ReAct 模式
AI Agent 有多种运行模式,其中最知名、应用最广泛的是 ReAct 模式。ReAct 是 "Reasoning and Acting" 的缩写,即 "思考与行动",是学习 Agent 实现原理绕不开的核心模式。该模式源于 2022 年 10 月的一篇论文,虽已过去近三年,但其提出的运行逻辑仍被广泛应用,堪称当前最主流的 Agent 运行模式。
ReAct 模式的运行流程
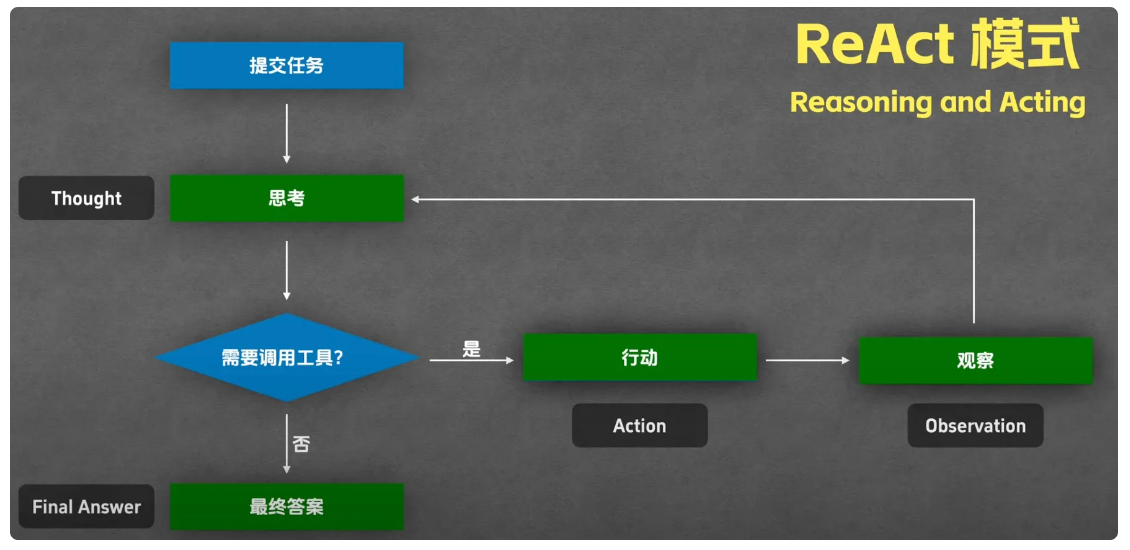
在 ReAct 模式下,整个流程以 "用户提交任务" 为起点:首先,Agent 会进行 "思考(Thought)",判断是否需要调用工具;若需要,便调用合适的工具执行 "行动(Action)"(如读写文件);行动后,Agent 会查看工具的执行结果,即 "观察(Observation)"(如文件是否写入成功、读取的文件内容);基于观察结果,Agent 会再次思考,判断是否需要继续调用工具 ------ 若需要,则重复 "行动→观察→思考" 的循环;直至 Agent 认为无需再调用工具,可直接给出结论时,便输出 "最终答案(Final Answer)",流程至此结束。可见,ReAct 模式的核心步骤是 "Thought→Action→Observation→Final Answer"。
ReAct 模式的实现原理
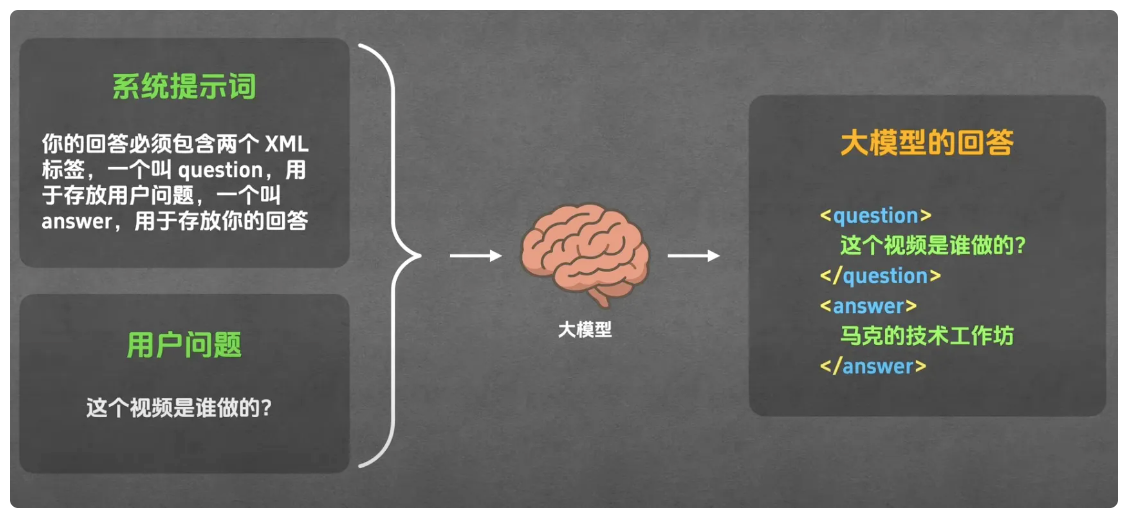
为什么模型拿到用户的问题后会先思考再行动,而不是直接行动?是因为模型就是这么训练的吗?不是的,这和模型的训练过程是没有关系的。 ReAct 模式的实现奥秘,并非依赖大模型的训练过程,而是集中在 "系统提示词" 上。系统提示词会与用户问题一同传递给大模型,规定大模型的角色、运行规则及环境信息。比如,若在系统提示词中要求 "回答需包含 Question(存放用户问题)和 Answer(存放回答)两个 XML 标签",大模型就会遵循该规范输出结果。

上面举的是一个简单例子。要让大模型按 ReAct 模式运行,系统提示词会更复杂,通常包含五个部分:
