语言模型与视觉语言模型及动作模型三大模型的定义、关系、区别
1.语言模型LLM
· 定义:在超大规模文本数据上训练,以理解和生成自然语言为核心目标的模型。
· 本质: "文本专家"。它将世界知识、逻辑和任务抽象为符号(语言)进行处理。
· 输入/输出: 文本 ------文本。
· 例子: GPT-4(纯文本版)、Llama、Claude。
2.视觉语言模型VLM
· 定义:在图像-文本对数据上训练,能够同时理解视觉内容和语言,并在两者间建立联系的模型。
· 本质: "视觉翻译官"或"视觉理解者"。它能描述图像、回答关于图片的问题、根据文字指令理解图片的特定部分。
· 输入/输出: (图像 + 文本)------文本。
· 例子: GPT-4V、Gemini(原生多模态)、LLaVA。
3. 动作模型VLA
· 定义:以第一视角视觉观测为主要输入,直接输出物理空间中的控制动作的模型。
· 本质: "物理世界执行者"。它的目标不是描述世界,而是改变世界,实现从感知到动作的闭环。
· 输入/输出: (图像/视频 + 可能的文本指令)------ 动作。
· 例子: RT-1、RT-2、Open X-Embodiment系列模型。
三者关系:
- LLM是基础层:它提供了强大的语义理解、知识存储、逻辑推理和任务规划能力。它是智能的"大脑"和"通用任务处理器"。
- VLM是连接与感知层:它在LLM的基础上,增加了视觉理解这个关键维度。VLM就像是给LLM这个"盲人智者"安装了一双"眼睛",让它能"看懂"物理世界,并用语言描述出来。没有强大的LLM作为基础,VLM的语义理解能力会大打折扣。
- VLA是具身执行层:它专注于在物理世界中落地行动。VLA将VLM的视觉理解和LLM的任务规划,最终转化为驱动电机、关节的具体动作序列,完成"手眼协调"。
总结与趋势
· LLM 是 智能的基石,定义了如何理解和处理抽象任务。
· VLM 是 智能的感官,将物理世界的感知接入抽象思维。
· VLA 是 智能的肢体,将思维和感知转化为物理世界的改变。
当前的大趋势是三者深度融合,通向"具身智能":
- VLM作为通用视觉接口:让LLM能"看到"世界,为规划提供依据。
- LLM作为高级规划器:将复杂指令分解为VLA可执行的步骤序列。
- VLA作为技能执行器:利用从海量交互数据中学到的"肌肉记忆",可靠地完成底层动作。
最新的VLA模型(如RT-2)已经将三者技术路线融合:它将动作本身作为一种"语言"token,与视觉、文本token放在一起训练,从而让模型同时具备了VLM的视觉语言能力和VLA的输出动作能力,实现了知识(来自LLM/VLM)向技能(VLA)的直接迁移。这正是通往通用具身智能体的关键一步。关注创鹤智能,探索Ai更多可能!
