论文题目:Prompt-Free Diffusion: Taking "Text" out of Text-to-Image Diffusion Models(无提示扩散:从文本到图像的扩散模型中提取"文本")
会议:CVPR2024
摘要:由于大规模的预训练扩散模型和许多新兴的个性化和编辑方法,文本到图像(T2I)的研究在过去的一年中呈爆炸式增长。然而,一个痛点仍然存在:文本提示工程和搜索高质量的文本提示以获得定制结果更像是艺术而不是科学。此外,正如人们常说的那样:"一张图片胜过千言万语"------试图用文字描述一个理想的图像往往会变得模棱两可,无法全面覆盖微妙的视觉细节,因此需要更多来自视觉领域的额外控制。在本文中,我们向前迈出了大胆的一步:将"文本"从预训练的T2I扩散模型中取出,以减少用户繁琐的提示工程工作。我们提出的框架,提示-自由扩散,仅依赖于视觉输入来生成新图像:它将参考图像作为"上下文",可选的图像结构条件和初始噪声,绝对没有文本提示。背后的核心架构是语义上下文编码器(SeeCoder),它取代了常用的基于clip或基于llm的文本编码器。SeeCoder的可重用性也使它成为一个方便的插入式组件:人们也可以在一个T2I模型中预训练SeeCoder并将其重用于另一个模型。通过大量的实验,实验发现(i)优于先前基于示例的图像合成方法;(ii)按照最佳做法使用提示,达到最先进的T2I模型的水平;(3)可自然扩展到其他下游应用,如动漫人物生成和虚拟试戴,质量良好。我们的代码和模型将是开源的。
源码链接:https://github.com/SHI-Labs/Prompt-Free-Diffusion
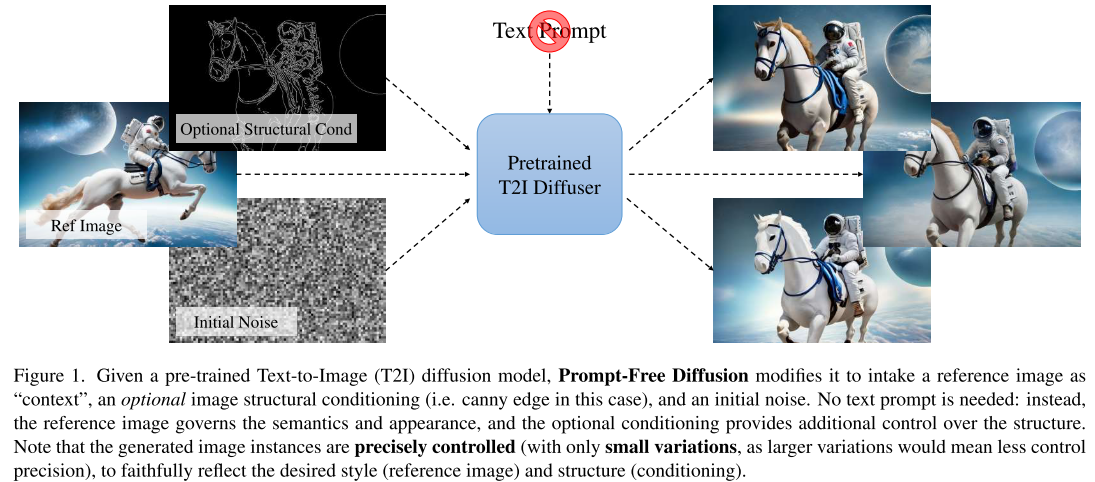
前言
你是否也被复杂的AI绘画提示词搞得头疼?是否花了大量时间调试各种关键词组合,却始终无法生成心目中的完美图像?CVPR 2024的一篇重磅论文为我们带来了解决方案 - Prompt-Free Diffusion,让我们彻底告别提示工程的烦恼。
问题的根源
当前的文本到图像生成技术虽然令人惊艳,但存在一个根本性问题:文本与视觉之间的天然鸿沟。
想象一下,你想要生成一张特定风格的城市夜景图。你可能需要这样的提示词:
"fantasy medieval dystopian city streets, vibrant light, hyper detailed, realistic, dynamic lighting, 8k, yellow and blue candles, rain and fog"即使如此详细的描述,生成的结果可能仍然与你的期望相去甚远。这是因为:
- 语言的局限性:文字难以精确描述复杂的视觉细节
- 提示工程的复杂性:需要掌握特定的关键词和语法规则
- 效果的不可预测性:相似的提示可能产生截然不同的结果
Prompt-Free Diffusion的革命性思路
研究团队提出了一个大胆的想法:既然图像本身就是最好的"提示",为什么不直接用图像来指导图像生成呢?
核心架构
Prompt-Free Diffusion的工作流程非常直观:
- 输入一张参考图像 - 提供风格、色彩、纹理等视觉信息
- 可选的结构条件 - 如边缘检测、深度图等,控制生成图像的结构
- 随机噪声 - 确保生成结果的多样性
整个过程完全不需要文本提示!
