引言:在C++标准库(STL)中,std::vector 是最重要且最常用的容器之一。它结合了动态数组的高效随机访问和动态内存管理的灵活性,成为现代C++开发中不可或缺的数据结构。
目录
[(1)下标 形式](#(1)下标[ ]形式)
[(2) 迭代器访问](#(2) 迭代器访问)

vector的介绍
vector是表示可变大小数组的序列容器。 就像数组一样,vector也采用的连续存储空间来存储元素。也就是意味着可以采用下标对vector的元素进行访问,和数组一样高效。但是又不像数组,它的大小是可以动态改变的,而且它的大小会被容器自动处理。
vector的本质优势
从本质讲,vector使用动态分配数组来存储它的元素。当新元素插入时候,这个数组需要被重新分配大小为了增加存储空间。其做法是,分配一个新的数组,然后将全部元素移到这个数组。就时间而言,这是一个相对代价高的任务,因为每当一个新的元素加入到容器的时候,vector并不会每次都重新分配大小。
vector分配空间策略:vector会分配一些额外的空间以适应可能的增长 ,因为存储空间比实际需要的存储空间更大。不同的库采用不同的策略权衡空间的使用和重新分配。但是无论如何,重新分配都应该是对数增长的间隔大小,以至于在末尾插入一个元素的时候是在常数时间的复杂度完成的。
因此,vector占用了更多的存储空间,为了获得管理存储空间的能力,并且以一种有效的方式动态增长。与其它动态序列容器相比(deque, list and forward_list),
vector在访问元素的时候更加高效,在末尾添加和删除元素相对高效。对于其它不在末尾的删除和插入操作,效率更低。比起list和forward_list 统一的迭代器和引用更好。
