note
- 相关实践经验:
- 如果你在用 GRPO 且遇到:训练不稳定、loss/奖励发散、MoE 特别难训------可以考虑 GSPO 这套"序列级重要性比 + 序列级 clip"的替代路线。
文章目录
- note
- 一、GSPO算法解析
-
- [1、GRPO 的问题:逐 token 重要性采样的不稳定性](#1、GRPO 的问题:逐 token 重要性采样的不稳定性)
- [2、GSPO:重要性采样从 token 级转移至序列级](#2、GSPO:重要性采样从 token 级转移至序列级)
- 二、重要性采样比的区别
- Reference
一、GSPO算法解析
论文标题:Group Sequence Policy Optimization
论文链接:https://huggingface.co/papers/2507.18071
博客链接:https://qwenlm.github.io/blog/gspo/
1、GRPO 的问题:逐 token 重要性采样的不稳定性
最近 Qwen 的研究表明,使用 GRPO 训练大语言模型时存在严重的稳定性问题,往往会导致模型不可逆地崩溃。他们认为 DeepSeek 的 GPRO 方法存在一些严重问题:
- 在每个 token 级别应用重要性采样,会在长序列中积累高方差,导致训练不稳定。
- 这一问题在 专家混合模型(Mixture-of-Experts, MoE) 中尤为严重,因为 token 级别的路由变化会加剧不稳定性。
- 为缓解这一问题,基于 GRPO 的训练流程通常需要依赖一些额外策略,例如 路由重放(Routing Replay)。
因此,Qwen 团队声称 GRPO 的 token 级重要性采样无法达到稳定训练,其优化目标是「病态的(ill-posed)」。为了解决这些问题并训练其最新的 Qwen3 系列模型,Qwen 团队提出了一种新的强化学习算法 ------ 组序列策略优化(Group Sequence Policy Optimization, GSPO)。
GRPO 的根本问题:「逐 token 重要性采样」的不稳定性
GRPO 是在每一个 token 的生成步骤上单独计算重要性权重的: w i , t ( θ ) = π θ ( y i , t ∣ x , y i , < t ) π θ old ( y i , t ∣ x , y i , < t ) w_{i, t}(\theta)=\frac{\pi_\theta\left(y_{i, t} \mid x, y_{i,<t}\right)}{\pi_{\theta_{\text {old }}}\left(y_{i, t} \mid x, y_{i,<t}\right)} wi,t(θ)=πθold (yi,t∣x,yi,<t)πθ(yi,t∣x,yi,<t)
2、GSPO:重要性采样从 token 级转移至序列级
GSPO 的核心在于将重要性采样从 token 级转移至序列级,其重要性比值基于整个序列的似然度计算: s i ( θ ) = ( π θ ( y i ∣ x ) π θ old ( y i ∣ x ) ) 1 ∣ y i ∣ = exp ( 1 ∣ y i ∣ ∑ t = 1 ∣ y i ∣ log π θ ( y i , t ∣ x , y i , < t ) π θ old ( y i , t ∣ x , y i , < t ) ) s_i(\theta)=\left(\frac{\pi_\theta\left(y_i \mid x\right)}{\pi_{\theta_{\text {old }}}\left(y_i \mid x\right)}\right)^{\frac{1}{\left|y_i\right|}}=\exp \left(\frac{1}{\left|y_i\right|} \sum_{t=1}^{\left|y_i\right|} \log \frac{\pi_\theta\left(y_{i, t} \mid x, y_{i,<t}\right)}{\pi_{\theta_{\text {old }}}\left(y_{i, t} \mid x, y_{i,<t}\right)}\right) si(θ)=(πθold (yi∣x)πθ(yi∣x))∣yi∣1=exp ∣yi∣1t=1∑∣yi∣logπθold (yi,t∣x,yi,<t)πθ(yi,t∣x,yi,<t)
