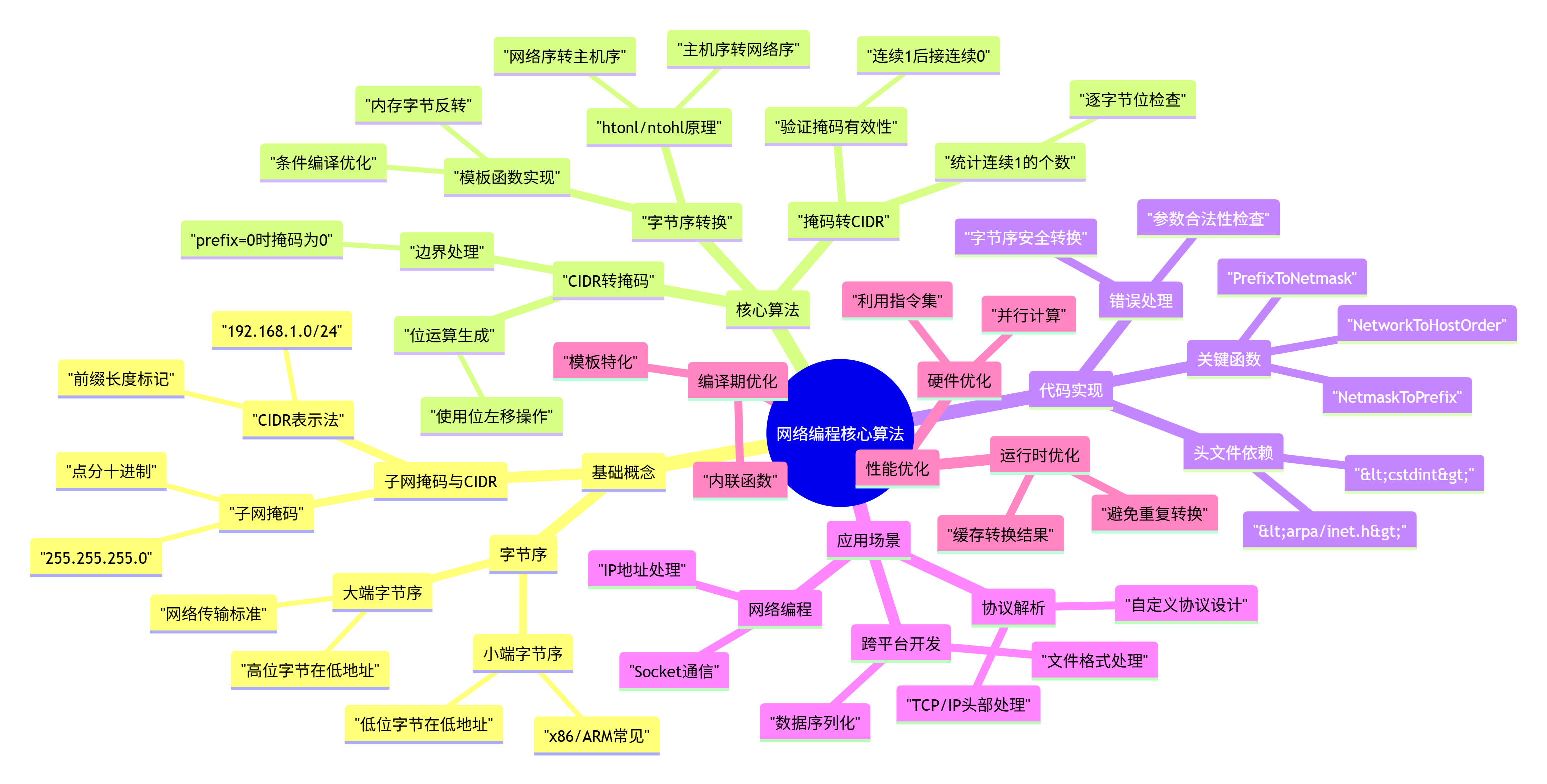
网络编程基础算法剖析:从字节序转换到CIDR掩码计算
深入理解网络编程中的基础算法,掌握数据表示与转换的核心原理
1. 引言:网络编程中的基础挑战
在网络编程中,我们面临着一个根本性挑战:不同的计算机系统可能以不同的方式表示和存储数据。这种差异主要体现在两个层面:
- 字节序:多字节数据在内存中的存储顺序差异
- 地址表示:IP地址和子网掩码的不同表示方法
本文将剖析解决这些挑战的核心算法,包括字节序转换函数(htonl/ntohl等)和CIDR与子网掩码的相互转换算法。通过理解这些基础但关键的算法,开发者能够编写出真正跨平台兼容、网络高效的应用程序。
2. 字节序基础概念与网络字节序
2.1 什么是字节序?
