温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目简介
心血管疾病(CVD)是全球范围内导致死亡的主要原因之一。早期识别和预防心血管疾病对于减少发病率和死亡率至关重要。本项目旨在开发一个基于机器学习的心血管疾病智能预测系统,利用数据挖掘和机器学习技术对患者的健康数据进行分析,提前预测潜在的心血管疾病风险,并提供相应的干预建议。该系统将涵盖数据收集、预处理、特征工程、模型训练、预测和结果展示等多个环节,旨在为医疗保健机构和个人用户提供一个全面的心血管疾病预警平台。通过该系统,用户可以更方便地了解自己的心血管疾病风险,并采取适当的预防措施。
2. 关键技术点
- Python:用于后端逻辑处理和API接口开发。
- Pandas:用于数据清洗、特征提取和预处理操作。
- NumPy:用于数值计算,提高数据处理效率。
- Matplotlib/Seaborn:用于数据可视化,帮助用户直观地了解数据分布和特征。
- Scikit-learn/XGBoost:用于机器学习算法和梯度提升树模型的实现。
- Flask:轻量级Web应用框架,用于构建后端服务。
- Bootstrap:前端框架,用于构建响应式的网页布局。
3. 心血管疾病预测建模
3.1 数据来源与特征
数据集字段说明:
- Age: 年龄(天数)
- Height: 身高(厘米)
- Weight: 体重(公斤)
- Gender: 性别(分类编码)
- ap_hi: 收缩压
- ap_lo: 舒张压
- Cholesterol: 胆固醇水平(1:正常, 2:高于正常, 3:远高于正常)
- Glucose: 血糖水平(1:正常, 2:高于正常, 3:远高于正常)
- Smoke: 吸烟(二进制)
- Alcohol: 饮酒(二进制)
- Active: 体力活动(二进制)
- Cardio: 心血管疾病(目标变量,二进制)
python
# 加载数据
df = pd.read_csv('cardio_train.csv')
print("数据集基本信息:")
print(f"数据集形状: {df.shape}")
print(f"\n前5行数据:")