vector的定义
vector在实际中非常的重要,在实际中我们熟悉常见的接口就可以,下面列出了哪些接口是要重点掌握的。

vector的使用
1)实例化
我们可以使用 vector<类型> 变量名,后面可以选择无参、有参初始化,例如:
cpp
//实例化
vector<int> S1;
vector<char> S2;
vector<char> S3(5);
vector<string> S4(10, "***");
vector<string>S2(S1.begin(), S1.end());(1)第一个为int类型和第二个为char类型属于无参实例化
(2)第三个类型为char,开辟了5个元素空间
(3)第四个类型为string,10个string对象都指定初始化为了"***"
(4)第五种属于用迭代器去初始化
这里我们再打开vs2022监视窗口查看一下
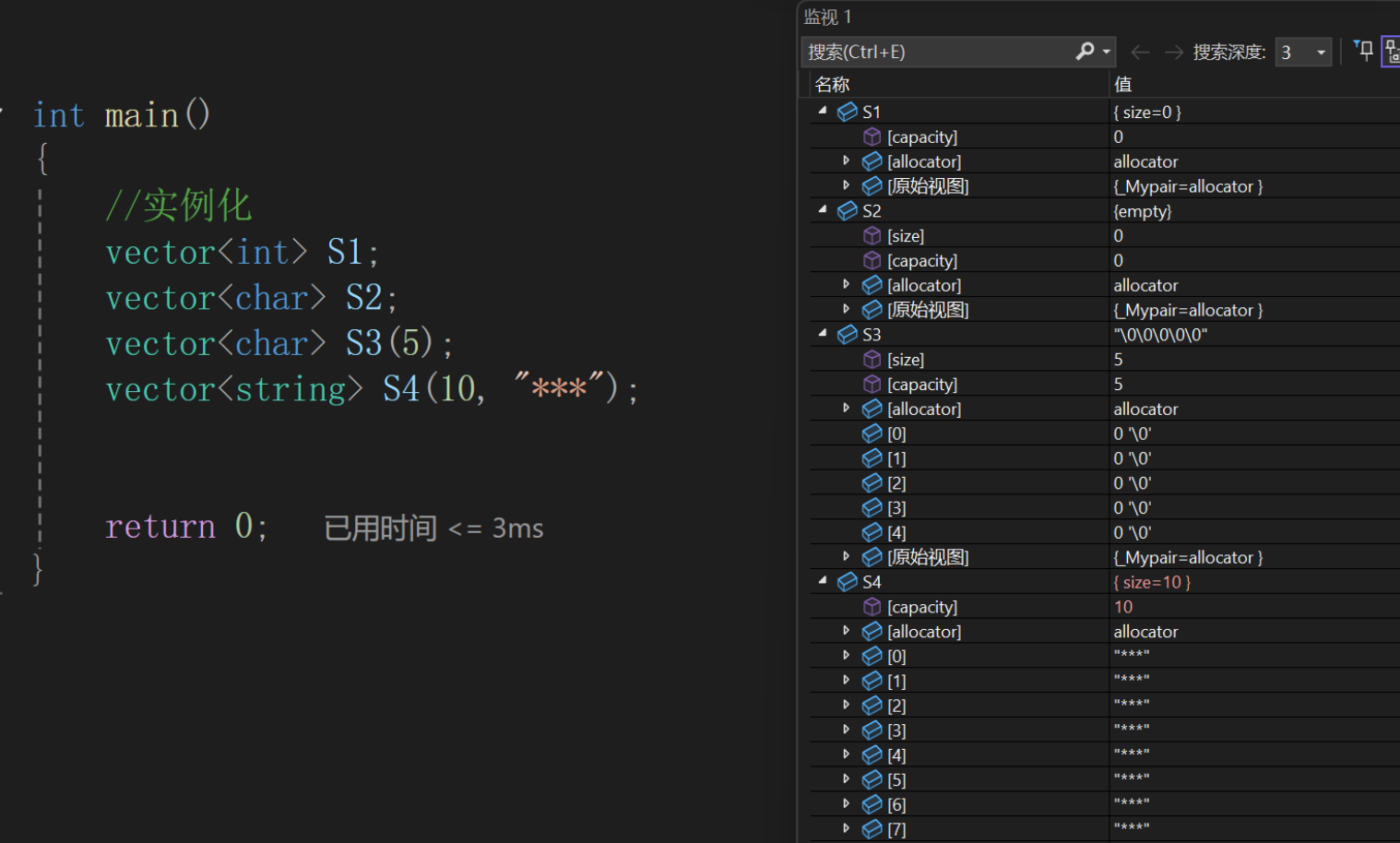
发现符合我们的猜想。那我们接下来再看看看尾插和尾删
2)尾插尾删
尾插尾删和我们之前学习的string很像,包括自动扩容,自动更改数据个数,只是调用对象不同,例如:
cpp
S1.push_back(1);
S1.pop_back();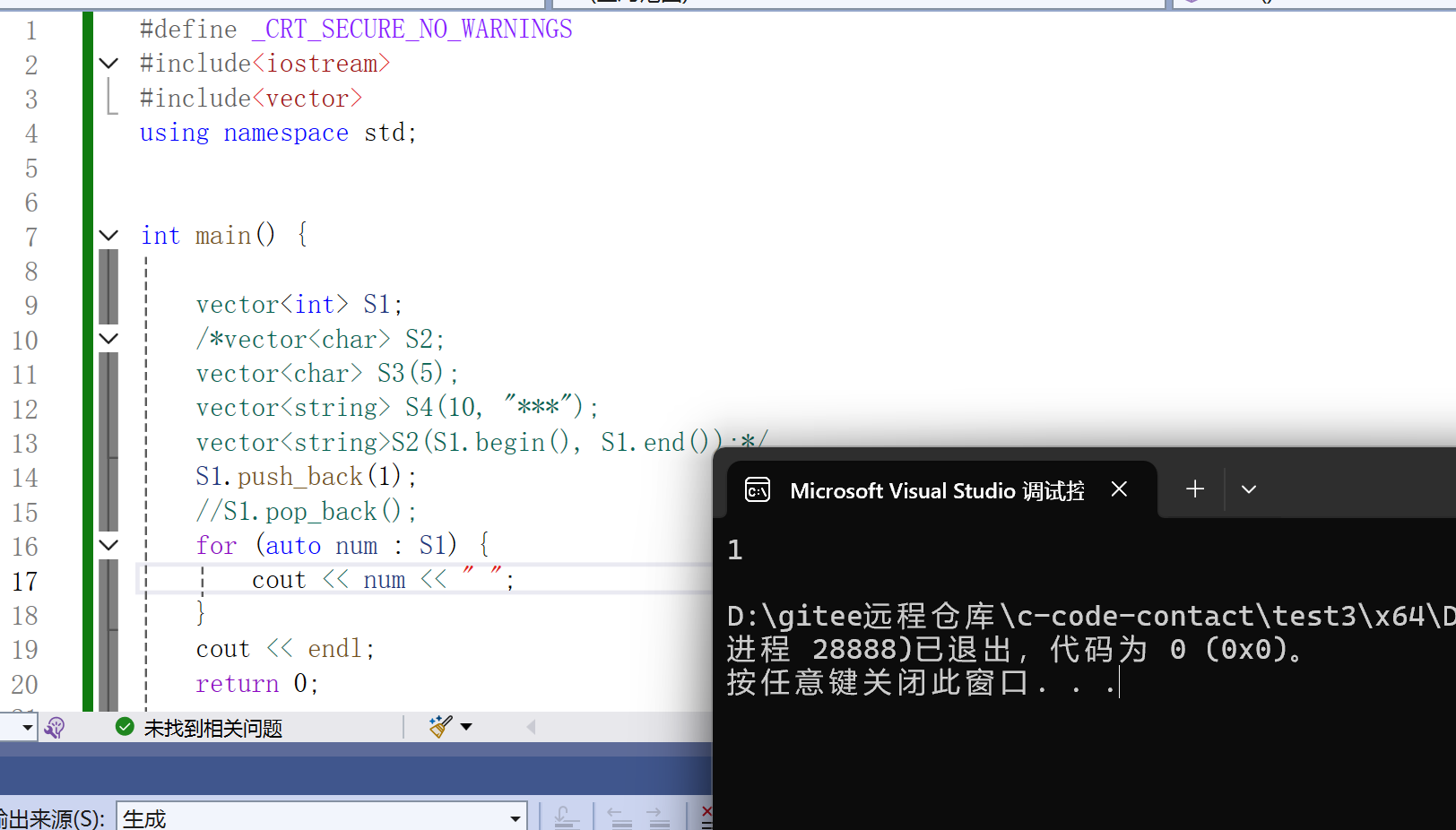
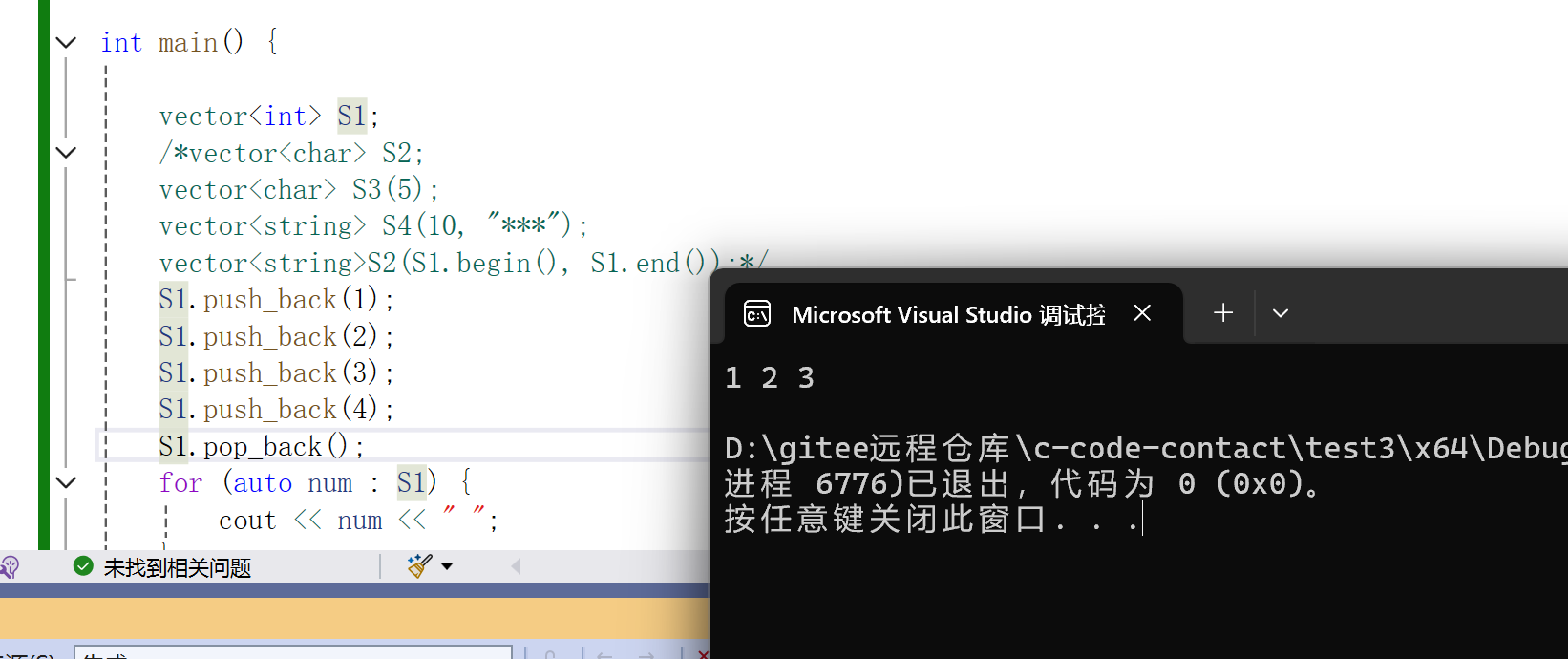
这里我们可以看到输出尾插尾删后的结果,不过要注意的是C++ 没有为 vector 重载 << 运算符,必须手动遍历输出。也就是循环,不过这里就涉及我们前面所说的范围for了,使用范围for可以更加便捷。
