第二章 Transformer架构-从注意力机制到完整实现
总目录
-
[第二章 Transformer 架构原理](#第二章 Transformer 架构原理)
-
[第三章 预训练语言模型](#第三章 预训练语言模型)
-
[第四章 大语言模型](#第四章 大语言模型)
-
[第五章 动手搭建大模型](#第五章 动手搭建大模型)
-
[第六章 大模型训练实践](#第六章 大模型训练实践)
-
[第七章 大模型应用](#第七章 大模型应用)
目录
- [3. Encoder-Decoder架构](#3. Encoder-Decoder架构)
- [3.1 Seq2Seq任务介绍](#3.1 Seq2Seq任务介绍)
- [3.2 前馈神经网络](#3.2 前馈神经网络)
- [3.3 层归一化](#3.3 层归一化)
- [3.3.1 为什么需要归一化](#3.3.1 为什么需要归一化)
- [3.3.2 Batch Norm vs Layer Norm](#3.3.2 Batch Norm vs Layer Norm)
- [3.3.3 Layer Norm的计算](#3.3.3 Layer Norm的计算)
- [3.4 残差连接](#3.4 残差连接)
- [3.4.1 什么是残差连接](#3.4.1 什么是残差连接)
- [3.4.2 为什么残差连接有效](#3.4.2 为什么残差连接有效)
- [3.4.3 Transformer中的残差连接](#3.4.3 Transformer中的残差连接)
- [3.5 Encoder的实现](#3.5 Encoder的实现)
- [3.5.1 Encoder Layer实现](#3.5.1 Encoder Layer实现)
- [3.5.2 完整Encoder实现](#3.5.2 完整Encoder实现)
- [3.6 Decoder的实现](#3.6 Decoder的实现)
- [3.6.1 Decoder Layer实现](#3.6.1 Decoder Layer实现)
- [3.6.2 完整Decoder实现](#3.6.2 完整Decoder实现)
3. Encoder-Decoder架构
3.1 Seq2Seq任务介绍
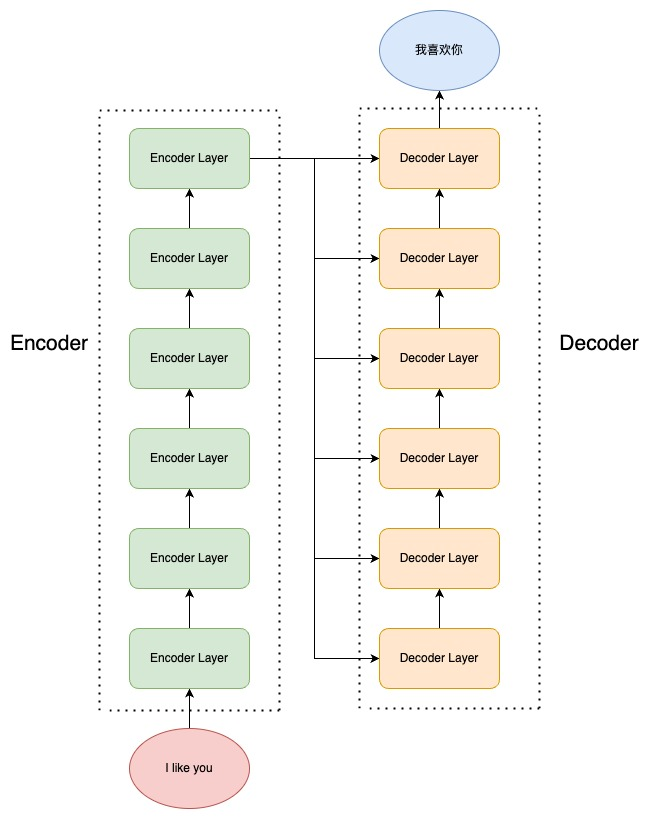
**序列到序列(Sequence-to-Sequence, Seq2Seq)**任务是NLP中最基础也最重要的任务类型。它指的是:
- 输入:一个序列 input = ( x 1 , x 2 , . . . , x n ) \text{input} = (x_1, x_2, ..., x_n) input=(x1,x2,...,xn)
- 输出:另一个序列 output = ( y 1 , y 2 , . . . , y m ) \text{output} = (y_1, y_2, ..., y_m) output=(y1,y2,...,ym)
典型的Seq2Seq任务包括:
- 机器翻译:输入中文,输出英文
- 文本摘要:输入长文本,输出摘要
- 对话生成:输入问题,输出回答
Seq2Seq模型通常采用**编码-解码(Encode-Decode)**框架:
- Encoder(编码器):将输入序列编码成固定的向量表示