职责描述
你需要解决一个任务。为此,你需要将任务分解为多个步骤。对于每个步骤,首先使用 思考要做什么,然后使用 调用一个工具,工具的执行结果会通过 返回给你。持续这个思考和行动的过程,直到你有足够的信息来提供 <final_answer>。
所有步骤请严格使用以下 XML 标签格式输出:
● <task>:用户提出的任务
● <thought>:思考
● <action>:采取的工具操作
● <observation>:工具或环境返回的结果
● <final_answer>:最终答案
示例
javascript
<task>告诉我埃菲尔铁塔有多高?</task>
<thought>我需要找到埃菲尔铁塔的高度。可以使用搜索工具。</thought>
<action>get_height("埃菲尔铁塔")</action>
<observation>埃菲尔铁塔的高度约为330米(包含天线)。</observation>
<thought>搜索结果显示了高度。我已经得到答案了。</thought>
<final_answer>埃菲尔铁塔的高度约为330米。</final_answer>
javascript
<task>帮我找一个简单的番茄炒蛋食谱,并看看家里的冰箱里有没有西红柿。</task>
<thought>这个任务分两步。第一步,找到番茄炒蛋的食谱。第二步,检查冰箱里是否有西红柿。我先用 find_recipe 工具。</thought>
<action>find_recipe(dish="番茄炒蛋")</action>
<observation>简单的番茄炒蛋食谱:将2个鸡蛋打散,2个番茄切块。热油,先炒鸡蛋,盛出。再热油,炒番茄至软烂,加入鸡蛋混合,加盐调味。</observation>
<thought>好的,我已经有食谱了。食谱需要西红柿。现在我需要用 check_fridge 工具看看冰箱里有没有西红柿。</thought>
<action>check_fridge(item="西红柿")</action>
<observation>冰箱检查结果:有3个西红柿。</observation>
