点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年09月22日更新到:
Java-130 深入浅出 MySQL MyCat 深入解析 核心配置文件 server.xml 使用与优化
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
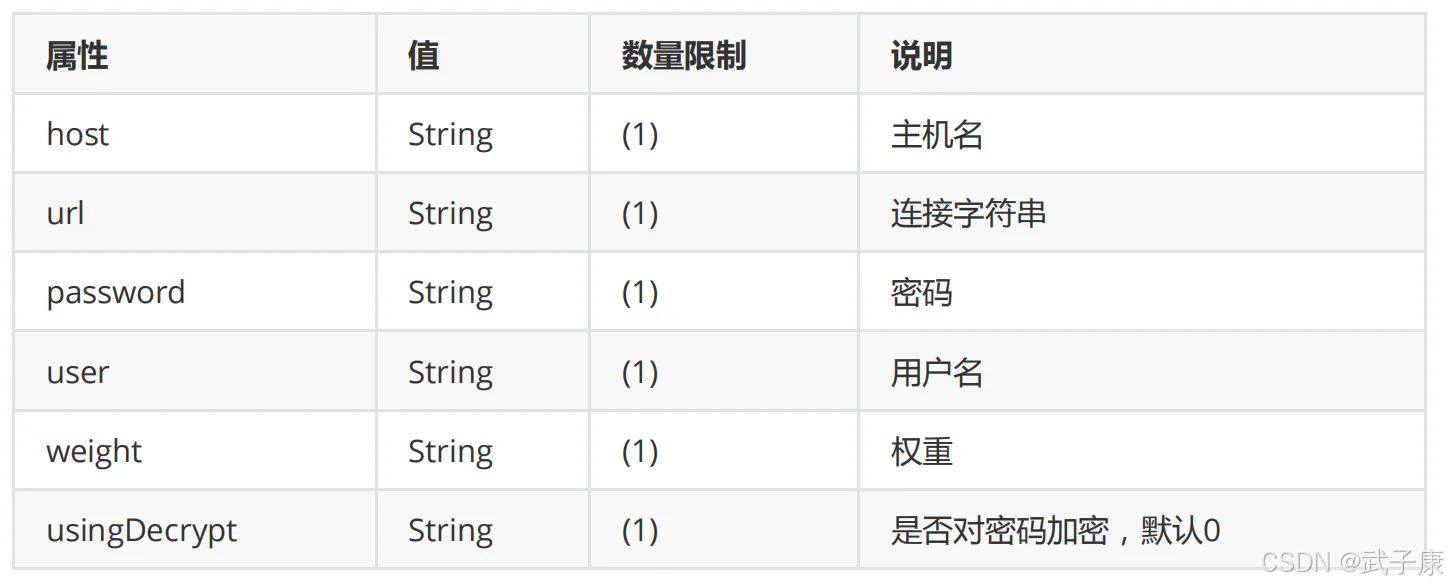
schema.xml 配置
schema.xml 是 Mycat 分库分表中间件中的核心配置文件之一,主要负责定义和管理以下关键组件:
- 逻辑库(Schema)配置:
- 定义虚拟数据库名称,与物理数据库解耦
- 可配置多个逻辑库,每个对应不同业务模块
- 示例:
<schema name="ORDER_DB" checkSQLschema="true" sqlMaxLimit="100">
- 逻辑表(Table)配置:
- 定义虚拟表结构,包括表名、主键等元数据
- 支持分片表(分片规则)、全局表(所有节点冗余)、非分片表等类型
- 示例:
<table name="orders" primaryKey="id" dataNode="dn1,dn2" rule="mod-long" />
- 数据节点(DataNode)配置:
- 映射逻辑表到物理数据库实例
- 定义数据源名称和所属数据库
- 示例:
<dataNode name="dn1" dataHost="host1" database="order_db_01" />
- 数据主机(DataHost)配置:
- 配置物理数据库服务器连接信息
- 包含读写分离、心跳检测等高级功能
- 示例:
<dataHost name="host1" maxCon="1000" minCon="10" balance="1">
典型应用场景包括:
- 电商系统订单表按月分片存储
- 用户数据按ID哈希分片
- 商品信息作为全局表同步到所有节点
配置注意事项:
- 需要与rule.xml配合使用定义分片规则
- 修改后需重启Mycat或执行reload命令生效
- 建议通过Mycat-web管理界面进行可视化配置
- 需要保持与真实数据库结构的同步更新
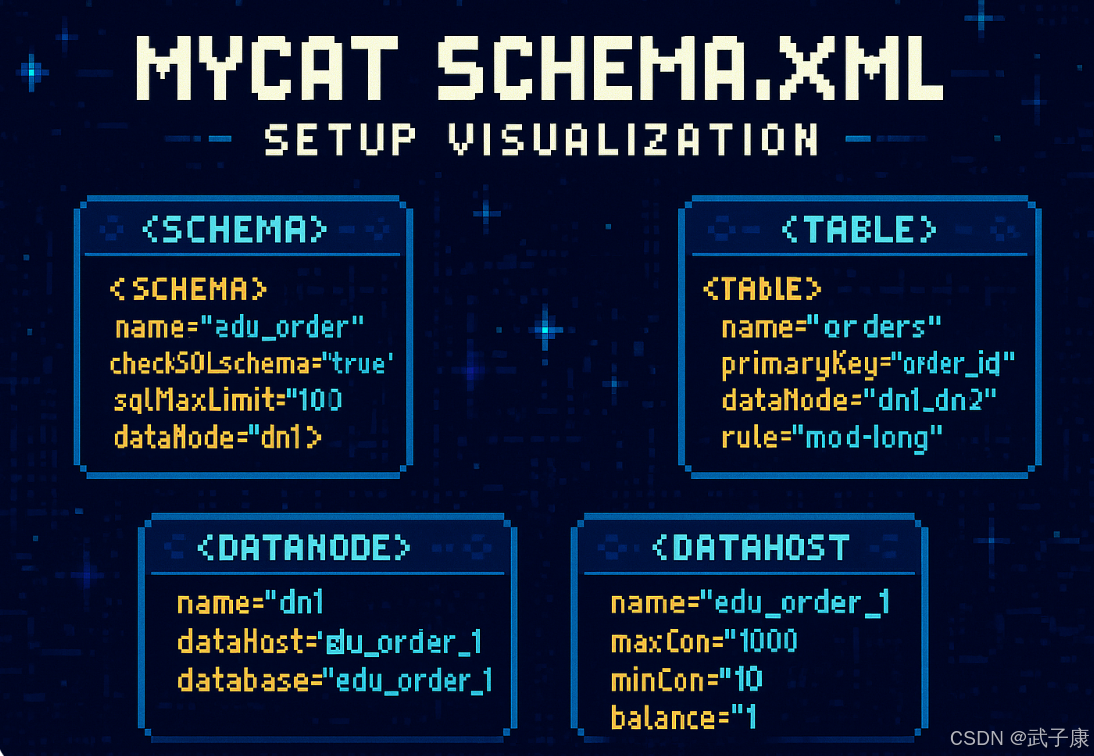
schema标签
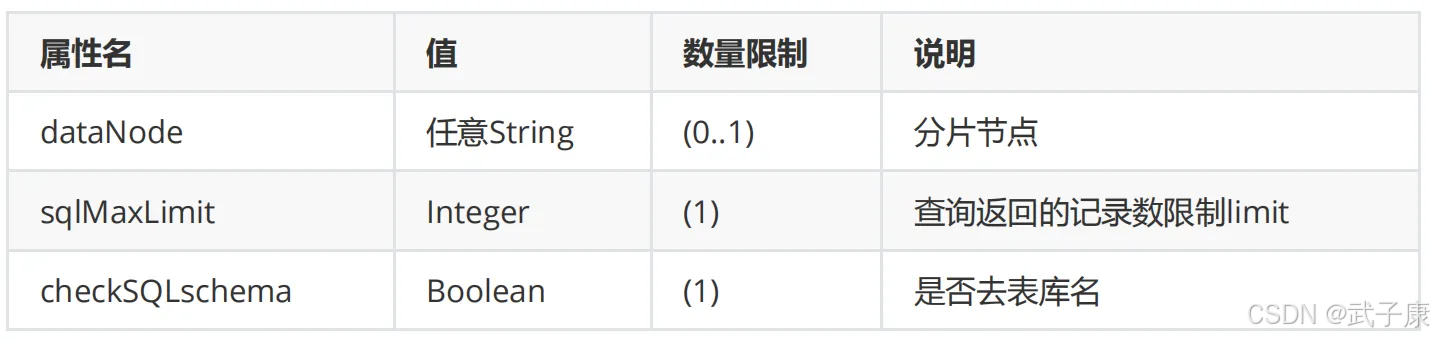
