TextFusion(2025Inffus 2023.12)
语义
Test√
1.使用clip对text进行编码,将编码后的特征映射到和图像特征统一的维度上,然后作为权重加在图像特征上:
x = x_vis + text_features * x_ir
2.使用coarse to fine association来生成掩码Bf和热图M作用到损失函数上
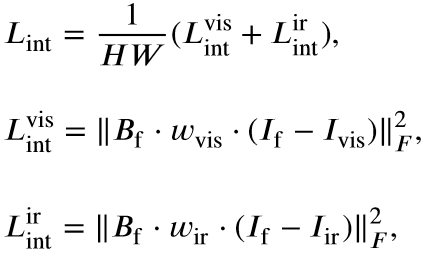
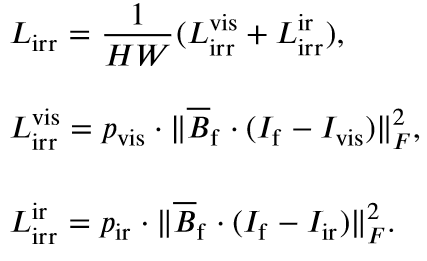
3.创建text引导的融合图像:
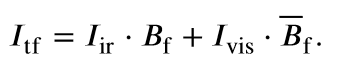
提出基于文本注意力的图像融合评估度量指标:
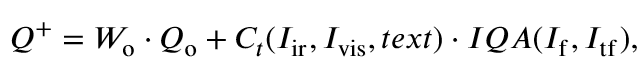
W0和CT分别代表传统和改进的评估组件的加权项。置信度得分CT是使用关联机制生成的热图计算的,定义为:
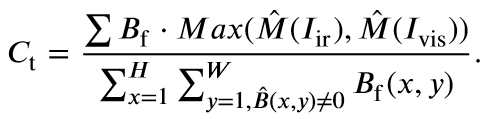
4.数据集
提出IVT数据集,每张图片带有5个文本描述,基本上是语义描述,1、2、3是分开描述,4、5是很全的描述。Train:IVT-LLVIP(10,000 RGBT and text triples) Test:IVT-TNO、IVT-RoadScene、IVT-LLVIP(remaining images)
IF-FILM:Image Fusion via Vision-Language Model(ICML2024 2024.03 DDFM、CDDFuse、IJCAI作者)
语义
Test×
首先,使用BLIP2、GRIT、Segment Anything对图像生成Image Caption, Dense Caption, and Semantic Mask,然后将它们喂到chatgpt来生成文本描述text,再将text输入到frozen的BLIP2得到文本特征,最后,将text的特征concat作为q与图像特征计算cross attention再解码。
数据集:可见光和红外光详细的text描述,包括各个语义对象的具体坐标以及图像的分辨率。还有blip编码的文本特征。
Eg:In this black and white photo of cars on a street at night, the resolution is 384X288. The image captures various objects and activities within the frame. One can see a car in the picture, positioned at 183, 138, 240, 190, as well as a car making a left turn at 25, 142, 109, 188. Furthermore, a person walking in the rain is also present, depicted at 16, 139, 31, 182. The photo also includes a large truck, which can be seen at 272, 105, 363, 190 and another car within