ViT与LLAVA关系
ViT(Vision Transformer)与LLaVA(Large Language and Vision Assistant)是多模态大模型中的两个关键组件,它们的关系是基础架构与具体实现的关系。ViT是视觉编码的核心技术,而LLaVA是基于ViT等组件构建的完整多模态模型系统。
ViT的核心作用
ViT是一种将图像处理为序列化数据的神经网络架构,其核心思想是将图像分割成固定大小的"图像块"(Patches),然后通过Transformer编码器学习这些块之间的关系,从而生成图像的视觉特征表示。
- 功能定位:在LLaVA等多模态模型中,ViT充当"视觉感知器",负责将输入的图像转换为模型可理解的数值向量(视觉token)。
- 技术特点:ViT摒弃了传统CNN的局部卷积设计,直接利用Transformer的自注意力机制捕捉图像全局信息,这使其与处理文本的LLM(大语言模型)在结构上具有天然的兼容性。
LLaVA对ViT的集成与应用
LLaVA是一种多模态大模型,其设计目标是让语言模型具备理解图像的能力。它通过一个简单的"投影器"(Projector)将ViT输出的视觉特征与文本指令对齐,从而实现视觉-语言联合理解。
- 结构集成:LLaVA的架构非常简洁,主要由三部分组成:ViT视觉编码器、一个轻量级的投影层(如MLP)和一个预训练的LLM(如Vicuna、Llama2)。其中,ViT是视觉信息提取的基石。
- 工作流程:当输入一张图片和文本指令时,LLaVA首先使用ViT对图像进行编码,生成视觉token序列;然后通过投影器将这些token的维度与LLM的文本token对齐;最后,将对齐后的视觉token与文本prompt拼接,输入LLM进行联合推理。
- 演进优化:LLaVA系列后续版本(如LLaVA-1.5、LLaVA-NeXT)持续优化ViT的使用,例如采用AnyRes方法支持更大输入尺寸(如672x672),或更换更强大的ViT基座(如SigLIP),以提升视觉理解能力。
综上所述,ViT是LLaVA实现视觉感知的核心技术组件,而LLaVA则是ViT在多模态指令微调场景下的一个成功应用范例。没有ViT,LLaVA就无法"看懂"图像;而没有LLaVA的框架,ViT的视觉特征也难以与语言模型有效协同。
MOE-LLAVA与LLAVA关系
MoE-LLaVA 与 LLaVA 是两种不同的视觉语言模型(VLM),它们在架构和设计理念上存在显著差异,但 MoE-LLaVA 的性能目标是与 LLaVA 系列模型相媲美甚至超越。
-
LLaVA:是一个稠密的视觉语言模型,其核心架构基于大型语言模型(LLM),通过将视觉编码器提取的图像特征投影到语言模型的嵌入空间,实现图文理解。LLaVA-1.5 系列是该方向的代表性模型,参数规模从 7B 到 13B 不等。在推理时,LLaVA 需要激活模型中的所有参数来处理每个输入,这导致了较高的计算和内存成本。
-
MoE-LLaVA:是基于 LLaVA 架构发展而来的稀疏化版本,其核心创新在于引入了混合专家(Mixture of Experts, MoE) 架构。它并非 LLaVA 的简单升级,而是一种全新的设计:
- 核心机制:MoE-LLaVA 将模型中的前馈神经网络(FFN)层复制为多个"专家"(experts),并引入一个"路由器"(router)。对于每个输入的 token(文本或图像块),路由器会动态计算其与各个专家的匹配度,并仅激活 top-k 个最匹配的专家进行计算,其余专家保持非活动状态。
- 性能目标:通过这种稀疏激活机制,MoE-LLaVA 旨在以远低于稠密模型的计算成本,达到相当的性能。例如,MoE-LLaVA-2.7B×4 模型在多个视觉理解基准上表现与 LLaVA-1.5-7B 相当,甚至在物体幻觉基准测试中超越了 LLaVA-1.5-13B,而其激活的参数量仅为约 3.6B。
