本文档旨在为运维人员和开发人员提供fuse-client进程部署方案的选型参考
背景介绍
司内使用自研的polefs共享存储,每挂载一个卷都会运行一个常驻的polefs-client进程。polefs-client运行方案有如下三种:
1、polefs-client进程运行在csi-node-driver pod中。
2、多个pod使用共享的polefs-client进程。
3、多个pod使用各自独占的polefs-client。
运行方案对比
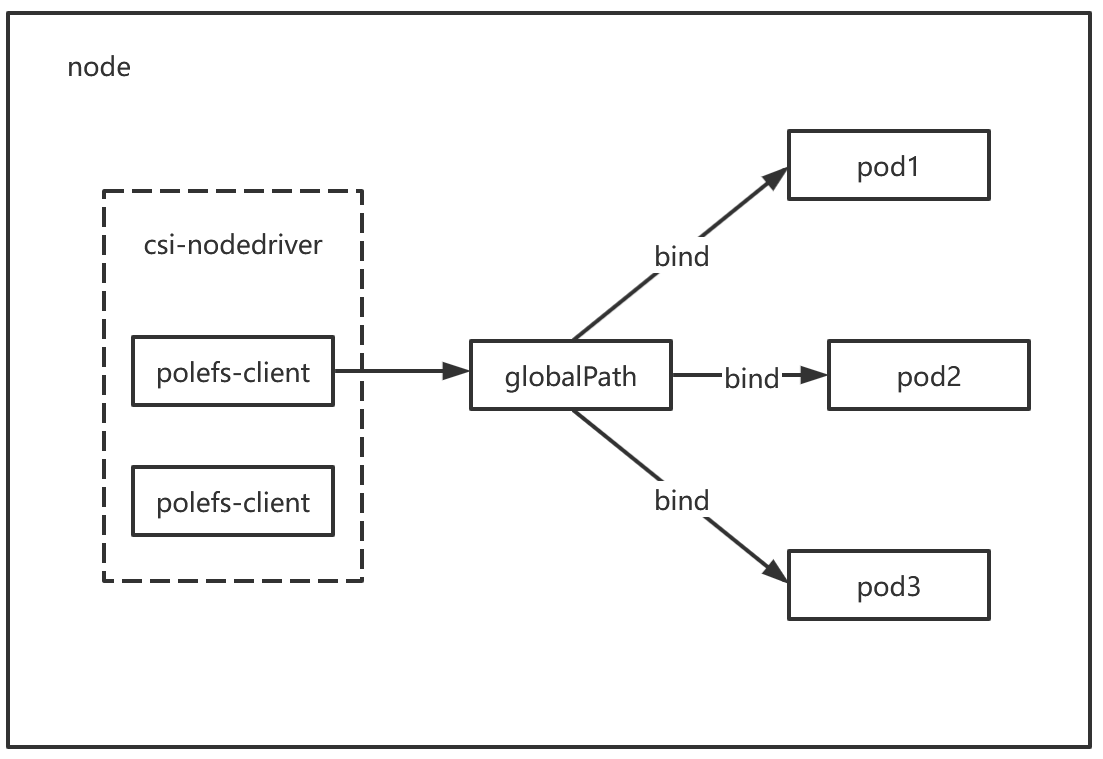
方案一:共享式客户端(polefs-client进程运行在csi-node-driver pod中)
**架构描述:**polefs-client 作为 Sidecar 进程,与 csi-node-driver 运行在同一个 DaemonSet Pod 中。节点上的不同卷挂载会启动多个polefs-client进程。
**主要风险:**升级与中断问题。