the frame at 127, 146, 187, 171. Additionally, the scene shows a car on the street at 232, 148, 257, 177 and a car parked on the street at 369, 154, 381, 190. Moreover, a person standing can be noticed in the photo, positioned at 107, 139, 118, 170. Lastly, a tall electrical tower stands tall at 280, 3, 332, 107 and there is also a tall building with several stories at 0, 1, 180, 145. This image offers a glimpse into a city street at night, showcasing the hustle and bustle of urban life.
OCCO:LVM-guided Infrared and Visible Image Fusion Framework based on Object-aware and Contextual COntrastive Learning(arxiv202503 LiHui)
语义
Test×
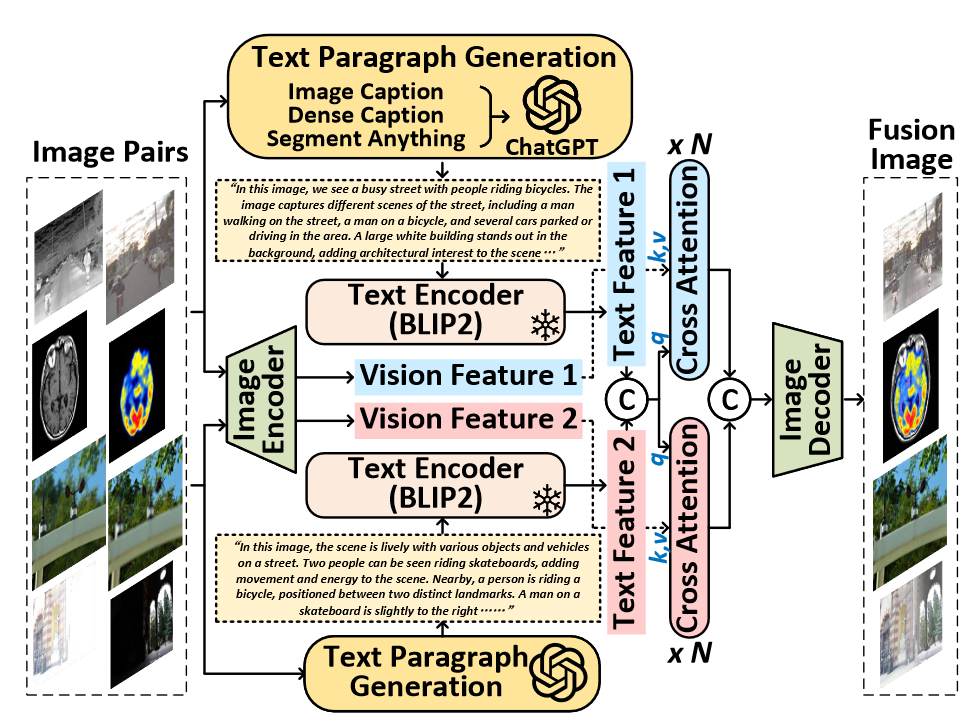
输入text prompt,使用grounding dino和sam来提取背景和语义信息(shared和unique)。
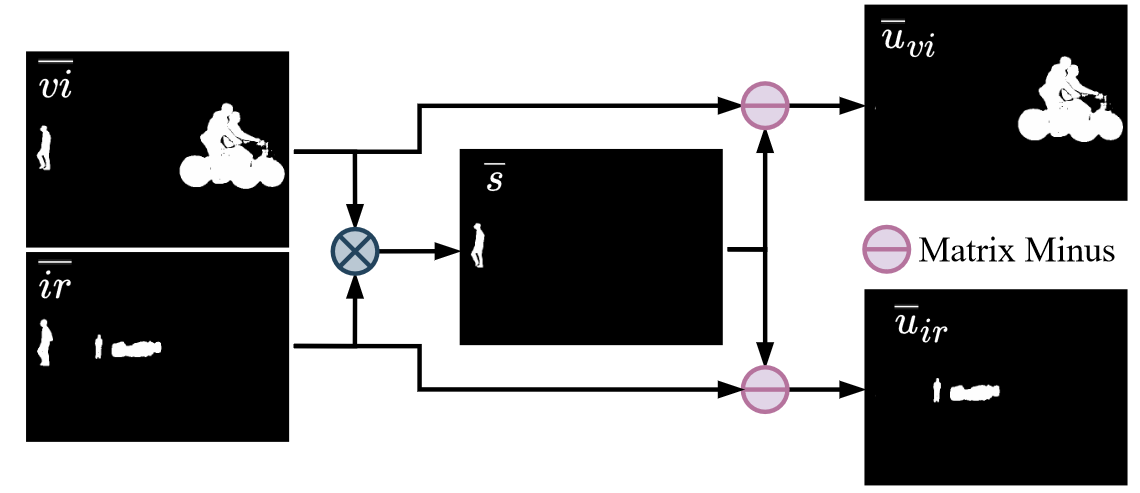
然后通过对比学习的思想来构建损失函数。
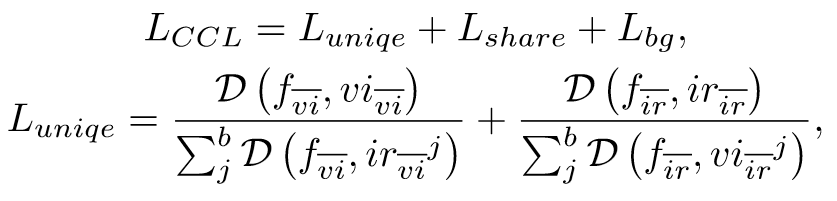
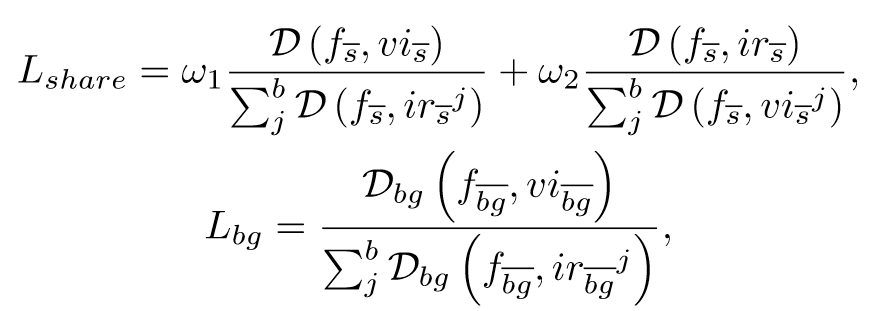
Text-IF(CVPR2024)
Degradation
Test√
1.使用clip对文本信息进行编码:
text_feature = self.model_clip.encode_text(text)然后将编码后的特征转换成权重和融合信息进行交互:
gamma, beta = self.MLP(text_embed).view(batch, -1, 1, 1).chunk(2, dim=1)
x = (1 + gamma) * x + beta2.在loss函数中通过调整各个损失函数权重的大小来适应各种不同的情况:
if task_type == "low_light":
loss, ssim_loss, max_loss, color_loss, grad_loss = self.fusion_loss(img_A, img_B, img_fused, max_ratio=8, ssim_ratio=1, text_ratio=10)
else:
raise ValueError(f"Unknown task type: {task_type}")2.数据集
带degradation标注的可见光红外图像对EMS(MFNet, RoadScene/FLIR_aligned, and LLVIP.)
