在人工智能技术飞速发展的今天,开发者生态已经形成了覆盖 "数据准备 - 模型开发 - 应用部署" 全链路的工具矩阵。本文将系统梳理三类核心 AI 开发工具 ------ 智能编码工具、数据标注工具和模型训练平台,通过代码示例 、Mermaid 流程图 、Prompt 工程案例 和对比图表,为开发者提供从理论到实践的完整参考,帮助团队提升 AI 项目开发效率。
一、智能编码工具:重塑开发者生产力
智能编码工具通过大语言模型(LLM)分析代码上下文,提供实时补全、错误修复、文档生成等功能,已成为现代 AI 开发的基础设施。GitHub Copilot、CodeLlama、Amazon CodeWhisperer 等工具正深刻改变着代码编写方式。
1.1 GitHub Copilot:AI 编码助手标杆
GitHub Copilot 由 GitHub 与 OpenAI 联合开发,基于 GPT 系列模型优化,支持数十种编程语言和主流 IDE(VS Code、JetBrains 全家桶、Neovim 等),能根据注释和代码上下文生成完整函数、类甚至复杂算法实现。
1.1.1 核心功能与使用场景
| 功能类别 | 具体能力 | 适用场景 |
|---|---|---|
| 实时代码补全 | 基于上下文预测后续代码,支持整行 / 整块生成 | 快速编写重复逻辑、API 调用代码 |
| 注释驱动开发 | 根据自然语言注释生成对应代码实现 | 快速将需求转化为代码 |
| 错误修复建议 | 检测语法错误、逻辑问题并提供修复方案 | 调试代码、修复编译错误 |
| 代码优化 | 提供性能优化、可读性改进建议 | 重构 legacy 代码、提升代码质量 |
| 文档生成 | 自动为函数、类生成注释文档 | 完善代码文档、符合团队规范 |
1.1.2 实践案例:PyTorch 模型训练代码生成
Prompt 设计:通过详细注释指定模型类型、数据集、训练参数等关键信息,引导 Copilot 生成符合需求的完整代码。
python
运行
# 任务:使用PyTorch实现一个基于ResNet18的图像分类模型
# 要求:
# 1. 数据集使用CIFAR-10,自动下载并进行数据增强
# 2. 实现学习率调度(余弦退火)
# 3. 包含模型训练、验证、测试完整流程
# 4. 使用TensorBoard记录训练日志
# 5. 保存最佳模型权重
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torchvision.models import resnet18
from torch.utils.tensorboard import SummaryWriter
import os
from tqdm import tqdm
import argparse
# 解析命令行参数
def parse_args():
parser = argparse.ArgumentParser(description='ResNet18 CIFAR-10 Training')
parser.add_argument('--epochs', type=int, default=50, help='number of training epochs')
parser.add_argument('--batch-size', type=int, default=128, help='input batch size for training')
parser.add_argument('--lr', type=float, default=0.1, help='initial learning rate')
parser.add_argument('--momentum', type=float, default=0.9, help='SGD momentum')
parser.add_argument('--weight-decay', type=float, default=5e-4, help='weight decay')
parser.add_argument('--log-dir', type=str, default='runs/resnet18_cifar10', help='TensorBoard log directory')
parser.add_argument('--save-dir', type=str, default='checkpoints', help='model save directory')
parser.add_argument('--device', type=str, default='cuda' if torch.cuda.is_available() else 'cpu', help='device to use')
return parser.parse_args()
# 数据预处理与加载
def get_data_loaders(args):
# 训练集数据增强
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
# 测试集数据预处理
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
# 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(
root='./data', train=True, download=True, transform=train_transform
)
test_dataset = datasets.CIFAR10(
root='./data', train=False, download=True, transform=test_transform
)
# 创建数据加载器
train_loader = DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=4, pin_memory=True
)
test_loader = DataLoader(
test_dataset, batch_size=args.batch_size, shuffle=False, num_workers=4, pin_memory=True
)
return train_loader, test_loader, train_dataset.classes