- Decoder(解码器):根据编码结果生成输出序列
Transformer就是一个经典的Encoder-Decoder模型。

3.2 前馈神经网络
前馈神经网络(Feed-Forward Neural Network, FFN)是Transformer中的一个重要组件。每个Encoder层和Decoder层都包含一个FFN。
Transformer中的FFN由两个线性层和一个激活函数组成:
FFN ( x ) = ReLU ( x W 1 + b 1 ) W 2 + b 2 \text{FFN}(x) = \text{ReLU}(xW_1 + b_1)W_2 + b_2 FFN(x)=ReLU(xW1+b1)W2+b2
实现代码:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class FeedForward(nn.Module):
"""前馈神经网络模块"""
def __init__(self, n_embd, hidden_dim, dropout=0.1):
"""
参数:
n_embd: 输入和输出维度
hidden_dim: 隐藏层维度(通常是n_embd的4倍)
dropout: dropout比率
"""
super().__init__()
# 第一个线性层:n_embd -> hidden_dim
self.w1 = nn.Linear(n_embd, hidden_dim, bias=False)
# 第二个线性层:hidden_dim -> n_embd
self.w2 = nn.Linear(hidden_dim, n_embd, bias=False)
# Dropout层,用于防止过拟合
self.dropout = nn.Dropout(dropout)
def forward(self, x):
"""
前向传播
参数:
x: 输入,shape = (batch_size, seq_len, n_embd)
返回:
输出,shape = (batch_size, seq_len, n_embd)
"""
# x -> 线性变换1 -> ReLU激活 -> 线性变换2 -> Dropout
return self.dropout(self.w2(F.relu(self.w1(x))))3.3 层归一化
层归一化(Layer Normalization)是深度学习中常用的归一化技术。
3.3.1 为什么需要归一化?
在深度神经网络中,随着层数的增加,每一层的输入分布可能会发生较大变化(称为内部协变量偏移)。这会导致:
- 训练不稳定
- 梯度消失或爆炸
- 需要更小的学习率
归一化可以稳定训练过程,加快收敛速度。
3.3.2 Batch Norm vs Layer Norm
Batch Normalization(批归一化):
- 在一个mini-batch上统计均值和方差
- 对每个特征维度分别归一化
Layer Normalization(层归一化):
- 在每个样本上统计均值和方差
- 对所有特征维度一起归一化
Layer Norm的优势:
- 不依赖batch size,适合小batch训练
- 更适合序列模型(RNN、Transformer)
- 测试时不需要保存训练统计量
