本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
现在大家遇到问题,第一反应都不是使用搜索引擎,而是问 chatGPT,chat 大家都知道是聊天的意思,但是 GPT 它到底是个什么呢?
展开一下全名:Generative Pretrained Transformer,翻译过来就是生成式预训练 Transformer。
所以在此之前我们需要更清楚知道 Transformer 到底是个啥。
Transformer 架构
说到 Transformer 还是不能不提其源头,鼎鼎大名的《Attention Is All You Need》,这篇论文提出了这个名为 Transformer 的深度神经网络架构。
在论文里面,这个架构是长这样的:
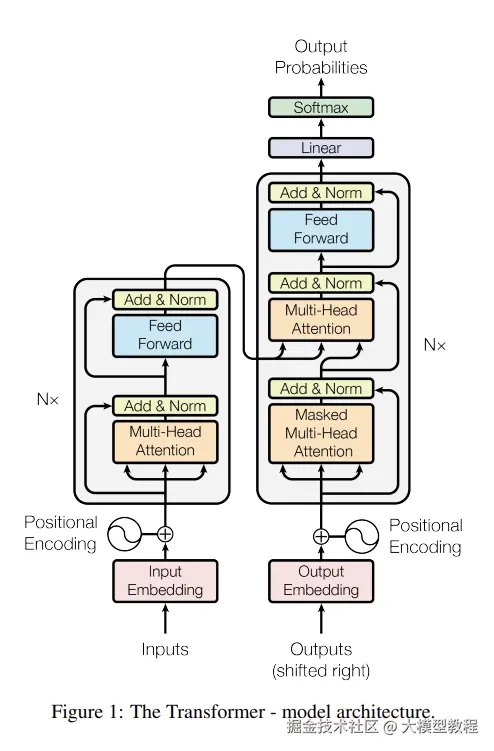
其核心就是自注意力机制。
注:后来很多 GPT 只保留了 decoder。
最基本的原理
回忆一下神经网络,我们的输入和输出,经过神经网络训练一顿操作!调整好权重,就能输出像模像样的答案。
那么对文字是不是也能这么操作呢?没错的,事实证明完全可以。
因为文字这个东西,现成的正确答案真的太多啦,我们训练的时候可以这样:
输入:番茄是
正确结果:番茄是红如果猜到的不是红,那就计算损失,把权重往对的那边凹一下。
经过很多 TB 的文字数据训练之后,就成就了现在的大语言模型,它似乎了解地球上一切文字知识,并且表达出来毫无维和感。
科学似乎还无法解释这件事,大模型可以流畅回答训练样本里没有的内容,这就称为涌现。例如大模型其实没有专门学过翻译呢,但是它偏偏就可以在繁多的参数里面懂得如何翻译不同语言。
输入和输出
对于大模型来说,输入和输出,本质上是 Token。
通过这个分词工具,可以更清晰地理解 Token 的概念,它不一定是一个字母、一个单词、一个符号,而有可能是它们的组合。
如图所示:
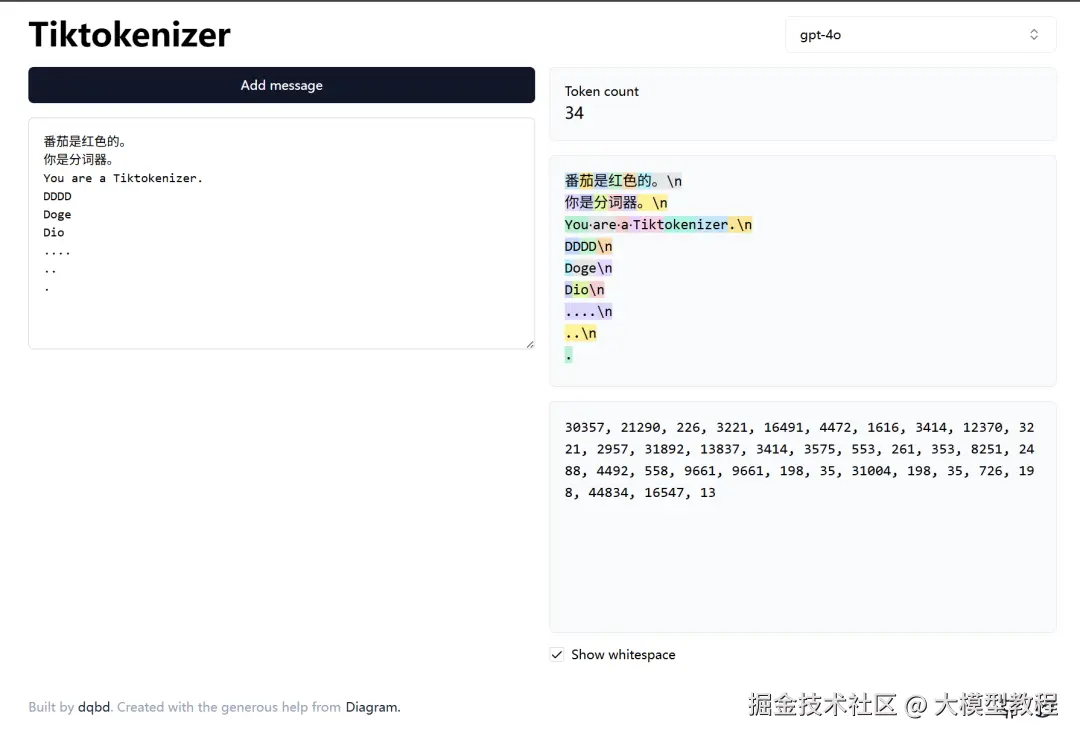
所以在训练的时候,输入输出就是:
yaml
输入:30357, 21290, 226, 3221
输出:30357, 21290, 226, 3221, 16491吗?
不是的,实际训练的肯定不是这个 Token ID,而是这个 ID 代表的含义本身。
把文字转换为向量就是所谓的词嵌入(embedding) (关于 RAG 后面再开坑)。根据《从零构建大模型》的说法:最小的 GPT-2 模型(参数量为 1.17 亿)使用的嵌入维度为 768,而 GPT-3模型(参数量为 1750 亿)使用的嵌入维度为 12288。