**问题说明:**该方案将存储客户端的生命周期与 CSI 驱动绑定。当需要升级 CSI 组件而重启或重建 Pod 时,polefs-client 进程会随之终止,导致依赖它的所有业务 Pod 出现存储 I/O 中断,影响面较大。
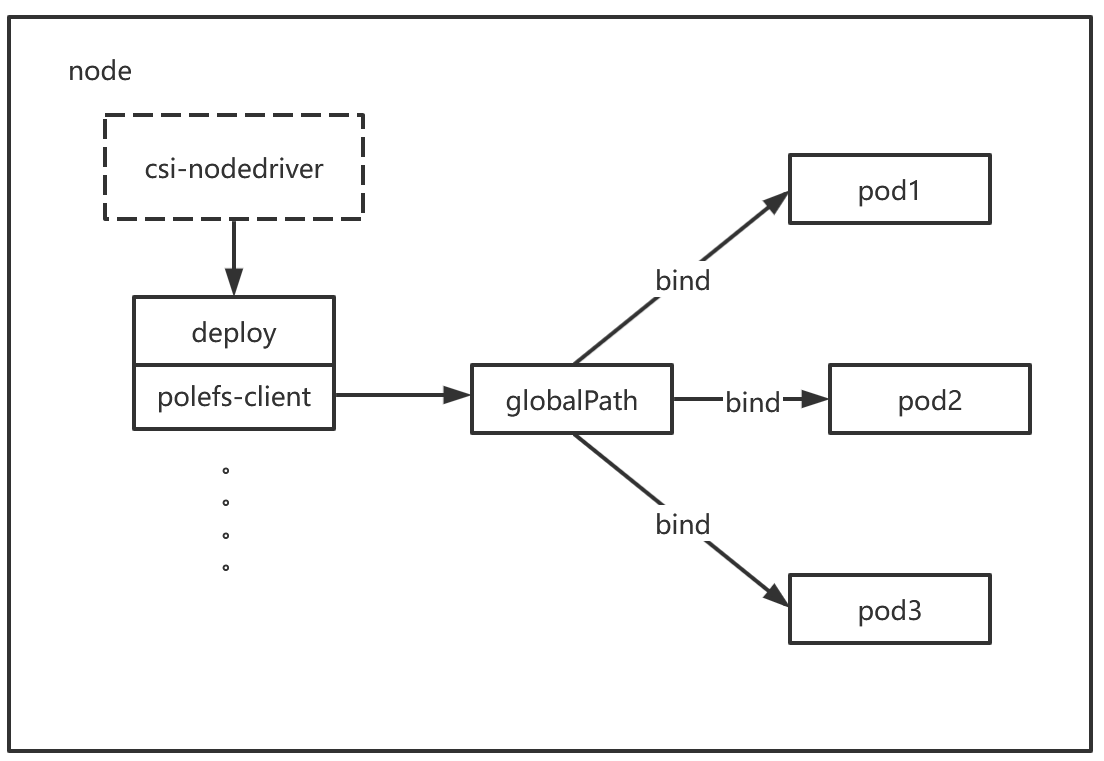
方案二:为每个PVC创建专属Client Deployment
架构描述 :CSI Node Driver 会为每个PVC动态创建一个独立的Deployment,用以运行 polefs-client 进程。节点上的多个Pod若挂载同一PVC,则共享这个客户端实例。
优点:
-
解耦升级 :CSI驱动升级不会中断
polefs-client服务,避免了方案一中的业务影响问题。 -
资源效率:资源消耗与方案一相当,保持了共享资源的优势。
缺点:
-
客户端升级困难 :此架构导致