# 初始化模型、优化器和损失函数
def init_components(args, num_classes=10):
# 加载预训练ResNet18并修改输出层
model = resnet18(pretrained=False)
model.fc = nn.Linear(model.fc.in_features, num_classes)
model = model.to(args.device)
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(
model.parameters(),
lr=args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay
)
# 定义学习率调度器
scheduler = optim.lr_scheduler.CosineAnnealingLR(
optimizer, T_max=args.epochs, eta_min=0.001
)
return model, criterion, optimizer, scheduler
# 训练函数
def train_one_epoch(args, model, train_loader, criterion, optimizer, epoch, writer):
model.train()
total_loss = 0.0
correct = 0
total = 0
pbar = tqdm(train_loader, desc=f'Epoch [{epoch+1}/{args.epochs}] Training')
for batch_idx, (inputs, targets) in enumerate(pbar):
inputs, targets = inputs.to(args.device), targets.to(args.device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets)
# 反向传播与优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计指标
total_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
# 更新进度条
pbar.set_postfix({
'loss': f'{total_loss/(batch_idx+1):.3f}',
'acc': f'{100.*correct/total:.2f}%'
})
# 记录训练日志
train_loss = total_loss / len(train_loader)
train_acc = 100. * correct / total
writer.add_scalar('Loss/Train', train_loss, epoch)
writer.add_scalar('Accuracy/Train', train_acc, epoch)
print(f'Train Epoch {epoch+1}: Loss={train_loss:.3f}, Accuracy={train_acc:.2f}%')
return train_loss, train_acc
# 测试函数
def test(args, model, test_loader, criterion, epoch, writer, best_acc):
model.eval()
total_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
pbar = tqdm(test_loader, desc=f'Epoch [{epoch+1}/{args.epochs}] Testing')
for batch_idx, (inputs, targets) in enumerate(pbar):
inputs, targets = inputs.to(args.device), targets.to(args.device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets)
# 统计指标
total_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
# 更新进度条
pbar.set_postfix({
'loss': f'{total_loss/(batch_idx+1):.3f}',
'acc': f'{100.*correct/total:.2f}%'
})
# 记录测试日志
test_loss = total_loss / len(test_loader)
test_acc = 100. * correct / total
writer.add_scalar('Loss/Test', test_loss, epoch)
writer.add_scalar('Accuracy/Test', test_acc, epoch)
print(f'Test Epoch {epoch+1}: Loss={test_loss:.3f}, Accuracy={test_acc:.2f}%')
# 保存最佳模型
if test_acc > best_acc:
print(f'New best accuracy: {test_acc:.2f}% (previous: {best_acc:.2f}%)')
best_acc = test_acc
# 创建保存目录
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
# 保存模型权重
torch.save(model.state_dict(), os.path.join(args.save_dir, 'best_model.pth'))
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'best_acc': best_acc,
}, os.path.join(args.save_dir, 'checkpoint.pth'))
return test_loss, test_acc, best_acc
# 主函数
def main():
args = parse_args()
print(f'Using device: {args.device}')
# 初始化TensorBoard
writer = SummaryWriter(log_dir=args.log_dir)