- 训练策略:MoE-LLaVA 采用三阶段训练,其中第二阶段使用 LLaVA 的权重作为初始化,以降低稀疏化训练的难度,这表明它在训练初期借鉴了 LLaVA 的能力。
总结来说,MoE-LLaVA 与 LLaVA 的关系可以理解为:
- 继承与发展:MoE-LLaVA 继承了 LLaVA 的基础架构理念(即视觉编码器+语言模型的融合),并在此基础上引入了 MoE 稀疏化技术进行创新。
- 性能对标:MoE-LLaVA 的设计目标是成为 LLaVA 系列模型的高效替代品,用更少的激活参数实现同等或更优的性能。
- 架构本质:LLaVA 是稠密模型(所有参数均被激活),而 MoE-LLaVA 是稀疏模型(仅激活部分专家),这是两者最根本的区别。
LLaVA
LLaVA(Large Language and Vision Assistant),全称为大型语言和视觉助手,是一种端到端训练的大型多模态模型。该模型将视觉编码器(如CLIP)与大型语言模型(如LLaMA或Vicuna)连接起来,实现了对视觉和语言指令的深入理解与执行。LLaVA的目标是为用户提供一种通用助手,能够基于视觉和语言输入完成各种现实世界的任务。其核心思想是,将一个预训练的视觉编码器(如CLIP的ViT)和一个预训练的大语言模型(如Vicuna或LLaMA)通过一个简单的投影层连接起来,从而"教会"LLM理解图像。
你可以把它想象成给一个盲人(LLM)配了一个能描述世界的"电子眼"(视觉编码器),并通过一个"翻译官"(投影层)将看到的信息转换成盲人能理解的语言。
LLaVA的结构可以分为三个主要部分,其框架如下图所示:
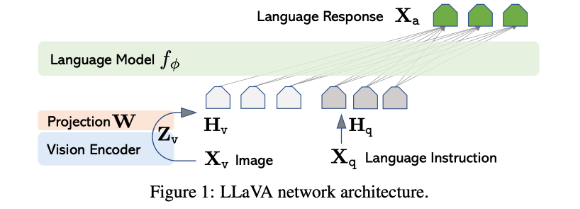
1. 视觉编码器
- 作用: 负责提取输入图像的视觉特征。常用的视觉编码器有CLIP的ViT-L/14模型,它能够将图像编码为一系列视觉特征向量。将输入图像从像素空间转换到一个高维的、具有语义信息的特征空间。简单来说,就是将图片变成计算机能理解的"数字向量"。
- 具体实现: LLaVA通常使用CLIP模型的视觉编码器部分(Visual Encoder),其本身是一个ViT(Vision Transformer)。
- 处理过程: 一张图片会被分割成多个图像块(Patches),然后送入ViT。ViT的输出是一个由特征向量组成的网格(例如 14x14 = 196个特征向量),每个向量都包含了图像局部和全局的信息。这些特征通常被称为视觉令牌。
2. 投影层(跨模态连接器)
- 作用: 负责将视觉编码器的输出与语言模型的输入进行对齐和融合。LLaVA使用了一个简单的线性层作为跨模态连接器,将视觉特征映射到语言模型的词嵌入空间中。这是LLaVA最巧妙也最关键的部分。视觉编码器输出的特征空间和LLM所理解的语言特征空间是完全不同的。投影层的作用就是将视觉特征"对齐"或"映射"到语言模型的特征空间中,让LLM能够"读懂"这些视觉信息。
- 具体实现: 在LLaVA v1中,这个投影层通常是一个简单的线性层(全连接层) 或一个小型的多层感知机。
- 处理过程: 视觉编码器输出的196个视觉令牌会分别通过这个投影层,被转换成196个与文本令牌维度相同的特征向量。此时,这些向量可以被视为**"伪语言令牌"**。它们本身不是文字,但LLM会像处理文字一样处理它们。
3. 大语言模型
- 作用: 作为模型的大脑,负责理解和推理。它接收由文本指令和投影后的视觉令牌组成的完整序列,并生成人类可读的文本回答。
- 具体实现: 早期版本使用Vicuna(一个基于LLaMA微调的对话模型),后续版本也支持其他LLaMA架构的模型。
- 处理过程:
- 令牌化: 用户的文本指令(例如"请描述这张图片")被LLM的令牌化器转换成一系列文本令牌。
- 序列拼接: 投影层输出的"伪语言令牌"(视觉特征)和文本令牌被拼接成一个长的序列。这个序列的结构通常是:<视觉令牌1> <视觉令牌2> ... <视觉令牌N> <文本令牌1> <文本令牌2> ...。
