本文介绍了企业级智能体的应用场景和搭建方法。智能体通过整合知识库、流程编排和大模型能力,可应用于知识问答、业务办理、内容润色和线索挖掘等场景。重点阐述了知识库建设(结构化/非结构化)、插件开发、流程节点设计等核心技术,并以保险系统运营助手为例,展示了从知识库构建到智能体部署的全流程。文章还提供了基于"扣子"平台的搭建实战案例,演示了FAQ问答和文档分析两种典型场景的实现效果。
一、应用场景
- 知识问答场景:适用于已有大量业务知识沉淀的业务场景,可为此类业务提供非技术也可以主导的管能体方案,包括知识库的维护和在智能体中的应用;
- 业务办理场景:适用于用户进线办理业务的场景,使用插件接口打通智能体和业务系统后,智能可利用大模型的规划、推理等能力,帮用户完成业务办理
- 内容润色场景:适用于邮件总结、公文错别字排查、PPT大岗文案等场景,可为办公场景提供多和提效工具。
- 线索挖掘场景,适用于需要从客户沟通细节发现商机的业务场景,在业务人员或人工坐席遗漏的情况下,仍可根据具体产品和客户信息/发言,发现商机线索,提供相关建议。
二、智能体介绍
1、智能体
智能体是大模型的企业落地应用,通过引入个性化的知识库、流程编排、LLM提示词工程、插件等,将专业化的大型任务进行更精细的拆分,更加符合个性化需求,充分利用大模型能力解决专业性和针对性更强、规模更大的和复杂度更高的问题。
单纯的提示词工程更适用于解决通用化的问题,面向C端。
通过引入知识库和LLM,智能体广泛应用于智能问答助手、办公助手等;通过插件引入和MCP开发,能够将智能体的流程节点关联到项目代码,实现业务流程的智能化和高效化。
2、知识库
(1)传统大模型适用更加通用的问题,回答结果具有普适性和联想性。引入专业知识库并加入限制后,智能体的搜集和分析材料基于知识库,可以让智能体的解决方案更加专业化,减少联想胡乱回答的情况。
(2)知识库的搭建主要是结构化知识和非结构化知识。
结构化知识通常用于FAQ咨询问答助手,采用excel的形式,录入标准问答,LLM准确精细度和匹配度设置的较高。经过语义分析和知识库分析后,输出答案。
非结构化的知识主要通过文档的形式,涉及到切片和最小片段设置,LLM准确精细度和匹配度设置的较低,能够更加专业化的提取、总结、分析。
为了提高精确度,非结构化的知识,可以经过人工进行处理,比如markdown进行结构化处理,以及对知识文档进行人工分类标签的标注即数据打标,或者将知识库以图数据库的形式存储,明确节点 (实体)和边(关联关系)。