df.head()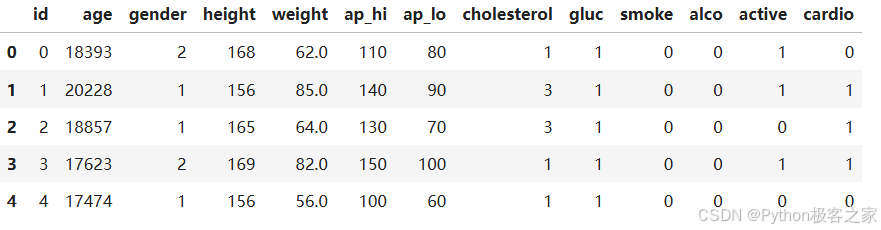
3.2 数据预处理和特征工程
python
# 数据预处理
# 将年龄从天数转换为年数
df['age_years'] = df['age'] / 365.25
# 计算BMI
df['bmi'] = df['weight'] / ((df['height'] / 100) ** 2)
# 创建血压分类特征
......
df['bp_category'] = df.apply(lambda x: categorize_bp(x['ap_hi'], x['ap_lo']), axis=1)
# 检查异常值
......
# 移除明显的异常值
df_clean = df[
(df['height'] >= 140) & (df['height'] <= 200) &
(df['weight'] >= 40) & (df['weight'] <= 150) &
(df['ap_hi'] >= 80) & (df['ap_hi'] <= 200) &
(df['ap_lo'] >= 50) & (df['ap_lo'] <= 120) &
(df['ap_hi'] > df['ap_lo']) # 收缩压应该大于舒张压
]
print(f"\n清理后数据集形状: {df_clean.shape}")
print(f"移除了 {len(df) - len(df_clean)} 行异常数据")
检查异常值: 身高异常值 (< 140 or > 200): 154 体重异常值 (< 40 or > 150): 111 收缩压异常值 (< 80 or > 200): 307 舒张压异常值 (< 50 or > 120): 1136 清理后数据集形状: (68330, 16) 移除了 1670 行异常数据
3.3 数据可视化分析
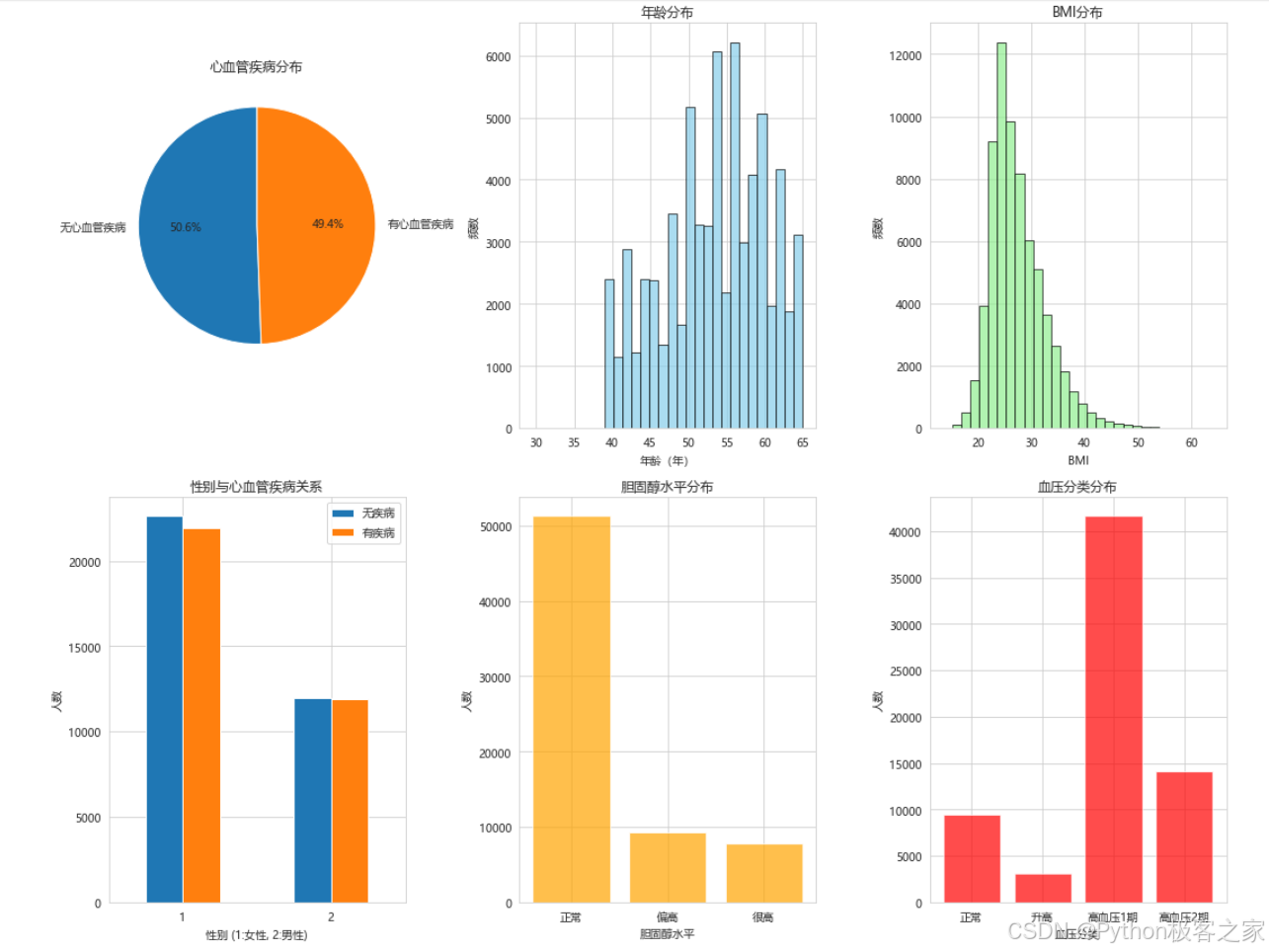
3.3.1 各特征分布情况
目标变量分布、年龄分布、BMI分布、性别与心血管疾病关系、胆固醇水平分布、血压分类分布:
3.3.2 特征相关性热力图
python