- 推理生成: 这个完整的序列被送入LLM。LLM基于其强大的上下文理解能力,将视觉令牌和文本令牌结合起来进行推理,并以自回归的方式(根据上文生成下一个词)产生流畅、准确的回答。
训练过程(两阶段)
LLaVA的训练分为两个阶段,这是其成功的关键:
- 预对齐阶段(特征对齐):
- 目标: 只训练投影层的参数,冻结视觉编码器和LLM。
- 数据: 使用大量"图像-描述文本"对(如CC3M数据集)。
- 目的: 让投影层学会如何将视觉特征准确地映射到LLM的输入空间。训练完成后,LLM看到投影后的视觉令牌,就能大致理解图像的内容。这可以看作是"教会LLM识字(图)"。
- 端到端微调阶段(指令跟随):
- 目标: 同时微调投影层和LLM的参数(视觉编码器通常仍被冻结)。
- 数据: 使用人工精心标注的"图像-复杂指令-回答"数据。例如,不仅描述图片内容,还包括回答问题、推理、推理等。
- 目的: 让模型学会根据人类的复杂指令与多模态上下文进行交互,成为一个真正有用的"助手",而不仅仅是一个图像描述器。
指令调优
为了使LLaVA能够遵循用户的多模态指令,研究团队采用了指令调优的方法。具体来说,他们使用ChatGPT/GPT-4等模型生成了大量的多模态指令跟随数据,包括对话、详细描述和复杂推理等多种类型。然后,他们利用这些数据对LLaVA进行微调,使其能够更好地理解并执行用户的多模态指令。
数据生成
由于缺乏现成的视觉语言指令跟随数据集,研究团队采用了创新的数据生成方法。他们首先从图像文本对(如COCO数据集)开始,利用GPT-4等模型生成一系列问题来指导助手描述图像内容。通过这种方法,他们成功地将图像文本对转换为了多模态指令跟随数据。最终,他们收集了约158K个数据样本,为LLaVA的微调提供了丰富的训练资源。
LLaVA的结构精髓在于其简洁而有效的设计:
- 视觉编码器: 负责"看"图。
- 投影层: 负责"翻译"视觉信号为语言信号。
- 大语言模型: 负责"思考"和"回答"。
MOE-LLAVA
MOE-LLaVA(Mixture of Experts for Large Vision-Language Models)是一种基于混合专家(MoE)架构的大型视觉语言模型,旨在通过稀疏激活机制提升多模态理解的效率与性能。
MOE-LLaVA是2024年1月来自北大、中山大学和FarReel AI Lab等单位的论文"MoE-LLaVA: Mixture of Experts for Large Vision-Language Models"。是Llava1.5的改进,是一个多模态视觉-文本大预言模型,可以完成图像描述、视觉问答、潜在可以完成单个目标的视觉定位、名画名人等识别(问答、描述),未知似乎否能够根据图片写代码(HTML、JS、CSS)。支持单幅图片输入(可以作为第一个或第二个输入),多轮文本对话。
整体基于Llava1.5,包括训练数据,主要变化在于LLM换为了更小的几个版本,并且LLM增加了MOE模块,进行了三阶段训练(前两个阶段和Llava1.5相同,第三阶段训练MOE层)。具体结构包含:基于CLIP的视觉编码器,以及多个小语言解码器(添加MOE层),使用最简单的两层FC构成MLP映射视觉特征到文本长度。
虽然其底层架构基于LLaVA-1.5,而部分多模态模型(如GPT-4V、Gemini等)已被展示具备根据图像生成简单代码的能力,但MoE-LLaVA的公开技术细节和基准测试主要集中在视觉理解与问答领域,例如在GQA、VQAv2、POPE等数据集上的表现,目前的公开资料中并未提及代码生成任务(如CodeVQA、Image2Code等)的评估结果。
MoE-LLaVA的技术原理
混合专家(MoE)策略
MoE-LLaVA的核心在于其混合专家策略,该策略通过引入多个专家模块,每个模块专注于处理不同类型的数据或任务。与传统密集模型相比,MoE-LLaVA在任何给定时刻仅激活与当前任务最相关的专家(即top-k专家),从而显著降低了计算负载和资源消耗,提高了模型效率。