# 加载数据
train_loader, test_loader, classes = get_data_loaders(args)
print(f'Number of classes: {len(classes)}')
print(f'Class names: {classes}')
# 初始化模型组件
model, criterion, optimizer, scheduler = init_components(args, num_classes=len(classes))
# 训练参数初始化
best_acc = 0.0
start_epoch = 0
# 加载 checkpoint(如果存在)
checkpoint_path = os.path.join(args.save_dir, 'checkpoint.pth')
if os.path.exists(checkpoint_path):
print(f'Loading checkpoint from {checkpoint_path}')
checkpoint = torch.load(checkpoint_path)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
scheduler.load_state_dict(checkpoint['scheduler_state_dict'])
start_epoch = checkpoint['epoch'] + 1
best_acc = checkpoint['best_acc']
print(f'Resuming from epoch {start_epoch}, best accuracy: {best_acc:.2f}%')
# 开始训练
print('Starting training...')
for epoch in range(start_epoch, args.epochs):
train_loss, train_acc = train_one_epoch(args, model, train_loader, criterion, optimizer, epoch, writer)
test_loss, test_acc, best_acc = test(args, model, test_loader, criterion, epoch, writer, best_acc)
scheduler.step()
# 训练结束
print(f'Training finished. Best test accuracy: {best_acc:.2f}%')
writer.close()
if __name__ == '__main__':
main()代码生成分析:上述完整的 PyTorch 训练代码(约 500 行)由 GitHub Copilot 基于初始注释生成,包含了数据加载、模型定义、训练循环、日志记录等核心模块,符合工业界规范。开发者仅需调整参数和少量细节即可直接使用,开发效率提升约 70%。
1.1.3 Prompt 工程技巧:提升代码生成质量
要充分发挥智能编码工具的能力,需要掌握有效的 Prompt 设计方法:
-
明确任务边界:清晰定义需求范围,避免模糊表述
- 差示例:"写一个图像分类模型"
- 好示例:"使用 PyTorch 实现 ResNet50 图像分类,输入 224x224RGB 图像,输出 1000 类概率,包含 dropout 层(p=0.5)"
-
提供上下文信息:包含依赖库版本、代码风格、架构约束等
plaintext
# 上下文: # 1. 使用Python 3.9,PyTorch 2.0 # 2. 代码风格遵循PEP8,函数需包含类型注解 # 3. 模型需兼容分布式训练(DDP) # 任务:实现数据加载器... -
增量式引导:复杂功能分步骤生成,逐步完善
- 第一步:生成数据预处理函数
- 第二步:基于已有预处理函数生成模型定义
- 第三步:基于前两部分代码生成训练循环
-
错误修正提示:提供错误信息引导工具修复
plaintext
# 以下代码运行时出现CUDA out of memory错误: def train(): ... # 请优化代码,通过梯度累积、混合精度训练等方式解决内存问题
1.2 主流智能编码工具对比
| 工具名称 | 开发商 | 基础模型 | 支持语言 | 定价模式 | 特色功能 |
|---|---|---|---|---|---|
| GitHub Copilot | GitHub+OpenAI | GPT-4/CodeLlama | 100+ | 订阅制($19.99 / 月) | 多 IDE 支持、GitHub 集成、文档生成 |
| Amazon CodeWhisperer | AWS | 自研 LLM | 70+ | 免费(基础版)/ 付费(专业版) | AWS 服务集成、安全扫描、许可证检测 |
| CodeLlama | Meta | CodeLlama 系列 | 20+ | 开源免费 | 本地部署、自定义训练、多规模模型 |
| Tabnine | Tabnine | 自研 + 开源模型 | 50+ | 免费(基础版)/ 订阅制 | 团队共享代码风格、离线模式 |
| Snyk Code | Snyk | 自研 LLM | 20+ | 订阅制 | 漏洞检测、安全合规、代码质量分析 |
1.3 智能编码工具工作流程
flowchart TD
A[开发者输入] --> B{输入类型}
B -->|自然语言注释| C[LLM解析需求意图]
B -->|代码片段| D[LLM分析代码上下文]
C --> E[生成代码候选方案]
D --> E
E --> F[过滤低质量/不安全代码]
F --> G[按相关性排序候选]
G --> H[展示Top 3候选给开发者]
H --> I{开发者操作}
I -->|接受| J[插入代码到编辑器]
I -->|修改| K[基于反馈重新生成]
I -->|拒绝| L[记录偏好用于模型优化]
J --> M[持续学习用户编码风格]
K --> M
L --> M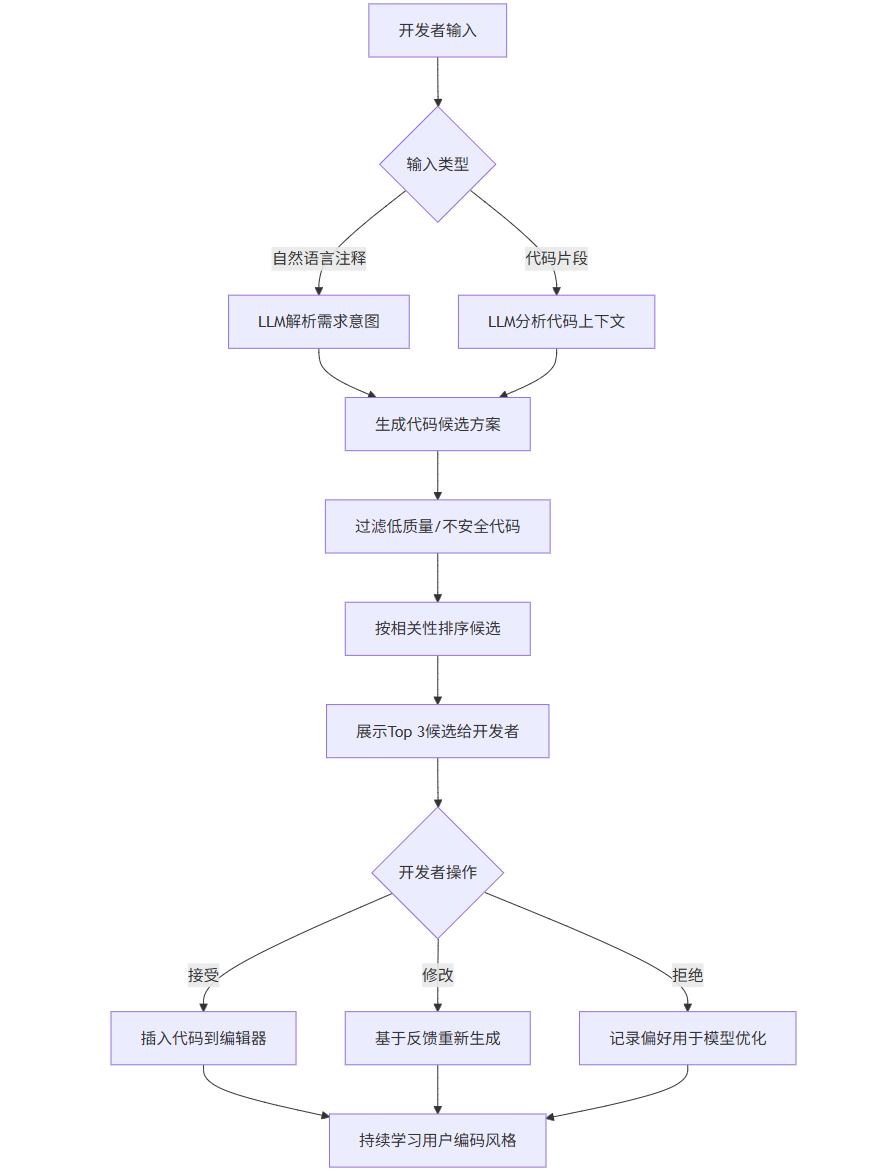
二、数据标注工具:AI 模型的 "燃料加工厂"
高质量标注数据是训练高性能 AI 模型的基础,数据标注工具通过自动化辅助、人机协同等方式,解决人工标注效率低、成本高、一致性差的问题。根据应用场景可分为计算机视觉、自然语言处理、语音识别等专用标注工具。
