基于正倒排索引的boost搜索引擎
- Parser模块:HTML解析与数据清洗的实现解析
-
- [1. 模块概述](#1. 模块概述)
- [2. 核心数据结构](#2. 核心数据结构)
- [3. 处理流程详解](#3. 处理流程详解)
- 模块代码实现
Parser模块:HTML解析与数据清洗的实现解析
1. 模块概述
Parser模块是搜索引擎数据处理流程中的第一道关卡,负责将原始的HTML文档转换为结构化的干净数据。它的主要功能包括:
-
递归扫描HTML文件目录
-
提取文档标题、内容和URL
-
去除HTML标签,保留纯文本内容
-
将处理后的数据写入目标文件供后续索引构建使用
2. 核心数据结构
HtmlInfo结构体
cpp
typedef struct HtmlInfo
{
std::string title_; // 文档标题
std::string content_; // 去标签后的纯文本内容
std::string url_; // 文档对应的官网URL
}HtmlInfo_t;3. 处理流程详解
3.1 初始化流程 (Init())
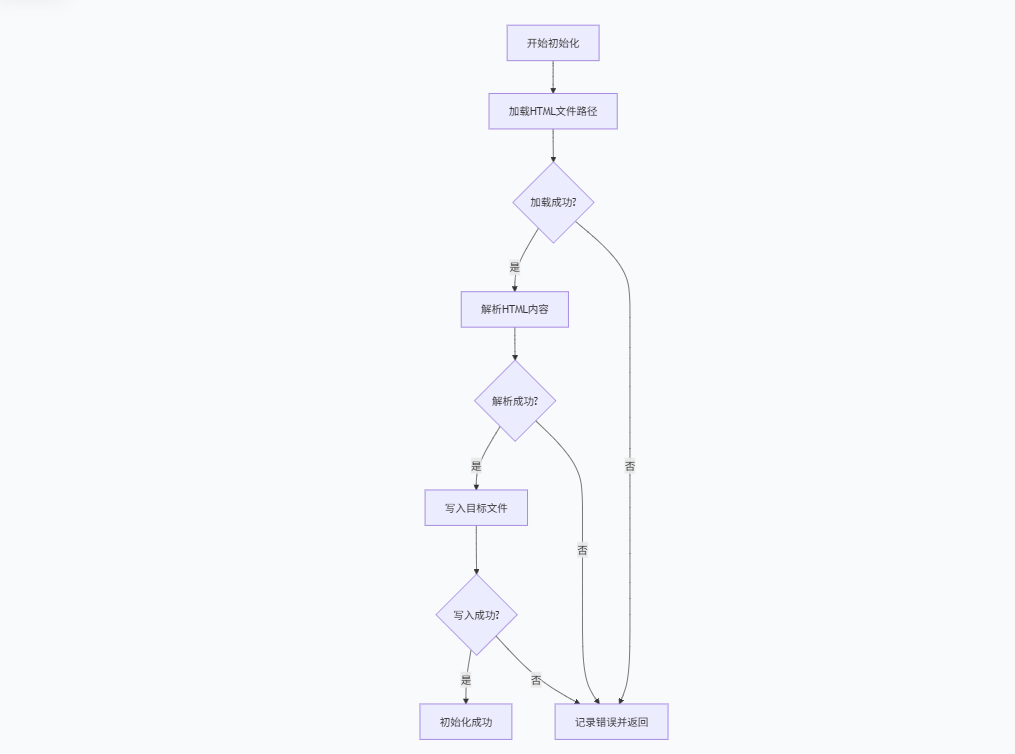
3.2 HTML文件路径加载 (LoadHtmlPath())
目录验证:检查原始数据目录是否存在且有效
递归遍历:使用boost::filesystem::recursive_directory_iterator遍历所有子目录
文件过滤:
跳过非普通文件
只处理.html扩展名的文件
路径收集:将符合条件的HTML文件路径存入htmlpaths_向量
3.3 HTML内容解析 (ParseHtml())
标题提取 (ParseTitle())
-
定位标签:查找和的位置
-
内容提取:截取两个标签之间的文本内容
-
错误处理:记录无法找到标题的文件
内容清洗 (ParseContent())
-
状态机解析:使用LABEL/CONTENT两种状态处理HTML
-
标签跳过:遇到<进入LABEL状态,跳过所有标签内容
-
文本保留:遇到>进入CONTENT状态,保留后续文本
-
换行处理:将换行符替换为空格,保持文本连贯性
URL构建 (ParseUrl())
-
路径转换:将本地文件路径转换为官网URL
-
前缀拼接:添加Boost_Url_Head作为URL前缀
-
文件名提取:使用path.filename()获取文件名部分
3.4 数据写入 (WriteToTarget())
-
格式组装:将各个字段按title\3content\3url\n格式拼接
-
批量写入:所有文档内容拼接后一次性写入文件
-
性能优化:使用大缓冲区(128KB)提高写入效率
模块代码实现
项目结构
Parser.h
cpp
#pragma once
// 包含公共头文件,可能包含一些全局定义、类型别名或常用工具函数
#include "common.h"
// 包含Boost文件系统库相关头文件,用于文件和目录操作
#include "boost/filesystem.hpp"
#include <boost/filesystem/directory.hpp>
#include <boost/filesystem/path.hpp>
// 包含vector容器头文件,用于存储路径和HTML信息列表
#include <vector>
// 为boost::filesystem定义别名别名fs,简化代码书写
#define fs boost::filesystem
// HTML信息结构体,用于存储解析后的HTML文档关键信息
typedef struct HtmlInfo
{
std::string title_; // 存储HTML文档的标题
std::string content_; // 存储HTML文档的正文内容(去标签后)
std::string url_; // 存储HTML文档的URL或来源路径
}HtmlInfo_t; // 定义结构体别名HtmlInfo_t,方便使用
class Parser
{
private:
// 解析HTML内容,提取标题并存储到title指针指向的字符串
// 参数:fdata-HTML原始数据,title-输出的标题字符串指针
// 返回值:bool-解析成功返回true,失败返回false
bool ParseTitle(std::string& fdata, std::string* title);
// 解析HTML内容,提取正文(去除标签后)并存储到content指针指向的字符串
// 参数:fdata-HTML原始数据,content-输出的正文内容字符串指针
// 返回值:bool-解析成功返回true,失败返回false
bool ParseContent(std::string& fdata, std::string* content);
// 将解析后的HTML信息写入目标文件(内部实现)
// 返回值:bool-写入成功返回true,失败返回false
bool WriteToTargetFile();
public:
// 构造函数,初始化原始数据路径和目标存储路径
// 参数:Datap-原始HTML文件所在路径,Targetp-解析后数据的存储路径
Parser(fs::path Datap, fs::path Targetp);
// 初始化函数:加载HTML路径→解析HTML数据→分割写入数据→记录URL
// 整合了整个解析流程的入口函数
// 返回值:bool-初始化成功返回true,失败返回false
bool Init();
// 加载所有HTML文件的路径到htmlpaths_容器中
// 返回值:bool-加载成功返回true,失败返回false
bool LoadHtmlPath();
// 解析HTML文件:读取文件内容,提取标题、正文和URL
// 将解析结果存储到htmlinfos_容器中
// 返回值:bool-解析成功返回true,失败返回false
bool ParseHtml();
// 对外接口:将解析后的HTML信息写入目标文件(调用内部WriteToTargetFile)
// 返回值:bool-写入成功返回true,失败返回false
bool WriteToTarget();
// 解析文件路径p,生成对应的URL信息并存储到out指针指向的字符串
// 参数:p-文件路径,out-输出的URL字符串指针
// 返回值:bool-解析成功返回true,失败返回false