模型架构
MoE-LLaVA的模型架构主要包括以下几个部分:
- 视觉编码器:将输入图像转换为视觉表示,为后续处理提供基础。
- 多层感知机(MLP):将视觉标记投射到语言模型的域中,视为伪文本标记,实现视觉与语言数据的初步融合。
- 分层LLM块:由多头自注意机制和前馈神经网络组成,集成视觉和文本数据,进一步加深模型对多模态内容的理解。
- MoE模块:作为架构的核心,包含多个专家的前馈网络(FFN),通过路由机制动态分配任务给不同的专家。
MoE-LLaVA 架构如图所示:由视觉编码器、视觉投影层 (MLP)、字嵌入层、多个堆叠 LLM 块和 MoE 块组成。
在阶段 I 中,仅训练 MLP。在阶段 II 中,除视觉编码器 (VE) 外,所有参数均经过训练。在阶段 III 中,使用 FFN 初始化 MoE 中的专家,并且仅训练 MoE 层。对于每个 MoE 层,每个 token 仅激活两个专家,而其他专家保持沉默。
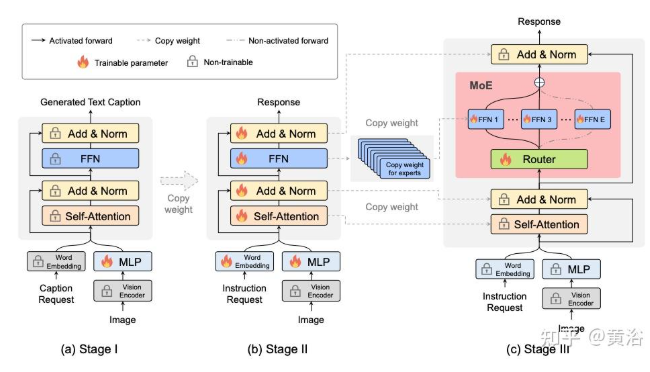
动态路由与稀疏路径
MoE-LLaVA采用动态路由机制,根据输入数据的特性,决定令牌分配给哪些专家。这种机制允许模型在处理过程中动态调整计算资源,实现高效的稀疏处理路径。同时,稀疏路径的引入进一步提高了模型的灵活性和适应性。
在MoE-LLaVA模型中,Hard Routers(硬路由器)和Soft Routers(软路由器)是两种不同的机制,用于决定如何将输入的视觉或文本token分配给多个专家(experts)进行处理。它们的核心区别在于分配方式的"硬性"或"软性"。
- Hard Routers(硬路由器):采用稀疏分配策略,即每个token被严格分配给少数(通常是top-k)最匹配的专家,其余专家保持静默。这种分配是离散的、非概率的,类似于"二选一"的决策。例如,在MoE-LLaVA中,一个token可能只被发送给前2个或前4个最匹配的专家,其他专家完全不参与该token的计算。这种方式能显著降低计算成本,但可能损失部分信息的融合。
- Soft Routers(软路由器):采用稠密分配策略,即每个token被以加权的方式分配给所有专家,权重由路由器计算得出,通常基于Softmax函数。这意味着每个专家都会参与处理每个token,只是贡献度不同。这种方式能更充分地利用所有专家的知识,但计算开销更大,因为所有专家都需要被激活。
在MoE-LLaVA的研究中,采用的是Hard Router(具体为Token Choice类型),通过稀疏激活实现高效计算。研究指出,在固定计算预算下,Soft MoE(软路由器)通常性能优于Sparse MoE(硬路由器),但MoE-LLaVA通过精巧的架构设计(如专家选择机制和三阶段训练策略),在使用硬路由器的情况下,仍能以更少的激活参数达到与稠密模型相当甚至更优的性能。
微调一个 MoE-LLaVA 模型
微调一个 MoE-LLaVA 模型,通常指的是采用专家混合(Mixture-of-Experts, MoE)与低秩自适应(Low-Rank Adaptation, LoRA)相结合的高效微调方法,如 LLaVA-MoLE(LLaVA with Mixture of LoRA Experts)。这种方法旨在解决多任务指令数据混合训练时的数据冲突问题,同时保持训练和推理成本接近原始 LoRA。
核心微调框架:LLaVA-MoLE
LLaVA-MoLE 是在 LLaVA-1.5 基础模型上进行的指令微调,其核心创新在于将 MoE 技术引入 LoRA 模块,为每个 Transformer 层的 FFN(前馈网络)部分创建一组稀疏激活的 LoRA 专家,并通过一个路由器(router)为每个输入 token 动态选择最合适的专家。
-
模型架构基础:
- 视觉编码器:使用 CLIP ViT 处理输入图像。
- 视觉投影器:通过一个两层 MLP 将视觉特征投影到语言模型的嵌入空间。
- 语言模型(LLM):基于 LLaVA-1.5 的 LLM 部分,其每一层的 FFN 模块被改造为 MoE-LoRA 结构。
- MoE-LoRA 模块:这是核心。在每个 FFN 层,不是添加一对固定的低秩矩阵(如标准 LoRA),而是添加一组(例如 K=4 或 8 个)LoRA 专家。每个专家都是一对独立的低秩矩阵,拥有自己的可训练参数。
- 路由器:一个轻量级的神经网络,接收当前 token 的表示作为输入,输出一个概率分布,指示该 token 应该激活哪个 LoRA 专家。通常采用Top-1 路由,即每个 token 只激活概率最高的那个专家。
-
微调过程:
- 数据准备:收集混合的多任务指令数据集,例如通用对话数据、文档理解数据和生物医学数据(如 PathVQA)。关键优势在于可以为不同数据集设置不同的采样频率(如 λG, λD, λM),以平衡任务间的冲突并侧重于特定领域。
- 参数训练:仅训练以下部分:
- 所有 LoRA 专家的低秩矩阵参数。
- 路由器的参数。
- (可选)视觉投影器的参数。
- 注意:预训练的 LLaVA-1.5 模型参数(包括原始的 FFN 权重和自注意力机制)在微调过程中保持冻结,这是参数高效的关键。
- 负载均衡:为防止某些专家被过度激活而其他专家闲置,训练时会引入一个负载均衡损失(Load Balancing Loss)。该损失鼓励路由器将 tokens 均匀地分配给所有专家,避免资源浪费。
- 训练配置:实验表明,使用 64 个 NVIDIA A100 80GB GPU 在三个数据集混合上训练一个 LLaVA-MoLE 模型大约需要 16 小时。通常采用 AdamW 优化器并配合学习率预热。
-
推理阶段:
- 推理过程与训练类似。对于每个输入的 token,路由器会根据其表示计算出一个专家选择概率,并仅激活概率最高的那个 LoRA 专家进行计算。
- 由于每个 token 只激活一个专家,且 LoRA 本身参数量小,因此推理的计算量和内存开销与标准 LoRA 基本持平,不会显著增加
总结优势
- 解决数据冲突:通过为不同领域的知识分配不同的 LoRA 专家,有效缓解了混合训练时不同任务数据间的干扰。
- 参数高效:仅微调少量 LoRA 参数和路由器参数,大幅降低计算和存储成本。
- 成本可控:稀疏激活机制确保了训练和推理成本与标准 LoRA 相当。
- 灵活扩展:可以轻松通过增加专家数量或调整数据采样比例来适应新的任务领域。
总而言之,微调 MoE-LLaVA 模型(如 LLaVA-MoLE)的核心是在冻结预训练模型的前提下,为 FFN 层引入一组可学习的 LoRA 专家和一个动态路由器,并通过混合数据集进行端到端训练。
模型量化技术
模型量化技术是一种通过降低深度学习模型中参数(如权重和激活值)的数值精度,来压缩模型体积、降低计算开销并提升推理速度的技术。其核心思想是用低比特宽度的数据类型(如INT8、INT4或FP8)替代原本的高精度浮点数(如FP32或FP16),从而在可接受的精度损失范围内,显著优化模型的运行效率。
核心作用与优势
- 减小模型体积:例如,将Llama2 7B模型从FP16(每个参数占2字节)量化至FP8后,模型权重所需显存可从约14GB降至约7GB,节省一半内存空间。
- 加速推理速度:低精度数据类型能更高效地利用硬件(如NVIDIA Tensor Core),提升计算吞吐量,缩短响应时间。
- 降低能耗:在移动端或边缘设备上运行时,量化能减少功耗,延长电池寿命。
- 实现资源受限部署:使原本需高端GPU运行的大模型(如生成式AI)能在手机、嵌入式设备等资源受限环境中部署。
关键量化对象
在基于Transformer的模型中,主要可对以下三部分进行量化:
- 模型权重:模型训练后存储的参数,是量化的主要对象。