在这个场景下,简单来说就是让这个 Token 转换为一个 768 个值的数组......
例如番茄就是 [0.9,0.4,0.7,0.5,0.9...后面还有七百多个维度],对比其它水果可能是这样的:
| 维度 | 含义 | "番茄"的值 | "草莓"的值 | "黄瓜"的值 |
|---|---|---|---|---|
| 1 | 有多红 | 0.9 | 0.85 | 0.1 |
| 2 | 甜度 | 0.4 | 0.8 | 0.1 |
| 3 | 水分 | 0.7 | 0.6 | 0.9 |
| 4 | 是否属于蔬菜 | 0.5 | 0.1 | 0.8 |
| 5 | 是否可生吃 | 0.9 | 0.95 | 0.8 |
注意:这里的含义只是比喻,实际上各个维度的含义人类是看不懂的。
大家应该差不多理解了,真正的输入输出就是这些几百上千维度。
把这些值的正确排列经过神经网络训练,让其预测下一个 Token 是某个词的概率(logits),然后取概率比较高的值。
最后举个输入输出例子:
less
输入: "番茄是"
↓ Token化
Token: [123, 456, 789]
↓ 转换为向量
Vector: [[0.1,0.2,...], [0.3,0.4,...], [0.5,0.6,...]]
↓ 神经网络预测
Hidden State: [0.7, -0.2, 1.1, ..., 0.3] # 768维隐藏状态
↓ 通过输出层投影
Logits: [-2.3, 1.5, ..., 4.2, ..., 2.1, ...] # 词汇表大小的向量
↓ Softmax转换为概率
概率分布: [0.001, 0.003, ..., 0.45(对应"红"), ..., 0.25(对应"圆的"), ...]
↓ 选择最高概率
输出: Token ID 4567 (对应"红")中间看不懂不用怕,下一章就会讲到自注意力机制的原理啦~
循环生成
上面一顿输入输出其实只生成了一个新 Token,你需要生成一句话的话,就继续把新的 Token 拼到原来的句子里,继续循环下去,就能生成一整段话啦。
参考资料
- • 从零构建大模型
- • Deep Dive into LLMs like ChatGPT
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。