阿里强势开源视频修复方法 Vivid - VR,为行业带来新突破。它基于 DiT,依托先进 T2V 模型,借 ControlNet 保内容一致。但传统微调因多模态对齐不完善,会出现分布漂移,损害修复质量。为此,Vivid - VR 提出概念蒸馏训练策略,用预训练模型合成样本提炼概念,保留纹理与时间质量。还重新设计控制架构,有控制特征投影器过滤伪影,以及双分支 ControlNet 连接器动态控特征。经大量实验,其在多方面表现优异,实现高质量、可控的视频修复。

相关链接
论文介绍
Vivid-VR 是一种基于 DiT 的生成视频修复方法,它建立在先进的 T2V 基础模型之上,并利用 ControlNet 来控制生成过程,从而确保内容的一致性。然而,由于多模态对齐不完善的限制,此类可控流水线的传统微调经常会出现分布漂移,从而损害纹理真实感和时间连贯性。
为了应对这一挑战,论文提出了一种概念蒸馏训练策略,该策略利用预训练的 T2V 模型合成嵌入文本概念的训练样本,从而提炼其概念理解以保留纹理和时间质量。为了增强生成的可控性,论文重新设计了控制架构,其中包含两个关键组件:
-
一个控制特征投影器,用于过滤输入视频潜在特征中的退化伪影,以最大限度地减少其在生成流水线中的传播;
-
一个采用双分支设计的新型 ControlNet 连接器。该连接器协同结合了基于多层感知器 (MLP) 的特征映射和交叉注意力机制,用于动态控制特征检索,从而实现内容保存和自适应控制信号调制。
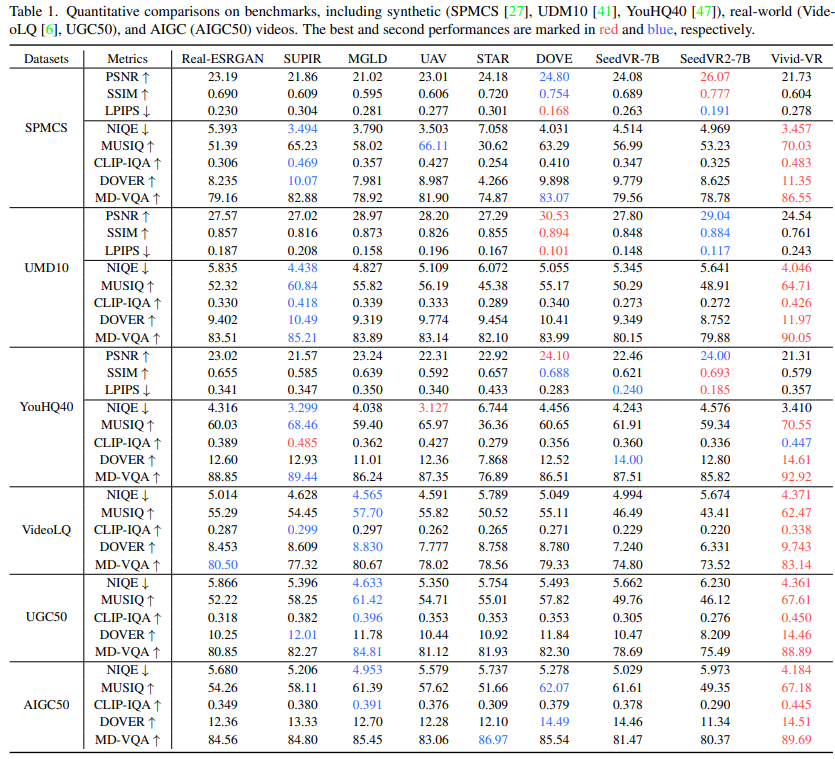
大量实验表明,Vivid-VR 在合成和真实世界基准测试以及 AIGC 视频上均优于现有方法,实现了令人印象深刻的纹理真实感、视觉生动性和时间一致性。