- 模型激活值:推理过程中各层产生的中间输出,具有动态性,量化需结合校准数据。
- KV缓存:解码器模型在自回归生成时缓存的键(Key)和值(Value)状态,量化可进一步减少显存占用。
主要量化方法
- 训练后量化(Post-Training Quantization, PTQ)
不重新训练模型,直接对已训练好的模型进行量化。常用方法包括:- 校准法(Calibration):使用少量真实数据统计参数分布,确定缩放因子和零点,以最小化精度损失。
- GPTQ:专为大语言模型设计的训练后量化算法,通过逐列量化权重并最小化输出误差,实现高精度压缩。
- 量化感知训练(Quantization-Aware Training, QAT)
在训练过程中模拟量化过程,使模型适应低精度表示,通常能获得比PTQ更高的精度,但训练成本更高。
如何基于modelslim做大模型量化
ModeSlim 是昇腾提供的模型量化压缩工具。它可以对深度学习模型进行轻量化处理,核心目标是在保证模型性能(如精度)基本不受显著影响的前提下,减小模型体积、降低计算复杂度,从而提升模型的部署效率和运行速度,尤其适用于资源受限的场景。
基于 msmodelslim 对大模型进行量化,主要采用训练后量化(PTQ)的方式,以 W8A8(权重8位、激活8位)为典型方案,可在昇腾NPU等硬件上显著降低模型显存占用并提升推理速度。以下是基于公开资料整理的完整流程和关键要点:
-
环境准备与依赖安装
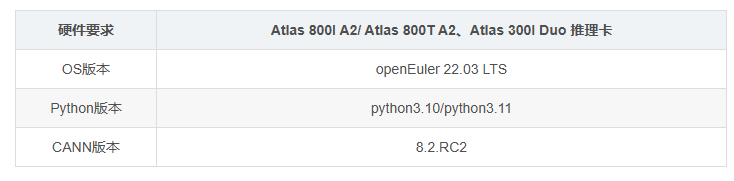
- 确保运行环境为昇腾NPU(如Atlas系列加速卡),并已安装配套的昇腾AI软件栈(如CANN)。
- 克隆 msmodelslim 仓库,该仓库由华为提供,专门用于大模型量化。可从其官方代码库获取,例如在 Ascend/msit 仓库的特定分支下找到相关示例代码。
- 安装必要的Python依赖,如 transformers, torch, tqdm 等。
基础配套镜像:https://www.hiascend.com/developer/ascendhub/detail/af85b724a7e5469ebd7ea13c3439d48f
-
加载原始模型与配置
- 使用 transformers 库的 AutoModelForCausalLM 和 AutoTokenizer 加载预训练的大模型(如DeepSeek)及其分词器。
- 根据需要调整模型配置,例如通过 config.num_hidden_layers 限制量化层数以加速过程。
- 将模型加载到NPU设备上,并设置合适的 torch_dtype(如 "auto")和 device_map="auto"。
-
激活异常值抑制(Anti-Outlier)
- 这是W8A8量化的关键预处理步骤,旨在解决激活值(Activation)分布范围广、量化误差大的问题。
- 该步骤基于 SmoothQuant 算法的原理,通过计算一个平滑因子 s,将激活值的分布"平滑"到与权重更接近的范围,从而减少量化误差。
- 在代码中,通过 AntiOutlierConfig 和 AntiOutlier 类实现。需要准备一个包含提示词的 anti_dataset(如 anti_prompt.json),用于收集模型在推理过程中的激活值分布,以计算最优的 s 值。
- 此过程会自动将除法操作融合到模型的Norm层(如LayerNorm)权重中,避免在推理时引入额外开销。
-
权重量化与校准(Calibration)
- 在完成激活异常值抑制后,进入核心的量化阶段。
- 使用 QuantConfig 类配置量化参数,指定 w_bit=8, a_bit=8,并选择量化设备为NPU。
- 需要准备一个 calib_dataset(如 calib_prompt.json),包含一组代表性的输入文本,用于在模型前向传播过程中收集权重和激活值的统计信息(如最小值、最大值),以确定量化缩放因子(scale)和零点(zero-point)。