字节序是指多字节数据在内存中的存储顺序。对于网络编程而言,理解字节序至关重要,因为它直接影响数据在不同系统间的正确解析。
2.1.1 大端字节序
大端字节序将高位字节存储在低地址处,低位字节存储在高地址处。这种顺序类似于我们书写数字的方式:从左到右,从高位到低位。
示例 :32位整数0x12345678在大端模式下的存储:
低地址 → 0x12 → 0x34 → 0x56 → 0x78 ← 高地址2.1.2 小端字节序
小端字节序将低位字节存储在低地址处,高位字节存储在高地址处。这种存储方式在x86架构中普遍使用。
示例 :同样的0x12345678在小端模式下的存储:
低地址 → 0x78 → 0x56 → 0x34 → 0x12 ← 高地址2.2 为什么需要关注字节序?
字节序的重要性体现在跨平台数据交换中。不同架构的处理器可能使用不同的字节序:
- Intel x86/x64系列:使用小端字节序
- ARM处理器:默认小端,但可配置为大端
- PowerPC、SPARC等:通常使用大端字节序
当这些不同架构的设备通过网络通信时,如果不对字节序进行统一,接收方将无法正确解析数据。
2.3 网络字节序的标准解决方案
为了解决字节序差异问题,TCP/IP协议族规定网络字节序统一使用大端模式。这意味着:
- 数据发送前,将主机字节序转换为网络字节序(大端)
- 数据接收后,将网络字节序转换为主机字节序
主机字节序 网络字节序 网络字节序 主机字节序 发送端主机 转换函数 网络传输 转换函数 接收端主机
3. 核心算法解析与实现
3.1 CIDR前缀转网络掩码算法
CIDR表示法使用斜线后跟数字表示网络前缀的长度,如192.168.1.0/24。将其转换为点分十进制格式的子网掩码是网络编程中的常见需求。
3.1.1 算法原理
CIDR前缀转换为子网掩码的核心思想是:创建一个连续n个1后面跟(32-n)个0的32位掩码,其中n为CIDR前缀长度。
数学表示:
mask = (2^n - 1) << (32 - n)实际实现中,我们使用更高效的方式:(-1L << (32 - prefix))。
3.1.2 实现代码分析
cpp
static UInt32 PrefixToNetmask(int prefix) noexcept {
// 处理prefix为0的特殊情况:掩码全为0
// 当prefix不为0时,通过左移操作生成连续的前缀位
UInt32 mask = prefix ? (-1L << (32L - prefix)) : 0L;
// 将主机字节序的掩码转换为网络字节序(大端模式)
return htonl(mask);
}关键步骤解析:
-
边界处理 :当prefix为0时,子网掩码为
0.0.0.0 -
掩码生成 :通过左移操作生成连续的前缀位。例如prefix=24时:
-1L << (32-24) = -1L << 8 = 0xFFFFFF00 -
字节序转换 :使用
htonl确保掩码以网络字节序表示
3.1.3 可视化转换过程
prefix = 0 prefix > 0 CIDR前缀 前缀值判断 掩码全0: 0.0.0.0 计算左移位数: 32-prefix 生成掩码: -1L << 32-prefix 转换为网络字节序 返回网络掩码
3.2 网络掩码转CIDR前缀算法
将点分十进制子网掩码转换为CIDR前缀长度是CIDR转换的逆过程,需要统计掩码中连续1的个数。
3.2.1 算法原理
该算法的核心是:统计子网掩码二进制表示中连续1的数量。有效子网掩码的1必须是连续的,从最高位开始,不能有间断。
验证步骤:
- 将掩码转换为二进制
- 确保所有1是连续的且从最高位开始
- 统计连续1的数量得到CIDR前缀
3.2.2 实现代码分析
cpp
static int NetmaskToPrefix(UInt32 mask) noexcept {
// 将32位掩码转换为字节数组进行处理
return NetmaskToPrefix(reinterpret_cast<unsigned char*>(&mask), sizeof(mask));
}
static int NetmaskToPrefix(unsigned char* bytes, int bytes_size) noexcept {
// 参数合法性检查:确保字节数组有效
if (NULL == bytes || bytes_size < 1) {
return 0;
}
int prefix = 0; // CIDR前缀计数器
// 遍历每个字节
for (int i = 0; i < bytes_size; i++) {
int b = bytes[i]; // 获取当前字节值
// 统计当前字节中连续1的数量
while (b) {
prefix += b & 1; // 检查最低位是否为1
b >>= 1; // 右移一位,检查下一位
}
}
return prefix; // 返回总的前缀长度
}关键步骤解析:
- 参数验证:确保输入的字节数组有效
- 字节遍历:逐个字节处理掩码数据
- 位统计:通过循环右移统计每个字节中1的数量
- 累加结果:将所有字节的1数量相加得到总前缀长度
3.2.3 算法示例
以掩码255.255.255.0为例:
- 转换为二进制:
11111111.11111111.11111111.00000000 - 统计连续1的数量:8+8+8+0=24