polefs-client自身的版本更新变得异常复杂。直接更新Deployment的镜像会触发Pod重启,导致所有关联业务Pod的存储中断。标准的滚动更新策略在此场景下无效,因为无法先驱逐所有使用该存储的业务Pod。 -
运维成本高 :迫不得已时,只能通过人工手动逐一驱逐(drain)所有关联的业务Pod,此过程耗时费力、容易出错,并对服务连续性产生负面影响。鉴于我方场景中
polefs-client更新频繁,此缺点将被急剧放大。
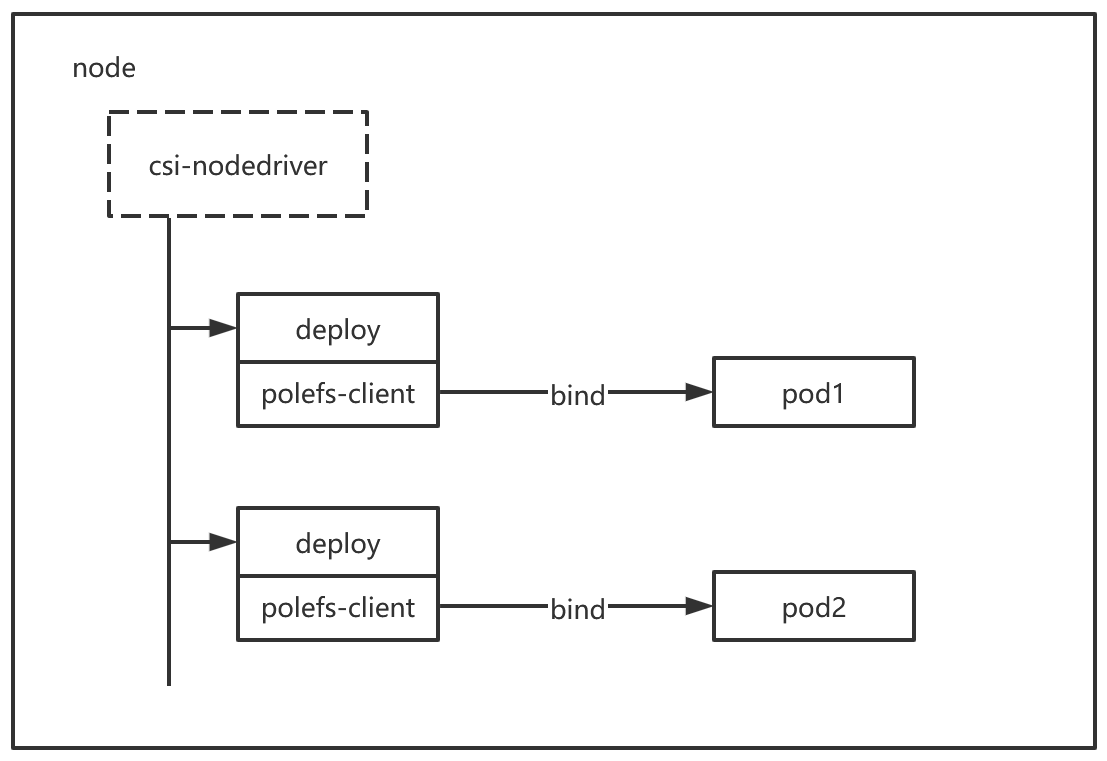
方案三:Pod级专属客户端
架构描述: 此为方案二的优化版本。核心思想是将 polefs-client 与业务 Pod 的生命周期完全绑定。CSI Driver 会为每一个使用了 PVC 的业务 Pod 单独创建一个对应的 polefs-client Deployment。
优点:
彻底解耦:不仅 CSI 驱动的升级不会影响业务,连 polefs-client 自身的升级也与业务应用同步。更新客户端镜像时,只需滚动更新用户的业务 Deployment/StatefulSet 即可。业务 Pod 的重建会触发其专属客户端随之更新,过程完全自动化且对用户无感。