TeRF(ACM MM2024)
Degradation
Test√
利用大模型
LDFusion: Infrared and visible Image Fusion with Language-driven Loss in CLIP Embedding Space
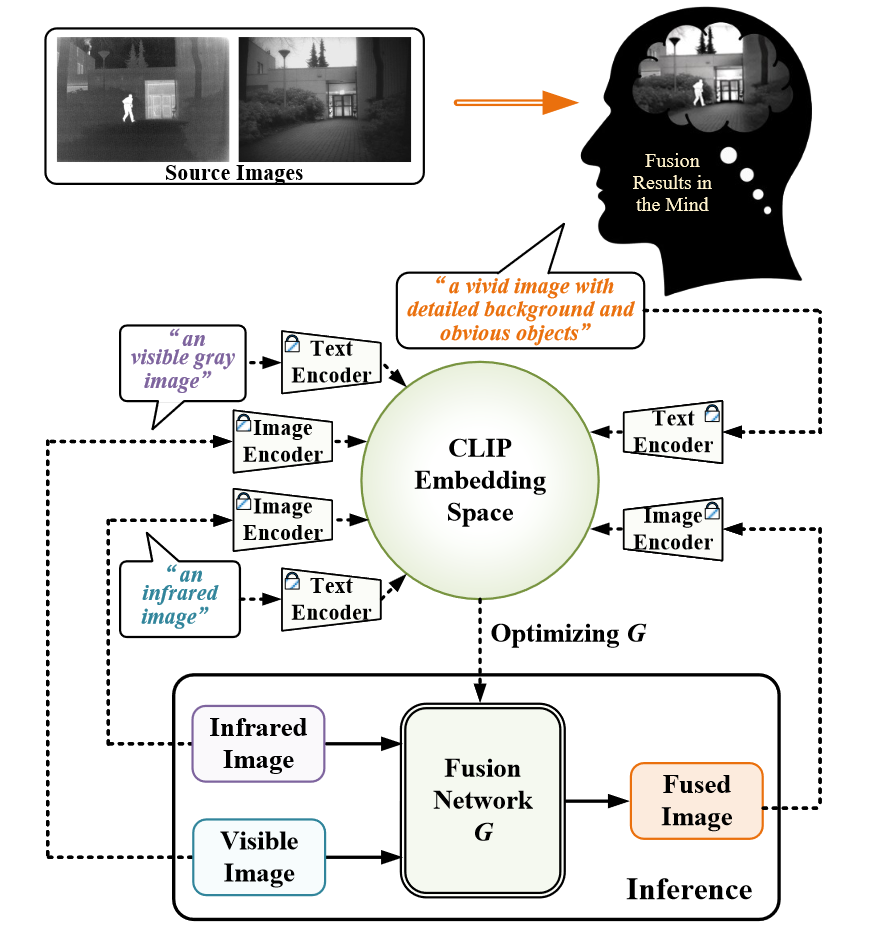
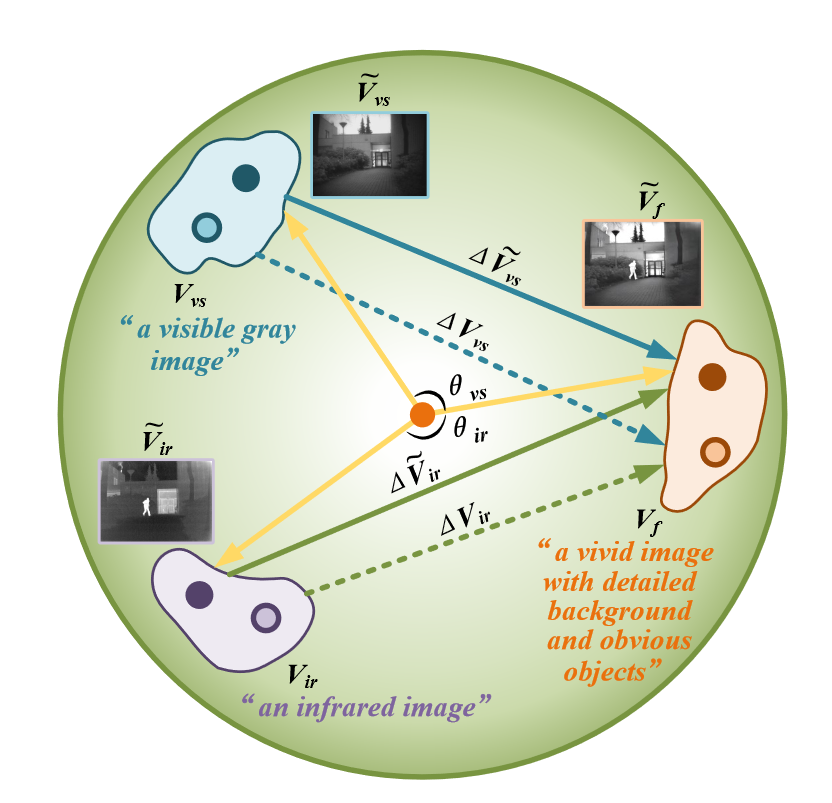
使用CLIP对可见光/红外/融合图像以及它们对应的文本进行编码,计算编码后的可见光/红外特征和融合特征差值,最小化text vector和image vector差值之间的距离:
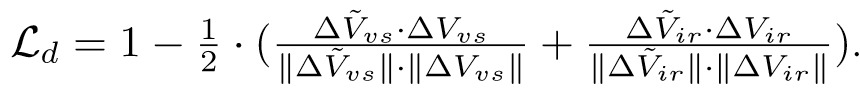
Robust Fusion Controller: Degradation-aware Image Fusion with Fine-grained Language Instructions(arxiv 4.9 jiayima)