Mycat 中的 schema 标签是配置文件中的核心元素,用于定义逻辑数据库(逻辑库)的结构和特性。在一个 Mycat 实例中可以配置多个逻辑库,每个逻辑库相当于一个独立的虚拟数据库,可以包含不同的表和数据节点配置。
schema 标签的主要属性包括:
name:指定逻辑库的名称,客户端将使用这个名称进行连接checkSQLschema:布尔值,控制是否检查SQL中的schema名称sqlMaxLimit:设置默认的查询结果集最大行数限制dataNode:指定默认的数据节点
在实际应用中,schema 标签通常这样配置:
xml
<!-- 订单业务逻辑库配置 -->
<schema name="edu_order" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<!-- 这里可以定义表的相关配置 -->
<table name="orders" primaryKey="order_id" dataNode="dn1,dn2" rule="mod-long"/>
</schema>
<!-- 用户业务逻辑库配置 -->
<schema name="edu_user" checkSQLschema="false" sqlMaxLimit="500" dataNode="dn3">
<table name="users" type="global" dataNode="dn3,dn4"/>
</schema>典型应用场景包括:
- 多租户系统:为不同租户分配独立的逻辑库
- 业务隔离:将订单、用户等不同业务模块分离到不同逻辑库
- 读写分离:为同一业务配置主从逻辑库
注意:每个逻辑库必须至少包含一个有效的 dataNode 配置,否则无法正常工作。逻辑库名称应该保持唯一性,避免与物理数据库名称冲突。
table标签
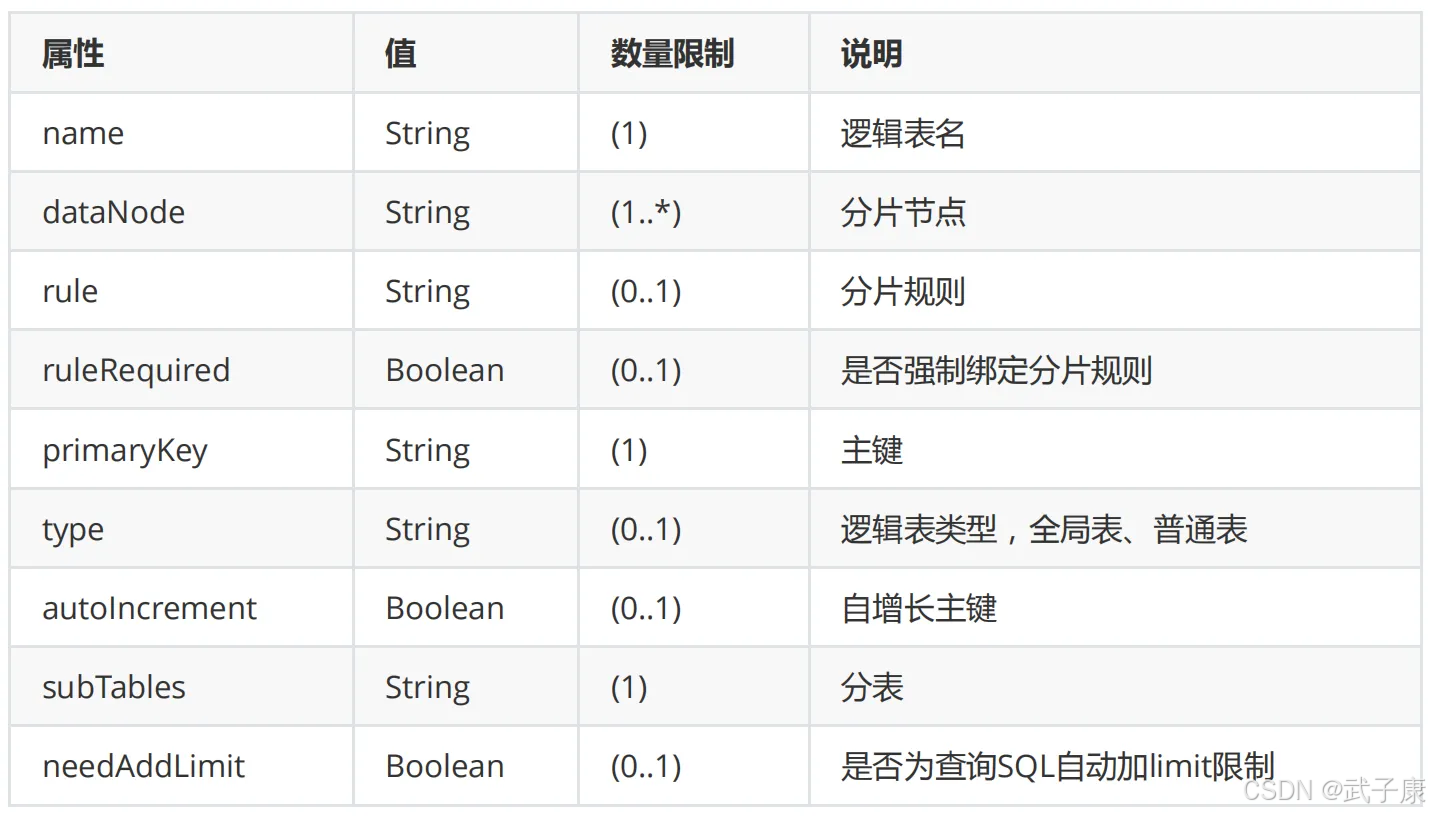
table标签是Mycat分库分表配置中定义逻辑表的核心元素,所有需要水平拆分的表都必须通过该标签进行配置。该标签的主要属性包括:
- name属性:指定逻辑表的名称,对应应用程序中访问的表名
- dataNode属性:定义该表分布的数据节点,多个节点用逗号分隔
- rule属性:指定分片规则,对应rule.xml中定义的规则名称
- primaryKey属性:声明表的主键字段
- autoIncrement属性:设置是否自增主键
配置示例:
xml