3)访问元素
(1)下标 形式
也就是数组的形式一样。
cpp
//下标括号访问
for (int i = 0; i < S1.size(); i++)
{
cout << S1[i] << " ";
}(2) 迭代器访问
cpp
//迭代器访问
vector<string>::iterator it = S1.begin();
while (it != S1.end())
{
cout << *it << " ";
it++;
}(3)范围for
如上图。运行截图如下:
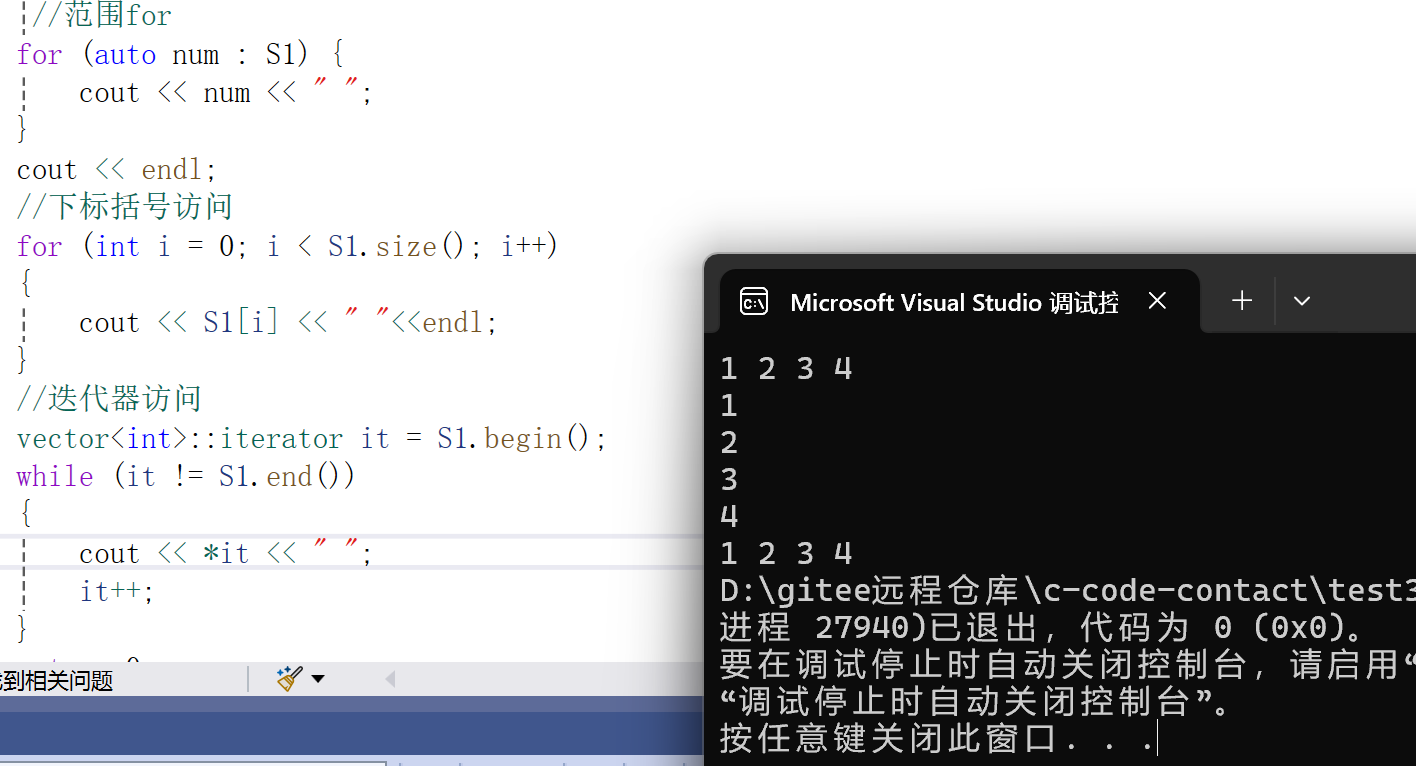
获取元素个数
cpp