Degradation
Test√
通过clip提取文本信息的特征,clipseg提取文本中的语义特征。再把两个特征通过网络合并起来,再以权重相乘和相加的方式加入到融合网络中。
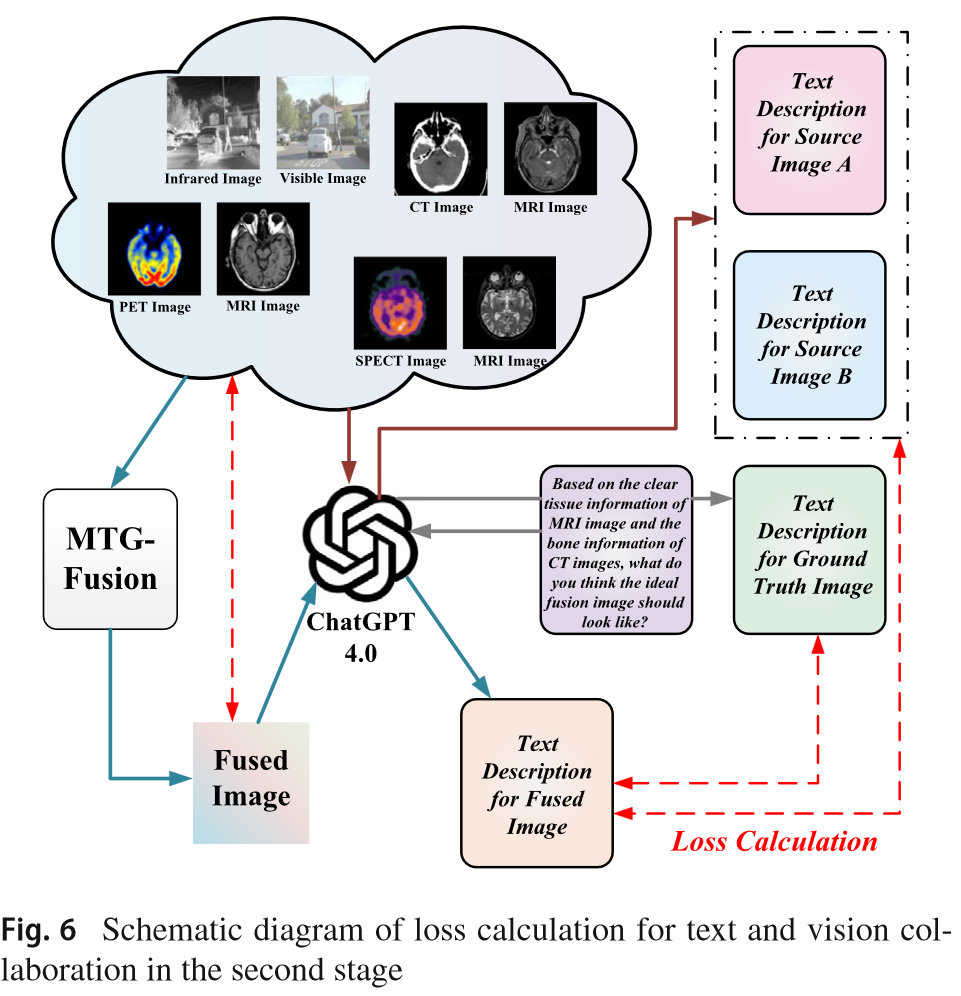
MTGFusion(2025IJCV)
没有侧重,文本仅作为辅助生成ground truth
Test×
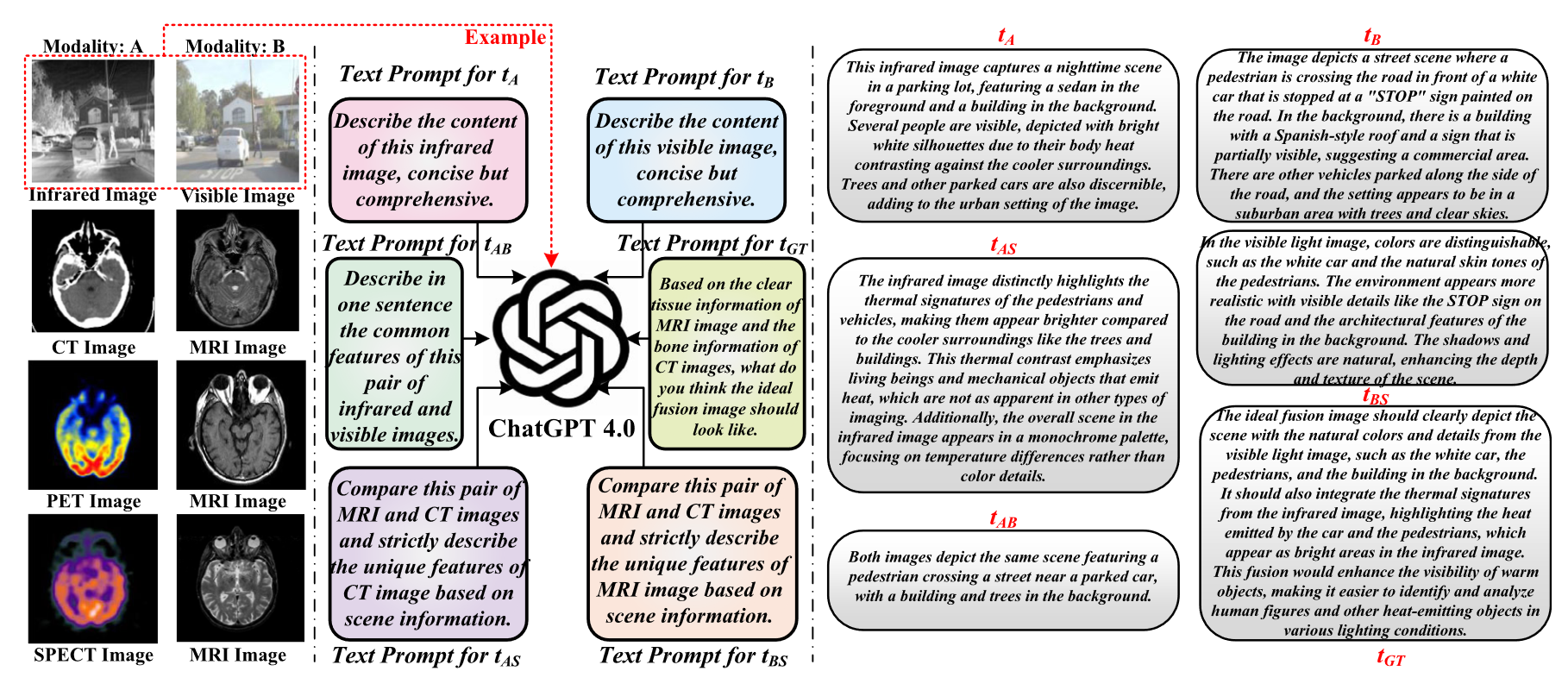
Text-image数据集构造的不错。重点关注如何打破text和image之间的模态差异的。
带文本标注的数据集生成:首先,用chatgpt4.0生成图像的描述,然后将其输入到BLIP进行编码。
将text prompt输入到chatgpt4,来生成不同的图像描述:

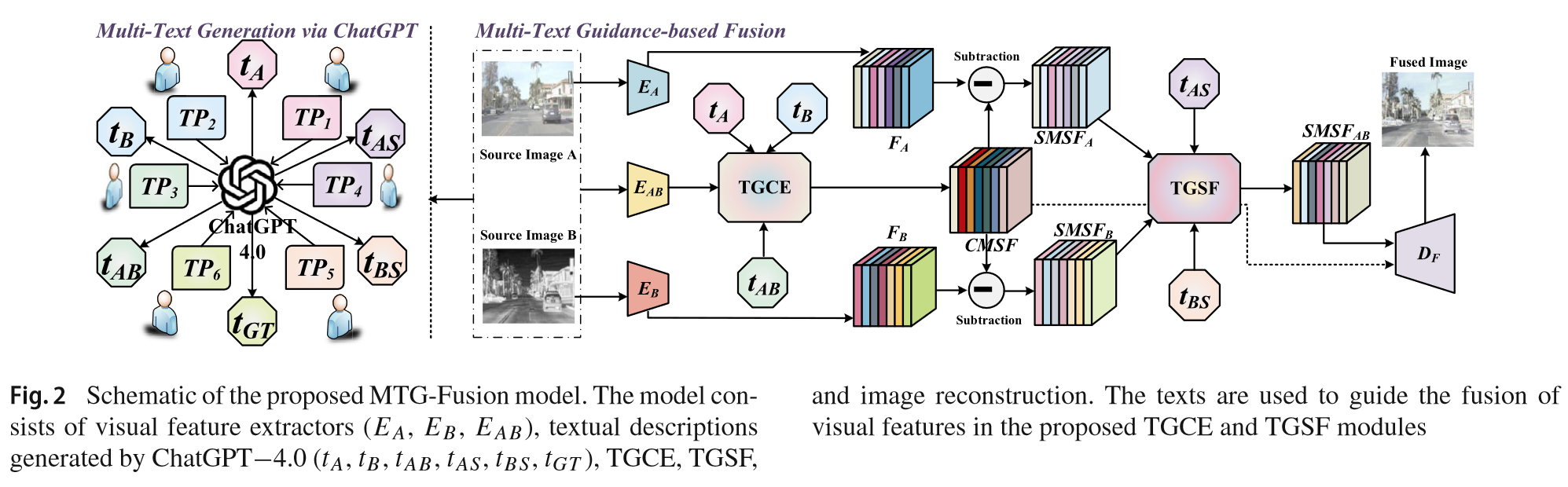
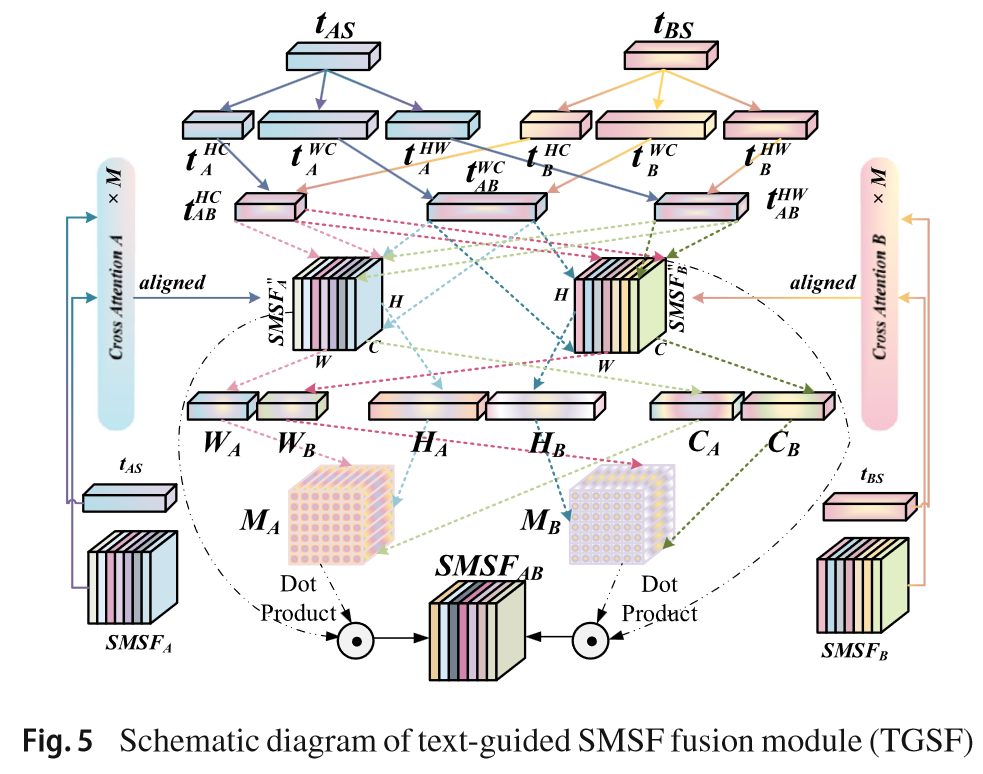