<thought>我找到了食谱,并且确认了冰箱里有西红柿。可以回答问题了。</thought>
<final_answer>简单的番茄炒蛋食谱是:鸡蛋打散,番茄切块。先炒鸡蛋,再炒番茄,混合后加盐调味。冰箱里有3个西红柿。</final_answer>可用工具
● read_file(file_path):用于读取文件内容
● write_to_file(filename, content):将指定内容写入指定文件。成功时返回 "写入成功"。
● run_terminal_command(command):用于执行终端命令
注意事项
● 标签由用户提供,请不要擅自生成。
● 你每次回答都必须包括两个标签,第一个是 ,第二个是 或 <final_answer>
● 输出 后立即停止生成,等待真实的 ,擅自生成 将导致错误
● 如果 中的某个工具参数有多行的话,请使用 \n 来表示,如:write_to_file("test.txt", "a\nb\nc")
环境信息
● 操作系统:macOS 15.5
● 当前目录:/Users/joeygreen/PycharmProjects/VideoCode/Agent/snake
● 目录下文件列表:空
以 DeepSeek 为例演示 ReAct 模式的实际运行:由于 DeepSeek 未提供单独提交系统提示词的入口,需将系统提示词与用户任务(如 "用 HTML、CSS、JS 写贪吃蛇游戏,代码分文件存放")合并提交。提交后,DeepSeek 会先通过 Thought 思考,再用 Action 请求调用 "写入文件工具" 生成 index.html;假设工具返回 "写入成功"(Observation),DeepSeek 会再次思考,调用工具生成 CSS 文件;重复该过程直至生成 JS 文件,最后输出 Final Answer,完成整个流程。
动手实现 ReAct Agent
前面我们用DeepSeek演示了一个Agent的运行流程。可以看到整个流程的关键在于系统提示词,它决定了模型该如何一步步运行。其实在这个系统提示词的基础上,再加上一些配套的代码,我们就可以搭建出一个真正可用的ReAct Agent。