<table name="b_order"
dataNode="dn1,dn2"
rule="b_order_rule"
primaryKey="ID"
autoIncrement="true"/>典型应用场景:
- 电商系统中的订单表(b_order)按用户ID分片存储
- 日志表按时间范围分片存储
- 用户表按地域分片存储
注意事项:
- dataNode指定的节点必须在schema.xml中正确定义
- rule指定的分片规则必须在rule.xml中配置
- 对于自增主键表,建议配置全局序列号
- 分片字段应该选择查询频率高的字段
完整配置通常需要配合schema.xml和rule.xml文件共同完成分片逻辑的定义。
dataNode标签
dataNode标签是Mycat分片配置中的核心元素,用于定义数据分片节点。它建立逻辑分片与实际物理数据库实例之间的映射关系。
xml
<!-- 数据节点配置示例 -->
<dataNode name="dn1" dataHost="edu_order_1" database="edu_order_1" />详细参数说明:
-
name属性:
- 作用:定义数据节点的唯一标识名称
- 要求:必须全局唯一,不能与其他dataNode重复
- 使用场景:在table标签中通过该名称指定表的分片规则
- 命名规范:建议采用"dn"+数字的格式,如dn1、dn2等,便于管理
-
dataHost属性:
- 作用:指定该分片节点所属的物理主机组
- 要求:必须对应dataHost标签中已定义的name属性值
- 示例:如果配置了
<dataHost name="edu_order_1">,则dataNode可以引用该主机组
-
database属性:
- 作用:指定该分片节点对应的实际物理数据库名称
- 要求:必须是目标数据库实例中真实存在的数据库
- 注意事项:该属性值会作为实际SQL路由时的目标数据库名
典型应用场景:
- 水平分片场景:将user表分散到dn1、dn2、dn3三个节点
- 垂直分片场景:将order表放在dn1,payment表放在dn2
配置建议:
- 建议为每个物理数据库实例创建单独的dataNode
- 在分库分表场景中,通常需要配置多个dataNode
- 可以通过schema.xml中的table标签将逻辑表映射到具体的dataNode
dataHost标签
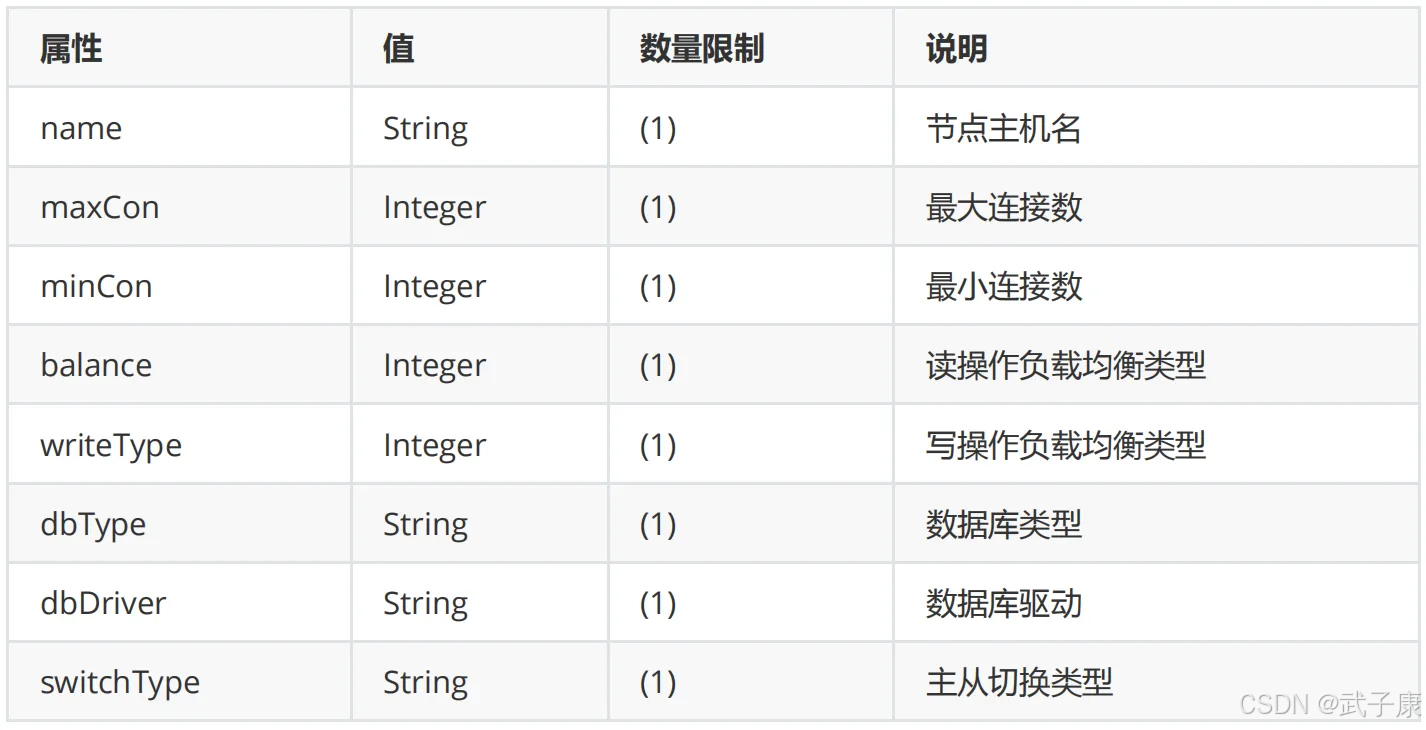