3.3.3 Layer Norm的计算
对于输入 x ∈ R d x \in \mathbb{R}^d x∈Rd,Layer Norm的计算步骤:
- 计算均值: μ = 1 d ∑ i = 1 d x i \mu = \frac{1}{d}\sum_{i=1}^d x_i μ=d1∑i=1dxi
- 计算方差: σ 2 = 1 d ∑ i = 1 d ( x i − μ ) 2 \sigma^2 = \frac{1}{d}\sum_{i=1}^d (x_i - \mu)^2 σ2=d1∑i=1d(xi−μ)2
- 归一化: x ^ = x − μ σ 2 + ϵ \hat{x} = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} x^=σ2+ϵ x−μ
- 缩放和平移: y = γ x ^ + β y = \gamma \hat{x} + \beta y=γx^+β
其中 γ \gamma γ 和 β \beta β 是可学习的参数, ϵ \epsilon ϵ 是一个小常数(防止除零)。
实现代码:
python
import torch
import torch.nn as nn
class LayerNorm(nn.Module):
"""层归一化模块"""
def __init__(self, n_embd, eps=1e-6):
"""
参数:
n_embd: 特征维度
eps: 防止除零的小常数
"""
super().__init__()
# 可学习的缩放参数,初始化为1
self.gamma = nn.Parameter(torch.ones(n_embd))
# 可学习的平移参数,初始化为0
self.beta = nn.Parameter(torch.zeros(n_embd))
self.eps = eps
def forward(self, x):
"""
前向传播
参数:
x: 输入,shape = (batch_size, seq_len, n_embd)
返回:
归一化后的输出,shape与输入相同
"""
# 在最后一个维度上计算均值和标准差
# mean shape = (batch_size, seq_len, 1)
mean = x.mean(dim=-1, keepdim=True)
# std shape = (batch_size, seq_len, 1)
std = x.std(dim=-1, keepdim=True)
# 归一化、缩放和平移
# 广播机制会自动处理维度
return self.gamma * (x - mean) / (std + self.eps) + self.beta3.4 残差连接
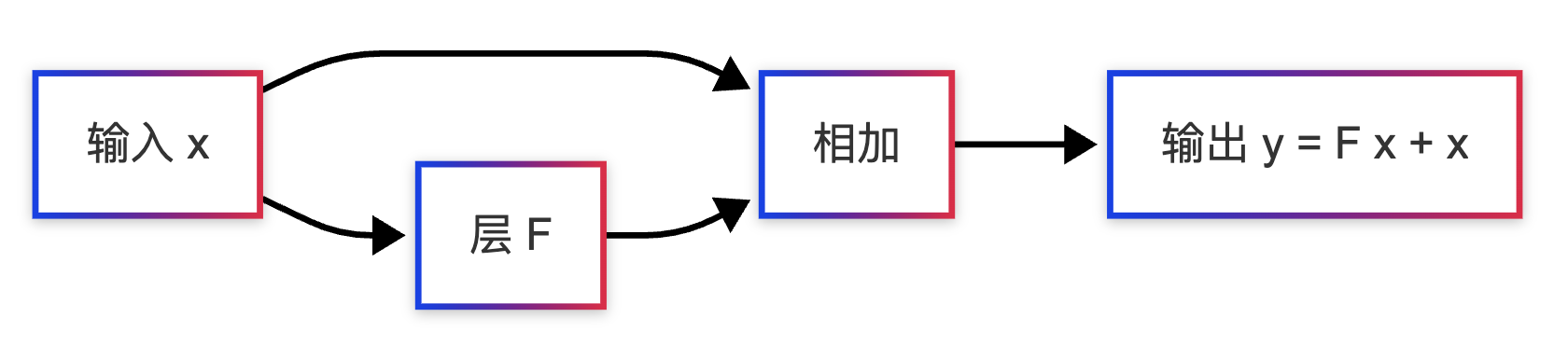
残差连接(Residual Connection)最早在ResNet中提出,用于解决深度网络的退化问题。
3.4.1 什么是残差连接?
残差连接的思想很简单:让每一层的输出包含原始输入。
普通网络: y = F ( x ) y = F(x) y=F(x)
残差网络: y = F ( x ) + x y = F(x) + x y=F(x)+x
3.4.2 为什么残差连接有效?