(3)知识库节点的输出,通常配合LLM节点的参数,将分析到的内容作为提示词工程prompt的背景知识,加入任务要求和用户输入,调用大模型做出回答。
3、插件
插件相当于api接口,扩展智能体的能力。可以使用已有的插件,与其他应用软件和通用功能的软件进行连接,比如抖音插件、头条插件、图片转文字插件。也可以将智能体的节点连入到项目的接口中,进行业务流程智能化开发,通常采用MCP插件。
4、流程编排
智能体流程的节点包括普通的流程节点和特色节点。普通流程节点包括 起始节点、条件判断分支节点、循环节点、结束节点等;特色节点主要是 知识库节点、LLM节点(提示词工程)、代码节点(处理输出内容,如知识库常返回json形式的,需要进行提取处理,再输入到下一节点)、MCP节点(连接代码接口、数据库等)、插件节点等。
智能体编排好后,还可以将智能体作为一个节点,进行多智能体的流程编排,进行大型项目工程的实现。
5、LLM节点
通常上一节点是知识库节点。通过采用提示词工程prompt进行标准化提问(LangGpt、CRISPE等),设置精确度、回文数、最大切片等定义精确度。
5、搭建思路
- 构建问题所需知识库,最好处理成结构化知识,采用表格和markdown等形式。
- 构建迭代后的最佳提示词prompt
- 将问题按照层级拆分,规模大和工程性强的拆分成多个智能体。一个智能体是一个流程,将一个流程的问题继续拆分成小问题,小流程查分成不同分支,引入所需的知识库节点、LLM节点、代码节点、分支节点、插入节点等。输出节点可用于调试观测。
三、智能体节点示例
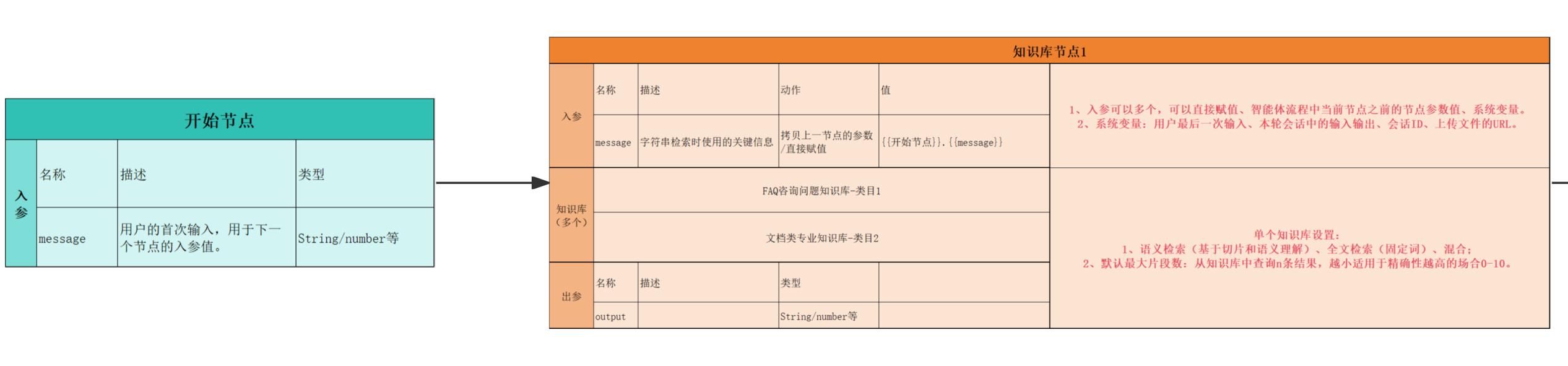
1、开始节点
用于用户输入,可以设置欢迎语,也用于后续节点的入参
|------------|---------|----------------------|----------------|
| 开始节点 ||||
| 入参 | 名称 | 描述 | 类型 |
| 入参 | message | 用户的首次输入,用于下一个节点的入参值。 | String/number等 |
2、知识库节点
搭配结构化和非结构化知识库,结构化知识库如果找不到,再分支到非结构化,用大模型通用能力处理