这种采样权重的设计自然地缓解了逐 token 方差的累积问题,从而显著提升了训练过程的稳定性。注意,指数中的因子用于「长度归一化」。如果不进行长度归一化,仅仅几个 token 的似然变化就可能导致序列级重要性比值的剧烈波动,而不同长度的生成响应在目标函数中也将需要不同的裁剪范围,这会进一步增加训练的不稳定性。
二、重要性采样比的区别
版本依赖:ms-swift>=3.7
Group Sequence Policy Optimization中指出GRPO在计算重要性采样权重时,是在token级别进行操作的。然而,这种做法由于每个token仅采样一次,无法实现有效的分布校正,反而会在模型训练过程中引入高方差噪声,极易导致模型的梯度估计不稳定,最终造成模型训练的崩塌。
因此,论文认为,优化目标的单位应该与奖励的单位保持一致。由于奖励通常是在序列级别(即完整生成的回复)给出的,因此更合理的做法是将 off-policy 校正和优化也提升到序列级别,而非 token 级别。以下是三种计算策略对比:
- GRPO
对每个 token 独立计算重要性采样比,具体公式为
w i , t G R P O = π θ ( y i , t ∣ x , y i , < t ) π θ o l d ( y i , t ∣ x , y i , < t ) w^{\mathrm{GRPO}}{i,t} = \frac{\pi\theta (y_{i, t} \mid x, y_{i, <t})}{\pi_{\theta_{\mathrm{old}}} (y_{i, t} \mid x, y_{i, <t})} wi,tGRPO=πθold(yi,t∣x,yi,<t)πθ(yi,t∣x,yi,<t)
- GSPO (Sequence-Level)
在序列级别上计算重要性采样比,具体公式为
w i G S P O = π θ ( y i ∣ x ) π θ o l d ( y i ∣ x ) 1 ∣ y i ∣ = exp ( 1 ∣ y i ∣ ∑ t = 1 ∣ y i ∣ log π θ ( y i , t ∣ x , y i , < t ) π θ o l d ( y i , t ∣ x , y i , < t ) ) w^{\mathrm{GSPO}}{i} = \left \\frac{\\pi_\\theta (y_i \\mid x)}{\\pi_{\\theta_{\\mathrm{old}}} (y_i \\mid x)} \\right^{\frac{1}{|y_i|}} = \exp\left( \frac{1}{|y_i|} \sum{t=1}^{|y_i|} \log \frac{\pi_\theta (y_{i, t} \mid x, y_{i, <t})}{\pi_{\theta_{\mathrm{old}}} (y_{i, t} \mid x, y_{i, <t})} \right) wiGSPO=πθold(yi∣x)πθ(yi∣x)∣yi∣1=exp ∣yi∣1t=1∑∣yi∣logπθold(yi,t∣x,yi,<t)πθ(yi,t∣x,yi,<t)
- GSPO-token
GSPO-token 结合了序列级与 token 级的重要性采样思想