方法概述
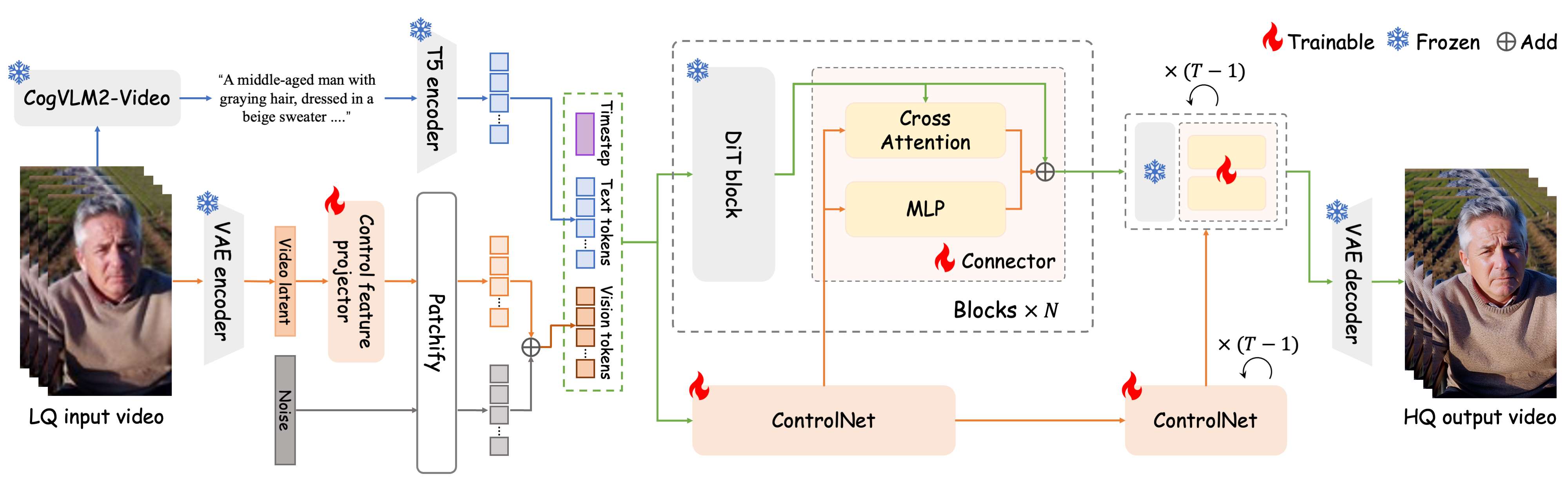
所提方法概述。Vivid-VR 首先使用 CogVLM2-Video 处理 LQ 输入视频,生成文本描述,并通过 T5 编码器将其编码为文本标记。同时,3D VAE 编码器将输入视频转换为潜在数据,其中我们的控制特征投影器会消除降级伪影。然后,视频潜在数据会被修补、加噪,并与文本标记和时间步嵌入相结合,作为 DiT 和 ControlNet 的输入。为了增强可控性,引入了一个双分支连接器:一个用于特征映射的 MLP 和一个用于动态控制特征检索的交叉注意力分支,从而实现自适应输入对齐。经过 T 个去噪步骤后,3D VAE 解码器重建 HQ 输出。只有控制特征投影器、ControlNet 和连接器通过所提出的概念蒸馏策略进行训练,其他参数保持不变。
实验结果


时间一致性的视觉比较结果。(a) 显示输入视频的第 5 帧,(b)-(g) 分别显示第 0、5 和 10 帧的输出,其中"CD"表示所提出的概念提炼。Vivid-VR 展现出卓越的时间连贯性,这从整个序列中窗户和门的一致结构可以看出。

结论
Vivid-VR 是一种基于 DiT 的生成式视频修复方法,它基于先进的 T2V 基础模型。为了减轻微调过程中的分布漂移,论文引入了一种概念蒸馏训练策略,该策略利用预训练的 T2V 模型来合成嵌入文本概念的训练样本。关于可控生成的模型架构,作者提出了两个关键组件:
-
一个控制特征投影器,用于消除潜在视频特征中的退化伪影;
-
一个双分支 ControlNet 连接器,结合 MLP 和交叉注意机制,用于控制特征映射和动态检索。定量和定性实验结果均证明了所提方法的有效性。