|---------|---------|---------------|-----------------|-----------------------|-----------------------------------------------------------------------------------------------------------|
| 知识库节点1 ||||||
| 入参 | 名称 | 描述 | 动作 | 值 | 1、入参可以多个,可以直接赋值、智能体流程中当前节点之前的节点参数值、系统变量。 2、系统变量:用户最后一次输入、本轮会话中的输入输出、会话ID、上传文件的URL。 |
| 入参 | message | 字符串检索时使用的关键信息 | 拷贝上一节点的参数/直接赋值 | {{开始节点}}. {{message}} | 1、入参可以多个,可以直接赋值、智能体流程中当前节点之前的节点参数值、系统变量。 2、系统变量:用户最后一次输入、本轮会话中的输入输出、会话ID、上传文件的URL。 |
| 知识库(多个) | FAQ咨询问题知识库-类目1 |||| 单个知识库设置: 1、语义检索(基于切片和语义理解)、全文检索(固定词)、混合; 2、默认最大片段数:从知识库中查询n条结果,越小适用于精确性越高的场合0-10。 |
| 知识库(多个) | 文档类专业知识库-类目2 |||| 单个知识库设置: 1、语义检索(基于切片和语义理解)、全文检索(固定词)、混合; 2、默认最大片段数:从知识库中查询n条结果,越小适用于精确性越高的场合0-10。 |
| 出参 | 名称 | 描述 | 类型 | | 单个知识库设置: 1、语义检索(基于切片和语义理解)、全文检索(固定词)、混合; 2、默认最大片段数:从知识库中查询n条结果,越小适用于精确性越高的场合0-10。 |
| 出参 | output | | String/ number等 | | 单个知识库设置: 1、语义检索(基于切片和语义理解)、全文检索(固定词)、混合; 2、默认最大片段数:从知识库中查询n条结果,越小适用于精确性越高的场合0-10。 |
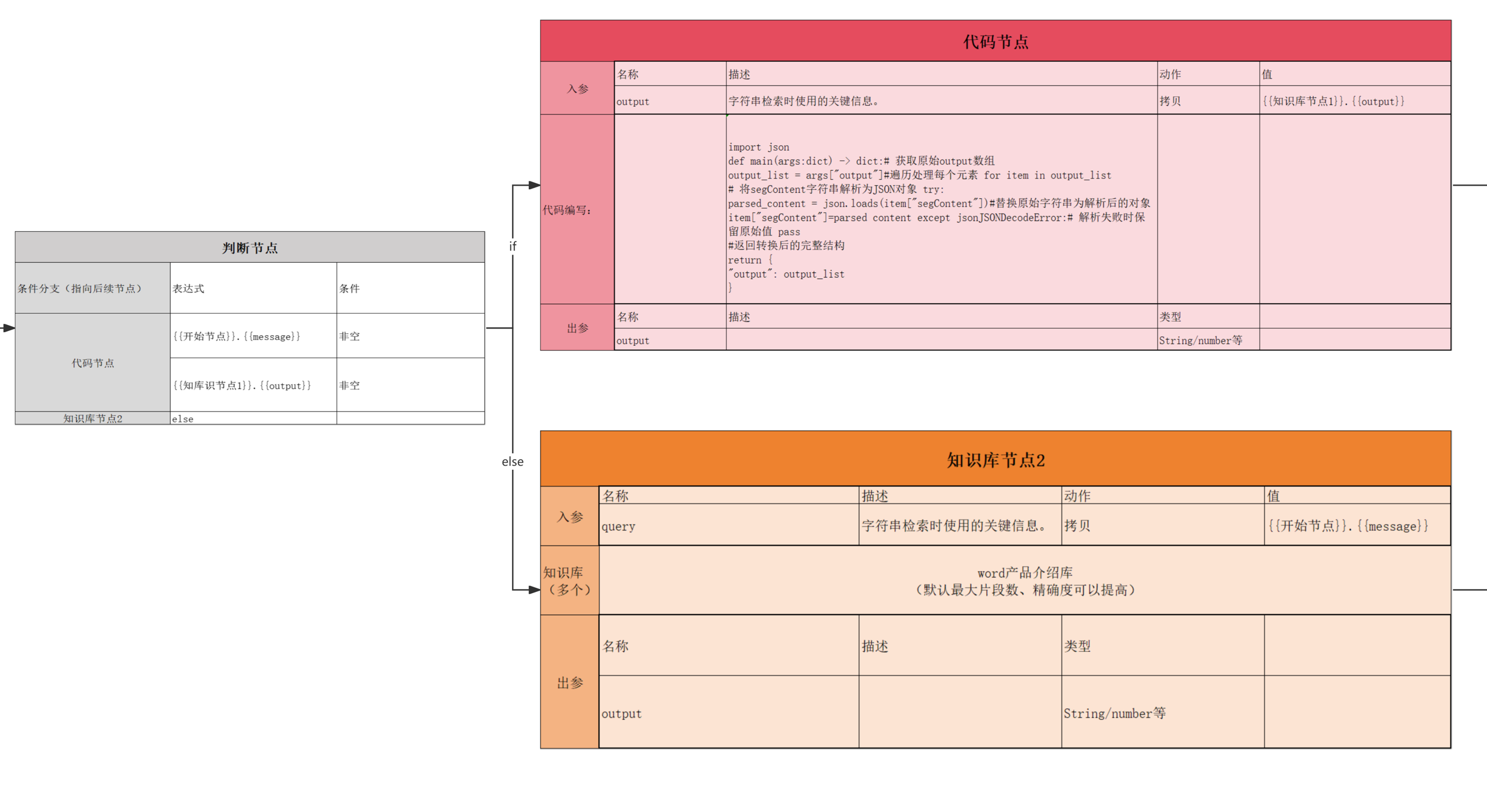
3、判断节点
判断条件的入参为上一分支的出参
|--------------|-----------------------|----|
| 判断节点 |||