# 相关性热力图
plt.figure(figsize=(12, 10))
correlation_matrix = df_clean[['age_years', 'gender', 'height', 'weight', 'bmi', 'ap_hi', 'ap_lo',
'cholesterol', 'gluc', 'smoke', 'alco', 'active', 'bp_category', 'cardio']].corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0, fmt='.2f')
plt.title('特征相关性热力图')
plt.tight_layout()
plt.show()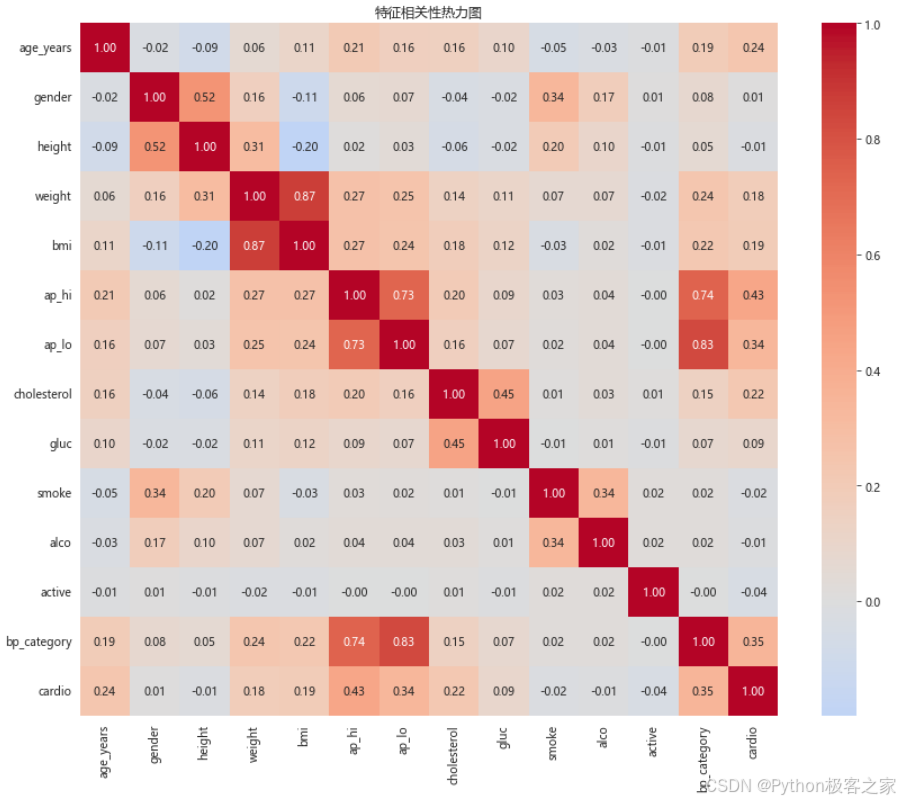
3.3.3 各特征与心血管疾病的关系
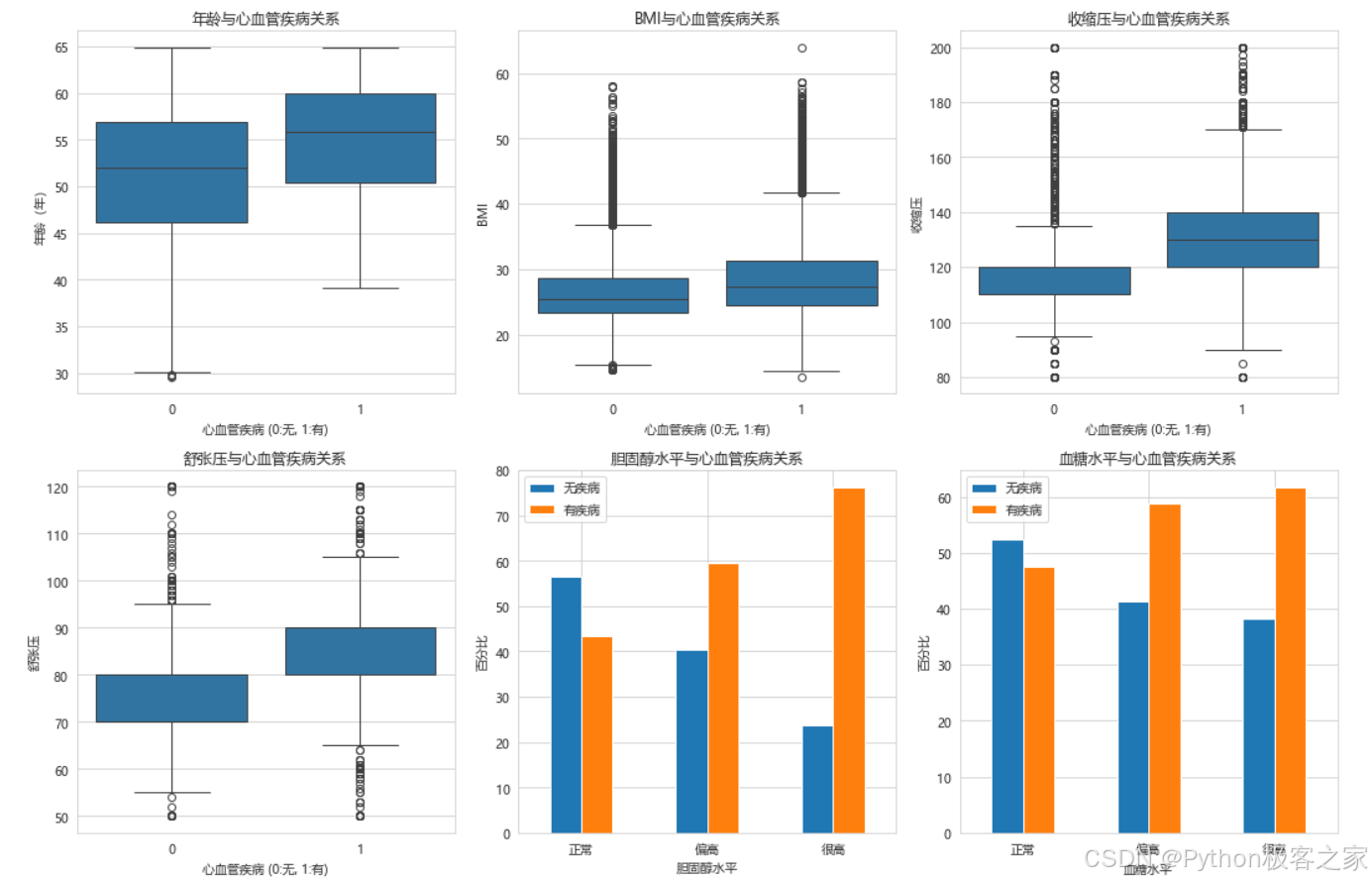
3.4 机器学习模型构建
利用 sklearn、xgboost框架,构建 Logistic Regression、Random Forest、Gradient Boosting、XGBoost 四种模型,对心血管疾病预测任务进行建模:
python
# 定义多个机器学习模型
models = {
'Logistic Regression': LogisticRegression(random_state=42),
'Random Forest': RandomForestClassifier(n_estimators=100, random_state=42),
'Gradient Boosting': GradientBoostingClassifier(random_state=42),
'XGBoost': xgb.XGBClassifier(random_state=42),
}
# 训练和评估模型
model_results = {}
for name, model in models.items():
print(f"\n训练 {name} 模型...")
# 对于需要标准化的模型使用标准化数据
......
