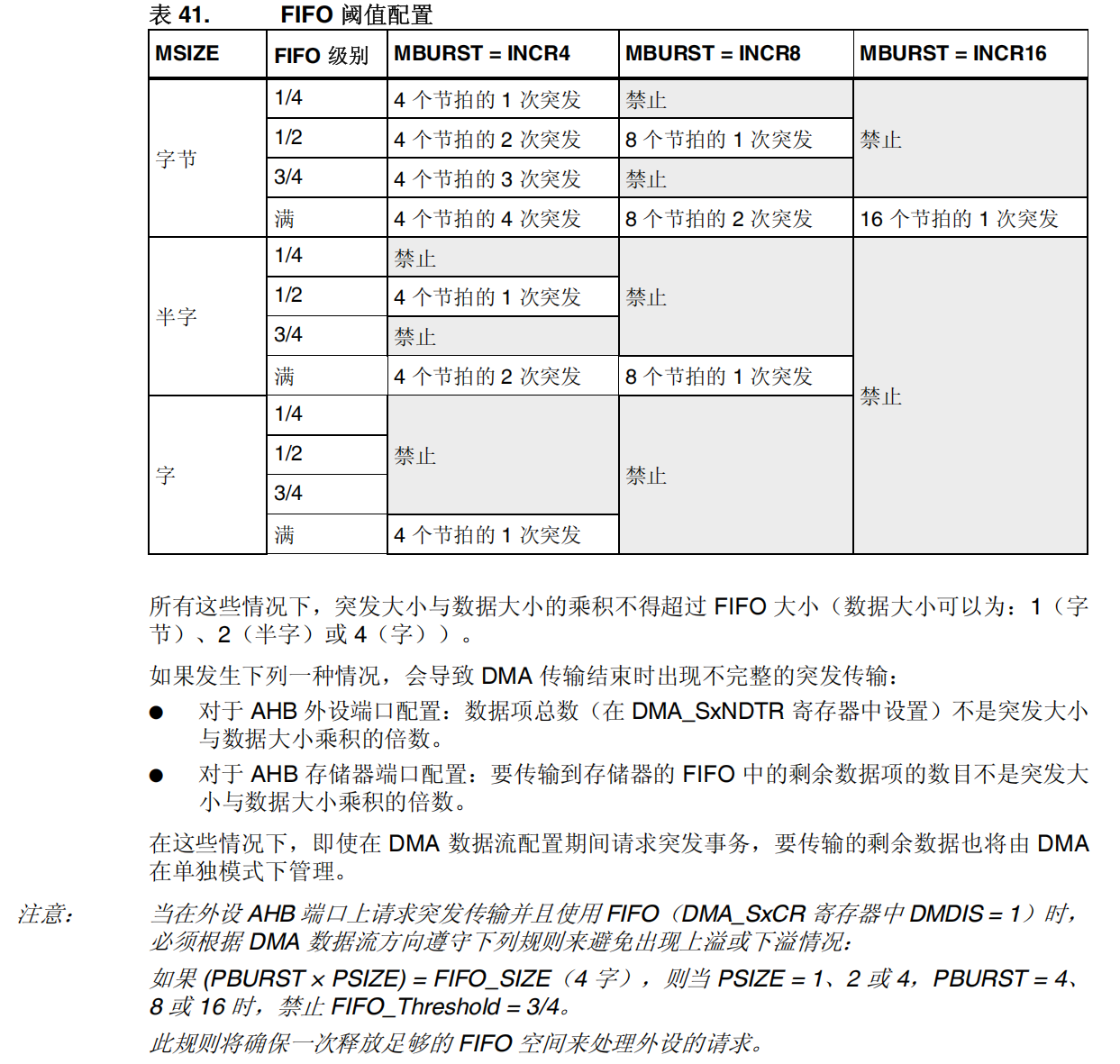
FIFO 阈值与 Burst 配置
选择 FIFO 阈值(DMA_SxFCR 寄存器的位 FTH1:0)和存储器突发大小(DMA_SxCR 寄存器的 MBURST1:0 位)时需要小心:FIFO 阈值指向的内容必须与整数个存储器突发传输完全匹配。如果不是这样,当使能数据流时将生成一个 FIFO 错误(DMA_HISR 或 DMA_LISR 寄存器的标志 FEIFx),然后将自动禁止数据流。允许的和禁止的配置在表 41:FIFO 阈值配置中介绍。