bool ParseUrl(fs::path p, std::string* out);
// 默认析构函数,无需额外资源释放
~Parser() = default;
private:
std::vector<fs::path> htmlpaths_; // 存储所有待解析的HTML文件路径
std::vector<HtmlInfo_t> htmlinfos_; // 存储解析后的所有HTML信息
std::string output_; // 可能用于临时存储输出数据
fs::path Orignalpath_; // 原始HTML文件所在的根路径
fs::path Targetpath_; // 解析后数据的目标存储路径
};Parser.cc
cpp
#include "Parser.h"
#include "Util.hpp"
#include "common.h"
#include <cstddef>
#include <fstream>
#include <string>
#include <utility>
// 构造函数:初始化原始数据路径和目标路径
Parser::Parser(fs::path Datap, fs::path Targetp)
{
Orignalpath_ = Datap;
Targetpath_ = Targetp;
}
// 初始化入口:加载路径→解析HTML→写入结果
bool Parser::Init()
{
if(!LoadHtmlPath())
{
Log(LogModule::DEBUG) << "LoadHtmlPath fail!";
return false;
}
if(!ParseHtml())
{
Log(LogModule::DEBUG) << "ParseHtml fail!";
return false;
}
if(!WriteToTarget())
{
Log(LogModule::DEBUG) << "WriteToTarget fail!";
return false;
}
return true;
}
// 加载所有HTML文件路径到容器
bool Parser::LoadHtmlPath()
{
// 检查原始路径有效性
if(!fs::exists(Orignalpath_) || !fs::is_directory(Orignalpath_))
{
Log(LogModule::DEBUG) << "Orignalpath is not exists or invalid!";
return false;
}
// 递归遍历目录
fs::recursive_directory_iterator end_it;
fs::recursive_directory_iterator it(Orignalpath_);
for(; it != end_it; it++)
{
// 筛选HTML文件
if(!it->is_regular_file()) continue;
if(it->path().extension() != ".html") continue;
htmlpaths_.push_back(it->path());
}
Log(LogModule::DEBUG) << "Found " << htmlpaths_.size() << " HTML files";
return true;
}
// 解析所有HTML文件内容
bool Parser::ParseHtml()
{
if(htmlpaths_.empty())
{
Log(LogModule::DEBUG) << "paths is empty!";
return false;
}
size_t successCount = 0;
// 遍历所有HTML文件
for(fs::path &p : htmlpaths_)
{
if (!fs::exists(p)) {
Log(LogModule::ERROR) << "File not exists: " << p.string();
continue;
}
std::string out;
HtmlInfo_t info;
// 读取文件内容
if(!ns_util::FileUtil::ReadFile(p.string(), &out))
{
Log(LogModule::ERROR) << "Failed to read file: " << p.string();
continue;
}
// 解析标题、内容、URL
if(!ParseTitle(out, &info.title_))
{
Log(LogModule::ERROR) << "Failed to parse title from: " << p.string();
continue;
}
if(!ParseContent(out, &info.content_))
{
Log(LogModule::ERROR) << "Failed to parse content from: " << p.string();
continue;
}
if(!ParseUrl(p, &info.url_))
{
Log(LogModule::ERROR) << "Failed to parse URL from: " << p.string();
continue;
}
htmlinfos_.push_back(std::move(info));
successCount++;
}
Log(LogModule::INFO) << "Parse HTML completed. Success: " << successCount
<< ", Total: " << htmlpaths_.size();
return successCount > 0;
}
// 整合解析结果并写入目标文件
bool Parser::WriteToTarget()
{
if(htmlinfos_.empty())
{
Log(LogModule::DEBUG) << "infos empty!";
return false;
}
// 拼接所有信息
for(HtmlInfo_t &info : htmlinfos_)
{
output_ += info.title_;
output_ += Output_sep;
output_ += info.content_;
output_ += Output_sep;