Text-Guided CMSF Extractor (TGCE)
Text Cube Construction
将BLIP编码的文本向量分别重塑到H、W、C空间中
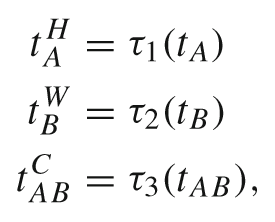
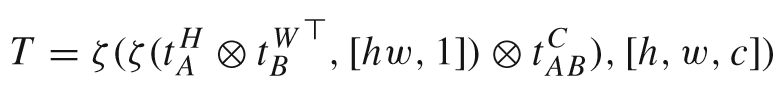
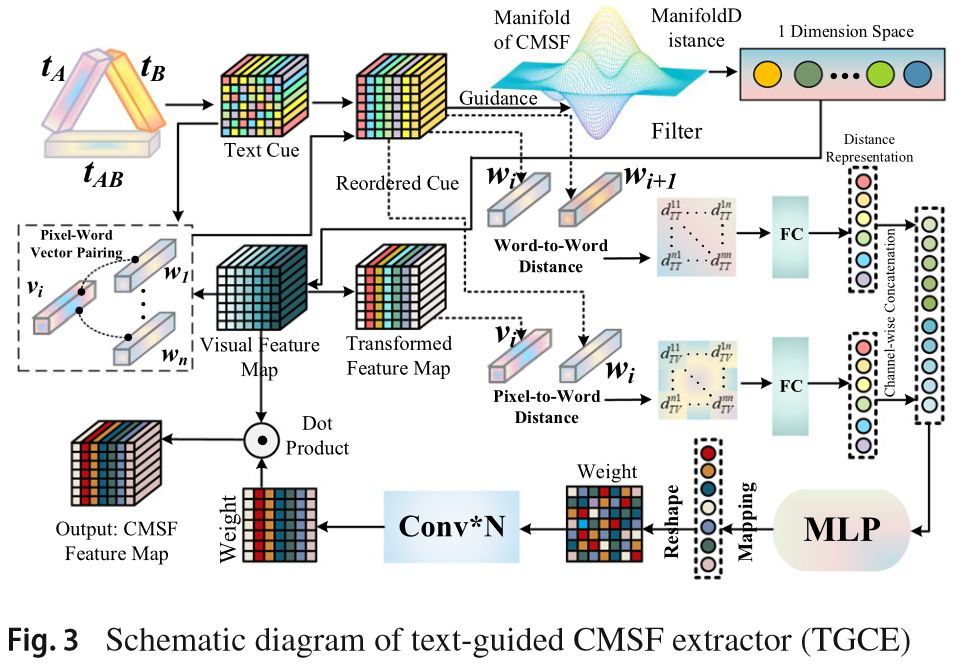
Text Cube Reordering
为了将文本和视觉特征进行匹配,计算每个像素的文本特征w和视觉特征v之间的相似度,每个像素点的文本特征值由与该像素点视觉特征最相似的文本特征赋值:
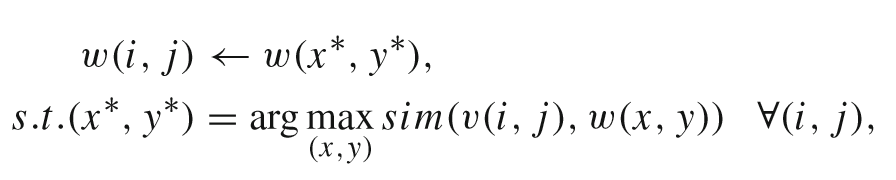
Text-Guided Domain Transform
目的:通过文本域的距离指导视觉特征的过滤和聚合。
首先计算文本特征中相邻向量的距离d,d反映了语义相似度,相似度越高,距离d越小。a∈(0,1)为前馈系数,d越大,当前特征受前一位置的影响越小。在语义差异大的区域(如物体边缘),保留更多原始视觉特征;在语义相似区域(如平滑背景),增强特征一致性。