- 缓解梯度消失:梯度可以直接通过残差连接回传
- 更容易训练 :如果某一层不需要,可以学习为恒等映射( F ( x ) ≈ 0 F(x) \approx 0 F(x)≈0)
- 允许更深的网络:信息可以跨越多层直接传递
3.4.3 Transformer中的残差连接
在Transformer中,每个子层(注意力层、前馈网络)后面都有残差连接:
output = LayerNorm ( x + SubLayer ( x ) ) \text{output} = \text{LayerNorm}(x + \text{SubLayer}(x)) output=LayerNorm(x+SubLayer(x))
注意:这里采用的是Pre-Norm 结构,即先做Layer Norm,再做残差连接。原始论文使用的是Post-Norm(先残差连接,再Layer Norm),但实践证明Pre-Norm更稳定。
代码实现:
python
# 在Encoder/Decoder层中的使用
def forward(self, x):
# 残差连接 + Layer Norm + 注意力
x = x + self.attention(self.layer_norm1(x))
# 残差连接 + Layer Norm + 前馈网络
x = x + self.ffn(self.layer_norm2(x))
return x3.5 Encoder的实现
Encoder由多个Encoder层堆叠而成,每个Encoder层包含:
- 多头自注意力层
- 前馈神经网络
- 层归一化和残差连接
3.5.1 Encoder Layer实现
python
import torch
import torch.nn as nn
class EncoderLayer(nn.Module):
"""Transformer Encoder层"""
def __init__(self, n_embd, n_heads, hidden_dim, dropout=0.1):
"""
参数:
n_embd: 嵌入维度
n_heads: 注意力头数
hidden_dim: FFN隐藏层维度
dropout: dropout比率
"""
super().__init__()
# 第一个Layer Norm(用于注意力层之前)
self.attention_norm = LayerNorm(n_embd)
# 多头自注意力层(不使用掩码)
self.attention = MultiHeadAttention(n_embd, n_heads, dropout, is_causal=False)
# 第二个Layer Norm(用于FFN之前)
self.ffn_norm = LayerNorm(n_embd)
# 前馈神经网络
self.ffn = FeedForward(n_embd, hidden_dim, dropout)
def forward(self, x):
"""
前向传播
参数:
x: 输入,shape = (batch_size, seq_len, n_embd)
返回:
输出,shape = (batch_size, seq_len, n_embd)
"""
# 第一个子层:Layer Norm -> 自注意力 -> 残差连接
norm_x = self.attention_norm(x)