dataHost 标签在 Mycat 逻辑库配置中作为最底层的核心标签,直接定义了实际的物理数据库实例连接信息及其运行策略。该标签通过详细的属性配置,实现了对后端数据库实例的精细化管理,主要包括以下关键方面:
-
基础连接配置:
name:唯一标识数据主机的名称dbType:指定数据库类型(如mysql/oracle等)dbDriver:驱动类型(native/jdbc)maxCon/minCon:连接池参数(最大100连接,最小10连接)
-
读写分离策略:
balance属性支持多种模式:- 0:不开启读写分离
- 1:随机读请求到所有writeHost/readHost
- 2:读请求随机分配到writeHost对应readHost
- 3:读请求随机分配到writeHost对应readHost且自动剔除故障节点
- 示例中的
balance="0"表示禁用读写分离
-
高可用配置:
switchType:故障切换方式(1-自动切换,2-基于MySQL主从状态,3-基于手动切换)slaveThreshold:从库延迟阈值(单位秒,超过则被剔除)- 心跳检测机制通过子标签
heartbeat配置,如:<heartbeat>select user()</heartbeat>
-
实例定义 :
通过嵌套的
writeHost和readHost标签定义具体实例:
xml
<writeHost host="hostM1" url="192.168.0.1:3306" user="root" password="123456">
<readHost host="hostS1" url="192.168.0.2:3306" user="root" password="123456"/>
</writeHost>典型应用场景包括:电商系统的订单库分片部署、金融系统的读写分离集群配置、物联网设备数据的高可用存储方案等。通过合理配置这些参数,可以实现数据库访问的负载均衡、故障自动转移等关键功能。
heartbeat标签
在数据库中间件配置中,heartbeat标签用于指定后端数据库连接的健康检查语句。不同的数据库类型需要配置对应的SQL语句来验证连接有效性:
MySQL数据库:
-
推荐使用
SELECT user()或SELECT 1等简单查询语句 -
执行这类语句不会产生锁表或性能开销
-
示例:
xml<dataHost> <heartbeat>SELECT user()</heartbeat> </dataHost>
