做开发这么多年,有一件事一直困扰我:当我们谈机器学习的时候,大部分人只关注模型训练,而忽视了线上推断 这个环节的"脆弱性"。模型再准,如果线上响应慢、数据不同步、特征不一致,用户体验还是一地鸡毛。 尤其是涉及到贷款审批、欺诈检测、推荐系统这类场景,延迟就是生死线。一个结果晚个几百毫秒,用户可能直接关掉页面,业务就没了。
这篇文章,我想分享如何用 Amazon ElastiCache for Redis + Feast + Redshift 的组合,搭建一个能跑实时推断的在线特征库(online feature store)。我会从几个方面讲清楚这件事:为什么需要它,它解决了什么坑,怎么搭起来,以及过程中踩过的雷。
为什么我需要一个在线特征库
先说痛点。以前我接触过一个贷款审批系统,流程是这样的:
- 用户提交贷款申请(附带一些实时信息,比如申请额度、设备指纹、时间戳等)。
- 系统需要把这个请求和用户的历史数据结合,比如他的信用历史、地理位置、过往贷款记录。
- 把所有特征拼起来,喂给模型,模型返回一个概率(批准还是拒绝)。
听起来没问题对吧?但真正上线后,问题一个接一个:
- 延迟高得吓人:因为有些特征要从离线数据库里查(Redshift / MySQL),再 join 上来,几十到上百毫秒起跳。用户点按钮的时候能感觉到卡顿。
- 特征不一致:训练的时候用的特征是离线批量算的,但线上实时拿不到完全一致的数据,结果模型在本地很准,线上却经常翻车。
- 扩展性差:随着并发量增加,数据库压力越来越大,频繁超时。
当时我就意识到:必须要有一个专门的存储 ,专门放那些线上推断需要的特征 ,并且要保证延迟极低 。这就是所谓的 在线特征库(Online Feature Store) 。
架构选择:Redis 为什么是核心
业界的套路其实挺清晰了:离线特征放在大数据存储(S3 / Redshift / Hudi / Iceberg),训练时取历史;线上特征必须放在一个超快的内存数据库里。
我们选了 Amazon ElastiCache for Redis,原因有三:
- 延迟低:Redis 是内存型数据库,单次读写通常在亚毫秒级,完全符合实时推断的需求。
- 可扩展:ElastiCache 支持分片集群,数据量上来后可以水平扩展,不会像单机 Redis 一样轻易顶满。
- 免运维:作为一个被业务 push 的苦命程序员,我最怕凌晨两点爬起来重启 Redis。托管服务至少让我少掉一些白头发。
但只用 Redis 不够,如何管理特征 、保证线上和线下一致性,还得靠 Feast 这种 Feature Store 框架。