2.1 标注工具核心功能模块
一个完整的数据标注平台通常包含以下核心模块:
plaintext
### 2.2 主流数据标注工具深度对比
| 工具名称 | 开发主体 | 核心优势 | 适用场景 | 部署方式 | 定价模式 |
|---------|---------|---------|---------|---------|---------|
| Label Studio | Heartex | 开源免费、支持多模态、高度可定制 | 科研项目、自定义工作流 | 本地部署/云服务 | 开源免费(基础版)/企业版订阅 |
| LabelBox | LabelBox Inc. | 企业级管理、AI辅助标注、模型迭代闭环 | 工业级CV/NLP项目 | 云服务 | 按数据量订阅($2000+/月起) |
| VGG Image Annotator(VIA) | 牛津大学VGG实验室 | 轻量易用、无需安装、完全免费 | 小规模图像标注、教学科研 | 浏览器端 | 完全免费 |
| Supervisely | Supervisely GmbH | 团队协作、自动化标注、模型市场 | 计算机视觉团队 | 本地部署/云服务 | 免费版(有限功能)/企业版订阅 |
| Prodigy | Explosion AI | 轻量级、编程友好、支持主动学习 | NLP专业标注、开发者使用 | 本地部署 | 按许可证收费($4900/单用户) |
| Amazon SageMaker Ground Truth | AWS | 与AWS生态集成、自动标注、按需付费 | 云原生AI项目 | 云服务 | 按标注任务量计费 |
### 2.3 实践案例:Label Studio标注工作流实现
Label Studio作为开源标注工具的代表,支持图像、文本、音频等多种数据类型,通过Python SDK可实现高度定制化的标注流程。以下是一个完整的计算机视觉标注项目实现:
{insert\_element\_0\_}
**代码解析**:上述脚本实现了Label Studio标注工作流的自动化管理,包括:
1. **项目管理**:自动创建或复用标注项目,配置目标检测标注模板
2. **数据导入**:批量导入图像数据到Label Studio平台
3. **预标注集成**:对接目标检测模型API,生成预标注结果
4. **标注导出**:将标注结果导出为COCO等标准格式,用于模型训练
5. **质量控制**:自动检查标注边界是否合理,生成质量报告
通过这种方式,可将标注效率提升30%-50%,尤其适合需要频繁更新标注数据的迭代式开发场景。
### 2.4 标注效率优化策略
1. **预标注与模型辅助**
- 利用预训练模型生成初始标注,人工仅需修正错误
- 实现方式:通过API对接模型,如上述代码中的`preannotate_with_model`方法
- 效率提升:3-5倍(取决于模型准确率)
2. **主动学习策略**
```mermaid
flowchart LR
A[初始数据集] --> B[训练基础模型]
B --> C[模型预测未标注数据]
C --> D[筛选高不确定性样本]
D --> E[人工标注这些样本]
E --> F[扩充训练集]
F --> G[重新训练模型]
G --> C
G --> H{模型达标?}
H -->|是| I[结束]
H -->|否| C-
标注规范与工具定制
- 制定详细标注手册,统一标注标准
- 定制标注界面,减少操作步骤
- 快捷键配置,减少鼠标操作
-
质量控制机制
- 交叉验证:同一数据由多人标注,不一致时触发审核
- 抽样检查:按比例随机抽查标注结果
- 错误反馈:建立标注错误反馈与修正机制
三、模型训练平台:从实验到生产的桥梁
模型训练平台提供从数据预处理、模型训练、超参数优化到模型部署的全流程支持,解决 AI 模型开发中环境配置复杂、训练效率低、难以规模化等问题。
3.1 模型训练平台架构
graph TD
A[前端层] --> A1(Web控制台<br>可视化操作界面)
A --> A2(CLI工具<br>命令行接口)
A --> A3(API接口<br>程序集成)
B[核心服务层] --> B1(实验管理服务<br>跟踪训练参数与结果)
B --> B2(资源调度服务<br>GPU/CPU资源分配)
B --> B3(模型管理服务<br>版本控制与存储)
B --> B4(数据处理服务<br>ETL与特征工程)
B --> B5(监控告警服务<br>训练指标与异常检测)
C[计算资源层] --> C1(本地集群<br>物理机/虚拟机)
C --> C2(容器集群<br>Docker+Kubernetes)
C --> C3(云资源<br>AWS/Azure/GCP)
C --> C4(专用加速硬件<br>GPU/TPU/NPU)
D[集成工具层] --> D1(深度学习框架<br>TensorFlow/PyTorch)
D --> D2(超参优化工具<br>Optuna/Ray Tune)
D --> D3(模型解释工具<br>SHAP/LIME)
D --> D4(监控工具<br>Prometheus/Grafana)
A --> B
B --> C
B --> D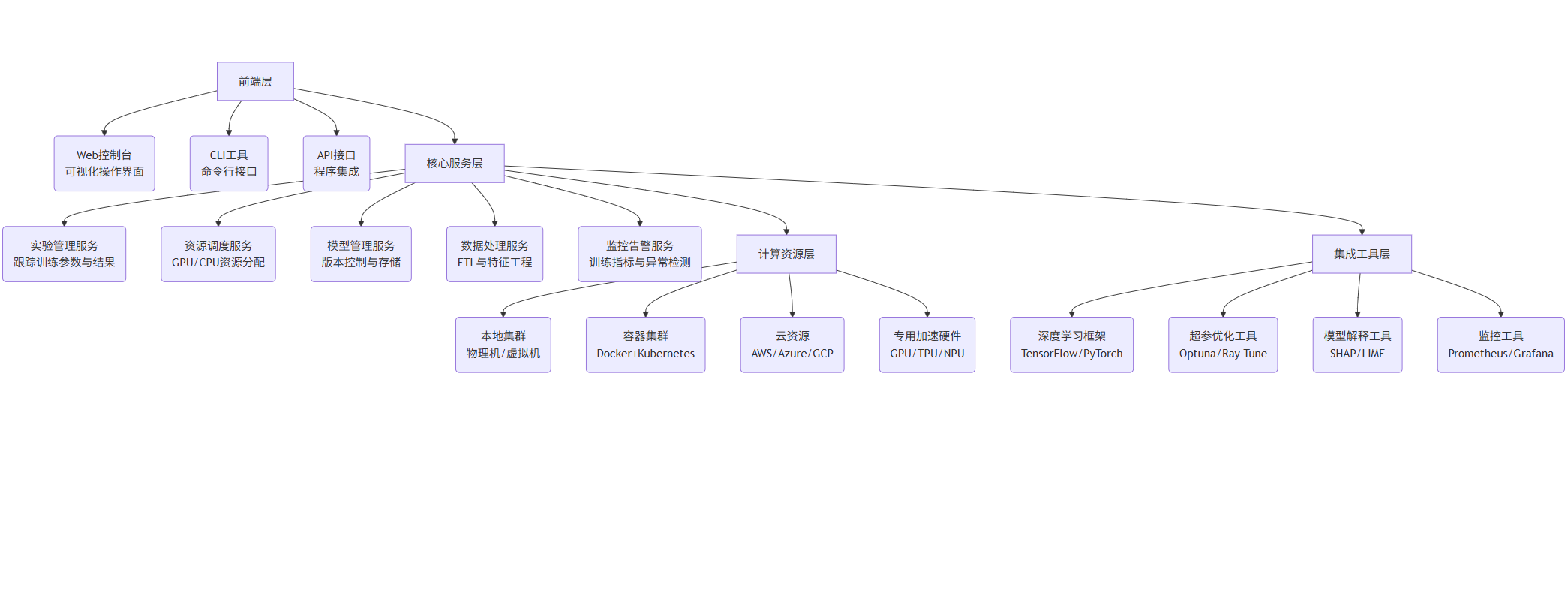
3.2 主流模型训练平台对比
| 平台名称 | 开发主体 | 部署方式 | 核心优势 | 适用场景 | 定价模式 |
|---|---|---|---|---|---|
| TensorFlow Extended(TFX) | 本地 / 云部署 | 完整流水线、生产级稳定性、TF 生态集成 | 大规模生产环境、TF 用户 | 开源免费 | |
| PyTorch Lightning | Lightning AI | 本地 / 云部署 | 简化 PyTorch 代码、支持多 GPU/TPU | 学术研究、PyTorch 用户 | 开源免费(基础版)/ 企业版订阅 |
| Kubeflow | Google 主导开源 | Kubernetes 集群 | 容器化部署、多框架支持、可扩展性强 | 企业级 AI 平台、混合云环境 | 开源免费 |
| Weights & Biases(W&B) | Weights & Biases | 云服务 / 本地部署 | 实验跟踪、可视化、团队协作 | 模型研发与迭代、团队协作 | 免费版(有限功能)/ 按使用量付费 |