output_ += info.url_;
output_ += Line_sep;
}
WriteToTargetFile();
return true;
}
// 解析文件路径生成URL
bool Parser::ParseUrl(fs::path p, std::string *out)
{
fs::path head(Boost_Url_Head);
head = head / p.string().substr(Orignaldir.size());
*out = head.string();
return true;
}
// 从HTML内容中解析标题
bool Parser::ParseTitle(std::string& fdata, std::string* title)
{
if(fdata.empty() || title == nullptr)
{
Log(LogModule::DEBUG) << "parameter invalid!";
return false;
}
// 查找<title>标签
size_t begin = fdata.find("<title>");
size_t end = fdata.find("</title>");
if(begin == std::string::npos || end == std::string::npos)
{
Log(LogModule::DEBUG) << "title find fail!";
return false;
}
begin += std::string("<title>").size();
*title = fdata.substr(begin, end - begin);
return true;
}
// 从HTML内容中解析正文(去除标签)
bool Parser::ParseContent(std::string& fdata, std::string* content)
{
if(fdata.empty() || content == nullptr)
{
Log(LogModule::DEBUG) << "parameter invalid!";
return false;
}
// 状态枚举:标签内/内容区
typedef enum htmlstatus
{
LABEL,
CONTENT
}e_hs;
e_hs statu = LABEL;
// 遍历字符,提取标签外内容
for(char& c: fdata)
{
switch (c)
{
case '<': statu = LABEL; break; // 进入标签状态
case '>': statu = CONTENT; break; // 进入内容状态
default:
if(statu == CONTENT)
*content += (c == '\n' ? ' ' : c); // 替换换行为空格
break;
}
}
return true;
}
// 将整合后的内容写入目标文件
bool Parser::WriteToTargetFile()
{
std::ofstream out;
try
{
// 确保目录存在
auto parent_path = Targetpath_.parent_path();
if (!parent_path.empty())
{
fs::create_directories(parent_path);
}
// 设置缓冲区
const size_t buffer_size = 128 * 1024; // 128KB
std::unique_ptr<char[]> buffer(new char[buffer_size]);
out.rdbuf()->pubsetbuf(buffer.get(), buffer_size);
// 打开文件
out.open(Targetpath_.string(), std::ios::binary | std::ios::trunc);
if (!out)
{
Log(LogModule::ERROR) << "Cannot open file: " << Targetpath_.string()
<< " - " << strerror(errno);
return false;
}
// 写入数据
if (!output_.empty())
{
out.write(output_.data(), output_.size());
if (out.fail())
{
Log(LogModule::ERROR) << "Write failed: " << Targetpath_.string()
<< " - " << strerror(errno);
return false;
}
}
out.flush(); // 刷新缓冲区
if (out.fail())
{
Log(LogModule::ERROR) << "Flush failed: " << Targetpath_.string()
<< " - " << strerror(errno);
return false;
}
Log(LogModule::INFO) << "Written " << output_.size()
<< " bytes to " << Targetpath_.string();
}
catch (const fs::filesystem_error& e)
{
Log(LogModule::ERROR) << "Filesystem error: " << e.what();
return false;
}
catch (const std::exception& e)
{
Log(LogModule::ERROR) << "Unexpected error: " << e.what();
return false;
}
if (out.is_open()) out.close(); // 关闭文件
return true;
}common.h
cpp
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include "Log.hpp"
using std::cout;
using std::endl;
using namespace LogModule;
const std::string Boost_Url_Head = "https://www.boost.org/doc/libs/1_89_0/doc/html";