| 条件分支(指向后续节点) | 表达式 | 条件 |
| 代码节点 | {{开始节点}}.{{message}} | 非空 |
| 代码节点 | {{知库识节点1}}.{{output}} | 非空 |
| 知识库节点2 | else | |
4、代码节点
通常用于处理数据
|-------|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------|-----------------------|
| 代码节点 |||||
| 入参 | 名称 | 描述 | 动作 | 值 |
| 入参 | output | 字符串检索时使用的关键信息。 | 拷贝 | {{知识库节点1}}.{{output}} |
| 代码编写: | | import json def main(args:dict) -> dict:# 获取原始output数组 output_list = args"output"#遍历处理每个元素 for item in output_list # 将segContent字符串解析为JSON对象 try: parsed_content = json.loads(item"segContent")#替换原始字符串为解析后的对象 item"segContent"=parsed content except jsonJSONDecodeError:# 解析失败时保留原始值 pass #返回转换后的完整结构 return { "output": output_list } | | |
| 出参 | 名称 | 描述 | 类型 | |
| 出参 | output | | String/number等 | |
5、LLM节点
|---------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------|----------------|-----------------------|
| LLM节点 |||||
| 入参 | 名称 | 描述 | 动作 | 值 |
| 入参 | message | 字符串检索时使用的关键信息。 | 拷贝 | {{系统变量}}.{{用户最后一次输入}} |
| 入参 | output | 字符串检索时使用的关键信息。 | 拷贝 | {{知识库节点2}}.{{output}} |