S1.size();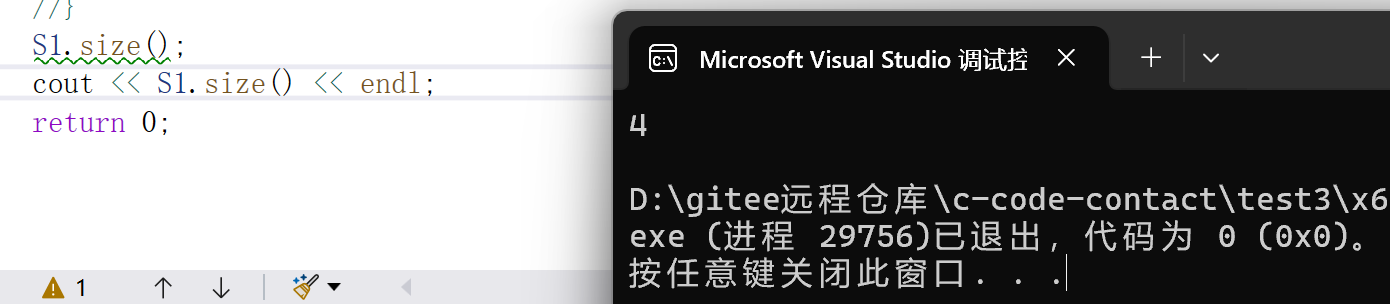
排序(顺序)
将元素按照从小到大的顺序去排序获取结果,这个sort排序接口不属于vector里面的,属于公有的接口,需要添加算法库的头文件:<algorithm>,同时排序会改变元素本来的位置(sort排序是不稳定的排序,这个后续map和set会讲)
cpp
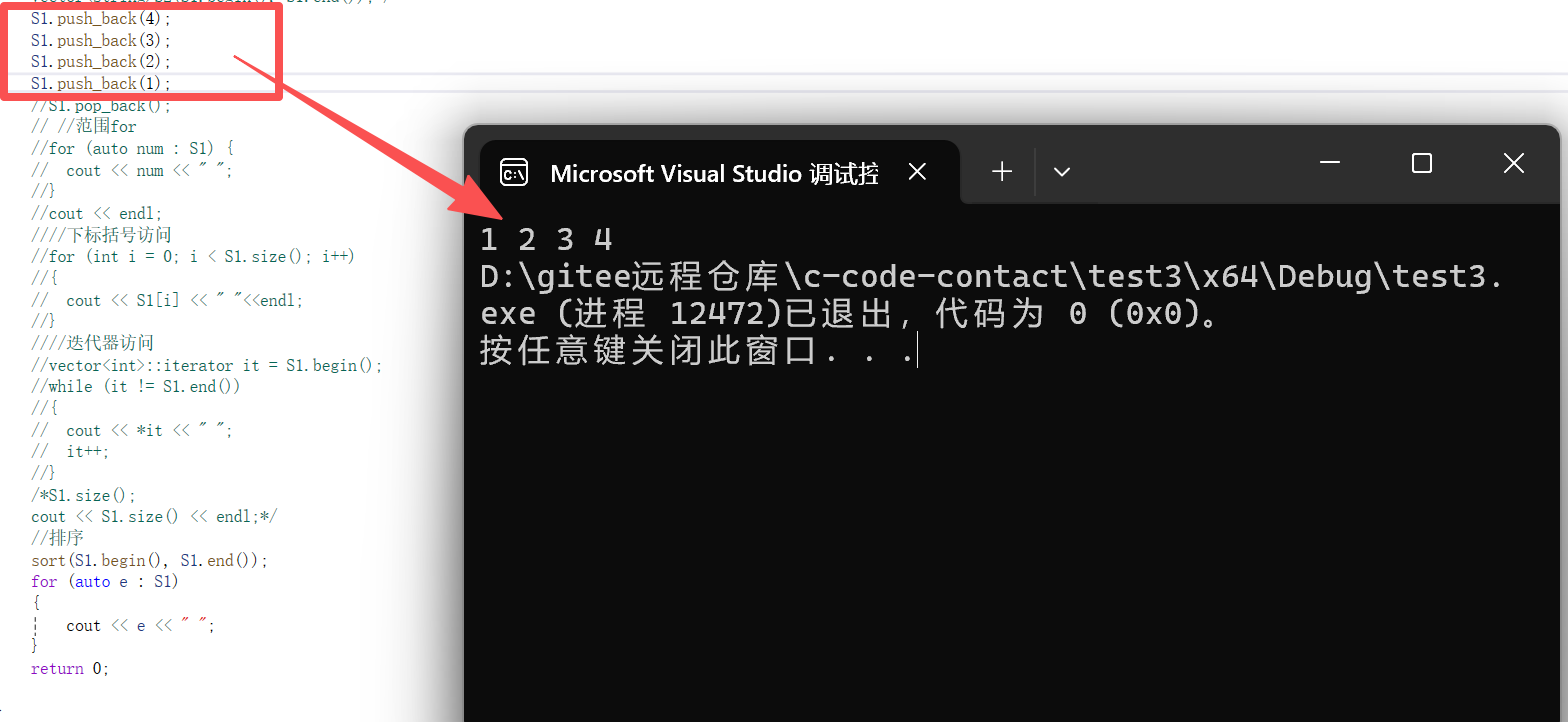
//排序
sort(S1.begin(), S1.end());
for (auto e : S1)
{
cout << e << " ";
}
排序(逆序)
这里有两种方法,同样都是使用迭代器,但是参数不同
1)只修改迭代器
cpp
sort(S1.rbegin(), S1.rend());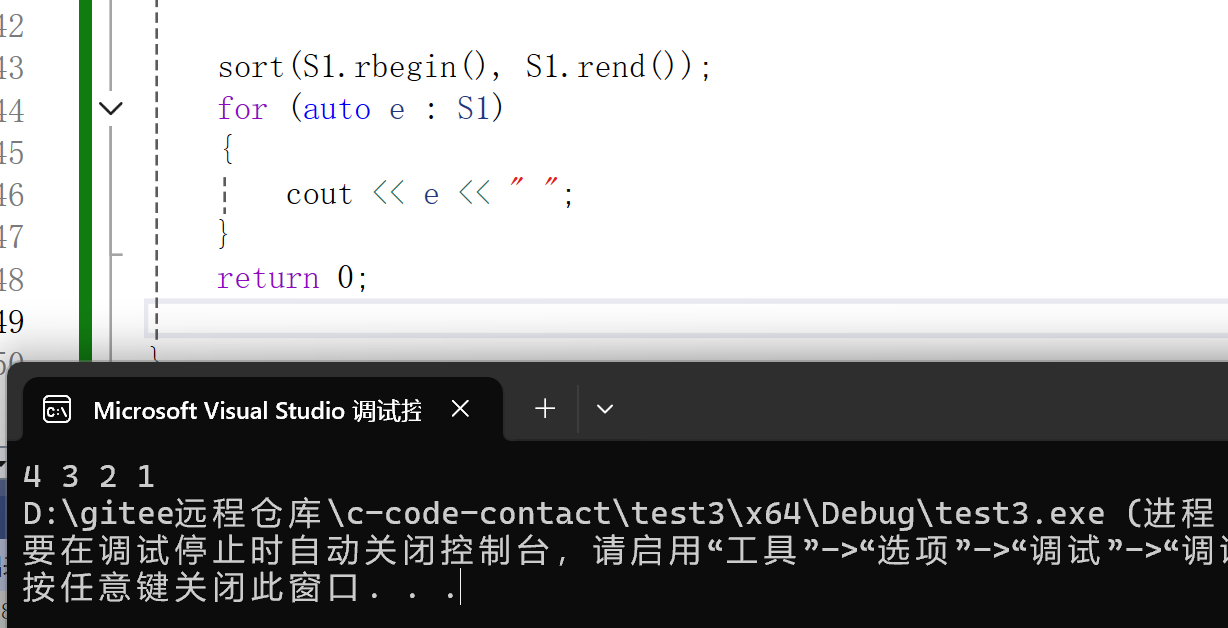