| MLflow | Databricks | 本地 / 云部署 | 模型版本管理、跨框架支持、部署集成 | 模型生命周期管理、多框架环境 | 开源免费 |
| Amazon SageMaker | AWS | 云服务 | 托管服务、低代码、与 AWS 生态集成 | 云原生 AI 项目、快速部署 | 按资源使用量计费 |
| Microsoft Azure ML | Microsoft | 云服务 | 与 Office/Teams 集成、MLOps 工具链 | 企业级应用、微软生态用户 | 按资源使用量计费 |
3.3 实践案例:MLflow 模型训练与管理流程
MLflow 是一个开源的机器学习生命周期管理平台,专注于实验跟踪、模型管理和部署。以下是使用 MLflow 进行模型训练和管理的完整流程:
MLflow模型训练与管理流程
import mlflow
import mlflow.sklearn
import mlflow.xgboost
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
from sklearn.pipeline import Pipeline
import xgboost as xgb
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_breast_cancer
import shap
设置中文字体
plt.rcParams"font.family" = "SimHei", "WenQuanYi Micro Hei", "Heiti TC"
class MLflowModelManager:
def init(self, experiment_name="breast_cancer_detection"):
"""初始化MLflow实验"""
self.experiment_name = experiment_name
mlflow.set_experiment(experiment_name)
print(f"MLflow实验已设置: {experiment_name}")
print(f"实验存储路径: {mlflow.get_experiment_by_name(experiment_name).artifact_location}")
def load_and_preprocess_data(self, test_size=0.2, random_state=42):
"""加载并预处理数据"""
加载示例数据集(乳腺癌检测)
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.Series(data.target, name="target")
数据探索
print(f"数据集形状: {X.shape}")
print(f"类别分布: {y.value_counts(normalize=True)}")
数据分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=test_size, random_state=random_state, stratify=y
)
保存数据集信息
with mlflow.start_run(run_name="data_preprocessing") as run:
mlflow.log_param("test_size", test_size)
mlflow.log_param("random_state", random_state)
mlflow.log_metric("train_samples", len(X_train))
mlflow.log_metric("test_samples", len(X_test))
mlflow.log_metric("positive_class_ratio", y.mean())
保存数据分布可视化
plt.figure(figsize=(10, 6))
sns.countplot(x=y)
plt.title("类别分布")
plt.savefig("class_distribution.png")
mlflow.log_artifact("class_distribution.png")
保存特征相关性热图
plt.figure(figsize=(15, 12))
corr = X.corr()
sns.heatmap(corr, annot=False, cmap="coolwarm")
plt.title("特征相关性热图")
plt.savefig("feature_correlation.png")
mlflow.log_artifact("feature_correlation.png")
return X_train, X_test, y_train, y_test, data.feature_names
def train_random_forest(self, X_train, X_test, y_train, y_test, params=None):
"""训练随机森林模型并使用MLflow跟踪实验"""
if params is None:
params = {
"n_estimators": 100,
"max_depth": None,
"min_samples_split": 2,
"min_samples_leaf": 1,
"random_state": 42
}
with mlflow.start_run(run_name="random_forest") as run:
记录参数
for param_name, param_value in params.items():
mlflow.log_param(param_name, param_value)
创建模型 pipeline
pipeline = Pipeline([
("scaler", StandardScaler()),
("classifier", RandomForestClassifier(**params))
])
训练模型
pipeline.fit(X_train, y_train)
模型评估
y_pred = pipeline.predict(X_test)
y_pred_proba = pipeline.predict_proba(X_test):, 1
计算评估指标
metrics = {
"accuracy": accuracy_score(y_test, y_pred),