Oracle数据库:
-
需要使用
SELECT 1 FROM dual特殊语法 -
dual是Oracle的虚拟表,专门用于这类简单查询
-
示例:
xml<dataHost> <heartbeat>SELECT 1 FROM dual</heartbeat> </dataHost>
其他常见数据库的心跳语句示例:
- PostgreSQL:
SELECT 1 - SQL Server:
SELECT 1 - DB2:
SELECT 1 FROM sysibm.sysdummy1 - MariaDB:
SELECT 1
配置注意事项:
- 心跳语句应该尽可能简单,避免复杂查询
- 不要使用会产生锁的语句(如SELECT FOR UPDATE)
- 语句执行时间应在毫秒级完成
- 心跳间隔通常配置为5-10秒
- 超时时间建议设置为心跳间隔的2-3倍
完整配置示例:
xml
<dataHost name="mysql_host" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1">
<heartbeat>SELECT user()</heartbeat>
<writeHost host="master" url="192.168.1.100:3306" user="root" password="123456">
<readHost host="slave" url="192.168.1.101:3306" user="root" password="123456"/>
</writeHost>
</dataHost>writeHost和readHost标签
在 Mycat 数据库中间件的配置中,writeHost 和 readHost 是用于定义后端数据库连接的重要标签,它们共同组成 dataHost 的数据源配置单元。这两个标签的主要区别在于:
-
功能分工:
writeHost专门用于指定可执行写操作(INSERT/UPDATE/DELETE)的主数据库实例readHost专门用于指定只读操作(SELECT)的从数据库实例- 一个典型的读写分离配置会包含1个
writeHost和多个readHost
-
高可用机制:
- 当主
writeHost宕机时,其绑定的所有readHost都会自动失效 - Mycat会自动检测故障并通过
switchType参数指定的策略切换到备用writeHost - 切换过程中会触发心跳检测机制(如示例中的