x = x + self.attention(norm_x, norm_x, norm_x)
# 第二个子层:Layer Norm -> FFN -> 残差连接
x = x + self.ffn(self.ffn_norm(x))
return x3.5.2 完整Encoder实现
python
class Encoder(nn.Module):
"""Transformer Encoder"""
def __init__(self, n_layers, n_embd, n_heads, hidden_dim, dropout=0.1):
"""
参数:
n_layers: Encoder层的数量
n_embd: 嵌入维度
n_heads: 注意力头数
hidden_dim: FFN隐藏层维度
dropout: dropout比率
"""
super().__init__()
# 堆叠多个Encoder层
self.layers = nn.ModuleList([
EncoderLayer(n_embd, n_heads, hidden_dim, dropout)
for _ in range(n_layers)
])
# 最后的Layer Norm
self.norm = LayerNorm(n_embd)
def forward(self, x):
"""
前向传播
参数:
x: 输入,shape = (batch_size, seq_len, n_embd)
返回:
编码结果,shape = (batch_size, seq_len, n_embd)
"""
# 依次通过每个Encoder层
for layer in self.layers:
x = layer(x)
# 最后的归一化
return self.norm(x)

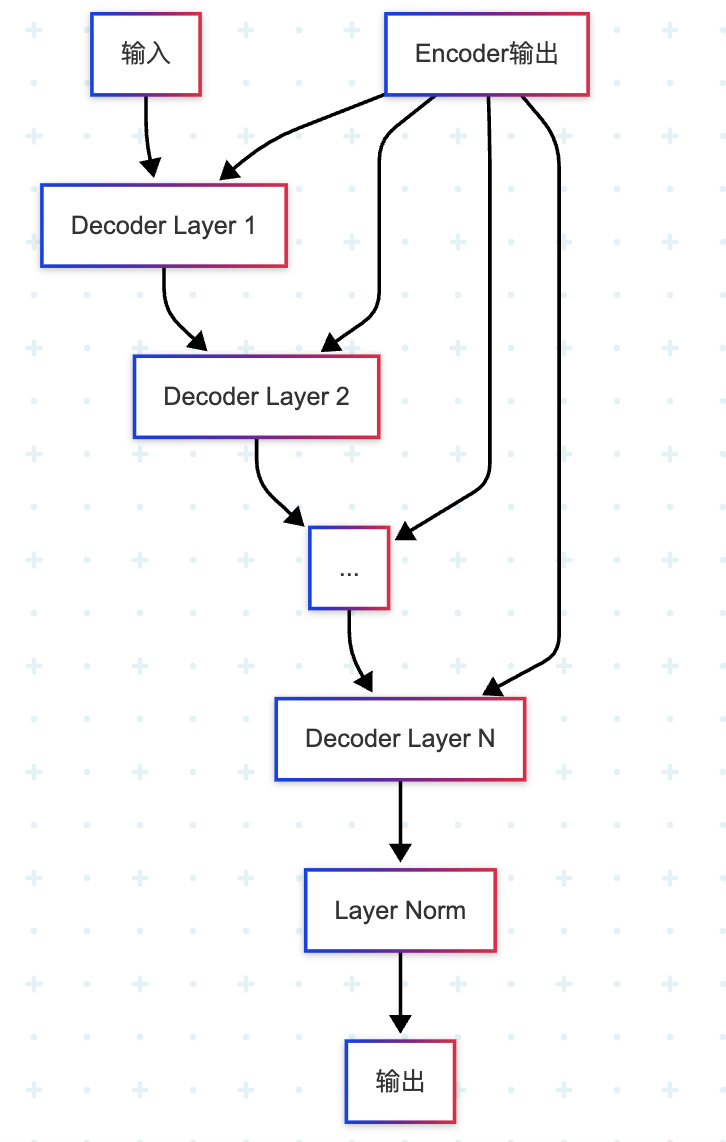
3.6 Decoder的实现
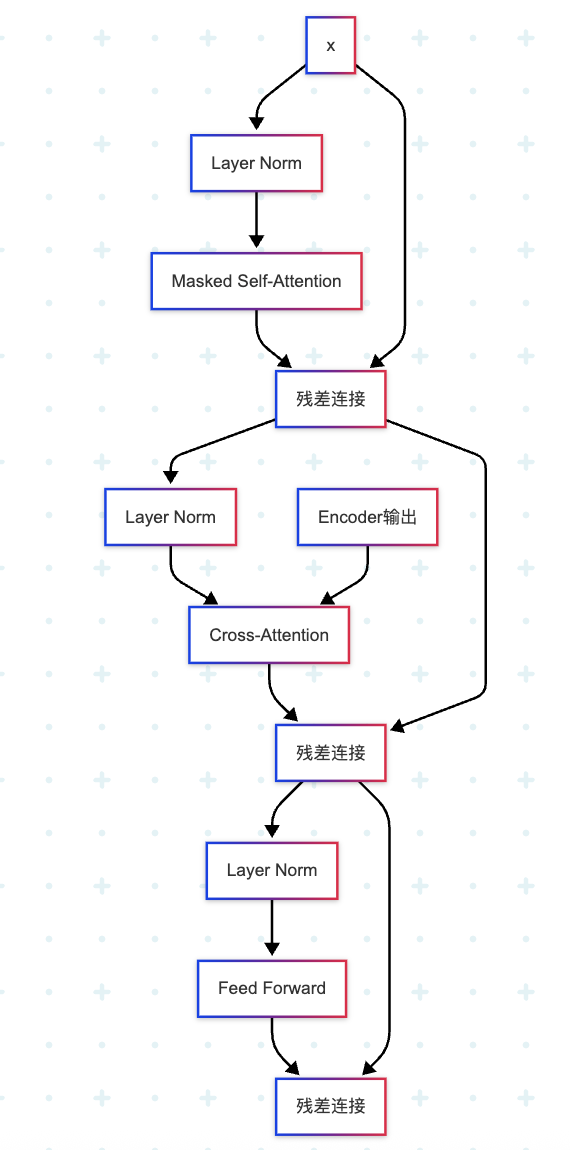
Decoder与Encoder类似,但有三个关键区别:
- 第一个注意力层使用掩码:防止看到未来信息
- 第二个注意力层是交叉注意力:Query来自Decoder,Key和Value来自Encoder输出
- 用于自回归生成:逐个生成输出token
3.6.1 Decoder Layer实现
python
class DecoderLayer(nn.Module):
"""Transformer Decoder层"""
def __init__(self, n_embd, n_heads, hidden_dim, dropout=0.1):
"""
参数:
n_embd: 嵌入维度
n_heads: 注意力头数
hidden_dim: FFN隐藏层维度
dropout: dropout比率
"""
super().__init__()
# 第一个子层:掩码自注意力
self.self_attn_norm = LayerNorm(n_embd)
self.self_attn = MultiHeadAttention(n_embd, n_heads, dropout, is_causal=True)
# 第二个子层:交叉注意力(与Encoder输出交互)
self.cross_attn_norm = LayerNorm(n_embd)