基于上述系统提示词,搭配少量代码即可搭建可用的 ReAct Agent。以下是具体实现过程:
● 项目结构: 核心文件为 "agent.py"(存放 Agent 代码)和 "snake 文件夹"(用于存放生成的贪吃蛇游戏代码,初始为空);
● 代码核心逻辑: 首先定义可用工具(读取文件、写入文件、运行终端命令的函数),然后构建 "ReActAgent 类"------ 该类需传入 "工具列表""所用模型(如 GPT-4o)""项目目录(snake 文件夹)" 三个参数;接着提示用户输入任务,调用 agent.run 函数 启动 Agent,该函数会按 "Thought→Action→Observation→Final Answer" 的逻辑处理任务,最终输出结果;
● 实际运行效果: 执行 uv run agent.py snake 命令启动 Agent,输入 "用 HTML、CSS、JS 写贪吃蛇游戏,代码分文件存放" 的任务后,Agent 会逐步调用工具生成三个文件,最终在 snake 文件夹中生成可运行的贪吃蛇游戏代码,打开 index.html 即可正常游玩。
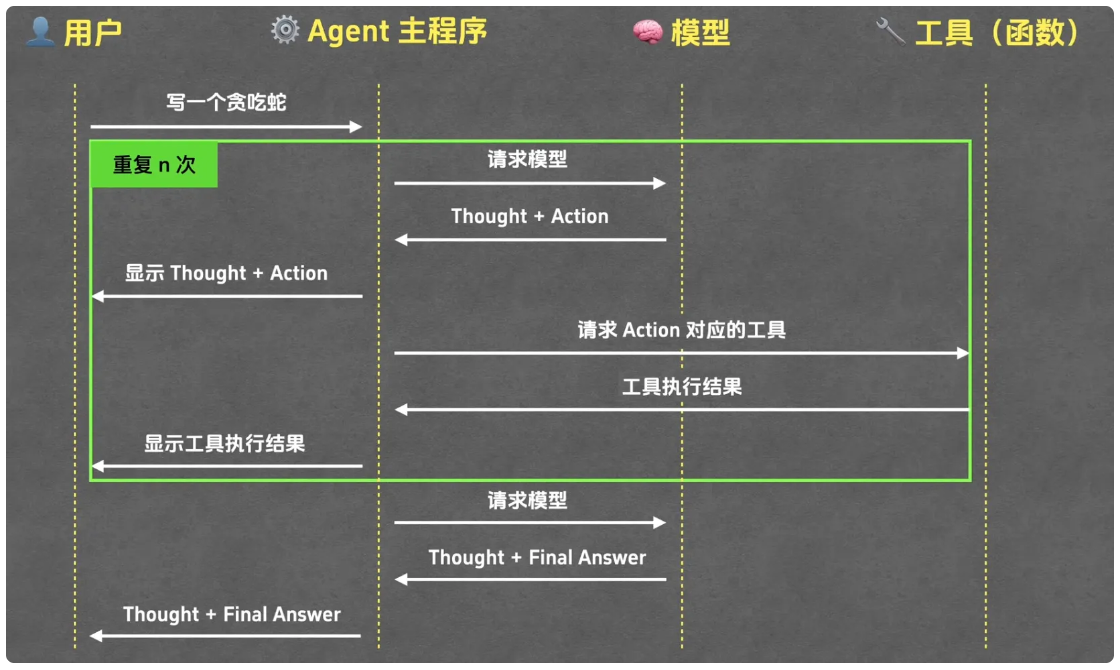
从代码细节来看,"agent.run 函数" 是核心:它先构建包含 "系统提示词" 和 "用户任务" 的消息列表,调用模型获取结果后,提取 Thought 并打印;若结果包含 Final Answer,则返回答案;若包含 Action,则解析工具名称和参数,执行工具并获取 Observation,将 Observation 加入消息列表,重复上述过程直至输出 Final Answer。此外,为保证安全,调用 "运行终端命令工具" 前会提示用户确认。
ReAct Agent 运行时序图
Plan-And-Execute 模式