const std::string Orignaldir = "../Data/html";
const std::string Tragetfile = "../Data/output.txt";
const std::string Output_sep = "\3";
const std::string Line_sep = "\n";
// 不可复制基类
class NonCopyable {
protected:
// 允许派生类构造和析构
NonCopyable() = default;
~NonCopyable() = default;
// 禁止移动操作(可选,根据需求决定)
// NonCopyable(NonCopyable&&) = delete;
// NonCopyable& operator=(NonCopyable&&) = delete;
private:
// 禁止拷贝构造和拷贝赋值
NonCopyable(const NonCopyable&) = delete;
NonCopyable& operator=(const NonCopyable&) = delete;
};Log.hpp
cpp
#ifndef __LOG_HPP__
#define __LOG_HPP__
#include <iostream>
#include <ctime>
#include <string>
#include <pthread.h>
#include <sstream>
#include <fstream>
#include <filesystem>
#include <unistd.h>
#include <memory>
#include <mutex>
namespace LogModule
{
const std::string default_path = "./log/";
const std::string default_file = "log.txt";
enum LogLevel
{
DEBUG,
INFO,
WARNING,
ERROR,
FATAL
};
static std::string LogLevelToString(LogLevel level)
{
switch (level)
{
case DEBUG:
return "DEBUG";
case INFO:
return "INFO";
case WARNING:
return "WARNING";
case ERROR:
return "ERROR";
case FATAL:
return "FATAL";
default:
return "UNKNOWN";
}
}
static std::string GetCurrentTime()
{
std::time_t time = std::time(nullptr);
struct tm stm;
localtime_r(&time, &stm);
char buff[128];
snprintf(buff, sizeof(buff), "%4d-%02d-%02d-%02d-%02d-%02d",
stm.tm_year + 1900,
stm.tm_mon + 1,
stm.tm_mday,
stm.tm_hour,
stm.tm_min,
stm.tm_sec);
return buff;
}
class Logstrategy
{
public:
virtual ~Logstrategy() = default;
virtual void syncLog(std::string &message) = 0;
};
class ConsoleLogstrategy : public Logstrategy
{
public:
void syncLog(std::string &message) override
{
std::cerr << message << std::endl;
}
~ConsoleLogstrategy() override
{
}
};
class FileLogstrategy : public Logstrategy
{
public:
FileLogstrategy(std::string filepath = default_path, std::string filename = default_file)
{
_mutex.lock();
_filepath = filepath;
_filename = filename;
if (std::filesystem::exists(filepath)) // 检测目录是否存在,存在则返回
{
_mutex.unlock();
return;
}
try
{
// 不存在则递归创建(复数)目录
std::filesystem::create_directories(filepath);
}
catch (const std::filesystem::filesystem_error &e)
{
// 捕获异常并打印
std::cerr << e.what() << '\n';
}
_mutex.unlock();
}
void syncLog(std::string &message) override
{
_mutex.lock();
std::string path =
_filepath.back() == '/' ? _filepath + _filename : _filepath + "/" + _filename;
std::ofstream out(path, std::ios::app);
if (!out.is_open())
{
_mutex.unlock();
std::cerr << "file open fail!" << '\n';
return;
}
out << message << '\n';
_mutex.unlock();
out.close();
}
~FileLogstrategy()
{
}
private:
std::string _filepath;
std::string _filename;
std::mutex _mutex;
};
class Log
{
public:
Log()
{
_logstrategy = std::make_unique<ConsoleLogstrategy>();
}
void useconsolestrategy()