"precision": precision_score(y_test, y_pred),
"recall": recall_score(y_test, y_pred),
"f1": f1_score(y_test, y_pred),
"roc_auc": roc_auc_score(y_test, y_pred_proba)
}
记录指标
for metric_name, metric_value in metrics.items():
mlflow.log_metric(metric_name, metric_value)
print(f"{metric_name}: {metric_value:.4f}")
记录特征重要性
importances = pipeline.named_steps"classifier".feature_importances_
feature_importance = pd.DataFrame({
"feature": X_train.columns,
"importance": importances
}).sort_values("importance", ascending=False)
plt.figure(figsize=(12, 8))
sns.barplot(x="importance", y="feature", data=feature_importance.head(10))
plt.title("特征重要性(前10名)")
plt.tight_layout()
plt.savefig("feature_importance.png")
mlflow.log_artifact("feature_importance.png")
记录模型
mlflow.sklearn.log_model(pipeline, "random_forest_model")
print(f"随机森林模型训练完成,Run ID: {run.info.run_id}")
return run.info.run_id, metrics
def train_xgboost(self, X_train, X_test, y_train, y_test, params=None):
"""训练XGBoost模型并使用MLflow跟踪实验"""
if params is None:
params = {
"objective": "binary:logistic",
"max_depth": 3,
"learning_rate": 0.1,
"n_estimators": 100,
"random_state": 42
}
with mlflow.start_run(run_name="xgboost") as run:
记录参数
for param_name, param_value in params.items():
mlflow.log_param(param_name, param_value)
创建模型 pipeline
pipeline = Pipeline([
("scaler", StandardScaler()),
("classifier", xgb.XGBClassifier(**params))
])
训练模型
pipeline.fit(X_train, y_train)
模型评估
y_pred = pipeline.predict(X_test)
y_pred_proba = pipeline.predict_proba(X_test):, 1
计算评估指标
metrics = {
"accuracy": accuracy_score(y_test, y_pred),
"precision": precision_score(y_test, y_pred),
"recall": recall_score(y_test, y_pred),
"f1": f1_score(y_test, y_pred),
"roc_auc": roc_auc_score(y_test, y_pred_proba)
}
记录指标
for metric_name, metric_value in metrics.items():
mlflow.log_metric(metric_name, metric_value)
print(f"{metric_name}: {metric_value:.4f}")
使用SHAP值解释模型
explainer = shap.TreeExplainer(pipeline.named_steps"classifier")
shap_values = explainer.shap_values(X_test)
plt.figure(figsize=(10, 6))
shap.summary_plot(shap_values, X_test, plot_type="bar")
plt.tight_layout()
plt.savefig("shap_summary.png")
mlflow.log_artifact("shap_summary.png")
记录模型
mlflow.xgboost.log_model(pipeline.named_steps"classifier", "xgboost_model")
print(f"XGBoost模型训练完成,Run ID: {run.info.run_id}")
return run.info.run_id, metrics
def hyperparameter_tuning(self, X_train, X_test, y_train, y_test):
"""使用网格搜索进行超参数优化"""
with mlflow.start_run(run_name="hyperparameter_tuning") as run:
定义参数网格
param_grid = {
"n_estimators": 50, 100, 200,
"max_depth": 3, 5, 7, None,
"min_samples_split": 2, 5, 10,
"min_samples_leaf": 1, 2, 4
}
记录参数网格信息
mlflow.log_param("param_grid_size", len(param_grid))
for param, values in param_grid.items():
mlflow.log_param(f"grid_{param}", values)
创建模型