self.cross_attn = MultiHeadAttention(n_embd, n_heads, dropout, is_causal=False)
# 第三个子层:前馈网络
self.ffn_norm = LayerNorm(n_embd)
self.ffn = FeedForward(n_embd, hidden_dim, dropout)
def forward(self, x, encoder_output):
"""
前向传播
参数:
x: Decoder输入,shape = (batch_size, tgt_seq_len, n_embd)
encoder_output: Encoder输出,shape = (batch_size, src_seq_len, n_embd)
返回:
输出,shape = (batch_size, tgt_seq_len, n_embd)
"""
# 第一个子层:掩码自注意力
# Query、Key、Value都来自x(目标序列)
norm_x = self.self_attn_norm(x)
x = x + self.self_attn(norm_x, norm_x, norm_x)
# 第二个子层:交叉注意力
# Query来自x,Key和Value来自encoder_output
norm_x = self.cross_attn_norm(x)
x = x + self.cross_attn(norm_x, encoder_output, encoder_output)
# 第三个子层:前馈网络
x = x + self.ffn(self.ffn_norm(x))
return x3.6.2 完整Decoder实现
python
class Decoder(nn.Module):
"""Transformer Decoder"""
def __init__(self, n_layers, n_embd, n_heads, hidden_dim, dropout=0.1):
"""
参数:
n_layers: Decoder层的数量
n_embd: 嵌入维度
n_heads: 注意力头数
hidden_dim: FFN隐藏层维度
dropout: dropout比率
"""
super().__init__()
# 堆叠多个Decoder层
self.layers = nn.ModuleList([
DecoderLayer(n_embd, n_heads, hidden_dim, dropout)
for _ in range(n_layers)
])
# 最后的Layer Norm
self.norm = LayerNorm(n_embd)
def forward(self, x, encoder_output):
"""
前向传播
参数:
x: Decoder输入,shape = (batch_size, tgt_seq_len, n_embd)
encoder_output: Encoder输出,shape = (batch_size, src_seq_len, n_embd)
返回:
解码结果,shape = (batch_size, tgt_seq_len, n_embd)
"""
# 依次通过每个Decoder层
for layer in self.layers:
x = layer(x, encoder_output)
# 最后的归一化
return self.norm(x)