| 模型选择 | QWEN/DS | | | |
| 提示词 | ##角色 你是一个专业的保险运营知识问答助手,请根据背景知识,回答用户输入的问题。要求简洁 背景知识:{{output}} 用户输入的问题:{{message}} ##任务: 根据用户提供的背景知识,回答用户提出的问题。背景知识如果没有相关项目,请输出,我正在努力学习中 ##技能: 准确提取背景信息用专业的语言表达 保持回答的逻辑性和一致性 ##限制 1.回等必须基于提供的背景知识,使用清断规范的中文避免使用模糊表述,禁止添加如识库外的内容 2.如果没有相关信息,请输出:我正在努力学习中 输出格式 ###"问题: {{message}}" --- 如果涉及系统操作,列出系统登录链接、权限申请通道链接如果不涉及系统操作,就按语义和背景知识回答. --- | | | |
| 用户输入 | {{message}} | | | |
| 携带近n轮输入 | | | | |
| 是否输出 | | | | |
| 出参 | 名称 | 描述 | 类型 | |
| 出参 | output | | String/number等 | |
四、智能体搭建实战
1、搭建方法和思路
以智能问答运营助手为例,如图是一个面向客户前台的智能保险系统运营问答助手
(1)知识库
FAQ:标准问题答案库,excel形式的结构性知识库,精确度匹配度参数设置较高,随意性参数设置低。
文档知识库:包含基本产品介绍、系统介绍、业务流程介绍,word文档形式,精确度匹配度参数设置相对FAQ要低,随意性参数设置相对FAQ高。
(2)LLM节点
将知识库检索分析后的输出设置为提示词的#背景#,加入#用户输入,采用LangGpt结构。当FAQ不能检索出标准问答时,调用文档知识库,结合prompt提示词工程,分析给出解答
(3)代码节点
处理输出,知识库输出通常为json形式,需要进行清理提取
简要关键流程和配置点如下
因图片像素限制下面为局部放大的:
(左部)
(中部)
(右部)

2、搭建实战
本文使用扣子平台做一个简单的测试智能体:
创建操作流程:
资源库->新建知识库
资源库->新建工作流
创建->智能体->引入创建好的工作流节点,再加上输入输出节点
发布智能体
(1)知识库创建
知识库如下:
a).FAQ:
|--------|-----------------|------------------------------|