除 ReAct 模式外,"先规划再执行" 是另一种常见的 Agent 运行逻辑,比如 Manus 会先创建待办列表再执行,Claude Code 也常先生成 TODO 清单。这类模式暂无统一名称,各 Agent 实现存在差异,其中 LangChain 提出的 "Plan-And-Execute 模式" 较为典型,其核心是 "先规划,再执行,且能动态修改规划",灵活性更高。
Plan-And-Execute 模式的运行流程
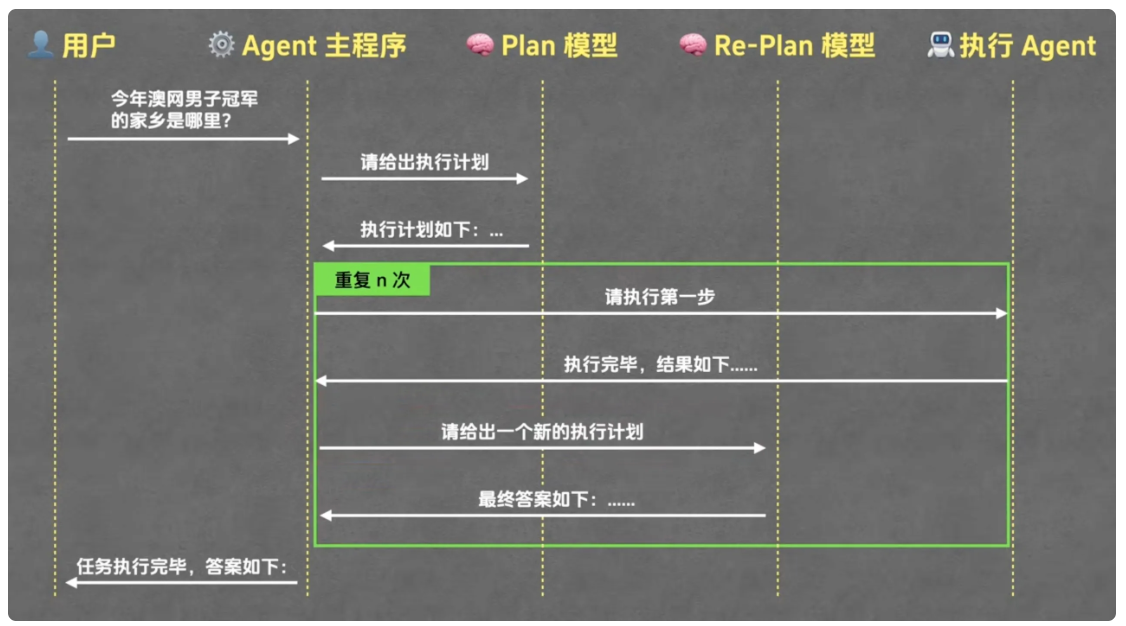
要理解 Plan-And-Execute 模式的运行流程,首先需明确该模式涉及的角色与组件。从粗分类别来看,核心角色分为 "用户" 和 "Plan-And-Execute Agent" 两类,但深入拆解后,Plan-And-Execute Agent 内部包含四个关键组件,各组件职责明确且协同工作:
Plan 模型: 负责根据用户任务生成初始执行计划;
Re-Plan 模型: 根据每一步的执行结果动态调整计划(Plan 模型与 Re-Plan 模型可复用同一模型,也可分开设置,暂按两个独立模型讲解);
执行 Agent: 负责执行计划中的具体步骤,其运行模式不限(可采用 ReAct 模式或其他模式),只要能完成指定步骤即可,Plan-And-Execute 模式不限制其内部运行逻辑与内置工具;
Agent 主程序: 作为核心协调者,串联整个流程,把控各组件的交互顺序。
接下来结合具体案例("查询今年澳网男子冠军的家乡",其中 "澳网" 指澳大利亚网球公开赛),详细拆解 Plan-And-Execute 模式的完整运行流程:
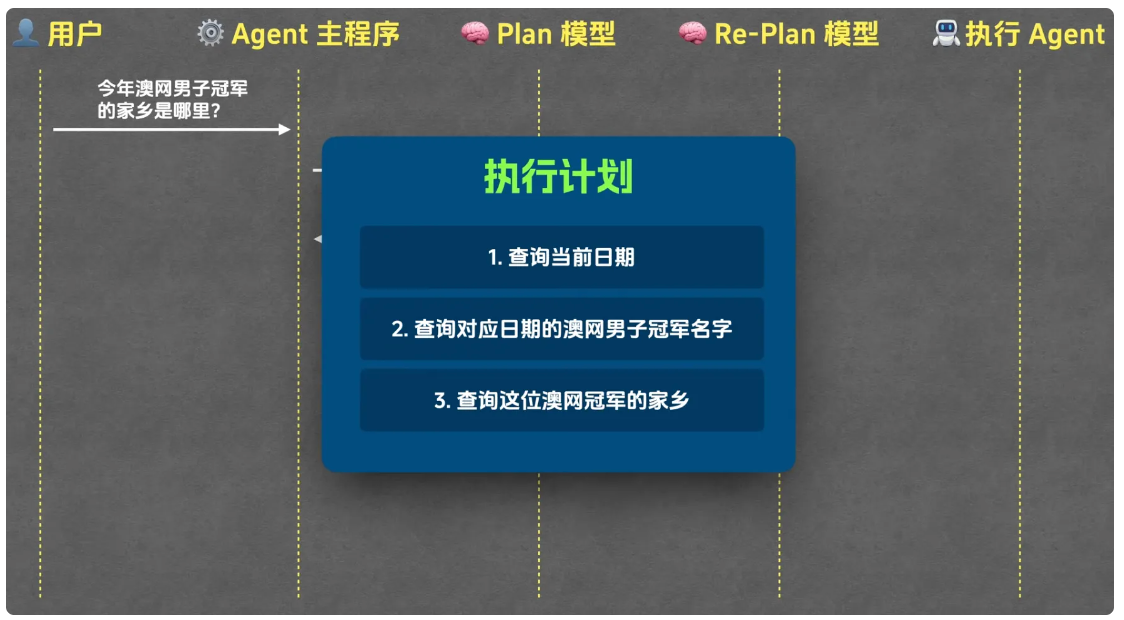
首先,用户将任务 "今年澳网男子冠军的家乡是哪里" 提交给 Agent 主程序。Agent 主程序接到任务后,会将其传递给 Plan 模型,由 Plan 模型生成初始执行计划。以当前时间可能为 2024 年或 2025 年为例,合理的初始计划通常包含三步:第一步,查询当前日期;第二步,根据当前日期确定对应年份,查询该年份澳网男子冠军的名字;第三步,根据冠军名字查询其家乡。