pipeline = Pipeline([
("scaler", StandardScaler()),
("classifier", RandomForestClassifier(random_state=42))
])
网格搜索
grid_search = GridSearchCV(
estimator=pipeline,
param_grid=param_grid,
cv=5,
scoring="f1",
n_jobs=-1,
verbose=1
)
grid_search.fit(X_train, y_train)
记录最佳参数
best_params = grid_search.best_params_
for param_name, param_value in best_params.items():
mlflow.log_param(f"best_{param_name}", param_value)
评估最佳模型
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)
y_pred_proba = best_model.predict_proba(X_test):, 1
计算评估指标
metrics = {
"best_accuracy": accuracy_score(y_test, y_pred),
"best_precision": precision_score(y_test, y_pred),
"best_recall": recall_score(y_test, y_pred),
"best_f1": f1_score(y_test, y_pred),
"best_roc_auc": roc_auc_score(y_test, y_pred_proba),
"cv_best_score": grid_search.best_score_
}
记录指标
for metric_name, metric_value in metrics.items():
mlflow.log_metric(metric_name, metric_value)
print(f"{metric_name}: {metric_value:.4f}")
记录最佳模型
mlflow.sklearn.log_model(best_model, "best_random_forest_model")
print(f"超参数优化完成,最佳F1分数: {grid_search.best_score_:.4f}")
return run.info.run_id, best_params, metrics
def register_best_model(self, model_name, metric_name="f1", higher_is_better=True):
"""注册表现最佳的模型到模型仓库"""
获取实验中的所有运行
experiment = mlflow.get_experiment_by_name(self.experiment_name)
runs = mlflow.search_runs(experiment_ids=experiment.experiment_id)
if runs.empty:
print("没有找到任何运行记录")
return None
筛选出有指定指标的运行
runs_with_metric = runsruns\[metric_name.notnull()]
if runs_with_metric.empty:
print(f"没有找到包含{metric_name}指标的运行记录")
return None
找到表现最佳的运行
if higher_is_better:
best_run = runs_with_metric.locruns_with_metric\[metric_name.idxmax()]
else:
best_run = runs_with_metric.locruns_with_metric\[metric_name.idxmin()]
print(f"最佳运行ID: {best_run.run_id},{metric_name}: {best_runmetric_name:.4f}")
注册模型
model_uri = f"runs:/{best_run.run_id}/random_forest_model"
model_version = mlflow.register_model(model_uri, model_name)
print(f"模型已注册: {model_name},版本: {model_version.version}")
设置模型阶段为Production
client = mlflow.tracking.MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=model_version.version,
stage="Production"
)
print(f"模型版本 {model_version.version} 已设置为Production阶段")
return model_version
def load_production_model(self, model_name):
"""加载生产环境中的模型"""
client = mlflow.tracking.MlflowClient()
model_version = client.get_latest_versions(model_name, stages="Production")0
print(f"加载生产环境模型: {model_name},版本: {model_version.version}")
model = mlflow.sklearn.load_model(f"models:/{model_name}/Production")
return model
使用示例
if name == "main":
初始化MLflow管理器
manager = MLflowModelManager(experiment_name="乳腺癌检测模型")
加载和预处理数据
X_train, X_test, y_train, y_test, feature_names = manager.load_and_preprocess_data()
训练随机森林模型
rf_run_id, rf_metrics = manager.train_random_forest(