Text-Guided SMSF Fusion Module (TGSF)
将文本特征重塑到各个维度上便于和视觉特征进行矩阵相乘操作得到融合的特征v,进而得到权重M。
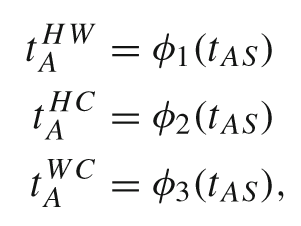
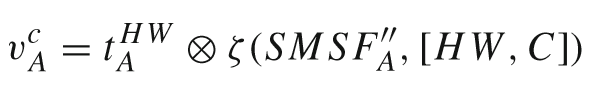
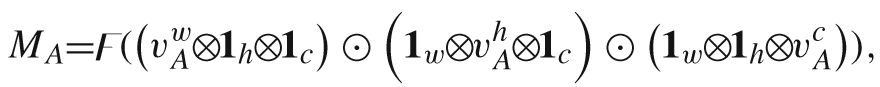
损失函数:在损失函数中加入文本损失:
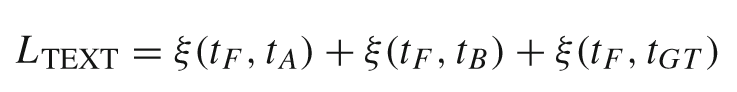
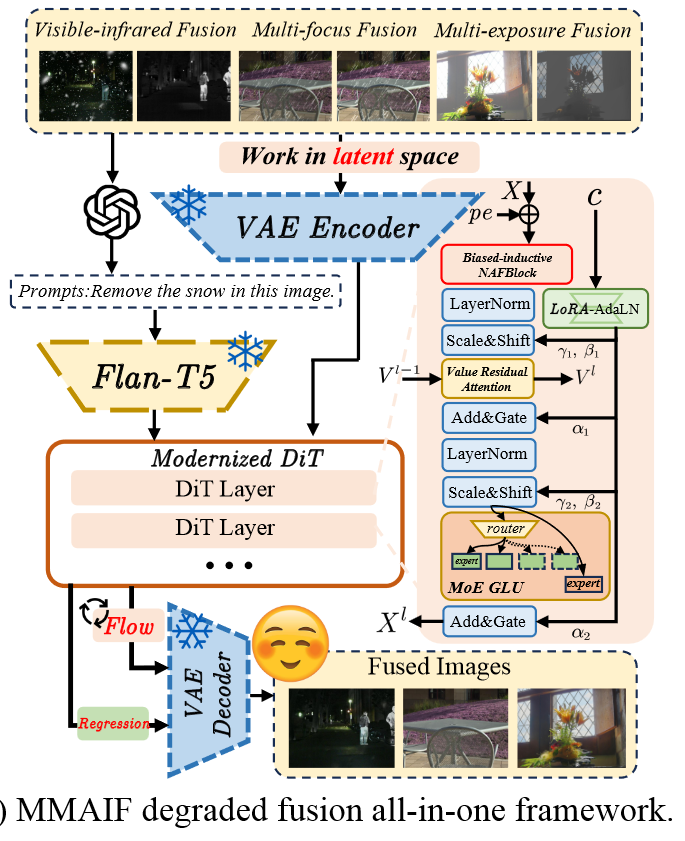
MMAIF: Multi-task and Multi-degradation All-in-One for Image Fusion with Language Guidance(arxiv202503)