# 计算评估指标
accuracy = accuracy_score(y_test, y_pred)
auc_score = roc_auc_score(y_test, y_pred_proba)
model_results[name] = {
'model': model,
'accuracy': accuracy,
'auc': auc_score,
'predictions': y_pred,
'probabilities': y_pred_proba
}
print(f"{name} - 准确率: {accuracy:.4f}, AUC: {auc_score:.4f}")
# 找出最佳模型
best_model_name = max(model_results.keys(), key=lambda x: model_results[x]['auc'])
best_model = model_results[best_model_name]['model']
print(f"\n最佳模型: {best_model_name}")
print(f"最佳AUC得分: {model_results[best_model_name]['auc']:.4f}")3.5 模型评估和可视化
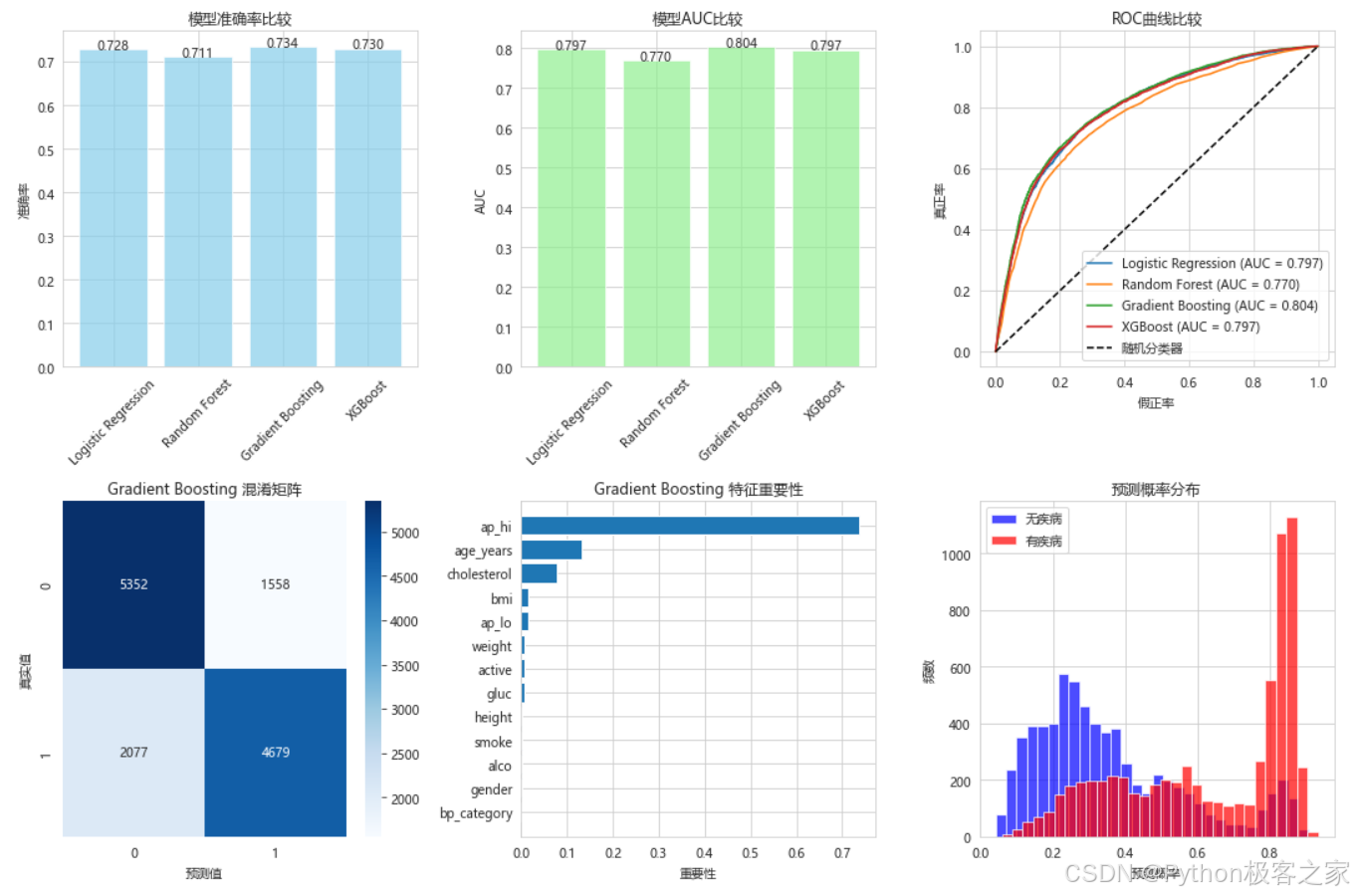
本项目完成了心血管疾病预测的完整机器学习流程:
- 数据分析: 对70000+条心血管疾病数据进行了全面的探索性数据分析
- 数据预处理: 处理异常值,创建新特征(BMI、血压分类等)