- CIDR前缀结果为:24
3.3 通用字节序转换模板函数
字节序转换是网络编程的基础操作,需要处理不同数据类型的转换需求。
3.3.1 算法原理
字节序转换的本质是反转多字节数据的字节顺序。对于小端系统,需要将数据字节序反转;对于大端系统,由于与网络字节序一致,无需转换。
转换策略:
- 小端系统:逆序排列字节
- 大端系统:直接返回原值(与网络字节序相同)
3.3.2 实现代码分析
cpp
template <class T>
static T NetworkToHostOrder(const T& network) noexcept {
// 如果不是小端系统(即大端或未知),直接返回(大端与网络字节序相同)
#if (__BYTE_ORDER__ != __ORDER_LITTLE_ENDIAN__)
return network;
#else
// 小端系统需要转换:逐字节逆序复制
T hostorder{};
char* __dst = (char*)&reinterpret_cast<const char&>(hostorder);
char* __src = (char*)&reinterpret_cast<const char&>(network);
// 从高位字节开始复制(网络字节序的高位在前)
__src += sizeof(network);
for (int i = 0; i < sizeof(network); i++) {
__src--; // 向前移动源指针
*__dst = *__src; // 复制字节
__dst++; // 向后移动目标指针
}
return hostorder;
#endif
}
template <class T>
static T HostToNetworkOrder(const T& host) noexcept {
// 利用NetworkToHostOrder的逆运算特性
return NetworkToHostOrder<T>(host);
}关键设计特点:
- 条件编译:根据目标平台字节序选择不同的实现路径
- 模板编程:支持任意数据类型的字节序转换
- 内存操作:通过指针操作直接操作内存字节,高效实现字节反转
- 对称设计 :
HostToNetworkOrder复用NetworkToHostOrder的逻辑
4. 完整实现代码(含头文件和详细注解)
以下是完整的、可编译的C++实现代码,包含了所有必要的头文件和详细的中文注解:
cpp
#include <iostream> // 输入输出流支持
#include <cstdint> // 标准整数类型定义(uint32_t等)
#include <arpa/inet.h> // 网络字节序转换函数(htonl/ntohl等)
/**
* @brief 网络字节序转换工具类
*
* 提供CIDR前缀与子网掩码转换、字节序转换等网络编程常用功能
* 所有方法均为静态方法,无需实例化即可使用
*/
class NetworkUtils {
public:
/**
* @brief 将CIDR前缀长度转换为网络掩码
* @param prefix CIDR前缀长度(0-32)
* @return 网络字节序的32位掩码
*/
static uint32_t PrefixToNetmask(int prefix) noexcept {
// 边界检查:确保prefix在合法范围内
if (prefix < 0) prefix = 0;
if (prefix > 32) prefix = 32;
// 如果prefix为0,掩码为0;否则通过左移生成对应掩码
// 示例:prefix=24 -> -1左移(32-24)=8位 -> 0xFFFFFF00
uint32_t mask = (prefix == 0) ? 0 : (~0U << (32 - prefix));
// 将主机字节序转换为网络字节序(大端模式)
return htonl(mask);
}
/**
* @brief 将网络掩码转换为CIDR前缀长度(32位版本)
* @param mask 网络字节序的32位掩码
* @return CIDR前缀长度
*/
static int NetmaskToPrefix(uint32_t mask) noexcept {
// 将网络字节序转换为主机字节序后处理
uint32_t host_mask = ntohl(mask);
// 将32位掩码转换为字节数组进行处理
return NetmaskToPrefix(reinterpret_cast<unsigned char*>(&host_mask), sizeof(host_mask));
}
/**
* @brief 将网络掩码转换为CIDR前缀长度(通用字节数组版本)
* @param bytes 掩码的字节数组表示
* @param bytes_size 字节数组大小
* @return CIDR前缀长度
*/
static int NetmaskToPrefix(unsigned char* bytes, int bytes_size) noexcept {
// 参数合法性检查
if (bytes == nullptr || bytes_size < 1) {
return 0;
}