Degradation
Test√
使用一堆大模型来实现文本生成编码以及图像增强功能。
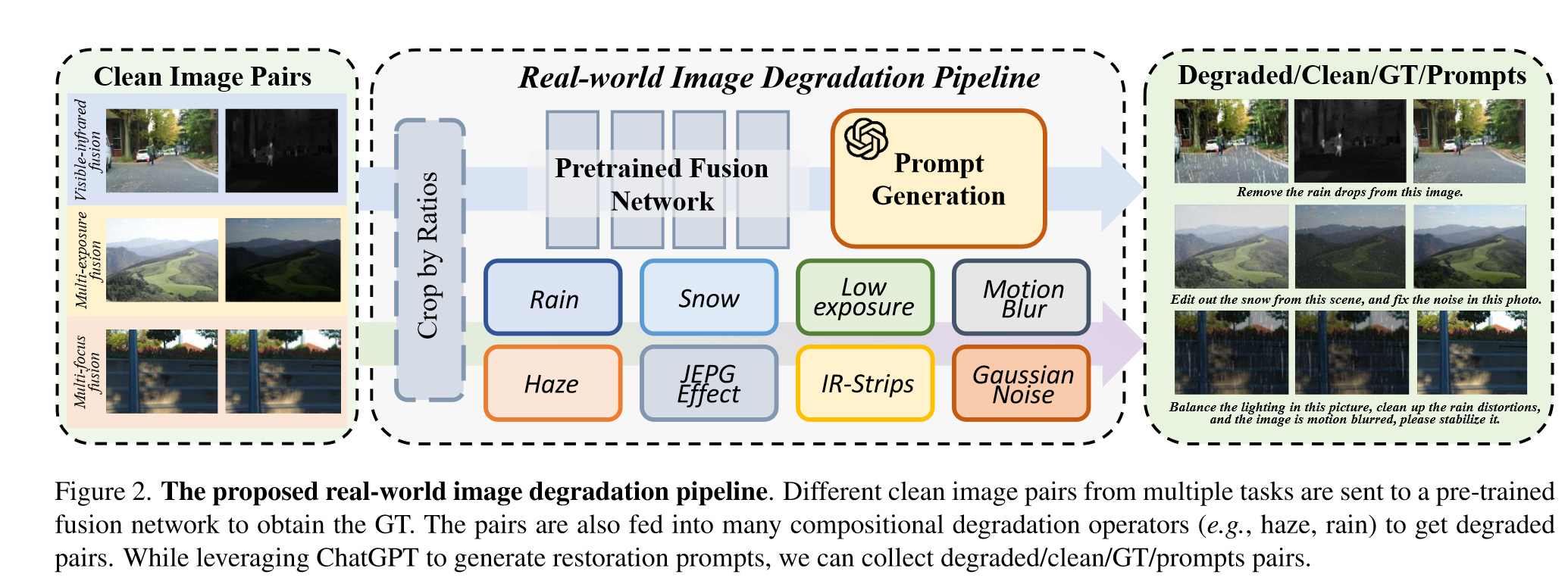
构建数据集
Degraded pairs:人工加degradations:Gaussian blur, motion blur, downsample, Gaussian noise...,为了使其更像真实图像,使用Depthything 来估计图像的深度,然后应用大气光散射公式来添加雾霾。
GT pairs:使用pre-trained SwinFusion and DeFuse生成。
Prompt pairs:使用chatgpt为每种degradation生成10至20个提示(e.g., "please remove the noise of the image pairs"),这些提示经过编码,然后在训练期间输入网络,以指导图像恢复和融合。
选择Cosmos VAE作为Image Tokenizer