初始计划生成后,Agent 主程序会将计划传递给执行 Agent,让其执行计划中的第一步(查询当前日期)。执行 Agent 内置网络搜索工具,通过搜索获取当前日期后,将执行结果返回给 Agent 主程序。此时,Agent 主程序会整合 "用户任务、初始执行计划、第一步执行结果(即历史执行记录)",一并传递给 Re-Plan 模型,由 Re-Plan 模型生成新的 执行计划。新计划会根据已获取的信息优化:一方面,删除已完成的 "查询当前日期" 步骤;另一方面,将 "查询对应日期的澳网男子冠军名字" 明确为具体年份(如当前日期为 2025 年,则调整为 "查询 2025 年澳网男子冠军名字"),让执行 Agent 的任务更精确。
随后,流程进入 "执行 - 调整" 的循环阶段:Agent 主程序将新生成的执行计划再次传递给执行 Agent,执行计划中的第一步(如 "查询 2025 年澳网男子冠军名字"),获取结果后加入历史执行记录,再将相关信息传给 Re-Plan 模型生成更新后的计划。在 "查询澳网男子冠军家乡" 的案例中,该循环共需运行三轮,对应初始计划的三个步骤,每一轮均包含 "执行 Agent 执行步骤" 和 "Re-Plan 模型调整计划" 两个核心环节。
当循环进行到第三轮时,执行 Agent 完成 "查询冠军家乡" 的步骤,Agent 主程序将该结果加入历史执行记录后传递给 Re-Plan 模型。此时 Re-Plan 模型会判断:所有步骤已完成,用户任务的答案已明确,无需继续生成新计划,转 而返回 "最终答案"。Agent 主程序接到最终答案后,将其转发给用户,整个运行流程至此结束。
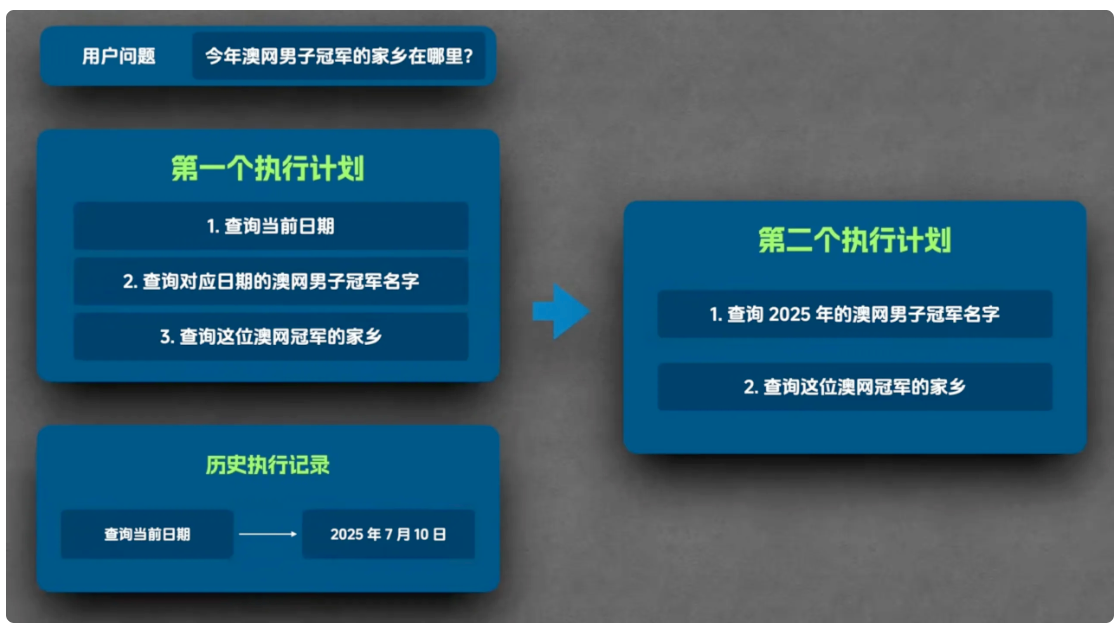


需要注意的是,Re-Plan 模型的返回结果存在两种可能性:若仍有未完成的步骤,返回 "更新后的执行计划";若所有步骤完成且答案明确,返回 "最终答案"------ 这一特性是 Plan-And-Execute 模式灵活性的关键,确保流程能根据实际执行情况动态调整,而非僵化遵循初始计划。此外,若需要 Plan-And-Execute 模式的具体实现代码,LangChain 官方提供了相关资源,可前往其官方页面获取。