图的基本概念
二维坐标中,两点可以连成线,多个点连成的线就构成了图。
当然图也可以就一个节点,甚至没有节点(空图)
1.图的种类
一般分为有向图和无向图。
2.度
无向图中有几条边连接该节点,该节点就有几度。
在有向图中,每个节点有出度和入度。
出度:从该节点出发的边的个数。
入度:指向该节点边的个数。
连通性
在图中表示节点的连通情况。
1.连通图
在无向图中,任何两个节点都是可以到达的,我们称之为连通图 。如果有节点不能到达其他节点,则为非连通图。
2.强连通图
在有向图中,任何两个节点是可以相互到达的,我们称之为 强连通图。强连通图是在有向图中任何两个节点是可以相互到达。
3.连通分量
在无向图中的极大连通子图称之为该图的一个连通分量。
强连通分量
在有向图中极大强连通子图称之为该图的强连通分量。
图的构造
如何用代码来表示一个图呢?
一般使用邻接表、邻接矩阵 或者用类来表示。
主要是 朴素存储、邻接表和邻接矩阵。
1.朴素存储
如果有8条边,我们就定义 8 * 2的数组,即有n条边就申请n * 2
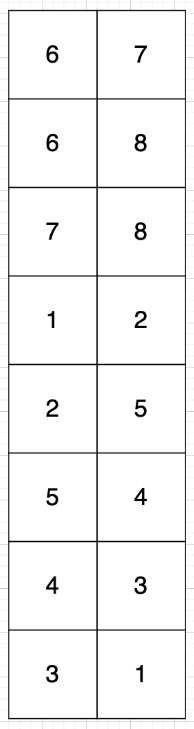
数组第一行:6 7,就表示节点6 指向 节点7。
优缺点:
这种表示方式的好处就是直观,把节点与节点之间关系很容易展现出来。
但如果我们想知道 节点1 和 节点6 是否相连,我们就需要把存储空间都枚举一遍才行。
2.邻接矩阵
邻接矩阵 使用 二维数组来表示图结构。 邻接矩阵是从节点的角度来表示图,有多少节点就申请多大的二维数组。
例如: grid25 = 6,表示 节点 2 连接 节点5 为有向图,节点2 指向 节点5,边的权值为6。如果想表示无向图,即:grid25 = 6,grid52 = 6,表示节点2 与 节点5 相互连通,权值为6。
这种表达方式(邻接矩阵) 在 边少,节点多的情况下,会导致申请过大的二维数组,造成空间浪费。而且在寻找节点连接情况的时候,需要遍历整个矩阵,即 n * n 的时间复杂度,同样造成时间浪费。
邻接矩阵的优点:
表达方式简单,易于理解
检查任意两个顶点间是否存在边的操作非常快
适合稠密图,在边数接近顶点数平方的图中,邻接矩阵是一种空间效率较高的表示方法。
缺点:
遇到稀疏图,会导致申请过大的二维数组造成空间浪费 且遍历 边 的时候需要遍历整个n * n矩阵,造成时间浪费
3.邻接表
邻接表 使用 数组 + 链表的方式来表示。 邻接表是从边的数量来表示图,有多少边 才会申请对应大小的链表。
邻接表的构造图:
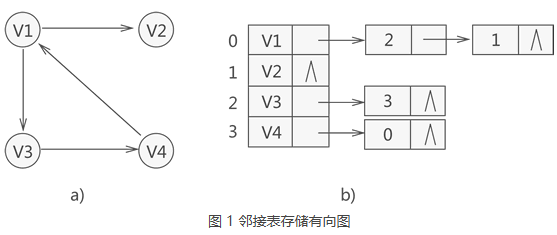
有多少边 邻接表才会申请多少个对应的链表节点。
可以直观看出 使用 数组 + 链表 来表达 边的连接情况 。
邻接表的优点:
对于稀疏图的存储,只需要存储边,空间利用率高
遍历节点连接情况相对容易
缺点:
检查任意两个节点间是否存在边,效率相对低,需要 O(V)时间,V表示某节点连接其他节点的数量。
实现相对复杂,不易理解
图的遍历方式
图的遍历方式基本是两大类:
深度优先搜索(dfs)
广度优先搜索(bfs)
1.深度优先搜索理论基础
dfs是可一个方向去搜,不到黄河不回头,直到遇到绝境了,搜不下去了,再换方向(换方向的过程就涉及到了回溯)。
关键就两点:
1>搜索方向,是认准一个方向搜,直到碰壁之后再换方向
2>换方向是撤销原路径,改为节点链接的下一个路径,回溯的过程。

回溯法得代码框架:
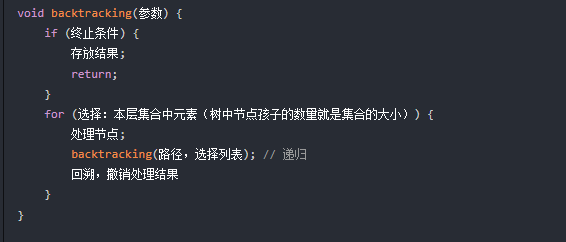