{
_logstrategy = std::make_unique<ConsoleLogstrategy>();
printf("转换控制台策略!\n");
}
void usefilestrategy()
{
_logstrategy = std::make_unique<FileLogstrategy>();
printf("转换文件策略!\n");
}
class LogMessage
{
public:
LogMessage(LogLevel level, std::string file, int line, Log &log)
: _loglevel(level)
, _time(GetCurrentTime())
, _file(file), _pid(getpid())
, _line(line),
_log(log)
{
std::stringstream ss;
ss << "[" << _time << "] "
<< "[" << LogLevelToString(_loglevel) << "] "
<< "[" << _pid << "] "
<< "[" << _file << "] "
<< "[" << _line << "] "
<< "- ";
_loginfo = ss.str();
}
template <typename T>
LogMessage &operator<<(const T &t)
{
std::stringstream ss;
ss << _loginfo << t;
_loginfo = ss.str();
//printf("重载<<Logmessage!\n");
return *this;
}
~LogMessage()
{
//printf("析构函数\n");
if (_log._logstrategy)
{
//printf("调用打印.\n");
_log._logstrategy->syncLog(_loginfo);
}
}
private:
LogLevel _loglevel;
std::string _time;
pid_t _pid;
std::string _file;
int _line;
std::string _loginfo;
Log &_log;
};
LogMessage operator()(LogLevel level, std::string filename, int line)
{
return LogMessage(level, filename, line, *this);
}
~Log()
{
}
private:
std::unique_ptr<Logstrategy> _logstrategy;
};
static Log logger;
#define Log(type) logger(type, __FILE__, __LINE__)
#define ENABLE_LOG_CONSOLE_STRATEGY() logger.useconsolestrategy()
#define ENABLE_LOG_FILE_STRATEGY() logger.usefilestrategy()
}
#endifUtil.hpp
cpp
#pragma once
#include "common.h"
#include <fstream>
#include <sstream>
namespace ns_util
{
class FileUtil : public NonCopyable
{
public:
static bool ReadFile(std::string path, std::string* out)
{
std::fstream in(path, std::ios::binary | std::ios::in);
if(!in.is_open())
{
Log(LogModule::DEBUG) << "file-" << path << "open fail!";
return false;
}
std::stringstream ss;
ss << in.rdbuf();
*out = ss.str();
in.close();
return true;
}
};
};makefile
makefile
# 编译器设置
CXX := g++
CXXFLAGS := -std=c++17
LDFLAGS :=
LIBS := -lboost_filesystem -lboost_system
# 目录设置
SRC_DIR := .
BUILD_DIR := build
TARGET := main
# 自动查找源文件
SRCS := $(wildcard $(SRC_DIR)/*.cc)
OBJS := $(SRCS:$(SRC_DIR)/%.cc=$(BUILD_DIR)/%.o)
DEPS := $(OBJS:.o=.d)
# 确保头文件依赖被包含
-include $(DEPS)
# 默认目标
all: $(BUILD_DIR) $(TARGET)
# 创建构建目录
$(BUILD_DIR):
@mkdir -p $(BUILD_DIR)
# 链接目标文件生成可执行文件
$(TARGET): $(OBJS)
$(CXX) $(OBJS) -o $@ $(LDFLAGS) $(LIBS)
@echo "✅ 构建完成: $(TARGET)"
# 编译每个.cc文件为.o文件
$(BUILD_DIR)/%.o: $(SRC_DIR)/%.cc
$(CXX) $(CXXFLAGS) -MMD -MP -c $< -o $@
# 清理构建文件
clean:
rm -rf $(BUILD_DIR) $(TARGET)
@echo "🧹 清理完成"
# 重新构建
rebuild: clean all
# 显示项目信息
info:
@echo "📁 源文件: $(SRCS)"
@echo "📦 目标文件: $(OBJS)"
@echo "🎯 最终目标: $(TARGET)"
# 伪目标
.PHONY: all clean rebuild info
# 防止与同名文件冲突
.PRECIOUS: $(OBJS)main.cc
cpp
#include "common.h"
#include "Parser.h"
int main()
{
Parser parser(Orignaldir, Tragetfile);
parser.Init();
return 0;
}