对DiT进行了一番改造:1.用Moe Glu替换了原始的DIT FFN,从而实现了更大的模型容量和相对较低的FLOP要求;2.将1DRoPE调整为2DRoPE,并将其应用于每个注意力层中,以使模型对位置的感知并提高其长度外推能力;等等 看不懂这么改的意义
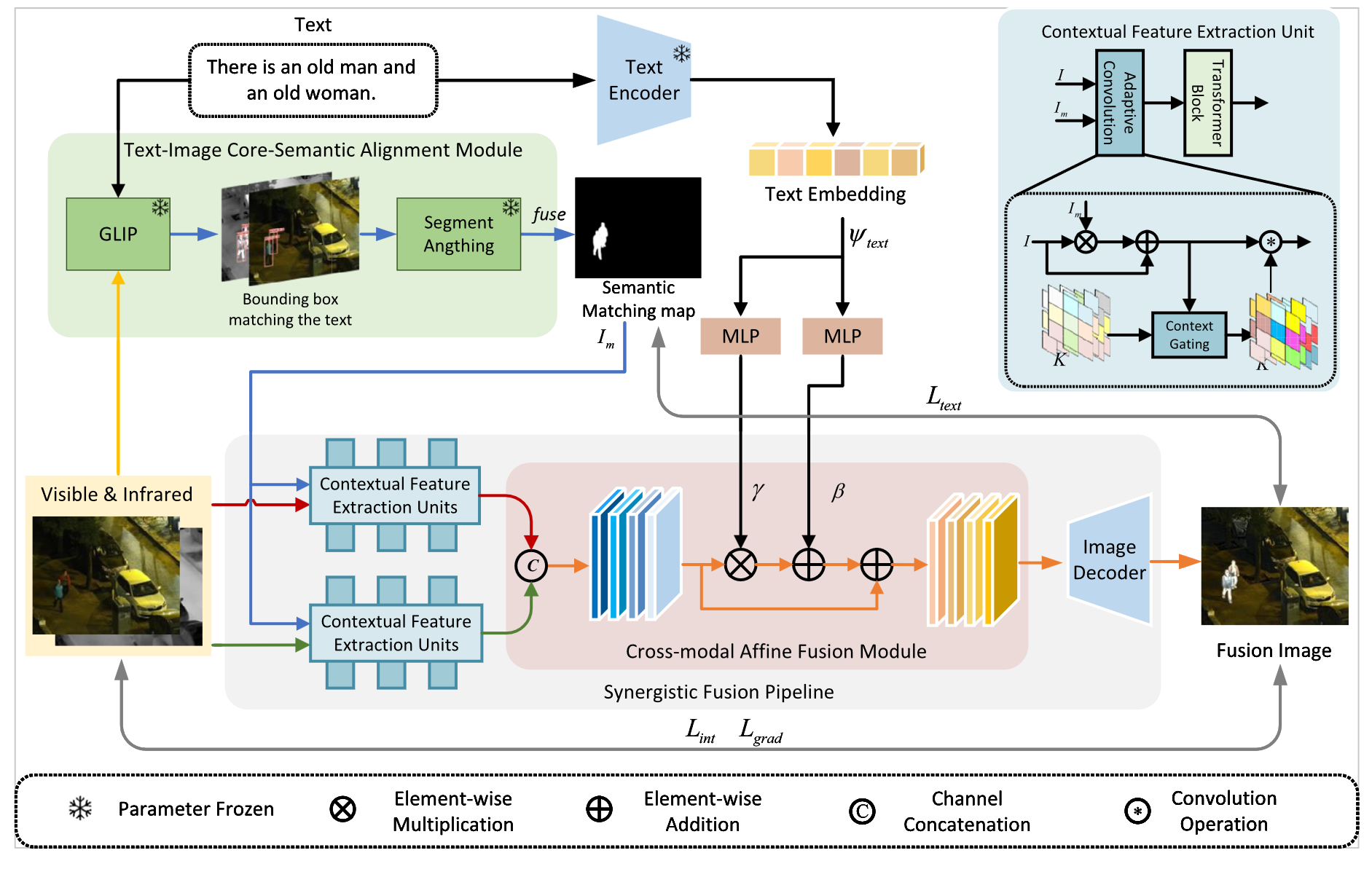
Infrared and visible image fusion based on text-image core-semantic alignment and interaction(Digital Signal Processing if=2.9 202503)
没有创新,Text+融合and语义分割+融合的大杂烩。
- 将text(重点关注的对象)输入GLIP和SAM得到掩码,将掩码加入到融合编码器中,在融合损失函数部分也使用该掩码约束;
- 使用clip对text进行编码然后经过mlp投影得到权重,将其作为权重加到融合图像上,很多text引导的融合方法都是这么做的。