回溯算法,其实就是dfs的过程,这里给出dfs的代码框架:

深搜三部曲
1>确认递归函数,参数
void dfs(参数)一般情况,深搜需要 二维数组数组结构保存所有路径,需要一维数组保存单一路径,这种保存结果的数组,我们可以定义一个全局变量,避免让我们的函数参数过多。
2>确认终止条件
if (终止条件) {
存放结果;
return;
}终止添加不仅是结束本层递归,同时也是我们收获结果的时候。
另外,其实很多dfs写法,没有写终止条件,其实终止条件 隐藏在下面dfs递归的逻辑里了,也就是不符合条件,直接不会向下递归。
3>处理目前搜索节点出发的路径
一般这里就是一个for循环的操作,去遍历目前搜索节点所能到的所有节点。
for (选择:本节点所连接的其他节点) {
处理节点;
dfs(图,选择的节点); // 递归
回溯,撤销处理结果
}2.广度优先搜索理论基础
广搜的使用场景:广搜的搜索方式就适合于解决两个点之间的最短路径问题。
广搜是从起点出发,以起始点为中心一圈一圈进行搜索,一旦遇到终点,记录之前走过的节点就是一条最短路。
实现:
仅仅需要一个容器,能保存我们要遍历过的元素就可以,那么用队列,还是用栈,甚至用数组,都是可以的。
用队列的话,就是保证每一圈都是一个方向去转,例如统一顺时针或者逆时针。
因为队列是先进先出,加入元素和弹出元素的顺序是没有改变的。
如果用栈的话,就是第一圈顺时针遍历,第二圈逆时针遍历,第三圈有顺时针遍历。
因为栈是先进后出,加入元素和弹出元素的顺序改变了。
广搜模板
用队列实现,向四个方向(上下左右)不断地扩展
java
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 表示四个方向
// grid 是地图,也就是一个二维数组
// visited标记访问过的节点,不要重复访问
// x,y 表示开始搜索节点的下标
void bfs(vector<vector<char>>& grid, vector<vector<bool>>& visited, int x, int y) {
// 定义队列
queue<pair<int, int>> que;
// 起始节点加入队列
que.push({x, y});
// 只要加入队列,立刻标记为访问过的节点
visited[x][y] = true;
// 开始遍历队列里的元素
while(!que.empty()) {
// 从队列取元素
pair<int ,int> cur = que.front(); que.pop();
int curx = cur.first;
// 当前节点坐标
int cury = cur.second;
// 开始想当前节点的四个方向左右上下去遍历
for (int i = 0; i < 4; i++) {
int nextx = curx + dir[i][0];
// 获取周边四个方向的坐标
int nexty = cury + dir[i][1];
// 坐标越界了,直接跳过
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue;
// 如果节点没被访问过
if (!visited[nextx][nexty]) {
// 队列添加该节点为下一轮要遍历的节点
que.push({nextx, nexty});
// 只要加入队列立刻标记,避免重复访问
visited[nextx][nexty] = true;
}
}
}
}