w i , t G S P O − t o k e n = s g w i G S P O ⋅ π θ ( y i , t ∣ x , y i , < t ) s g π θ ( y i , t ∣ x , y i , \< t ) w_{i, t}^{\mathrm{GSPO-token}} = \mathrm{sg}\leftw_i\^{\\mathrm{GSPO}}\\right \cdot \frac{\pi_{\theta}(y_{i, t} \mid x, y_{i, < t})}{\mathrm{sg}\left\\pi_{\\theta}(y_{i, t} \\mid x, y_{i, \< t})\\right} wi,tGSPO−token=sgwiGSPO⋅sgπθ(yi,t∣x,yi,\
其中, ( s g ⋅ ) (\mathrm{sg}\\cdot) (sg⋅) 表示梯度截断(detach())。
注意:根据梯度推导(即论文中的公式(11)和(18)),当各 token 的 advantage 相同时,GSPO-token 与 GSPO 等价。当前的 GRPO 实现中,所有 token 的 advantage 实际上都是基于句子级 reward 并在 group 内进行归一化,因此在这种设置下,GSPO-token 和 GSPO 在理论上是等价的。不过,GSPO-token 为未来更细粒度(token 级别)的 advantage 提供了支持。
伪代码实现
python
log_ratio = per_token_logps - old_per_token_logps
# GRPO
log_importance_weights = log_ratio
# GSPO (Sequence-Level)
seq_weight = (log_ratio * mask).sum(-1) / mask.sum(-1)
log_importance_weights = seq_weight.unsqueeze(-1) # (B,1)
# GSPO-token
seq_weight = (log_ratio * mask).sum(-1) / mask.sum(-1)
log_importance_weights = seq_weight.detach().unsqueeze(-1) + (per_token_logps - per_token_logps.detach())
importance_weights = torch.exp(log_importance_weights)我们可以在 GRPO 训练的基础上,通过参数 --importance_sampling_level 选择不同的算法:
importance_sampling_level token(默认,GRPO 实现)importance_sampling_level sequence(GSPO)importance_sampling_level sequence_token(GSPO-token)
其中 sequence_token 要求 ms-swift > 3.7 (源码安装)
论文其他超参
bash
--epsilon 3e-4 # from paper section 5.1
--epsilon_high 4e-4 # from paper section 5.1
--steps_per_generation 4 # from paper section 5.1 (each batch of rollout data is partitioned into four minibatches for gradient updates)
--beta 0 # zero kl regularization https://github.com/volcengine/verl/pull/2775#issuecomment-3131807306训练可以参考该脚本
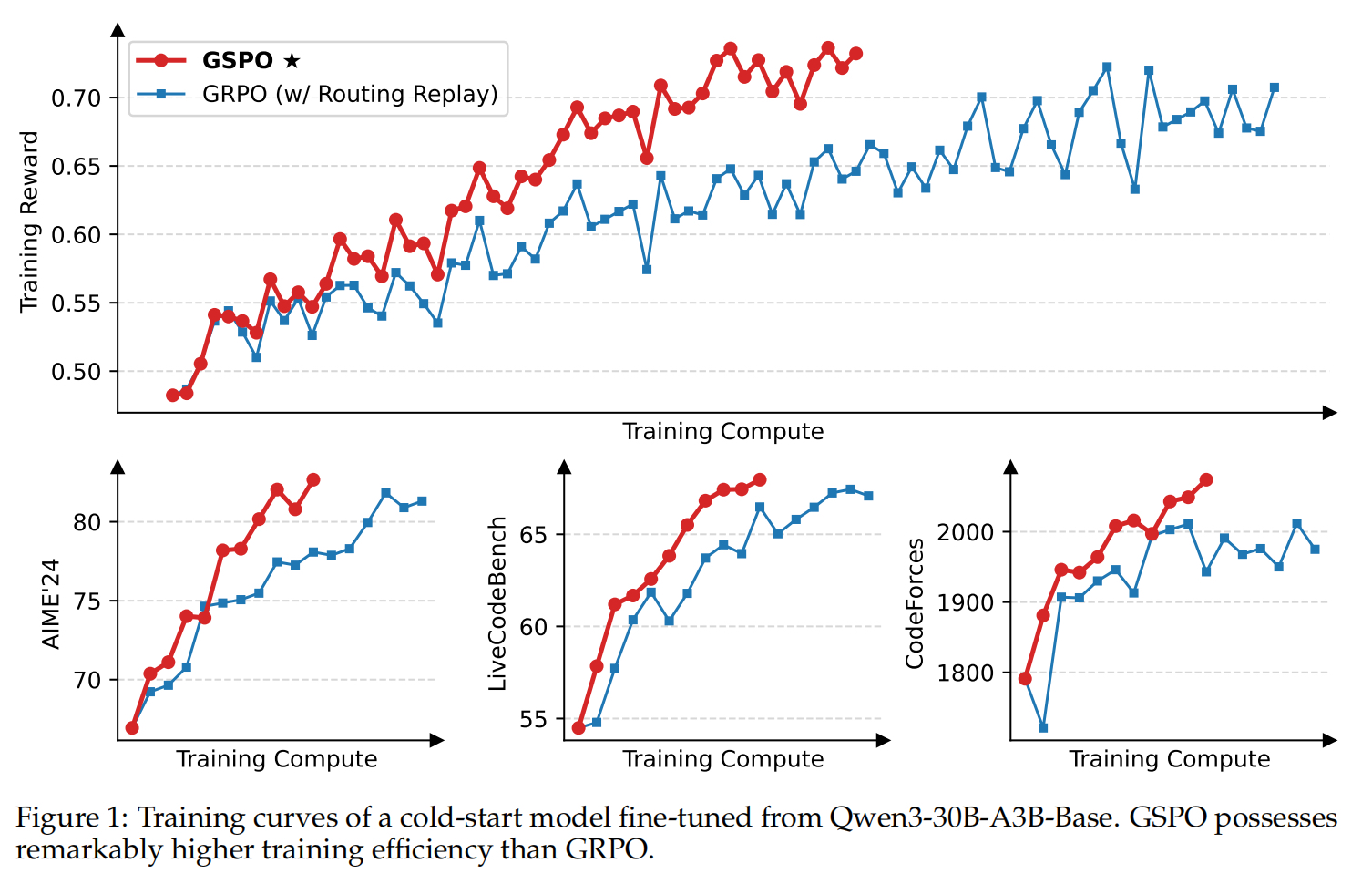
效果优势体现如下图:
- 在相同训练计算资源时,GSPO比GRPO训练的模型效果更好
w/是with的缩写,这里对照组GRPO还是使用了routing replay优化过的GRPO。这里是把旧策略(或生成时)的专家激活路径记录下来,并在训练时强制/复用同样的路由,让新旧策略对该 token 经过同一组专家,从而稳定比率与训练。