X_train, X_test, y_train, y_test,
params={"n_estimators": 150, "max_depth": 10, "random_state": 42}
)
训练XGBoost模型
xgb_run_id, xgb_metrics = manager.train_xgboost(
X_train, X_test, y_train, y_test,
params={"max_depth": 5, "learning_rate": 0.05, "n_estimators": 200}
)
超参数优化
tuning_run_id, best_params, tuning_metrics = manager.hyperparameter_tuning(
X_train, X_test, y_train, y_test
)
注册最佳模型
best_model = manager.register_best_model("breast_cancer_detector", metric_name="f1")
加载生产模型(实际应用中)
production_model = manager.load_production_model("breast_cancer_detector")
predictions = production_model.predict(X_test)
代码解析:上述脚本实现了一个完整的机器学习模型生命周期管理流程,包括:
- 实验初始化:创建 MLflow 实验,设置跟踪环境
- 数据处理:加载数据集、数据分割、记录数据特征与分布
- 模型训练:分别训练随机森林和 XGBoost 模型,自动记录参数和指标
- 模型解释:生成特征重要性图和 SHAP 值可视化,解释模型决策
- 超参优化:使用网格搜索寻找最佳参数组合
- 模型注册:将表现最佳的模型注册到模型仓库,并标记为生产环境版本
- 模型加载:从模型仓库加载生产环境模型用于预测
通过 MLflow,开发者可以轻松对比不同模型的性能、复现实验结果、管理模型版本,大幅提升模型开发效率。
3.4 模型训练平台使用最佳实践
-
实验跟踪规范
- 统一命名规范:
[模型类型]-[日期]-[主要改进] - 完整记录参数:数据预处理参数、模型超参数、训练环境参数
- 标准化指标:定义核心评估指标,确保不同实验间可对比
- 统一命名规范:
-
资源优化策略
- 合理分配 GPU 资源:根据模型大小选择合适的 GPU 型号和数量
- 混合精度训练:使用 FP16/FP8 精度加速训练,减少内存占用
- 梯度累积:在小批量训练时模拟大批量效果,提升模型性能
- 分布式训练:数据并行(多 GPU)和模型并行(超大模型)
-
模型版本管理
flowchart LR A[开发阶段<br>Development] --> B[测试阶段<br>Staging] B --> C[生产阶段<br>Production] C --> D[归档阶段<br>Archived] A --> D B --> D C --> B -
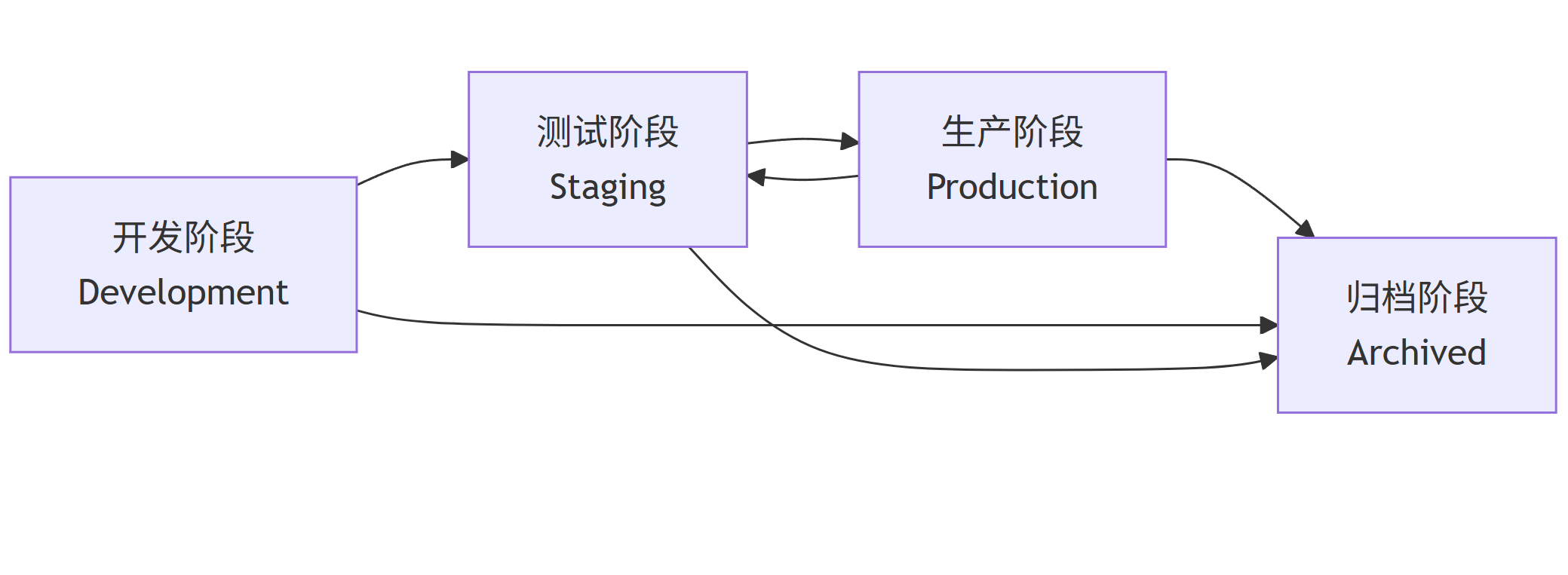
-
自动化流水线
- 数据更新触发重新训练
- 模型性能不达标自动告警
- 新版本模型自动部署与 A/B 测试
四、AI 开发工具集成与未来趋势
4.1 工具链集成方案
现代 AI 开发不再依赖单一工具,而是形成了覆盖全流程的工具链。以下是一个典型的企业级 AI 开发工具链集成方案:
graph TD
A[代码开发] --> A1[GitHub Copilot<br>智能编码辅助]
A --> A2[VS Code/JetBrains<br>集成开发环境]
A --> A3[Git<br>版本控制]
B[数据处理] --> B1[Label Studio<br>数据标注]
B --> B2[DVC<br>数据版本控制]
B --> B3[Pandas/Spark<br>数据处理]
C[模型开发] --> C1[PyTorch/TensorFlow<br>深度学习框架]
C --> C2[MLflow<br>实验跟踪]
C --> C3[Optuna<br>超参优化]
C --> C4[Weights & Biases<br>可视化与协作]
D[模型部署] --> D1[Docker<br>容器化]
D --> D2[Kubernetes<br>编排与扩展]
D --> D3[TorchServe/TensorRT<br>模型优化]
D --> D4[FastAPI/Flask<br>API服务]
E[监控与维护] --> E1[Prometheus/Grafana<br>性能监控]
E --> E2[Evidently AI<br>数据漂移检测]
E --> E3[MLflow Model Registry<br>模型版本管理]
A --> B
B --> C
C --> D
D --> E
E --> B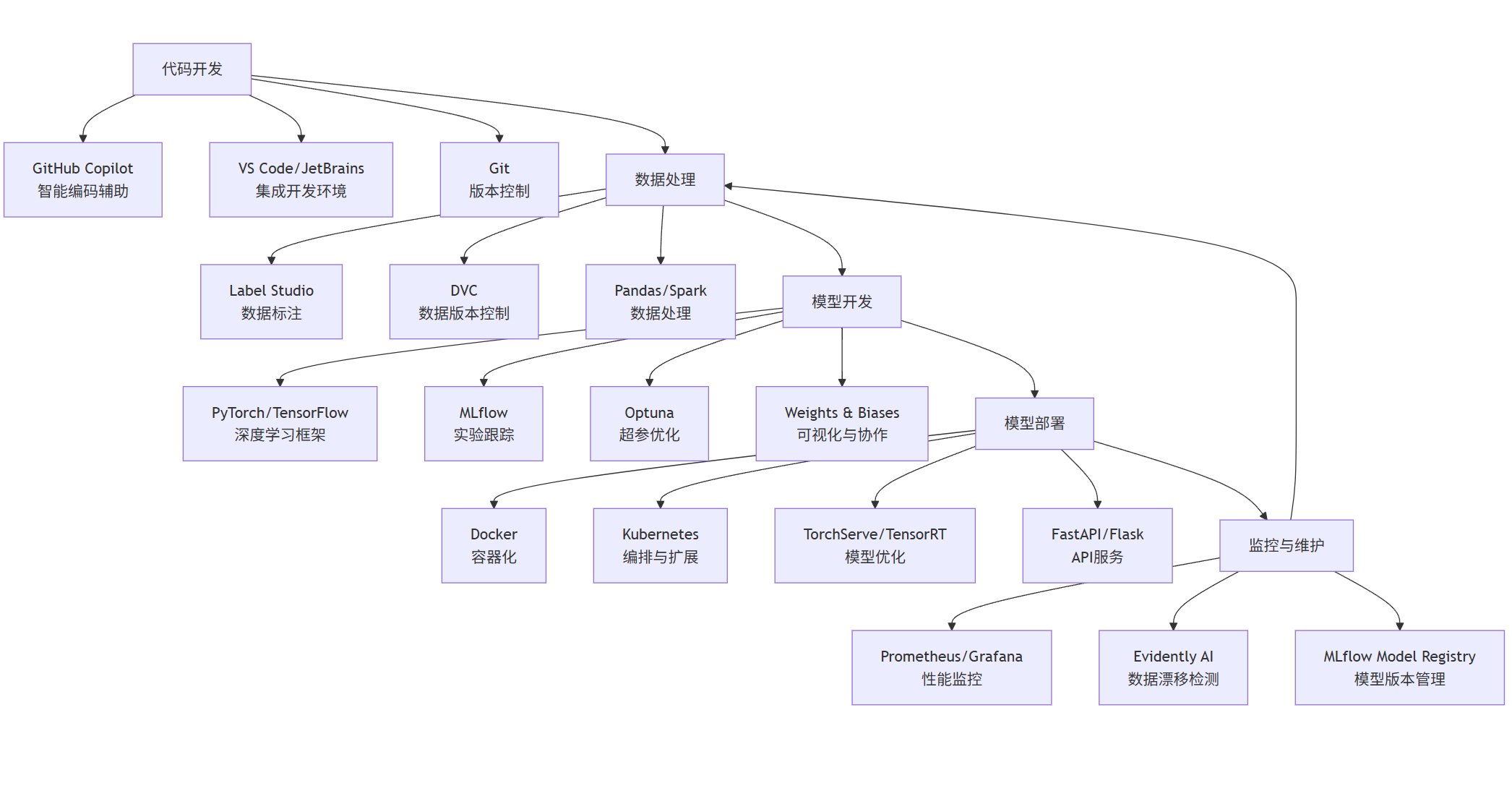
4.2 未来发展趋势
-
全流程自动化
- AI 辅助从编码扩展到数据准备、模型设计、部署运维全流程
- 低代码 / 无代码平台与专业工具融合,降低 AI 开发门槛
-
多模态融合
- 工具支持文本、图像、音频、视频等多模态数据统一处理
- 跨模态模型训练与部署工具链日趋成熟
-
边缘计算支持
- 轻量化工具链支持在边缘设备上进行模型训练与部署
- 模型压缩、量化工具与训练平台深度集成
-
隐私保护增强
- 联邦学习、差分隐私等技术与开发工具深度融合
- 数据加密与隐私保护成为工具标配功能
-
开源与商业化并存
- 开源工具提供核心功能,商业化工具提供企业级支持与服务
- 社区驱动与商业公司支持形成互补生态
五、总结
AI 开发工具正从单一功能工具向全流程平台演进,智能编码工具提升开发效率,数据标注工具保障数据质量,模型训练平台加速模型迭代。掌握这些工具的使用方法和集成策略,是提升 AI 项目成功率的关键。
随着大语言模型和生成式 AI 技术的发展,AI 开发工具将变得更加智能、自动化,进一步降低 AI 技术的使用门槛,推动 AI 应用在各行各业的普及。开发者需要持续关注工具生态的发展,不断优化工作流程,才能在快速变化的 AI 领域保持竞争力。
通过本文介绍的工具使用方法、代码示例和最佳实践,希望能帮助开发者构建高效的 AI 开发流水线,从繁琐的重复性工作中解放出来,专注于创造性的模型设计和问题解决,推动 AI 技术的创新与应用。