隔离性最佳:每个客户端实例仅服务一个业务 Pod,实现了故障和生命的周期的完美隔离。
缺点:
资源开销增加:这是为获得极致灵活性与隔离性所付出的主要代价。相较于前两种共享方案,此方案会消耗更多的 CPU 和内存资源,因为客户端实例数量与业务 Pod 数量成正比。
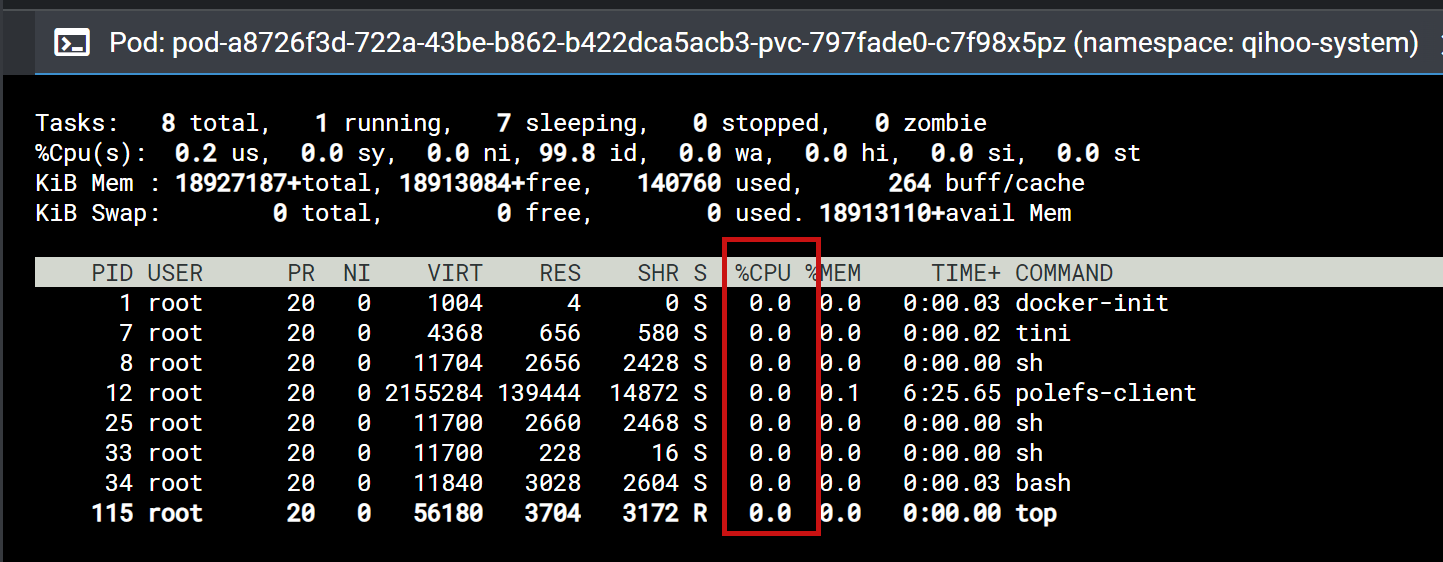
360内部共享存储client资源占用分析
1、polefs-client进程运行资源占用。进程的运行基本上不消耗cpu资源,物理内存大概消耗40M左右
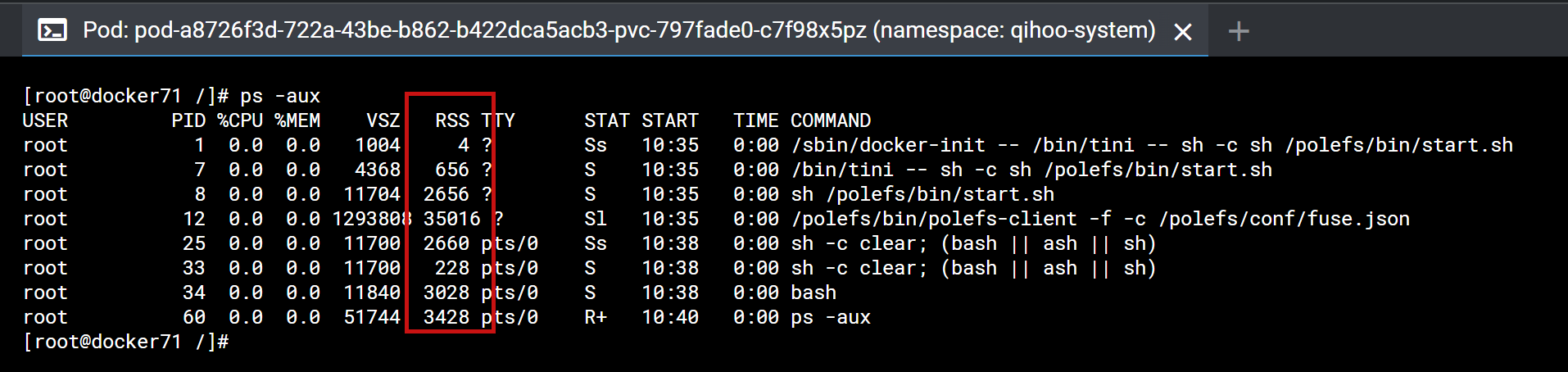
2、在大量读写的情况下,polefs-client内存与cpu的占用;并且确认在读写结束后,polefs-client会释放占用的内存与cpu。
在pod的挂载内执行dd指令模拟大量读写的场景,指令如下:
