
2019
1.摘要
background
背景: 当前先进的深度神经网络通常层数很深、计算和内存成本高昂,难以部署在资源受限的设备上。
动机: 知识蒸馏(Knowledge Distillation, KD)是一种有效的方法,旨在将一个复杂的"教师模型"学到的知识迁移到一个轻量的"学生模型"中。
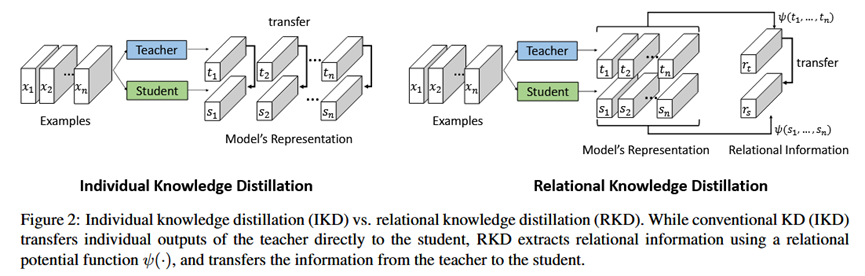
问题 : 传统知识蒸馏方法的核心思想是让学生模型模仿教师模型对单个样本 的输出激活值(例如logits或特征图),这是一种"点对点"的知识迁移。作者认为这种方式可能不是最有效的,因为它忽略了数据样本之间的相互关系,而这种关系恰恰构成了知识的关键部分。作者从语言结构主义中获得启发:一个符号(数据样本)的意义取决于它与系统中其他符号的关系。
innovation
核心创新点 : 论文提出了一个全新的视角,认为模型的知识更多地体现在它所学到的数据样本之间的结构关系 中,而非单个样本的独立输出。因此,知识迁移的目标应该是让学生模型学习教师模型输出的关系结构,实现"结构对结构"的迁移。
提出新方法 : 基于上述思想,论文提出了一种新颖的关系知识蒸馏 (Relational Knowledge Distillation, RKD) 框架。
具体实现 : 为了实现RKD,论文设计了两种具体的损失函数:
1. 距离损失 (Distance-wise loss) : 惩罚教师和学生模型输出空间中,成对样本之间欧氏距离的差异。这是一种二阶关系。
2. 角度损失 (Angle-wise loss) : 惩罚教师和学生模型输出空间中,由三个样本组成的夹角的差异。这是一种更高阶(三阶)的关系。
- 方法 Method
总体框架 (Pipeline)
该方法的核心流程如下:
1.给定一个教师模型T和一个学生模型S。
2.从数据集中取一个mini-batch的样本作为输入。
3.将这批样本分别输入教师和学生模型,得到各自的输出特征表示(例如,全连接层之前的特征向量)。
4.核心步骤: RKD不直接比较教师和学生的单个输出,而是从一个mini-batch的输出中构建N元组(例如,样本对或样本三元组)。
5.定义一个关系势能函数 (Relational Potential Function) ψ(·),用它来计算这些N元组的结构关系信息(例如,计算一对样本的距离,或三个样本的夹角)。
6.最后,通过一个损失函数 l 来最小化教师和学生的关系信息之间的差异,即 l(ψ(teacher_outputs), ψ(student_outputs))。
7.总的训练目标函数由任务损失(如分类的交叉熵损失)和RKD损失加权组成:L_total = L_task + λ * L_RKD。
各部分细节
1.距离损失 (Distance-wise Distillation Loss, RKD-D)
输入: 一个mini-batch中任意一对样本 (xi, xj) 在教师和学生模型中的输出 (ti, tj) 和 (si, sj)。
计算:
势能函数 ψD 计算两个输出向量之间的欧氏距离。
为了消除教师和学生模型输出尺度不一致带来的影响,该距离会被mini-batch内的平均距离进行归一化。
损失函数采用Huber Loss来计算教师归一化距离和学生归一化距离之间的差异,这比L2损失更稳健。
输出: 距离蒸馏损失 LRKD-D。
2.角度损失 (Angle-wise Distillation Loss, RKD-A)
输入: 一个mini-batch中任意三个样本 (xi, xj, xk) 在教师和学生模型中的输出 (ti, tj, tk) 和 (si, sj, sk)。
计算:
势能函数 ψA 计算由这三个点形成的夹角的余弦值(例如,以 xj 为顶点,计算向量 xj->xi 和 xj->xk 的夹角余弦)。
损失函数同样采用Huber Loss计算教师和学生输出的对应角度余弦值之间的差异。
输出: 角度蒸馏损失 LRKD-A。
- 实验 Experimental Results
实验数据集:
度量学习: CUB-200-2011, Cars 196, Stanford Online Products (SOP)。
图像分类: CIFAR-100, Tiny ImageNet。
少样本学习: Omniglot, miniImageNet。
主要实验结论:
1.向小模型蒸馏 (度量学习):
实验目的: 验证RKD能否有效地将知识从大模型迁移到小模型,并与其他KD方法进行比较。
结论: RKD的性能显著优于基线(直接用Triplet loss训练)和其他KD方法(如FitNet, Attention, DarkRank)。在Cars 196数据集上,使用RKD训练的小学生模型(ResNet18-128)的性能(82.50%)甚至远超强大的教师模型(ResNet50-512)的性能(77.17%)。
2.自蒸馏:
实验目的: 验证当教师和学生模型结构相同时,RKD是否能提升模型性能。
结论: 在多个数据集上,使用RKD进行一代自蒸馏就能显著提升模型的性能。
3.与SOTA方法对比 (度量学习):
实验目的: 将RKD与当时最先进的度量学习方法进行比较。
结论: 无论使用何种骨干网络(GoogLeNet或ResNet50),RKD在所有三个基准数据集上都取得了极具竞争力的结果,在多个榜单上达到SOTA。
4.图像分类任务:
实验目的: 验证RKD的通用性,以及它与传统IKD方法的互补性。
结论: RKD同样能提升分类任务的性能。更有趣的是,将RKD与传统IKD方法(如Hinton的KD)结合使用时,性能会进一步提升,证明了它们捕捉到了互补的知识信息。
5.少样本学习任务:
实验目的: 在另一个不同的任务上验证RKD的有效性。
结论: RKD能稳定地提升Prototypical Networks在Omniglot和miniImageNet上的性能。
- 总结 Conclusion
神经网络中知识的核心,不仅在于它对单个样本的映射能力,更在于它为整个数据空间建立的关系结构。通过迁移这种关系知识(例如,通过距离和角度损失),可以实现比传统模仿单个输出更高效的知识蒸馏,尤其适用于度量学习这类强调样本间关系的任务。