- 通过 Calibrator 类运行校准过程,它会遍历 calib_dataset,收集统计信息并应用量化。
-
保存量化模型与配置
- 校准完成后,调用 calibrator.save() 方法,将量化后的INT8权重、量化参数(如scale、zero-point)保存为文件(如 safe_tensor 格式)。
- 使用 copy_config_files 函数将原始模型的配置文件(如 config.json)复制到保存路径,并通过自定义钩子(custom_hook)更新配置,确保推理引擎能识别并使用量化后的模型。
大模型部署与框架vLLM
大模型部署是指将训练好的大型语言模型(LLM)投入实际应用的过程,涉及推理加速、资源管理、服务化接口等多个环节。vLLM 是一个开源的大模型推理加速框架,专为解决传统框架在高并发、长序列场景下显存利用率低、吞吐量不足等问题而设计,已成为当前高性能推理的标杆方案之一。
vLLM 的核心特性
- PagedAttention 显存优化:vLLM 的核心技术,通过将注意力机制中的键值对(KV)缓存划分为固定大小的页(如 4KB)进行管理,类似操作系统的虚拟内存机制。这能有效避免传统连续存储导致的显存碎片化,使显存占用降低 30%--50%,尤其在处理长上下文时优势显著。
- 持续批处理(Continuous Batching):突破传统静态批处理的限制,允许新请求动态插入到正在处理的批中,并与未完成的请求并行计算。这大幅减少了 GPU 的空闲时间,使吞吐量提升 2--3 倍,同时显著降低首字延迟(TTFB)。
- 高性能与低延迟:通过 CUDA 内核优化和向量化计算,vLLM 实现了极高的推理效率。例如,在单张 A100 显卡上部署 7B 模型时,延迟可低于 100ms,吞吐量可达 120 请求/秒,远超 Hugging Face Transformers 等框架。
- 易用性与兼容性:提供与 Hugging Face 模型无缝集成的 Python API,以及兼容 OpenAI 接口的 RESTful API 和 gRPC 服务,支持流式输出,便于快速集成到现有应用中。
- 分布式扩展能力:支持张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism),可轻松扩展至多卡(如 8 卡 A100)集群,实现对 70B 级大模型的高效部署。
部署示例
以下是一个使用 vLLM 加载模型并进行推理的简单代码示例:
from vllm import LLM, SamplingParams
# 初始化模型(支持 Hugging Face Hub 上的数千种模型)
llm = LLM(model="meta-llama/Llama-2-7b-chat-hf", tensor_parallel_size=1, dtype="bfloat16")
# 设置采样参数
sampling_params = SamplingParams(temperature=0.7, top_p=0.9, max_tokens=50)
# 执行推理
outputs = llm.generate(["解释量子计算原理:"], sampling_params)
# 输出结果
print(outputs.outputs.text)对于需要更高性能的场景,vLLM 还支持 AWQ 等量化技术进行模型压缩,进一步降低显存需求。
环境准备:依赖与版本控制
- Python环境:推荐3.8-3.10,通过conda create -n vllm python=3.9创建隔离环境。
- CUDA工具包:需与GPU驱动匹配(如A100需11.6+)。
- 依赖安装:
pip install vllm torch==2.0.1 cuda-version=11.7
性能调优:关键参数解析