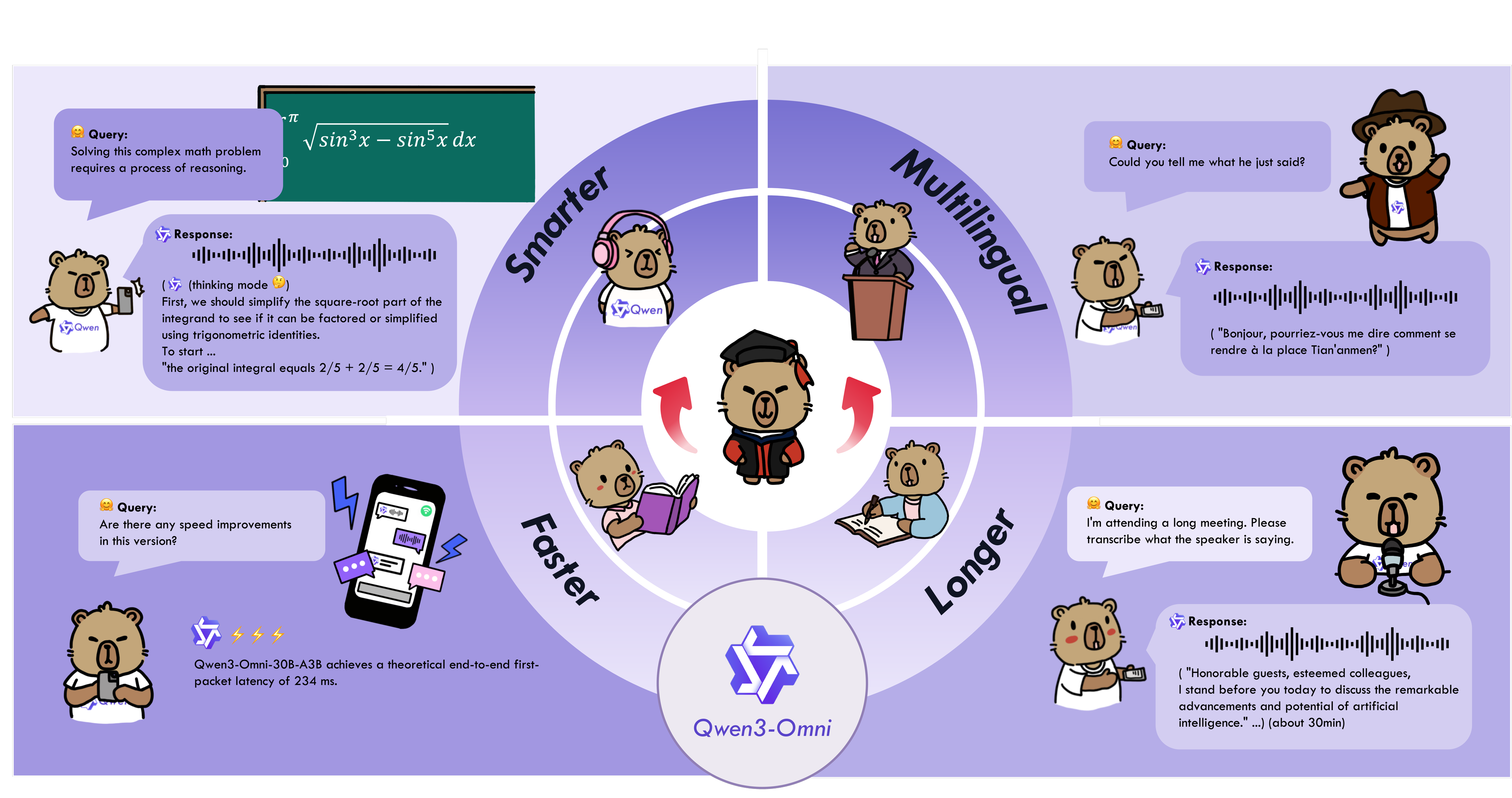
2025年9月23日,阿里云正式上线了全球首个原生端到端全模态AI模型Qwen3-Omni,还大方开源,这难道不意味着AI领域要迎来新的变革了吗?要知道,以往处理文本、图像、音频和视频得用不同模型,现在Qwen3-Omni一个模型就能搞定,这差距可不是一星半点。它不仅能处理多种输入类型,还能实现实时流式输出,不管是文本还是自然语音,都能快速响应,这效率简直没话说。

模型性能对比
模型性能对比(部分数据)
| 模型 | 上下文窗口 | 推理速度 |
|---|---|---|
| Qwen3-Omni | 超长(具体未公开) | 极快(领先行业平均水平) |
| Gemini2.5Pro | 较长 | 快(行业较高水平) |
跨模态先进表现
Qwen3-Omni模型在多个领域都展现出了跨模态的先进表现。它通过早期以文本为核心的预训练和混合多模态训练,拥有了强大的多模态能力。在音频和视频性能上,它表现尤为出色;在文本和图像效果上,也能保持高标准。
据36项音频和视频的基准测试显示,Qwen3-Omni在22项中达到了最新领先水平,尤其是在自动语音识别和音频理解等领域,和同行业的Gemini2.5Pro不相上下。值得一提的是,在图像生成领域,Qwen3-Omni生成的高清图像,色彩鲜艳且细节丰富,和传统图像生成模型相比,优势明显。
强大语言支持与架构设计
Qwen3-Omni的语言支持能力也十分强大。它支持119种文本语言和19种语音输入语言,还有10种语音输出语言,像英语、中文、法语和德语等多种语言都涵盖在内。
这让它能更好地服务全球用户,不管用户来自哪个国家、说什么语言,都能轻松使用。其创新的架构设计基于MoE(专家混合)系统,结合了AuT预训练,让模型具有强大的通用表征能力。同时,多码本设计确保了低延迟的实时音频和视频交互,能让自然对话流畅进行。
文本转语音模型Qwen3-TTS
除了Qwen3-Omni,阿里云还发布了Qwen3-TTS,这是一个支持17种音色选择的文本转语音模型。该模型在多项评估基准中表现出色,超越了多款竞品,尤其在语音稳定性和音色相似度方面表现突出。想象一下,用Qwen3-TTS转换出来的语音,就像真人说话一样自然流畅,是不是很神奇?
图像编辑工具Qwen-Image-Edit-2509
Qwen-Image-Edit-2509是另一个新发布的工具,它专注于图像编辑的多图像支持,显著提升了编辑的一致性和效果。它不仅能处理单图像,还支持多图像的拼接编辑,能满足更复杂的编辑需求。比如,你想把几张照片拼接成一张有创意的大图,用Qwen-Image-Edit-2509就能轻松实现。
Qwen3-Omni模型地址
模型地址: https://huggingface.co/collections/Qwen/qwen3-omni-68d100a86cd0906843ceccbe
GitHub地址:https://github.com/QwenLM/Qwen3-Omni
文章来源:AITOP100,原文地址:阿里云推出全球首个全模态AI模型Qwen3-Omni,实现文本、图像、音视频端到端处理-AITOP100,AI资讯