| 常见问题代码 | 问题描述 | 标准答案 |
| A001 | 销售:提示业务员无销售资格 | 1、检查业务员机构片区权限配置; 2、是否完成相关考核 |
| B001 | 投保:投保失败,显示重复投保 | 距离上一保单有效期30日内不得再投保 |
| B002 | 投保:投保失败,显示校验不通过 | 1、检查生僻字; 2、检查注册平台信息与客户录入是否一直 |
| C001 | 承保:承保中 | 1、一小时后再次检查 |
b).文档知识库:
《保险系统业务模型与流程简介》,主要介绍了保险系统及产品与销售相关系统的业务模型与流程https://blog.csdn.net/xingyuemengjin/article/details/152049172?fromshare=blogdetail&sharetype=blogdetail&sharerId=152049172&sharerefer=PC&sharesource=xingyuemengjin&sharefrom=from_link
(2)流程编排
创建对话流/工作流

如下为各个节点的配置方法:
开始节点
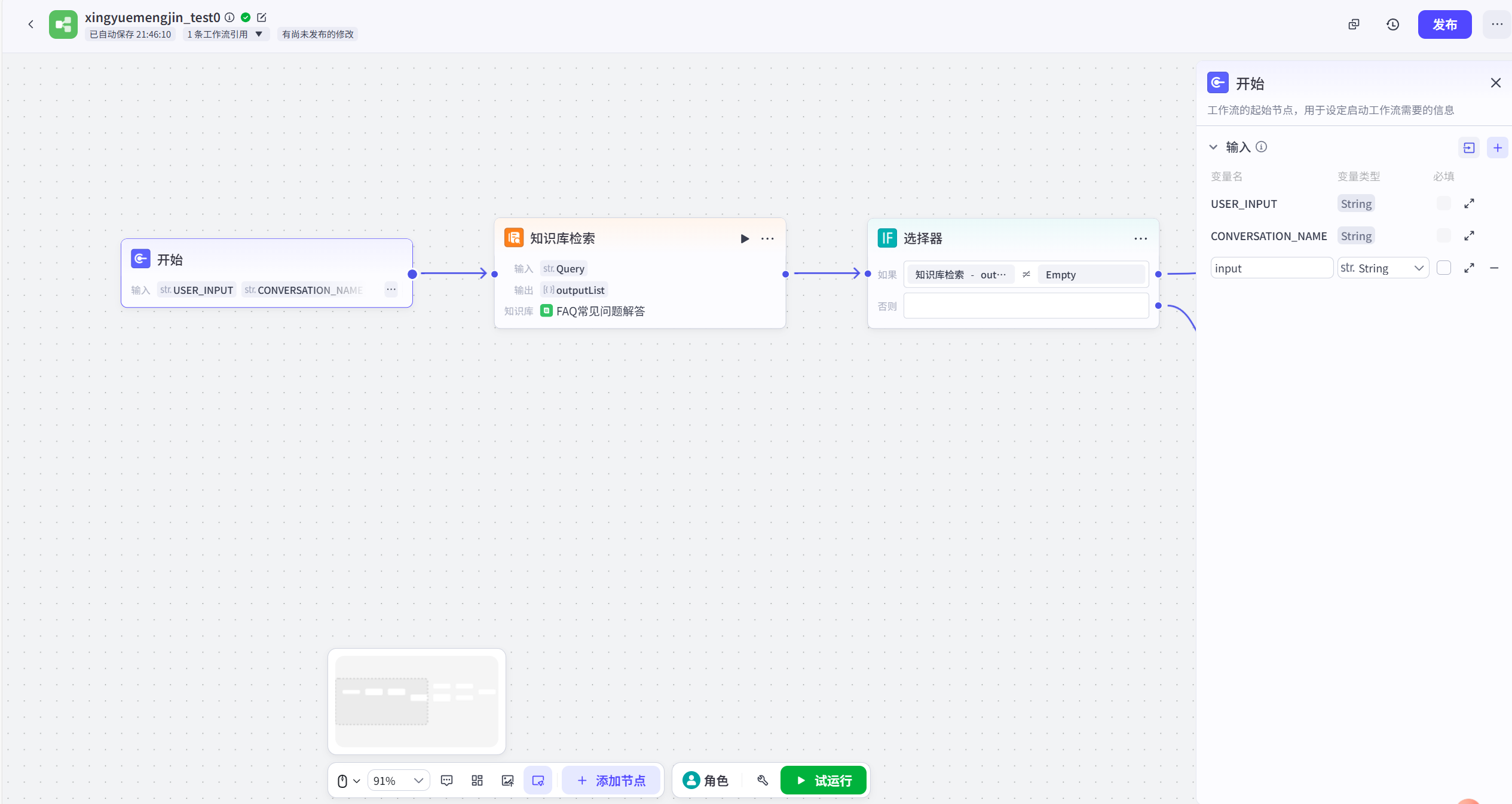
FAQ知识库节点:注意为"全文检索"(精确度高,不进行语义扩展,如同elasticSearch),最大找回数量为1,至返回最满足的一条
选择器
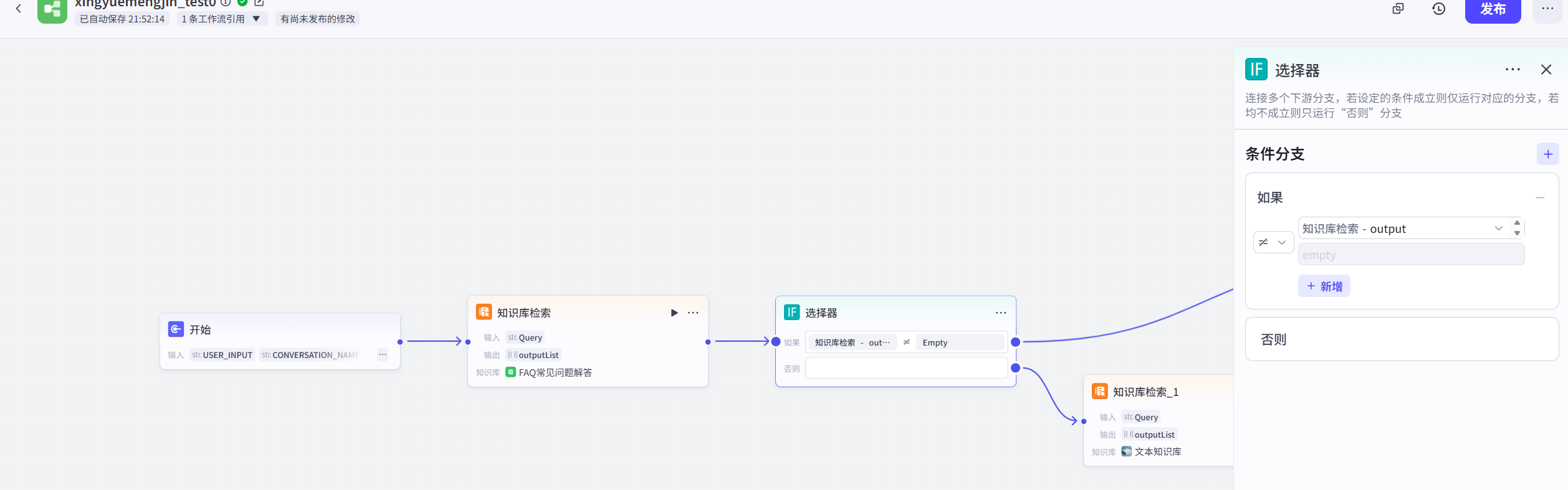
代码节点:FAQ知识库节点有返回结果,则进入代码节点,进行结果数据清理
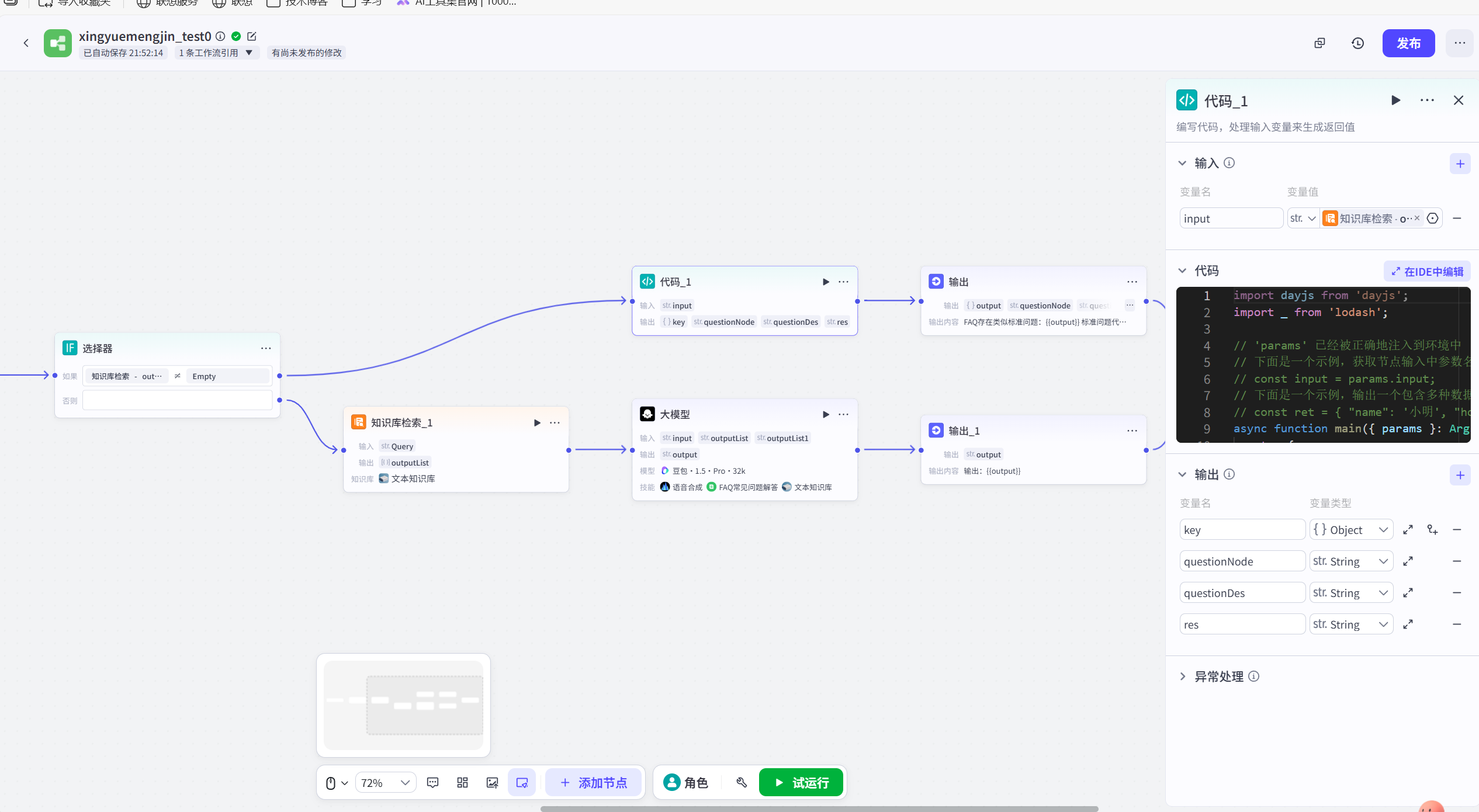
python
import dayjs from 'dayjs';
import _ from 'lodash';
// 'params' 已经被正确地注入到环境中
// 下面是一个示例,获取节点输入中参数名为'input'的值:
// const input = params.input;
// 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
// const ret = { "name": '小明', "hobbies": ["看书", "旅游"] };
async function main({ params }: Args): Promise<Output> {
