摘要 :我们提出了一种面向语言模型的变分推理框架,该框架将思维轨迹视为潜在变量,并通过变分推断对其进行优化。基于证据下界(ELBO),我们将其扩展为多轨迹目标函数以实现更紧的边界约束,并提出前向KL公式化方法以稳定变分后验的训练过程。进一步研究表明,拒绝采样微调与包括GRPO在内的二元奖励强化学习均可解释为局部前向KL目标函数,其中模型准确度的隐式权重分配自然源于推导过程,并揭示了此前未被察觉的、倾向于简单问题的偏差。我们在Qwen 2.5和Qwen 3模型系列上,针对广泛推理任务进行了实证验证。总体而言,本研究提供了统一变分推断与强化学习风格方法的有原则的概率视角,并提出了稳定的目标函数以提升语言模型的推理能力。代码已开源,详见https://github.com/sail-sg/variational-reasoning。Huggingface链接:Paper page,论文链接:2509.22637
研究背景和目的
研究背景:
近年来,大型语言模型(LLMs)在数学、编程和科学问题解决等推理任务中取得了显著进展。然而,要训练出具有强大推理能力的模型,仍面临诸多挑战。
目前,监督微调(SFT)和强化学习(RL)是两种主要的训练方法。SFT方法依赖于精心策划的长思考轨迹数据,但这些数据收集成本高昂,且作为离线方法可能难以泛化。另一方面,RL方法虽然能够通过可验证的奖励来减轻奖励黑客攻击的问题,但训练过程往往不稳定,输出多样性也可能下降。
为了应对这些挑战,研究人员开始探索将概率建模与RL风格方法相结合的新途径。
变分推理(Variational Inference, VI)提供了一种自然的方式来优化正确答案的对数似然,通过引入潜在变量(即思考轨迹)来处理复杂的推理任务。然而,传统的VI方法在处理复杂推理任务时,面临着边际化计算不可行和训练不稳定等问题。
研究目的:
本研究旨在提出一种变分推理框架,用于提升语言模型的推理能力。
通过将思考轨迹视为潜在变量,并利用变分推理进行优化,本研究希望解决传统SFT和RL方法在训练推理模型时的局限性。具体目标包括:
- 提出一种新的变分推理框架:该框架将思考轨迹视为潜在变量,并通过变分推理进行优化,以提高模型生成正确答案的概率。
- 解决传统方法的局限性:通过引入多轨迹目标函数和前向KL散度,解决传统VI方法在处理复杂推理任务时的边际化计算不可行和训练不稳定问题。
- 验证框架的有效性:在多种推理任务上验证所提出框架的有效性,并展示其相对于基线方法的优势。
研究方法
1. 变分推理框架设计:
本研究提出的变分推理框架将思考轨迹视为潜在变量,并通过变分推理进行优化。
框架的核心思想是将推理过程分解为思考轨迹生成和答案生成两个步骤,并通过最大化正确答案的对数似然来优化模型参数。
2. 多轨迹目标函数:
为了解决传统VI方法在处理复杂推理任务时的边际化计算不可行问题,本研究从证据下界(ELBO)出发,将其扩展为多轨迹目标函数。多轨迹目标函数通过引入多个思考轨迹来紧化边界,从而提高优化过程的稳定性和有效性。
3. 前向KL散度优化:
为了解决训练变分后验时的稳定性问题,本研究提出了一种基于前向KL散度的优化方法。前向KL散度优化方法通过最小化真实后验与变分后验之间的KL散度,提高变分后验生成有效思考轨迹的能力。