select user())
- 当主
-
配置细节:
- 每个
writeHost需要定义完整的连接参数:host:主机标识名url:数据库连接地址和端口user/password:认证信息
- 可选参数包括:
maxCon/minCon:连接池大小限制dbType:数据库类型(如MySQL)dbDriver:驱动类型(native/jdbc)
- 每个
示例配置展示了最简单的单节点配置,实际生产环境通常会包含更复杂的高可用方案:
xml
<dataHost name="order_cluster" maxCon="200" minCon="20" balance="1"
writeType="1" dbType="mysql" dbDriver="native" switchType="2"
slaveThreshold="100">
<heartbeat>select 1 from dual</heartbeat>
<!-- 主写节点 -->
<writeHost host="M1" url="192.168.1.111:3306" user="rw_user" password="securePwd123">
<!-- 从读节点 -->
<readHost host="S1" url="192.168.1.112:3306" user="ro_user" password="readonlyPwd"/>
<readHost host="S2" url="192.168.1.113:3306" user="ro_user" password="readonlyPwd"/>
</writeHost>
<!-- 备用写节点 -->
<writeHost host="M2" url="192.168.1.121:3306" user="rw_user" password="securePwd123">
<readHost host="S3" url="192.168.1.122:3306" user="ro_user" password="readonlyPwd"/>
</writeHost>
</dataHost>在这个增强版配置中:
- 设置了主备双写节点(M1/M2)和多个读节点(S1-S3)
- 使用更安全的心跳检测语句
select 1 from dual - 配置了更完善的连接池参数和负载均衡策略(balance="1")
- 采用更可靠的切换机制(switchType="2")