技术核心:SeeCoder
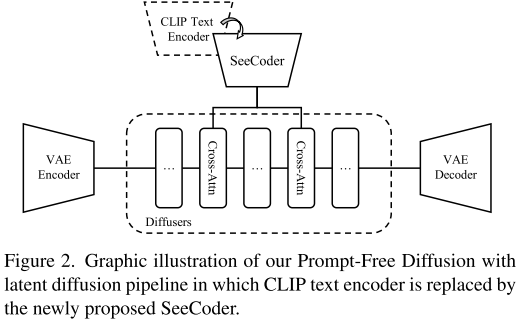
论文的技术核心是名为SeeCoder(Semantic Context Encoder)的创新组件,它替代了传统T2I模型中的CLIP文本编码器。
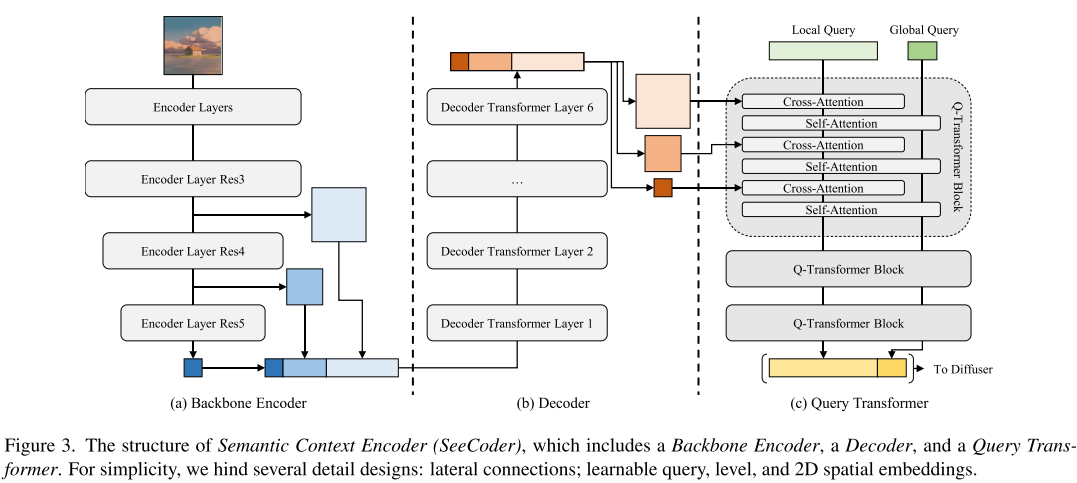
SeeCoder的三个关键组件:
- Backbone Encoder:使用SWIN-L架构处理任意分辨率的图像
- Decoder:基于Transformer的网络,整合不同层级的特征
- Query Transformer:将复杂的视觉特征转换为可供扩散模型使用的嵌入向量
实际效果如何?
与传统方法的对比


研究团队进行了大量对比实验,结果令人印象深刻:
- 质量对比:Prompt-Free Diffusion生成的图像质量可以匹敌使用复杂提示词的最先进模型
- 控制精度:在纹理、色彩、风格复制方面表现出色
- 稳定性:避免了提示工程中的试错过程,结果更可预测
通用性验证
更令人惊喜的是,SeeCoder具有出色的即插即用特性。研究团队测试了7个不同的开源模型:
- Stable Diffusion 1.5
- AnythingV4
- OpenJourney-V4
- RealisticVision-V2
- 等等
在所有模型上都取得了良好效果,无需额外训练。
应用场景展示
1. 风格迁移
只需提供一张参考图像,就能生成相同风格的新图像,保持原有的艺术特色和视觉效果。
2. 结构控制
结合ControlNet等结构控制工具,可以精确控制生成图像的构图和结构。
3. 创意应用
- 动漫人物生成:基于参考图像生成不同姿态的动漫角色
- 虚拟试穿:在服装设计和电商领域的应用
- 图像变体:生成同一主题的多种变化
技术实现细节
对于技术爱好者,这里简单介绍一些实现细节:
训练数据
- 使用Laion2B-en和COYO-700M数据集
- 只使用图像数据,不依赖文本标注
模型架构
- 保持原有的潜在扩散模型(LDM)架构
- 用SeeCoder替换CLIP文本编码器
- 支持多种分辨率和宽高比
训练策略
- 100k次迭代训练
- 两阶段学习率调整
- 位置感知版本(SeeCoder-PA)提供更好的空间理解
局限性与未来展望
虽然Prompt-Free Diffusion表现出色,但仍有一些局限:
- 创意表达:完全去除文本可能限制某些抽象概念的表达
- 精确控制:对于需要精确文字描述的场景(如特定物体组合),可能不如文本提示直接
- 计算资源:SeeCoder的训练仍需要大量计算资源
对行业的影响
Prompt-Free Diffusion的出现可能带来以下变化:
- 降低使用门槛:普通用户无需学习复杂的提示工程技巧
- 提高工作效率:设计师和艺术家可以更直观地表达创意想法
- 新的交互范式:从文本驱动转向图像驱动的生成模式
结语
Prompt-Free Diffusion代表了AI图像生成技术的一个重要转折点。它不仅解决了提示工程的痛点,更重要的是提供了一种更自然、更直观的人机交互方式。
虽然文本提示在某些场景下仍有其价值,但对于大多数用户而言,"一图胜千言"的Prompt-Free方法无疑更具吸引力。随着技术的进一步发展,我们有理由相信,未来的AI图像生成将更加贴近人类的自然思维方式。
这项研究不仅在技术上取得了突破,更在用户体验方面开辟了新的可能性。对于AI艺术创作者、设计师,以及所有对AI绘画感兴趣的朋友来说,这都是一个值得关注的重要进展。