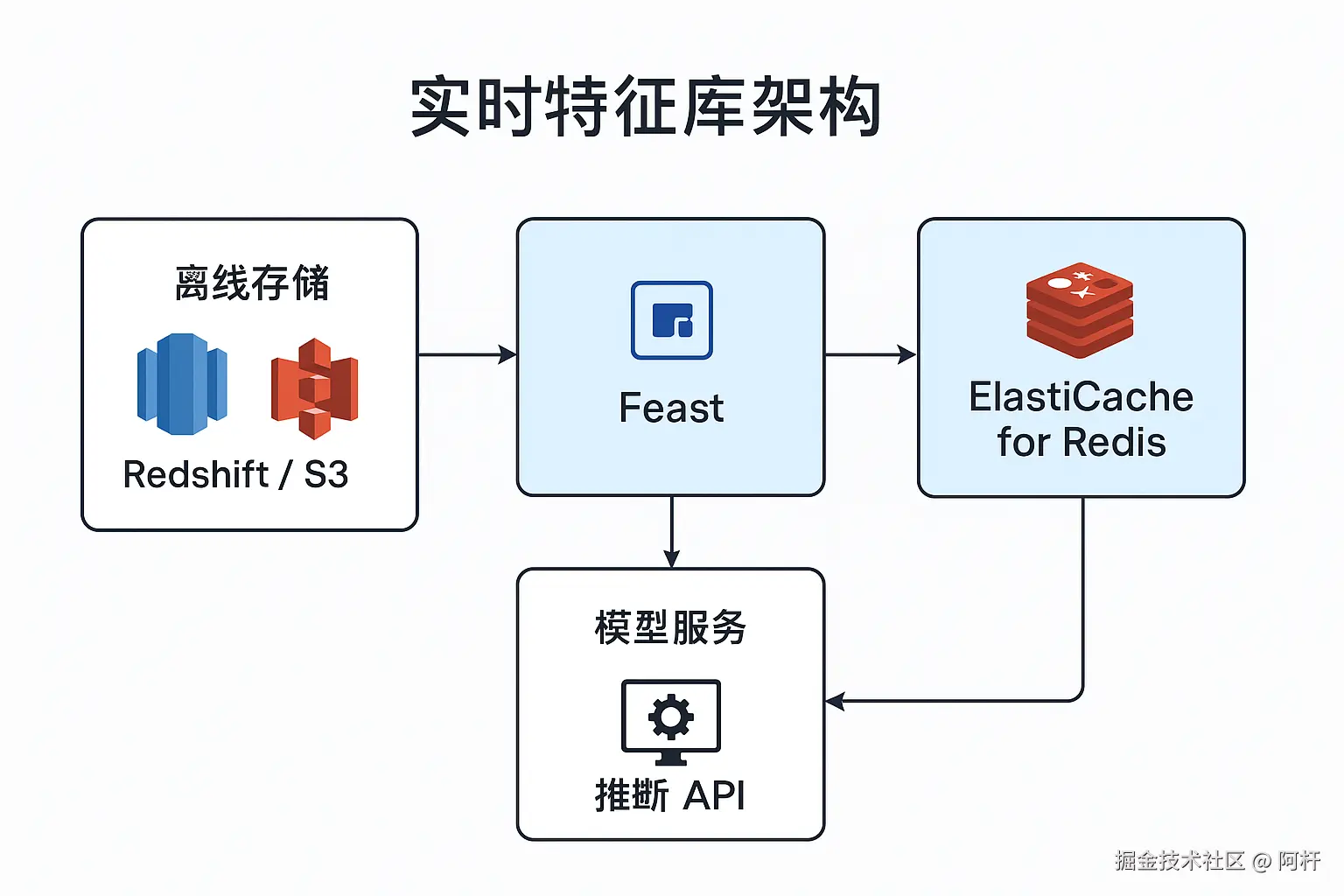
架构长什么样
这套系统,大致就是三层:
- 离线特征存储:Redshift + S3,主要负责存放历史数据、做批处理、训练数据生成。
- 特征管理层:Feast,用来统一定义特征、管理实体 ID、保证线上/线下特征对齐。
- 在线特征存储:Redis(ElastiCache),负责实时读写,用来支撑推断请求。
流程是这样的:
- 我先在 Feast 里定义 实体(Entity) ,比如用户 ID、手机号、邮编。
- 定义 特征视图(Feature View) ,比如"信用历史特征","地理位置特征"。这些特征既可以从 Redshift 离线计算来,也可以实时写进 Redis。
- Feast 提供了 materialize(物化) 功能,可以定期把离线数据推到 Redis,让线上特征保持新鲜。
- 推断时,代码直接调用 Feast 的
get_online_features(),从 Redis 拿到所有特征,再丢给模型。
这样,线上推断全程走内存数据库,延迟降到了个位数毫秒,用户根本感知不到卡顿。
一个真实的案例:贷款审批
为了让你更有画面感,我们来说说当时的贷款审批案例。
- 用户请求:一个人点了"申请贷款",带上了 SSN(社保号)、邮编、额度这些参数。
- 获取特征:系统通过 Feast,从 Redis 拿到这个 SSN 对应的历史违约次数、最近信用卡使用率、他所在地区的平均违约率。
- 模型推断:所有特征拼在一起,输入到一个 XGBoost 模型。
- 实时结果:模型立刻给出一个 0~1 的分数,系统判断是否批准。
整个过程不到 10ms,比当初用数据库 join 的方案快了一个数量级。
Redis 真香,但也有坑
不得不说,Redis 在做在线特征库时简直就是神器。但实际用起来,也有一些需要注意的点。
1. 成本问题
内存存储很贵。你要是把所有历史特征全塞进去,分分钟成本爆炸。我们的经验是:
- 把 Redis 当成缓存,只放线上实时需要的那部分特征。
- 长期历史留在 Redshift / S3。
- 定义好 TTL(过期时间),让一些不常用的特征自动清理掉。
2. 特征一致性
训练用的是离线特征,推断用的是在线特征,如果两边不一致,模型效果就废了。 Feast 在这里特别有用,它能保证同一个特征定义既能产出训练数据,也能产出线上数据。我的建议是:一定要用统一的特征定义文件,别手写两份。
3. 扩容与监控
别天真地以为 Redis 托管就不用管了,高并发下,网络、CPU、内存都会是瓶颈。