dd if=/dev/zero of=./image bs=8k count=10485760 oflag=direct #写
dd if=/data/image of=/dev/null bs=32k oflag=direct #读
可以看到在大量读写的时候cpu占用2c,内存占用400M左右。
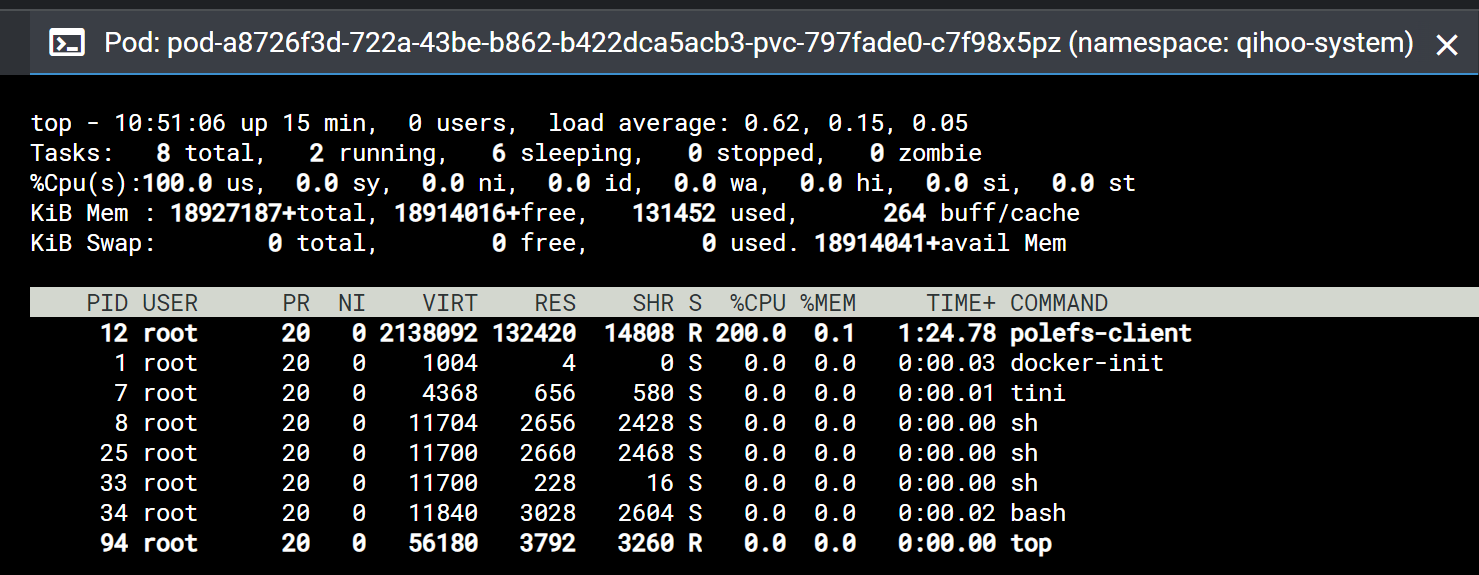
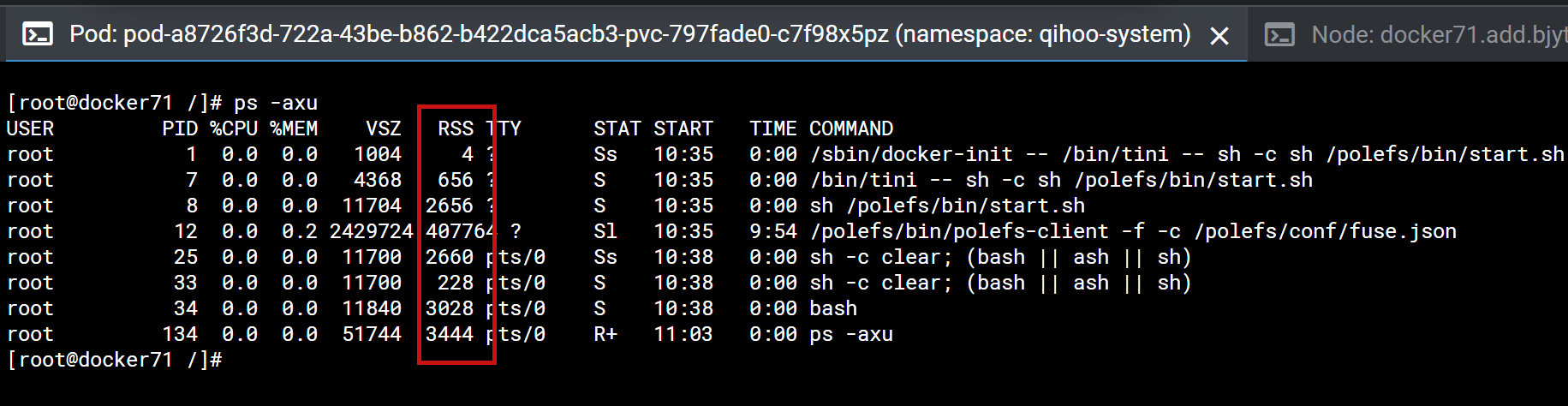
等待读写完成,过段时间再查看polefs-client的cpu与内存占用情况,可以看到,内存使用量降到100M以下。
总结:1、polefs-client进程本身占用资源并不多
2、在大量读写时polefs-client会占用大量cpu,并随着读写不断进行,占用的物理内存资源也在不断升高。
3、随着读写的完成,占用的cpu资源会立马降低。占用的内存资源过段时间后会逐渐降低(大约10min)
总结
| 方案 | 资源占用 | 升级影响 | 版本更新复杂度 | 适用场景 |
|---|---|---|---|---|
| 方案一:共享进程 | 低(单进程40M内存) | 升级csi时中断业务 | 需中断业务 | 非频繁更新场景 |
| 方案二:PVC专属Deploy | 低(同方案一) | 升级csi无影响 | 需手动驱逐Pod,风险高 | 版本更新较少场景 |
| 方案三:Pod专属Deploy | 较高(每个Pod独占资源) | 升级无影响 | 支持滚动更新 | 频繁更新场景(如360场景) |
1、线上用户创建多副本时比如创建了30副本,基本会均匀的分布在不同节点(分布的越均匀第二种与第三种方案性能开销就越接近)。
2、大部分线上用户使用polefs保存一些配置文件,大量读写的情况很少。
如果单方面的只考虑资源开销前两种方案占用资源要比第三种方案低, 但结合线上使用情况、运维成本与polefs-client资源占用情况,个人认为第三种方案更符合公司内部的场景。