
1.摘要
background
多模态大语言模型(MLLMs)在处理长视频时面临一个核心挑战:它们的上下文窗口(Context Capacity)有限,无法一次性处理视频中的所有帧。因此,现有的视频MLLMs通常需要对视频帧进行采样,例如均匀采样(Uniform Sampling)。这种简单的采样方式很可能会丢失包含关键信息的帧,从而导致模型对视频内容的理解错误,给出不正确的答案。
innovation
1.提出自适应关键帧采样算法 (Adaptive Keyframe Sampling, AKS): 作者提出了一个简单而有效的即插即用(plug-and-play)模块AKS,用于在将视频输入MLLM之前,智能地挑选出信息量最丰富的关键帧。
2. 两大核心准则 (Relevance & Coverage): AKS将关键帧选择问题建模为一个优化问题,其核心是最大化两个准则:
相关性 (Relevance): 选出的关键帧需要与用户提出的问题(Prompt)高度相关。
覆盖度 (Coverage): 选出的关键帧集合需要能全面地覆盖整个视频时间轴上的重要信息,避免因为只关注局部高相关性片段而丢失全局信息。
- 方法 Method
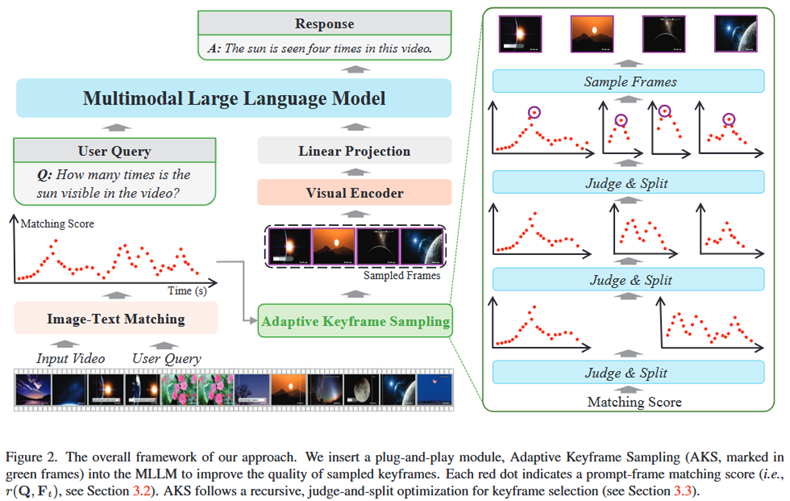
**整体 Pipeline:**AKS作为一个即插即用的预处理模块,被插入到常规的视频MLLM流程中。
输入: 一个长视频V和一个文本问题Q。
AKS模块处理:
首先,对视频进行初步采样(如1fps),得到一系列候选帧。
使用一个轻量的视觉语言模型(如CLIP或BLIP)计算每个候选帧Ft与问题Q之间的相关性分数r(Q, Ft)。
AKS算法根据所有帧的相关性分数,执行一个递归的"判断-分裂"(Judge-and-Split)策略,来决定最终选择哪些帧。
输出: AKS模块输出M个被选中的关键帧的索引。
后续流程: 这些被选中的关键帧被送入MLLM的视觉编码器,转换成Visual Tokens,再与问题文本一起输入LLM,最终生成答案。
**各部分详解:**AKS的核心是其自适应优化算法,它旨在平衡"相关性"和"覆盖度"。
相关性计算 r(Q, Ft):
输入: 问题Q的文本嵌入,和某一帧Ft的图像嵌入。
做法: 使用一个预训练好的、计算成本较低的图文匹配模型(如BLIP的ITM模块)来计算两者之间的相似度得分。得分越高,代表该帧与问题越相关。
输出: 一个标量分数。
覆盖度估计与自适应采样 (ADA算法):
输入: 所有候选帧的相关性分数序列,以及要采样的总帧数M。
做法: 采用一种分层、递归的优化方法。
初始化: 将整个视频时间轴 [0, T) 视为一个"桶"(bin)。
判断: 在当前的桶内,计算所有帧的平均分s_all和得分最高的M帧的平均分s_top。如果s_top远超s_all(超过一个阈值S_thr),说明这个桶内的信息非常集中,此时算法会直接选择分数最高的Top-M帧(偏向相关性)。
分裂: 否则,说明信息分布较散,算法会将当前的桶均分为两个子桶,并将采样名额M均分给这两个子桶(偏向覆盖度)。
递归: 对每个子桶重复"判断-分裂"的过程,直到达到最大递归深度或分配完所有采样名额。
输出: 最终被选中的M个关键帧的索引。
- 实验 Experimental Results
实验数据集:
LongVideoBench: 一个用于长上下文、交错视频语言理解的基准。
VideoMME: 一个全面的多模态LLM视频分析评估基准。
主要实验结论:
与SOTA方法对比:
实验目的: 验证AKS能否提升现有视频MLLMs的性能。
结论: 将AKS应用于三个不同的基线模型(Qwen2-VL, LLaVA-OV, LLaVA-Video)后,在两个数据集上都取得了一致且显著的准确率提升。例如,LLaVA-Video-7B结合AKS后,性能甚至超过了一些使用更多帧的专有闭源模型(如GPT-4V)。
不同采样策略的诊断分析:
实验目的: 比较AKS (ADA) 与其他采样策略,如均匀采样(UNI)、只看相关性的顶峰采样(TOP)和只看覆盖度的分桶采样(BIN)的效果。
结论: AKS (ADA) 在两个数据集上的综合表现最好。这证明了它成功地结合了TOP策略(适用于问题答案集中在视频某一刻的场景)和BIN策略(适用于答案分布在视频多个时间点的场景)的优点。
消融实验:
实验目的: 探究不同组件对性能的影响,如候选帧的采样频率、计算相关性分数的视觉语言模型选择等。
结论:
即使将候选帧的采样频率从1fps降低到0.25fps,性能也只有轻微下降,证明AKS可以在保证效果的同时降低计算开销。
不同的VL模型(CLIP, BLIP)在不同数据集上各有优劣,这与数据集的问题类型和模型的预训练数据有关。
- 总结 Conclusion
对于上下文窗口有限的MLLM来说,在处理长视频时,一个智能的视觉信息预过滤(pre-filtering)阶段至关重要。本文提出的AKS算法,通过同时考虑与用户问题的相关性 和对视频内容的覆盖度,提供了一个非常有效的预过滤方案,能显著提升模型对长视频的理解能力。