2)添加greater参数
cpp
sort(S1.begin(), S1.end(), greater<int>());
sort(S1.begin(), S1.end(), gt);这里的gt是命名对象,greater<int>()是匿名对象。

调整容量
注意:reserve 虽然会调整容量,但是不会更改size元素个数。
cpp
S1.reserve(10);调整容量+初始化
cpp
S1.resize(10,"**");查找指定内容
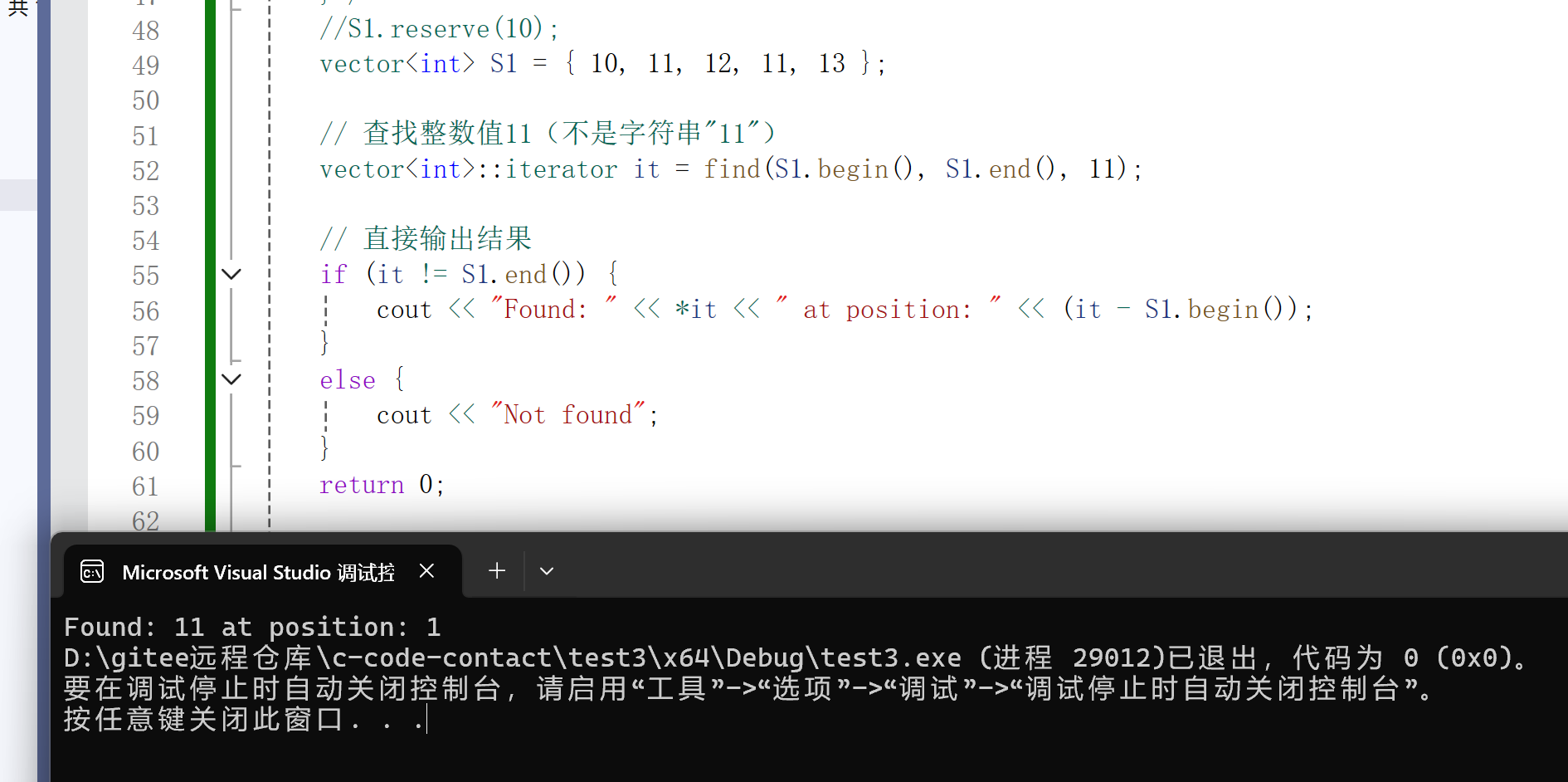
这里的 find 不属于vector,而是算法模拟实现的。
cpp
vector<int>::iterator it = find(S1.begin(), S1.end(), "11");