int prefix = 0; // CIDR前缀计数器
bool found_zero = false; // 标记是否已遇到0(确保1的连续性)
// 遍历每个字节
for (int i = 0; i < bytes_size; i++) {
unsigned char b = bytes[i]; // 获取当前字节值
// 检查当前字节的8个位
for (int bit = 7; bit >= 0; bit--) {
unsigned char mask = (1 << bit);
if (b & mask) { // 当前位为1
if (found_zero) {
// 在0之后又出现了1,说明不是连续掩码
return 0; // 无效掩码
}
prefix++; // 增加前缀计数
} else { // 当前位为0
found_zero = true; // 标记已遇到0
}
}
}
return prefix; // 返回总的前缀长度
}
/**
* @brief 网络字节序转主机字节序
* @param network 网络字节序的数据
* @return 主机字节序的数据
*/
template <class T>
static T NetworkToHostOrder(const T& network) noexcept {
// 使用预编译指令检查字节序,避免运行时判断
#if (defined(__BYTE_ORDER__) && defined(__ORDER_LITTLE_ENDIAN__) && \
__BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__)
// 小端系统需要转换:逐字节逆序复制
T hostorder{};
const char* __src = reinterpret_cast<const char*>(&network);
char* __dst = reinterpret_cast<char*>(&hostorder);
// 从高位字节开始复制(网络字节序的高位在前)
for (size_t i = 0; i < sizeof(T); i++) {
__dst[i] = __src[sizeof(T) - 1 - i];
}
return hostorder;
#else
// 大端系统与网络字节序相同,直接返回
return network;
#endif
}
/**
* @brief 主机字节序转网络字节序
* @param host 主机字节序的数据
* @return 网络字节序的数据
*/
template <class T>
static T HostToNetworkOrder(const T& host) noexcept {
// 利用NetworkToHostOrder的逆运算特性
// 注意:转换是对称的,所以两次转换结果相同
return NetworkToHostOrder<T>(host);
}
/**
* @brief 检查子网掩码是否有效(连续的1后跟连续的0)
* @param mask 网络字节序的子网掩码
* @return 是否有效
*/
static bool IsValidNetmask(uint32_t mask) noexcept {
uint32_t host_mask = ntohl(mask);
// 将掩码取反后加1,检查是否只有1个连续的1块
uint32_t inverted = ~host_mask;
return (inverted & (inverted + 1)) == 0;
}
};
/**
* @brief 测试函数,演示工具类的使用方法
*/
void DemonstrateNetworkUtils() {
std::cout << "=== 网络工具类功能演示 ===" << std::endl;
// 测试CIDR转掩码
std::cout << "1. CIDR转掩码测试:" << std::endl;
int test_prefixes[] = {0, 24, 32, 16};
for (int prefix : test_prefixes) {
uint32_t mask = NetworkUtils::PrefixToNetmask(prefix);
std::cout << " /" << prefix << " -> "
<< ((mask >> 24) & 0xFF) << "."
<< ((mask >> 16) & 0xFF) << "."
<< ((mask >> 8) & 0xFF) << "."
<< (mask & 0xFF) << std::endl;
}
// 测试掩码转CIDR
std::cout << "2. 掩码转CIDR测试:" << std::endl;
uint32_t test_masks[] = {0x00000000, 0xFFFFFF00, 0xFFFFFFFF};
for (uint32_t mask : test_masks) {
int prefix = NetworkUtils::NetmaskToPrefix(mask);
std::cout << " "
<< ((mask >> 24) & 0xFF) << "."
<< ((mask >> 16) & 0xFF) << "."