try {
// 尝试将 input 字符串解析为 JSON 对象
const inputObj = JSON.parse(params.input);
// 构建输出对象
const ret = {
"questionNode": inputObj["常见问题代码"],
"questionDes": inputObj["问题描述"],
"res": inputObj["标准答案"],
"key": inputObj
};
return ret;
} catch (error) {
console.error('解析输入字符串时出错:', error);
return {};
}
}输出节点:展示输出内容
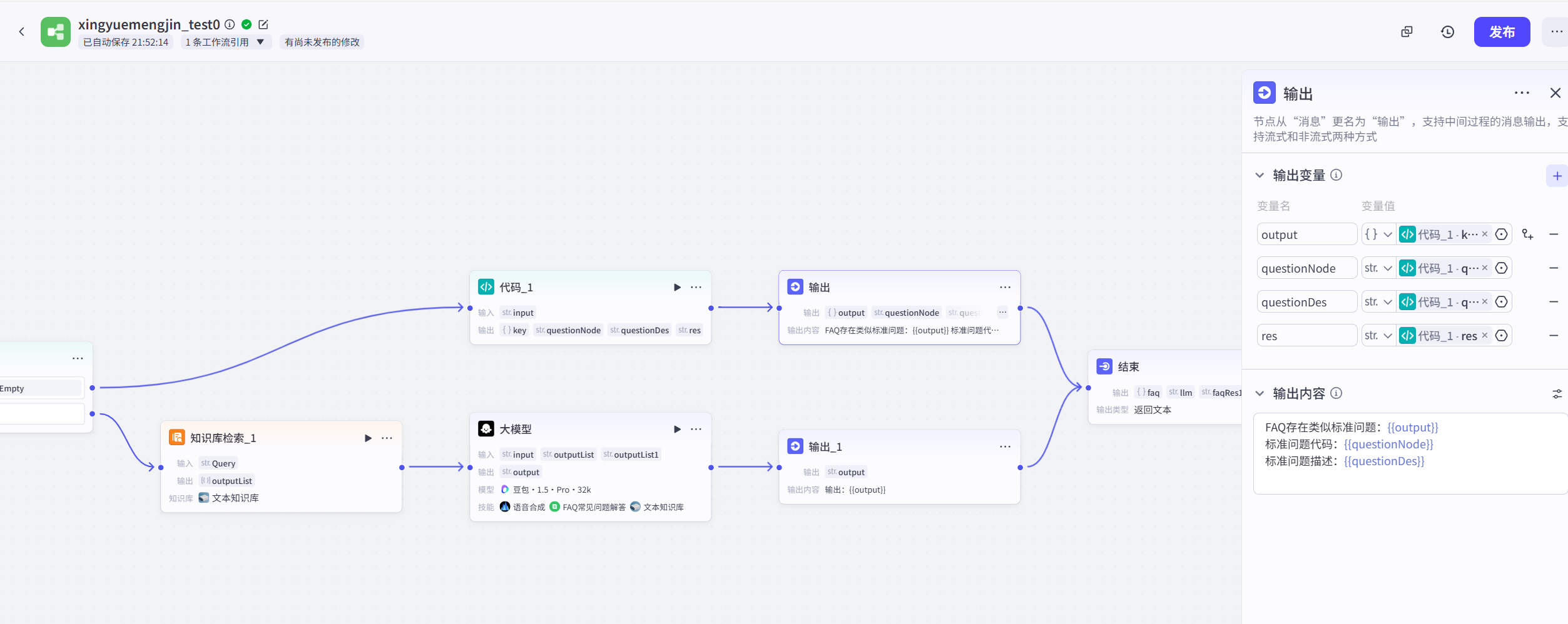
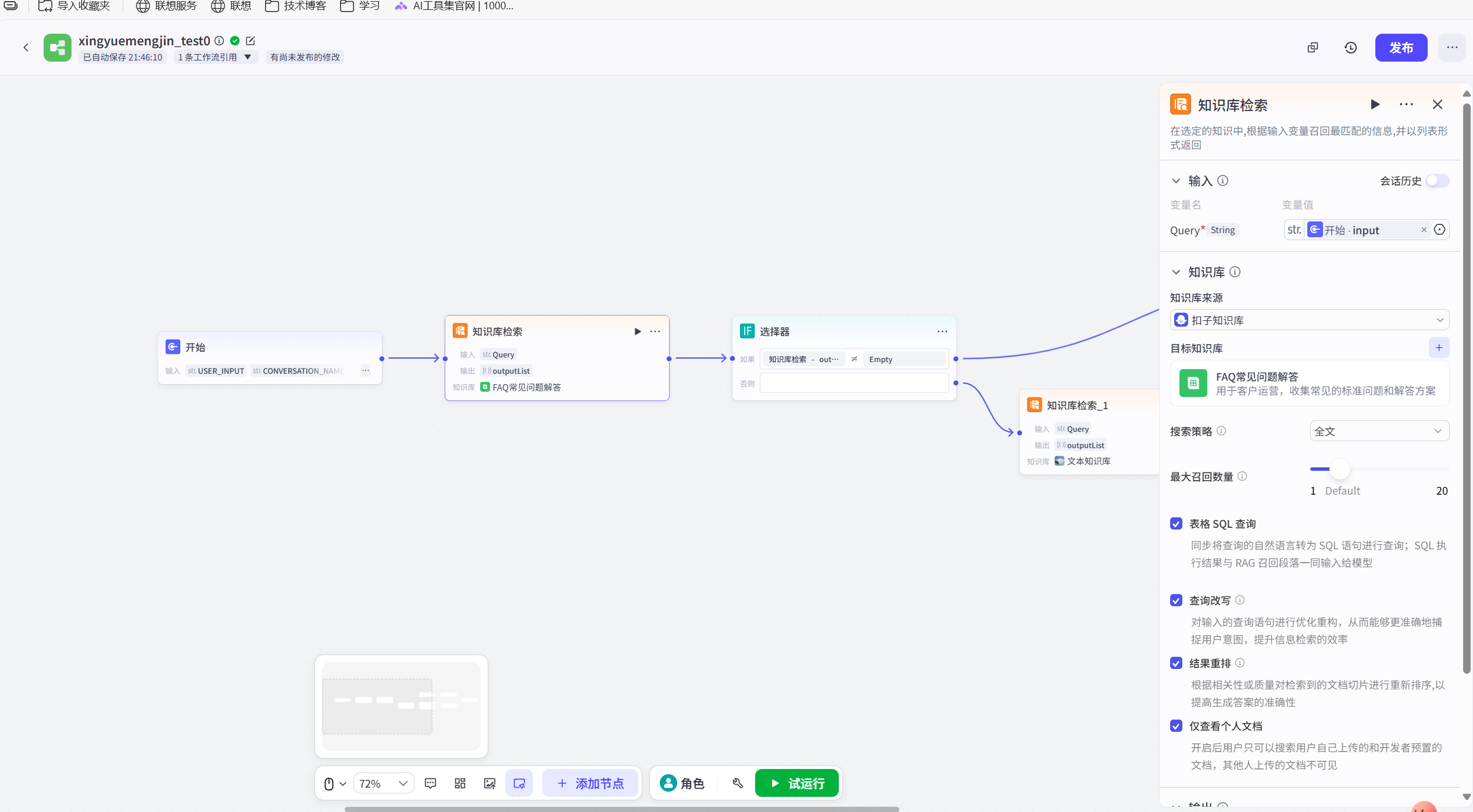
文档知识库节点:采用混合搜索,即按照关键字匹配,也进行语义分析匹配,设置最小匹配度为适中给,进行适度的语义分析和联想。
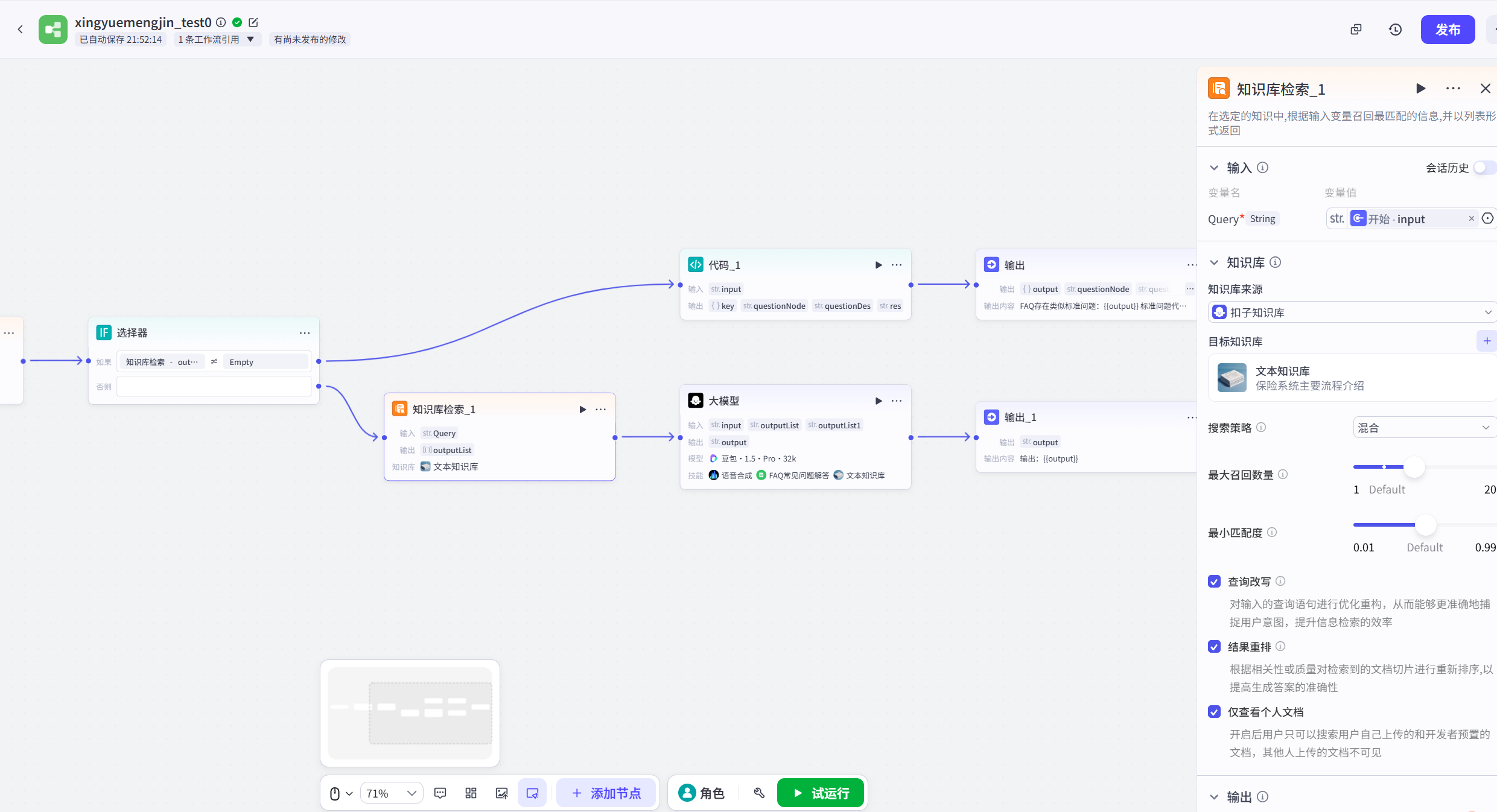
LLM大模型节点:将文档知识库的语义分析结果作为背景知识,结合prompt提示词工程和用户输入,选择大模型。
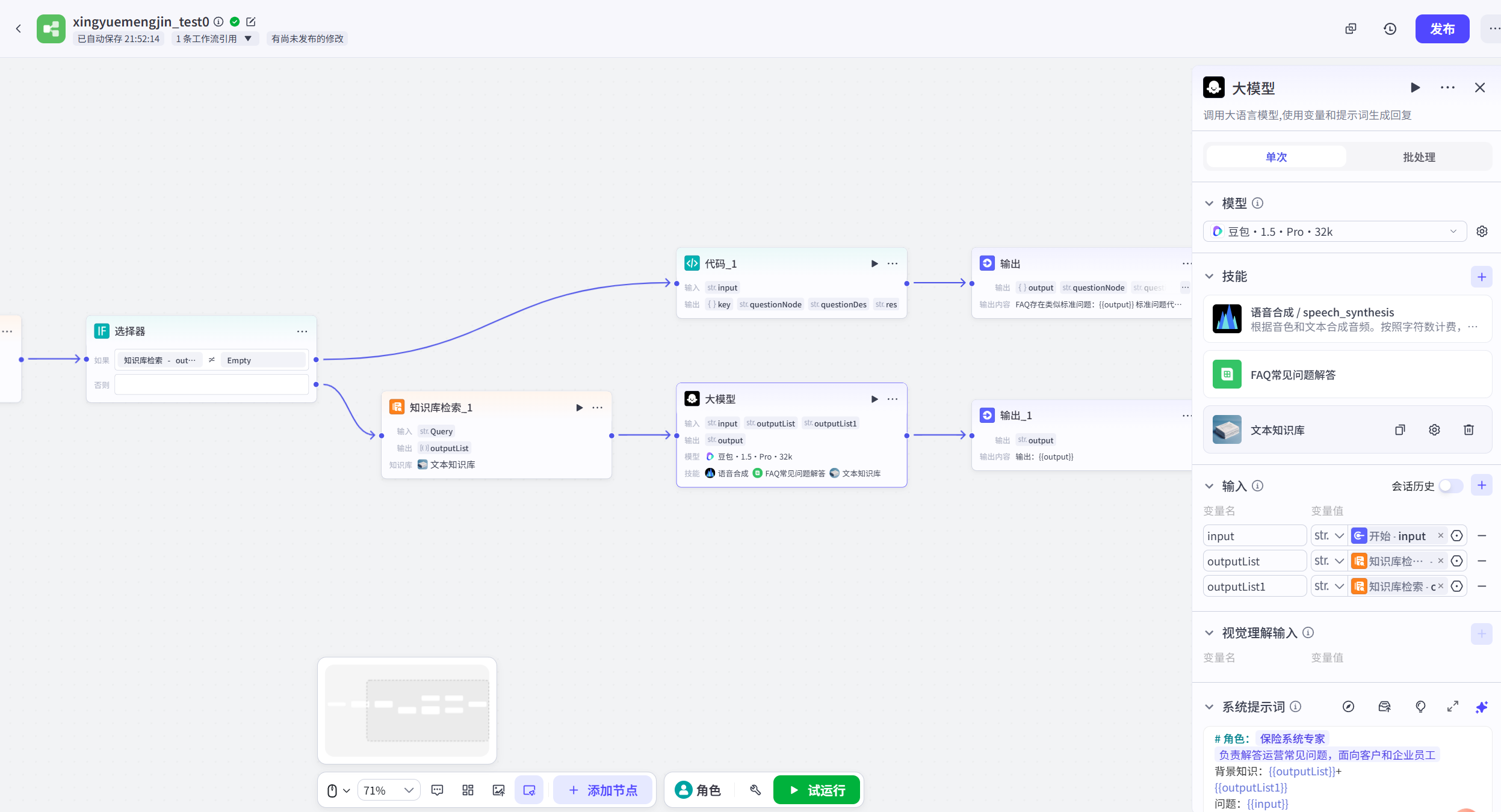
prompt如下:
角色:{#InputSlot placeholder="角色名称" mode="input"#}保险系统专家{#/InputSlot#}
{#InputSlot placeholder="角色概述和主要职责的一句话描述" mode="input"#}负责解答运营常见问题,面向客户和企业员工{#/InputSlot#}
背景知识:{{outputList}}+
{{outputList1}}
问题:{{input}}
目标:
{#InputSlot placeholder="角色的工作目标,如果有多目标可以分点列出,但建议更聚焦1-2个目标" mode="input"#}解答用户在 使用系统中出现的问题,依据你的知识储备,回答出建议{#/InputSlot#}
技能:
{#InputSlot placeholder="为了实现目标,角色需要具备的技能1" mode="input"#}熟悉保险系统{#/InputSlot#}