- 打开 CloudWatch 指标,盯着 P99 延迟。
- 定期压测,看节点数是否够用。
- 设计好自动扩容规则。
经验总结
我们把搭建在线特征库的几个关键点总结成了这些:
- 先定义业务延迟目标:明确你能接受的最大延迟(比如 10ms),倒推需要多大规模的 Redis 集群。
- 特征分类管理:哪些是静态特征(出生日期、邮编),哪些是动态特征(最近 1 小时交易次数),更新策略要区分开。
- 存储分层:Redis 放热数据、实时特征;Redshift / S3 放冷数据、历史特征。
- 特征一致性优先:用 Feast 或其他工具,保证训练和推断用的是同一份定义。
- 成本监控:Redis 节点很贵,没必要的数据别往里塞,TTL 要用好。
- 安全合规:贷款、金融数据很敏感,传输要加密,访问要限权,日志要留痕。
顺带聊一个很多人关心的问题:做这种实时推理场景,工具有了,思路也清楚了,那环境成本怎么控制?最近我发现亚马逊云科技新出的 Free Tier 2.0 免费套餐,对个人开发者和小团队其实挺友好。
几个点让我觉得实用:
- 门槛低:终于支持银联信用卡和人民币支付了,不用再折腾外币卡。
- 福利多:新用户最高能拿到 200 美元的抵扣金,注册送 100 美元,再做一些入门任务还能再拿 100 美元。
- 安全感强:最长 6 个月完全免费,不会莫名被扣费,除非你自己去升级付费计划。
- 资源更集中:这些抵扣金可以直接砸在常用的服务上,比如 EC2、RDS、Lambda、Bedrock、Budgets,比以前那种"广撒但浅"的免费模式更务实。
对平时需要做 PoC、快速验证原型的开发者来说,这个新套餐几乎是零风险的实验环境,还顺带能把 Amazon Q Developer、Bedrock 这些新工具玩起来。
写在最后
对我来说,这套 Redis + Feast + Redshift 的组合,让我第一次体会到"实时推断"真正落地的感觉。 以前写推荐系统、风控系统,总觉得模型是核心。但实践告诉我,特征管理和数据存储才是真正的瓶颈。没有一个稳定、低延迟的在线特征库,再好的模型也发挥不出威力。
所以,如果你也在做类似的事,我的建议是:
- 把 Redis 当作在线特征库的基石;
- 用 Feast 管好特征定义,保证一致性;
- 再结合 Redshift/S3 做离线数据。
这样,你就能搭出一个真正能跑在生产里的实时推断系统。
以上就是本文的全部内容啦。最后提醒一下各位工友,如果后续不再使用相关服务,别忘了在控制台关闭,避免超出免费额度产生费用~