<< ((mask >> 8) & 0xFF) << "."
<< (mask & 0xFF) << " -> /" << prefix << std::endl;
}
// 测试字节序转换
std::cout << "3. 字节序转换测试:" << std::endl;
uint32_t host_value = 0x12345678;
uint32_t network_value = NetworkUtils::HostToNetworkOrder(host_value);
uint32_t back_to_host = NetworkUtils::NetworkToHostOrder(network_value);
std::cout << " 原始值: 0x" << std::hex << host_value << std::endl;
std::cout << " 主机->网络: 0x" << std::hex << network_value << std::endl;
std::cout << " 网络->主机: 0x" << std::hex << back_to_host << std::endl;
std::cout << " 转换正确性: " << (host_value == back_to_host ? "通过" : "失败") << std::endl;
}
int main() {
DemonstrateNetworkUtils();
return 0;
}5. 应用场景与实战示例
5.1 网络编程中的典型应用场景
5.1.1 Socket编程中的地址处理
在网络编程中,IP地址和端口号需要使用网络字节序。以下是典型的使用场景:
cpp
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
void SetupSocket() {
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server_addr;
server_addr.sin_family = AF_INET;
server_addr.sin_port = NetworkUtils::HostToNetworkOrder<uint16_t>(8080); // 端口转换
// IP地址转换(点分十进制到网络字节序)
inet_pton(AF_INET, "192.168.1.1", &server_addr.sin_addr);
// 设置子网掩码(CIDR转网络字节序)
uint32_t netmask = NetworkUtils::PrefixToNetmask(24);
// ... 其他socket操作
}5.1.2 网络协议解析
当解析自定义网络协议时,需要确保多字节字段的正确字节序:
cpp
struct NetworkPacket {
uint32_t magic; // 魔术字(需要字节序转换)
uint16_t length; // 数据长度(需要字节序转换)
uint8_t data[]; // 数据(单字节,无需转换)
};
void ProcessPacket(const NetworkPacket* packet) {
// 将网络字节序转换为主机字节序
uint32_t magic = NetworkUtils::NetworkToHostOrder(packet->magic);
uint16_t length = NetworkUtils::NetworkToHostOrder(packet->length);
// 验证魔术字
if (magic != 0xDEADBEEF) {
return; // 无效包
}
// 处理数据...
}5.2 性能优化考虑
5.2.1 编译期优化
现代编译器可以对字节序转换进行优化,特别是当目标平台字节序与网络字节序相同时:
cpp
// 使用内联函数和常量表达式优化
template<typename T>
static constexpr T OptimizedHostToNetwork(T value) noexcept {
if constexpr (host_is_big_endian) {
return value; // 大端系统无需转换
} else {
return ByteSwap(value); // 小端系统需要字节交换
}
}5.2.2 避免不必要的转换
在性能敏感的场景中,应避免重复的字节序转换:
cpp
// 不好的做法:重复转换
void SendData(uint32_t value) {
uint32_t net_value1 = NetworkUtils::HostToNetworkOrder(value);
// ... 一些操作
uint32_t net_value2 = NetworkUtils::HostToNetworkOrder(value); // 重复转换!
}
// 好的做法:缓存转换结果
void SendDataOptimized(uint32_t value) {
uint32_t net_value = NetworkUtils::HostToNetworkOrder(value);
// ... 使用缓存的值
}6. 总结
本文剖析了网络编程中的核心算法:字节序转换 和CIDR掩码转换。这些算法虽然基础,但却是构建可靠网络应用的基石。
6.1 关键知识点总结
- 字节序的本质:不同CPU架构对多字节数据的不同存储方式
- 网络字节序标准:大端模式作为网络传输的统一标准
- CIDR表示法:无类别域间路由的高效地址表示方法
- 算法实现技巧:位运算在高效网络编程中的应用
6.2 实际应用价值
掌握这些算法不仅有助于理解网络协议栈的工作原理,还能帮助开发者:
- 编写跨平台代码:正确处理不同架构的字节序差异
- 优化网络性能:减少不必要的数据转换和复制
- 调试网络问题:快速定位字节序相关的数据解析错误
- 设计网络协议:创建高效、可扩展的自定义协议
通过理解本文介绍的核心算法,开发者将具备解决实际网络编程问题的坚实基础,能够构建出更加健壮、高效的网络应用系统。