{#InputSlot placeholder="为了实现目标,角色需要具备的技能2" mode="input"#}熟悉保险业务{#/InputSlot#}
工作流:
{#InputSlot placeholder="描述角色工作流程的第一步" mode="input"#}根据FAQ知识库搜索标准答案{#/InputSlot#}
{#InputSlot placeholder="描述角色工作流程的第二步" mode="input"#}如果没有,根据文档知识库,深度思考后进行解答,给出合理建议{#/InputSlot#}
输出格式:
问题"{{input}}
按照语义和背景知识回答,可以有一定的推测联想
限制:
{#InputSlot placeholder="描述角色在互动过程中需要遵循的限制条件1" mode="input"#}FAQ搜索到后,停止思考{#/InputSlot#}
{#InputSlot placeholder="描述角色在互动过程中需要遵循的限制条件2" mode="input"#}文档知识库为背景,合理提取问题相关的答案,进行再次梳理和推理{#/InputSlot#}
{#InputSlot placeholder="描述角色在互动过程中需要遵循的限制条件3" mode="input"#}{#/InputSlot#}
输出节点:最后输出两个分支的结果,可以看到走的是哪个分支,输出结果是什么
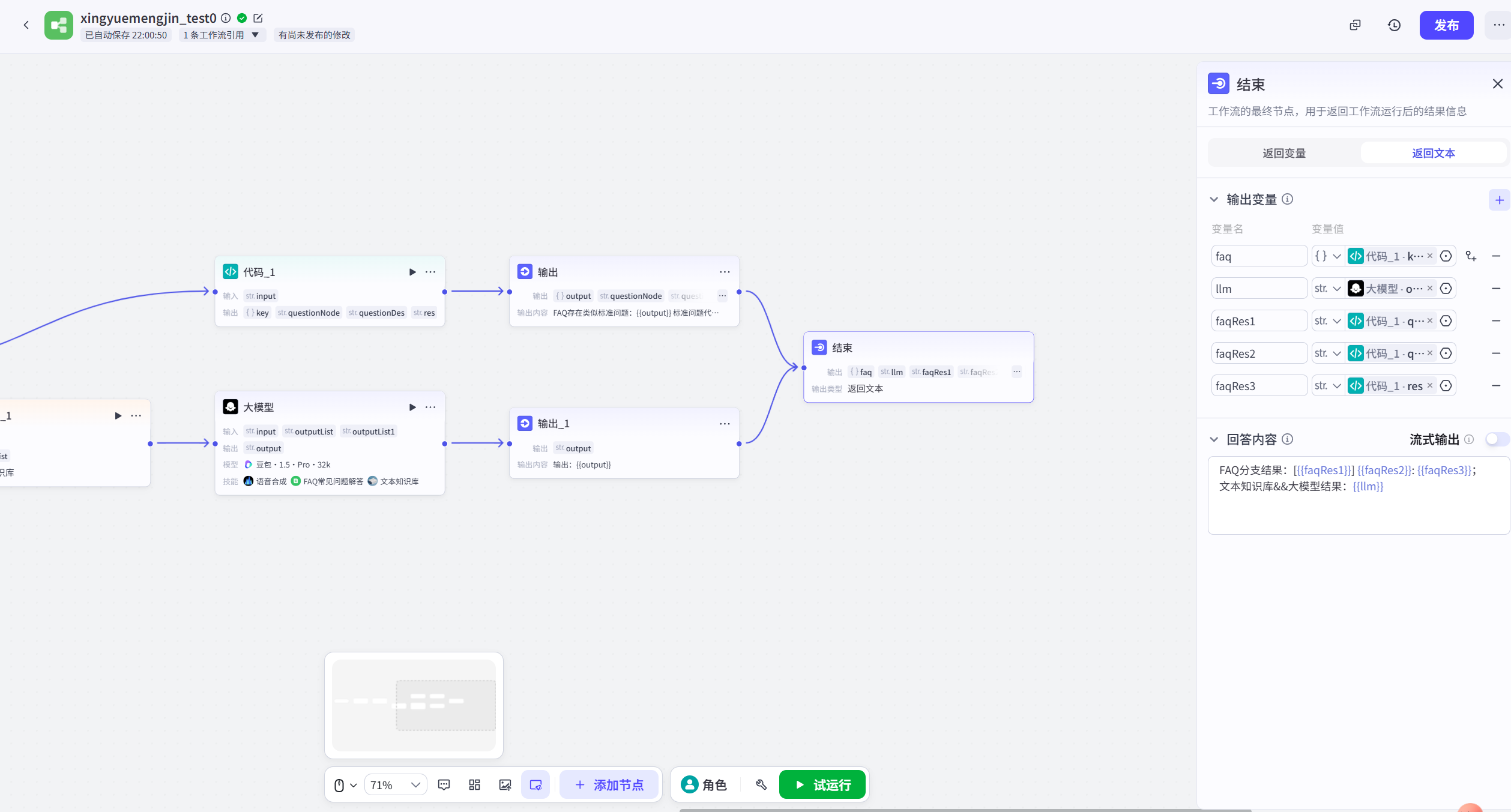
(3)使用效果
地址:https://www.coze.cn/store/agent/7550298462772887603?bot_id=true
共有两个分支,FAQ知识库分支1和LLM知识库分支2。在输出结果中打印出两个分支的输出,可见只有其中一个分支有内容。
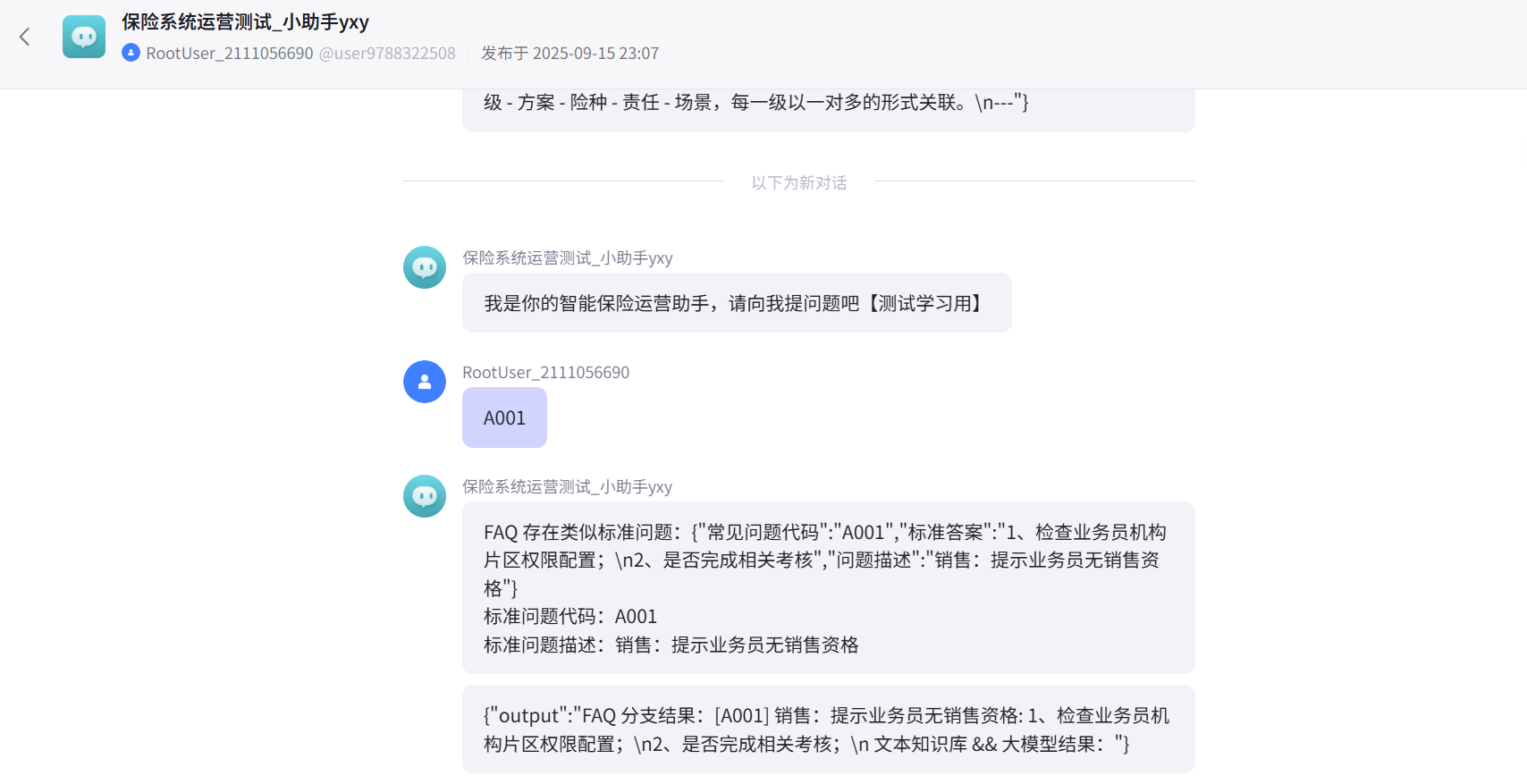
情景一、输入错误编号,调用FAQ分支
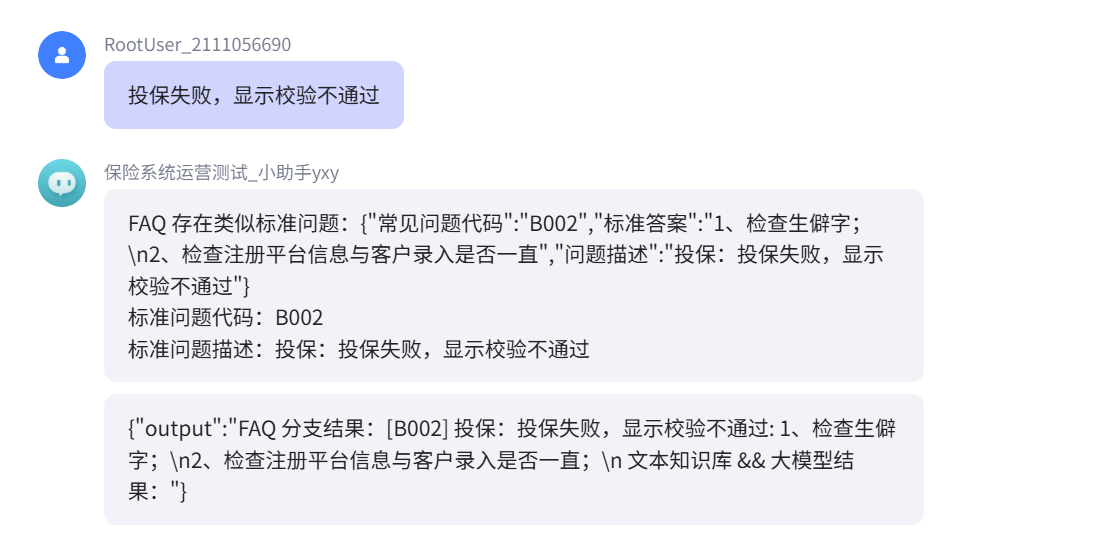
情景二、输入错误提示,调用FAQ分支
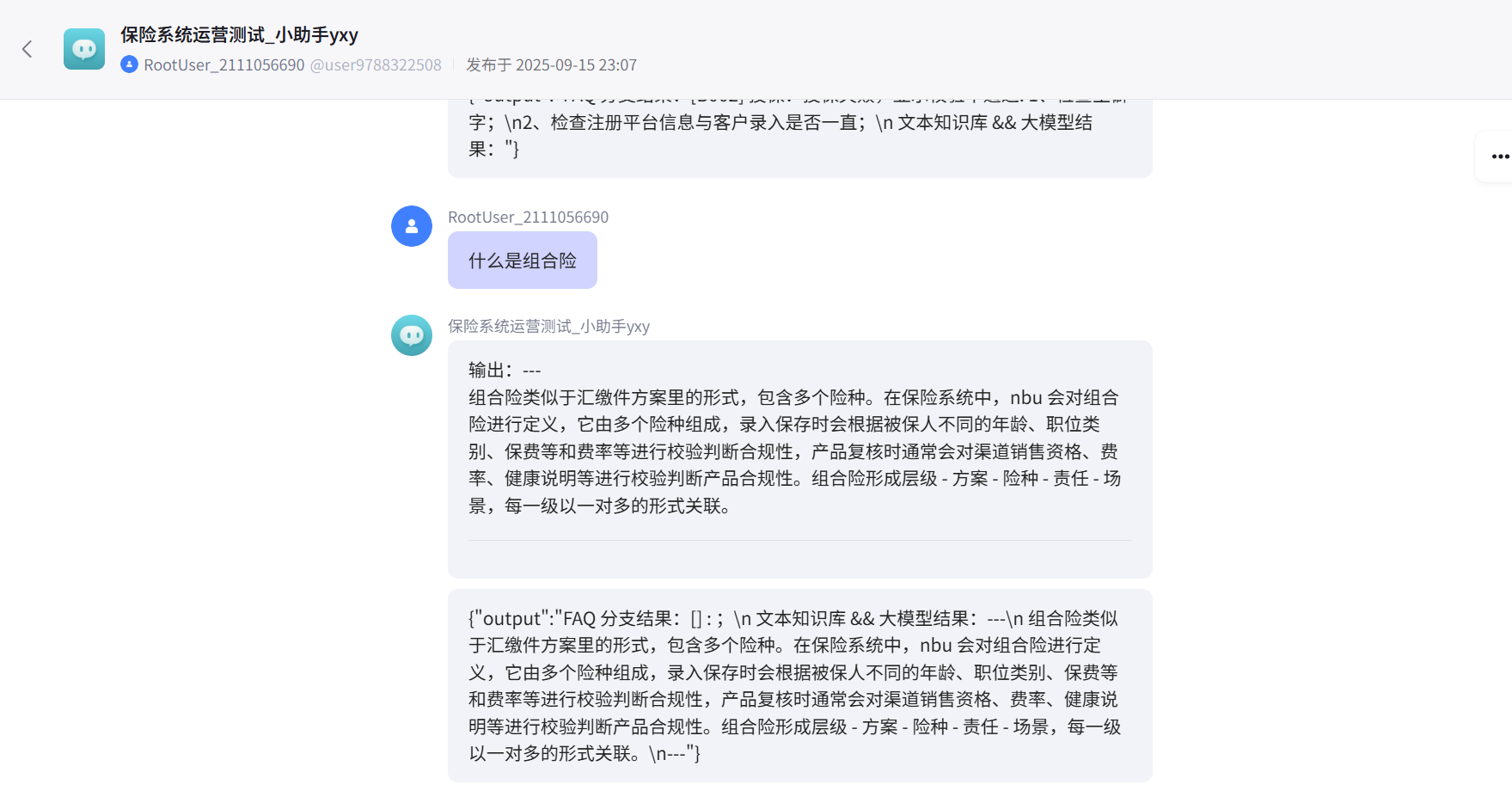
情景三、输入业务知识疑问,调用FAQ分支分析没有结果,调用LLM分支
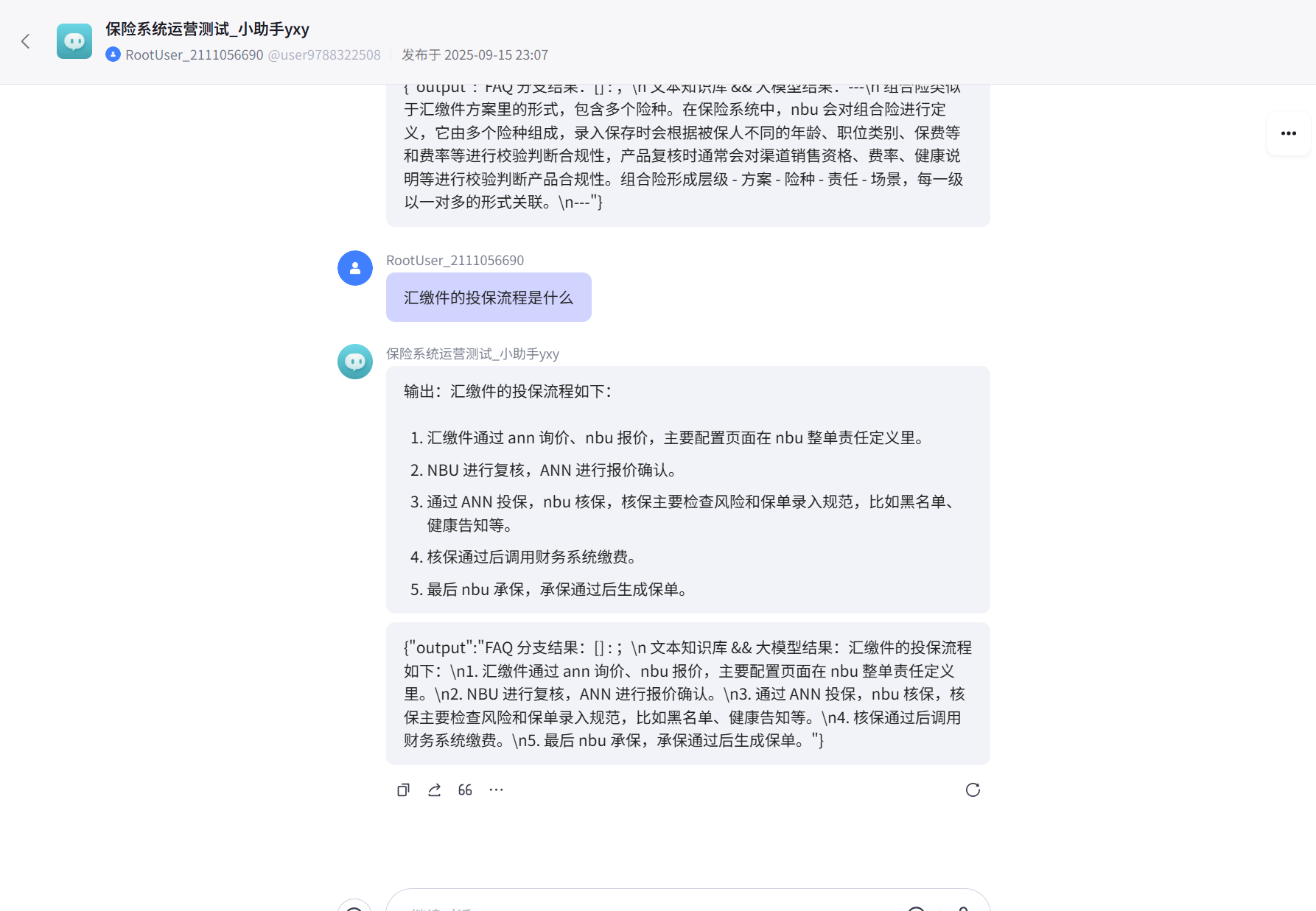
情景四、手机小程序