4. 实验设置:
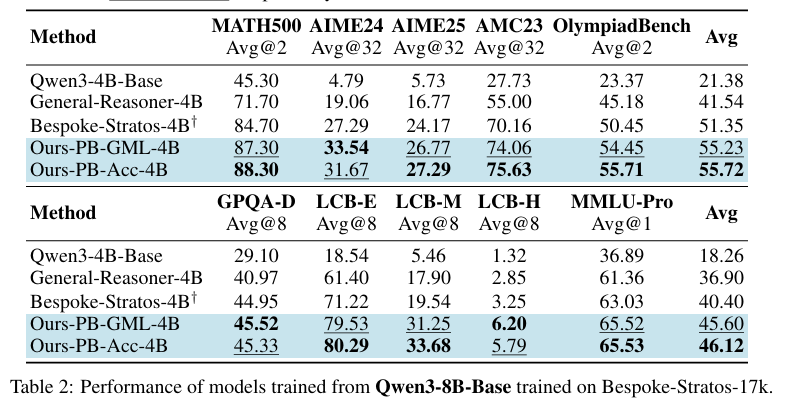
本研究在Qwen2.5和Qwen3模型家族上进行了广泛的实验验证。
实验数据集包括MATH500、AIME24&25、OlympiadBench、LiveCodeBench、GPQA-Diamond和MMLU-Pro等多种推理基准。实验过程中,本研究对比了所提出框架与多种基线方法的性能,包括Bespoke-Stratos、RLT和General-Reasoner等。
研究结果
1. 性能提升:
实验结果表明,所提出的变分推理框架在多种推理任务上显著优于基线方法。例如,在MATH500基准上,所提出框架的模型性能比基线方法提高了超过160%;在AIME24&25基准上,性能提升了超过152%。
这些结果表明,变分推理框架能够有效提升语言模型的推理能力。
2. 不同模型规模下的性能:
本研究还对比了不同模型规模下所提出框架的性能。实验结果显示,随着模型规模的增大,所提出框架的性能提升更加显著。例如,在Qwen3-8B-Base模型上,所提出框架的性能比基线方法提高了超过14%。
这表明,变分推理框架在处理复杂推理任务时具有更好的可扩展性。
3. 不同推理基准上的性能:
除了整体性能提升外,所提出框架在不同推理基准上也表现出色。例如,在LiveCodeBench基准上,所提出框架的模型在Hard子集上的性能比基线方法提高了超过20%。这表明,变分推理框架在处理具有挑战性的推理任务时具有显著优势。
研究局限
1. 数据集依赖性:
尽管所提出的变分推理框架在多种推理基准上表现出色,但其性能仍高度依赖于训练数据集的质量和多样性。
如果训练数据集存在偏差或覆盖不足,可能会导致模型在特定任务上的性能下降。
2. 模型架构限制:
当前研究主要基于Qwen2.5和Qwen3模型家族进行实验验证。
虽然这些模型在推理任务中表现出色,但所提出框架在其他模型架构上的适用性仍需进一步验证。
3. 计算资源需求:
变分推理框架在训练过程中需要生成多个思考轨迹,并进行复杂的计算和优化。这可能导致训练过程对计算资源的需求较高,限制了其在资源有限环境下的应用。
未来研究方向
1. 扩展数据集和任务类型:
未来的研究可以进一步扩展训练数据集的类型和规模,以涵盖更多领域的推理任务。
通过增加数据集的多样性和复杂性,可以进一步提高模型的泛化能力和推理性能。
2. 优化模型架构和训练方法:
未来的研究可以探索更先进的模型架构和训练方法,以提高变分推理框架的性能和效率。
例如,可以引入更高效的注意力机制、更复杂的变分后验分布等,以进一步提升模型的推理能力。
3. 降低计算资源需求:
针对变分推理框架对计算资源需求较高的问题,未来的研究可以探索降低计算资源需求的方法。
例如,可以通过模型压缩、量化等技术减少模型参数量和计算量;或者通过优化算法和并行计算等技术提高训练效率。
4. 集成到实际应用中:
最终,未来的研究可以将变分推理框架集成到实际应用中,如智能问答系统、自动化代码生成等领域。
通过在实际场景中验证框架的有效性和实用性,可以进一步推动其在自然语言处理领域的应用和发展。