- 可视化分析: 通过多种图表展示数据分布和特征关系
- 模型构建: 比较了5种不同的机器学习算法
- 模型评估: 使用准确率、AUC、ROC曲线等多种指标评估模型性能
- 模型保存: 保存最佳模型用于Web应用集成
最佳模型在测试集上的表现良好,可以用于实际的心血管疾病风险预测。
接下来将基于这个训练好的模型构建Web应用系统。
4. 心血管疾病智能预测系统
4.1 首页
首页展示系统核心功能与健康建议,支持快速预测与数据可视化,提升用户健康管理体验。
4.2 用户注册登录
4.2.1 用户注册
用户注册页面支持填写用户名、邮箱和密码,完成账号创建并享受个性化健康管理服务。
4.2.2 用户登录
用户登录页面支持账号密码登录,提供快速体验功能,方便用户便捷使用系统。
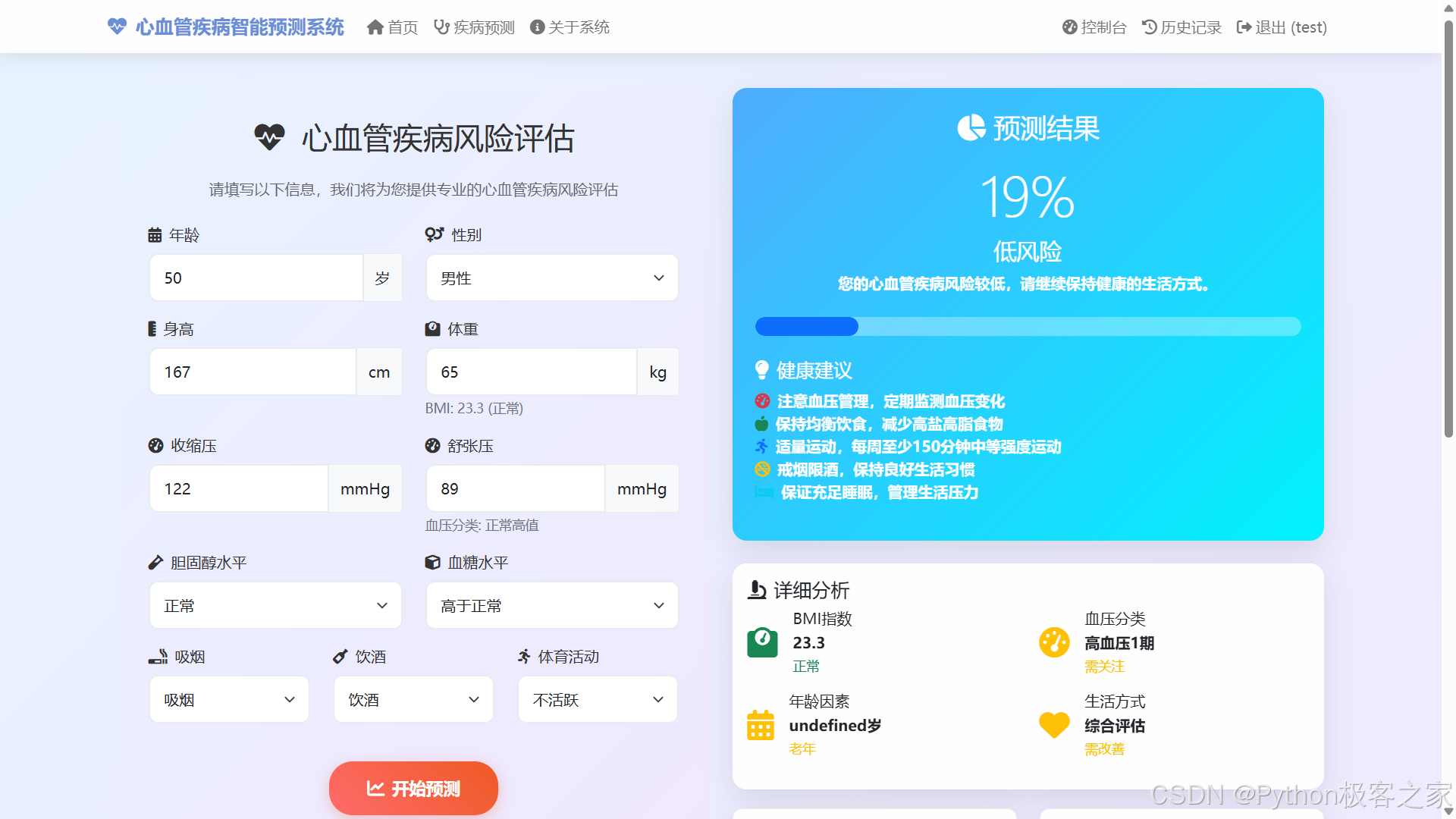
4.3 心血管疾病预测
输入健康数据,系统智能评估心血管疾病风险并提供个性化健康建议。
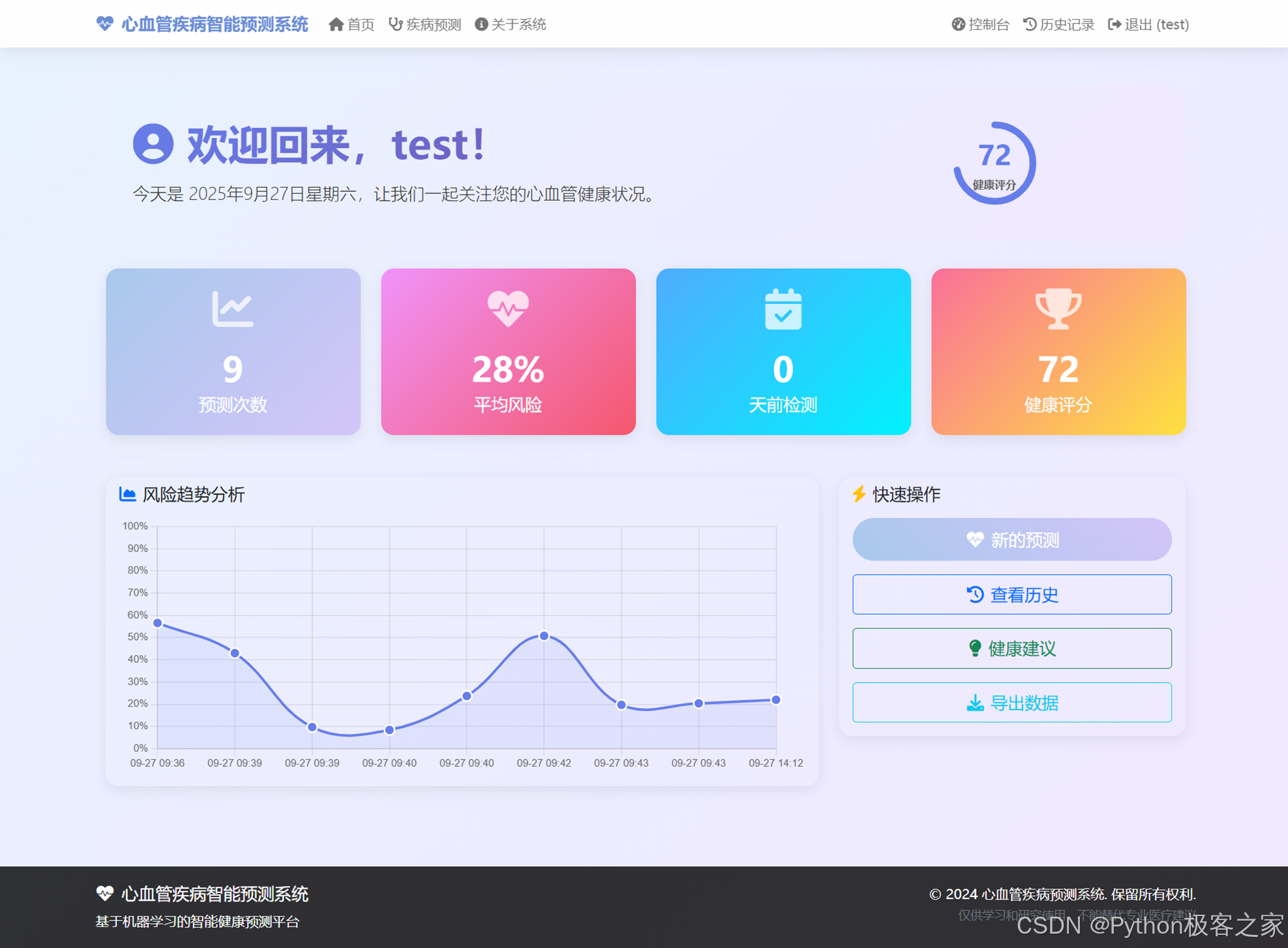
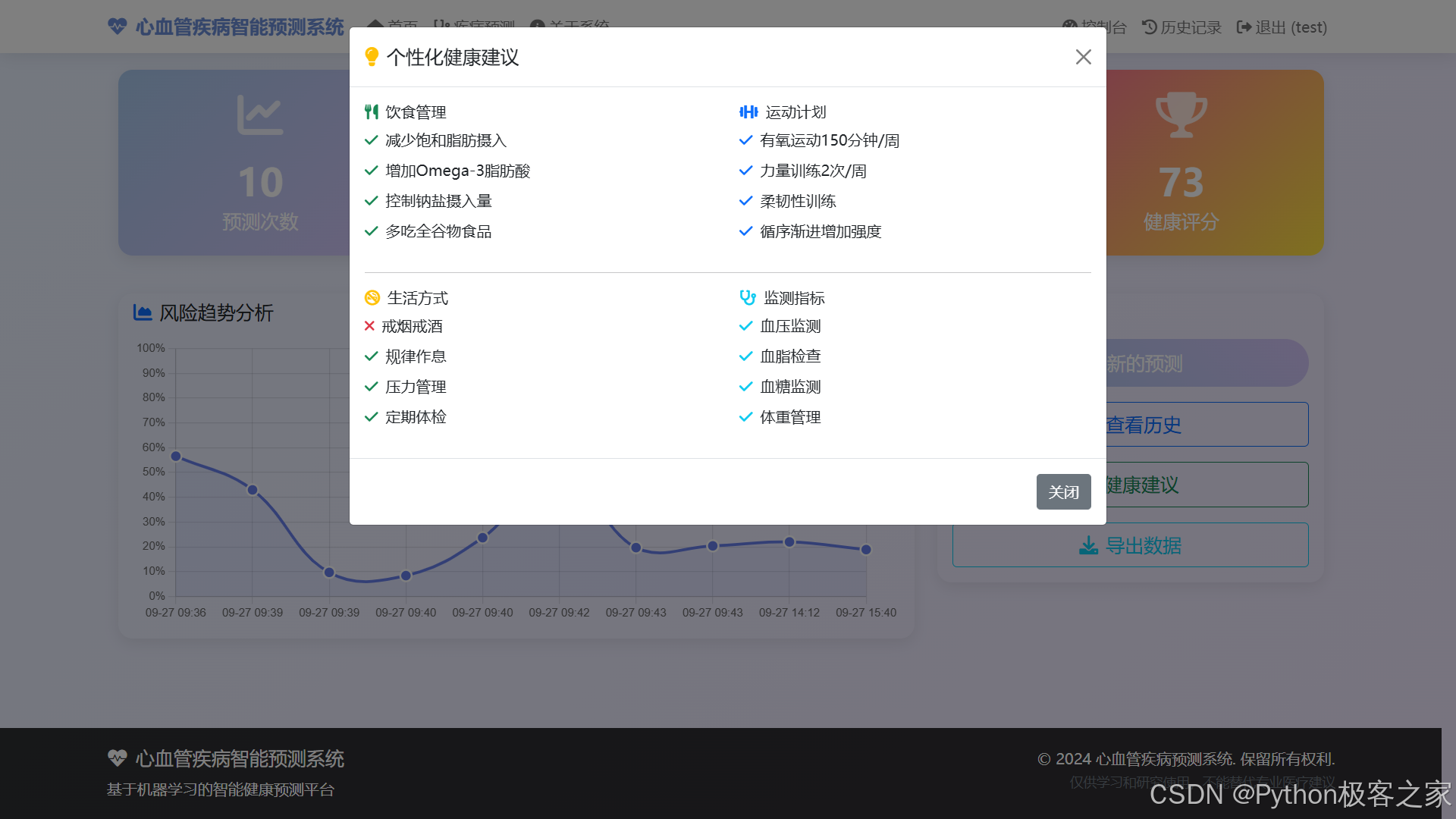
4.4 控制台面板
控制台面板展示健康评分、风险趋势与预测数据,支持快速操作与历史查看。
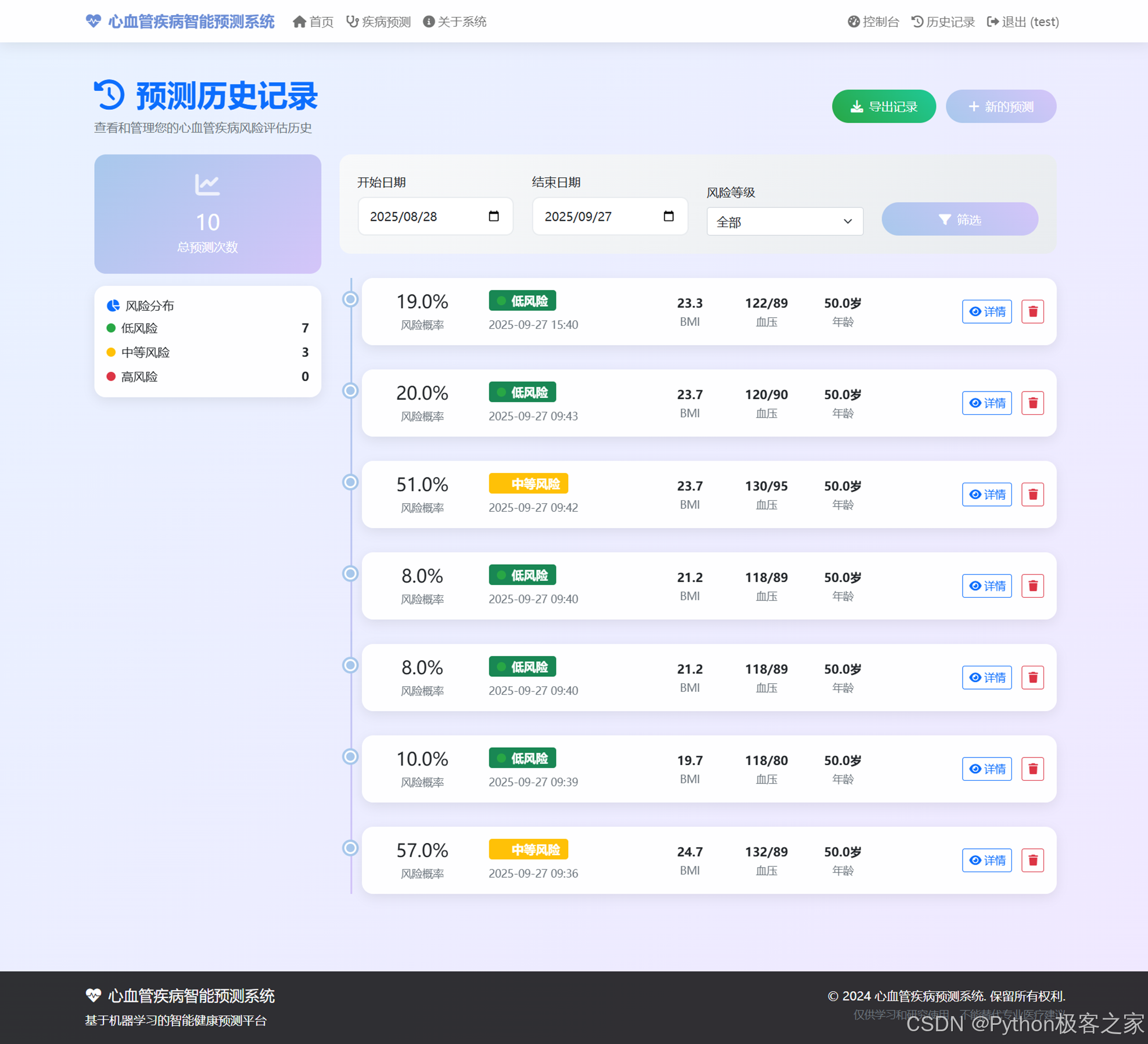
4.5 检测记录历史
检测记录页面展示历史预测数据,支持筛选、查看详情与导出记录。
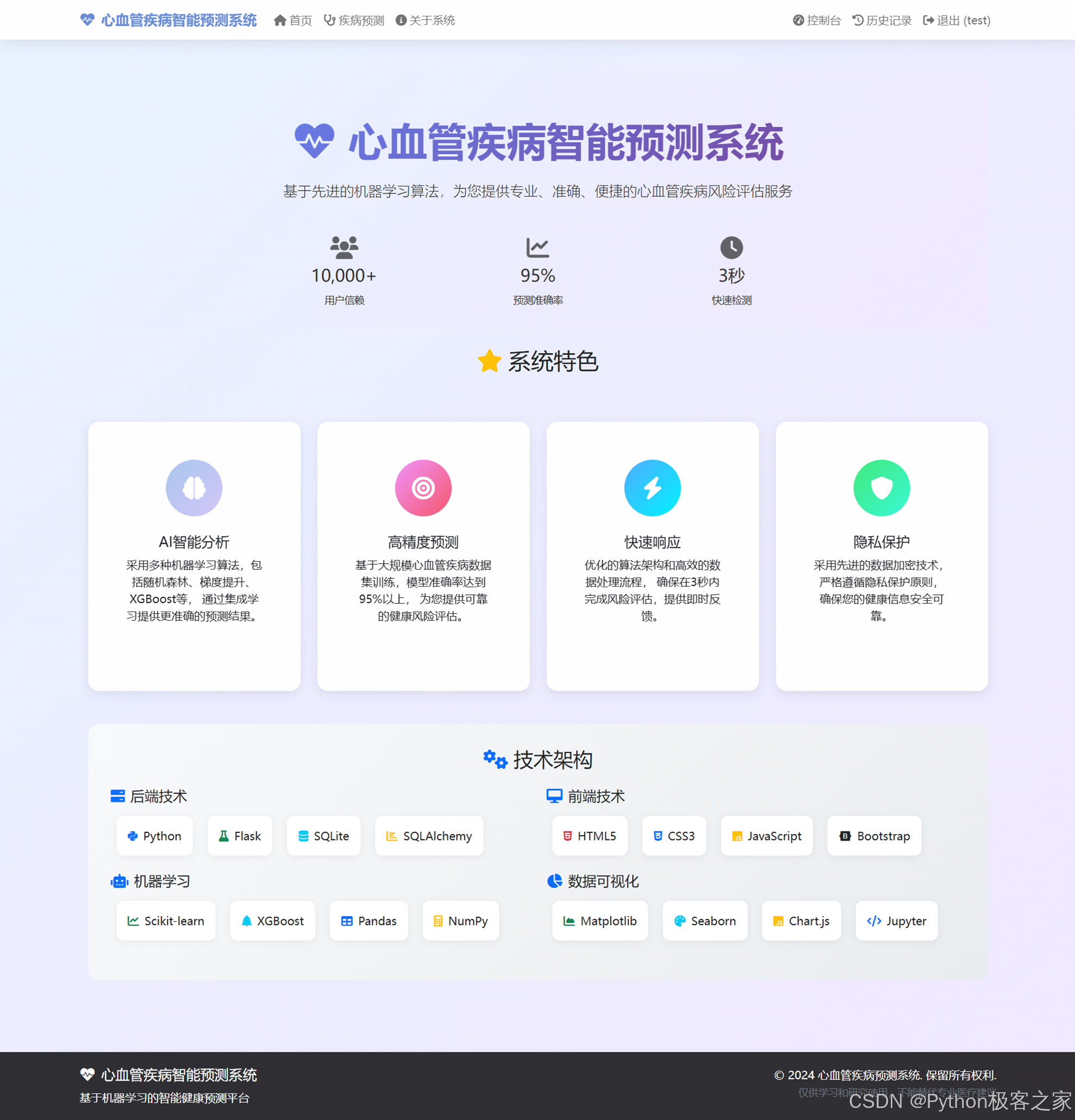
4.6 关于系统
介绍系统功能、技术架构与核心优势,展示AI智能分析与隐私保护特性。
5. 代码架构
6. 总结
本项目旨在开发一个基于机器学习的心血管疾病智能预测系统,利用数据挖掘和机器学习技术对患者的健康数据进行分析,提前预测潜在的心血管疾病风险,并提供相应的干预建议。该系统将涵盖数据收集、预处理、特征工程、模型训练、预测和结果展示等多个环节,旨在为医疗保健机构和个人用户提供一个全面的心血管疾病预警平台。通过该系统,用户可以更方便地了解自己的心血管疾病风险,并采取适当的预防措施。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取 认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