while (it != S1.end())
{
if (*it == "11")
{
cout << *it;
}
++it;
}
指定位置前插入
cpp
S1.insert(S1.begin(),"100");删除指定位置
cpp
S1.erase(S1.end() - 1);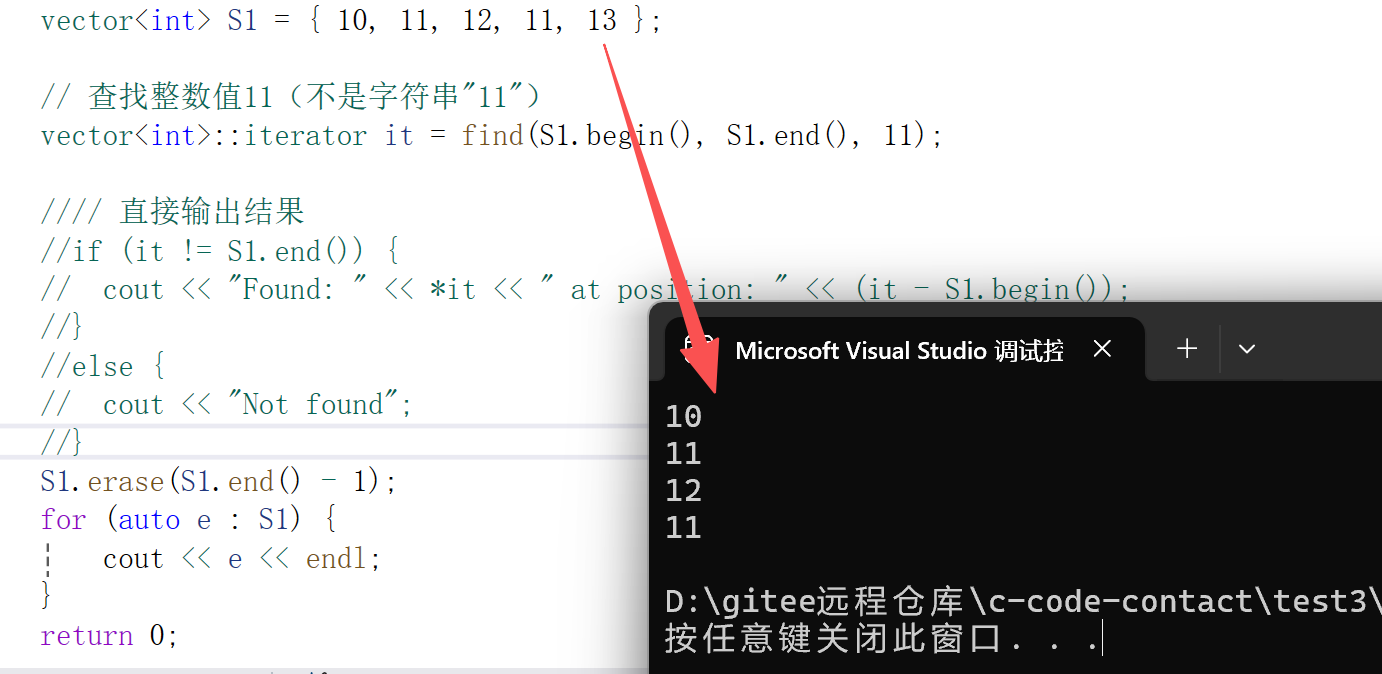
去重
unqiue :返回一个迭代器,指向去重后序列的末尾(即最后一个不重复元素的下一个位置)
cpp
auto new_end = erase(begin() , end());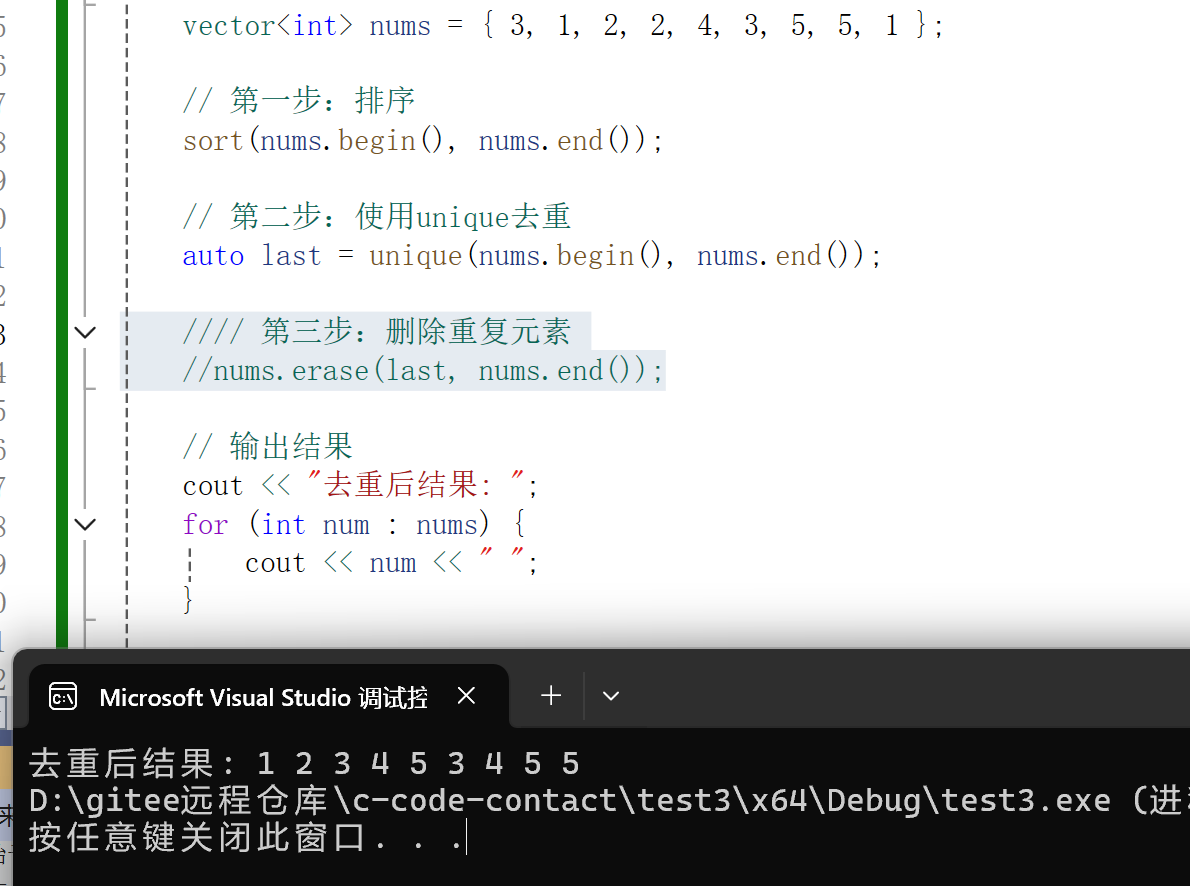
这里指针指向的是去重后第一个3。