嵌入式八股文--P2 内存篇
目录
[嵌入式八股文篇--P2 内存篇](#嵌入式八股文篇--P2 内存篇)
[1. 内存分配有几种方式](#1. 内存分配有几种方式)
[2. 堆和栈有什么区别(申请方式、效率、方向)](#2. 堆和栈有什么区别(申请方式、效率、方向))
[7. 字节对齐问题](#7. 字节对齐问题)
[11. 在1G内存的计算机中能否malloc(1.2G)?为什么?](#11. 在1G内存的计算机中能否malloc(1.2G)?为什么?)
12.strcat、strncat、strcmp、strcpy哪些函数会导致内存溢出?如何改进
13.malloc、calloc、realloc内存申请函数
1. 内存分配有几种方式
程序运行时,内存按 "管理责任 + 生命周期" 分为 3 类,就像生活中 "不同场景的储物方式":
|----------|-----------------------------------------------------------|-----------------------------------------------------------------------------|
| 分配方式 | 技术细节 | 通俗类比(生活场景) |
| 栈上分配(自动) | 函数执行时自动为局部变量、参数分配内存;函数结束 "弹栈" 自动释放,空间小(几 MB)易溢出。 | 超市的 "临时储物柜":存东西(分配内存)时按流程开柜,取完(函数结束)柜子自动清空,柜子大小固定(不能放超大型物品)。 |
| 静态全局存储区 | 程序启动时为全局变量、静态变量分配内存;程序退出才释放,默认初始化为 0,生命周期和程序一致。 | 家里的 "固定衣柜":衣服(变量)从放进衣柜(程序启动)到搬家(程序退出)才拿走,衣柜空间固定,放进去的衣服不会自己消失。 |
| 堆上分配(手动) | 程序员用malloc/new 申请、free/delete 释放,空间大(GB 级)但需手动管理,易泄漏。 | 租的 "长期仓库":租仓库(申请内存)要自己找房东(写代码),用完必须主动退租(释放),不然仓库一直被占(内存泄漏),仓库大小可按需选(大中小都有)。 |
记忆总结词
"栈自弹,静随程,堆手动"
- 栈自弹:栈上内存随函数结束自动弹栈释放;
- 静随程:静态 / 全局变量内存随程序生命周期存在;
- 堆手动:堆上内存需程序员手动申请(
new/malloc)和释放(delete/free)。
2. 堆和栈有什么区别(申请方式、效率、方向)
堆和栈作为程序内存中两种关键的动态存储区域,在申请与释放机制 、空间大小限制 、内存增长方向 及操作效率上存在本质差异,具体对比如下:
|-----------|----------------------------------------------|--------------------------------------------------|----------------------------------------------------|
| 对比维度 | 栈(Stack) | 堆(Heap) | 通俗类比差异 |
| 申请 / 释放方式 | 系统自动管理:函数执行时分配,结束时自动释放,无需程序员干预。 | 程序员手动管理:malloc/new 申请,free/delete 释放,漏释放会泄漏。 | 栈 = 快递柜:取件后柜子自动关(释放);堆 = 储物间:租 / 退都要自己和房东沟通(手动操作)。 |
| 空间大小限制 | 固定且小(几 MB,如 Windows 1-2MB、Linux 8MB),超了会栈溢出。 | 灵活且大(理论上用系统大部分内存),仅受物理内存 + 虚拟内存限制。 | 栈 = 小快递柜(只能放小件);堆 = 大储物间(能放冰箱、衣柜等大件)。 |
| 内存增长方向 | 向低地址增长(从高地址往下 "叠" 数据),内存连续。 | 向高地址增长(从低地址往上 "堆" 数据),内存不连续(像散落的储物间)。 | 栈 = 从书架顶层往下放书(越放位置越靠下);堆 = 从书架底层往上放书(越放位置越靠上)。 |
| 操作效率 | 极快:仅修改栈指针(加减运算),无额外开销。 | 较慢:申请时要找空闲内存块(遍历链表),释放时要合并碎片,有额外操作。 | 栈 = 取快递:扫码直接开柜(1 秒搞定);堆 = 租储物间:要选位置、签合同(流程多,耗时间)。 |
记忆总结词
"栈自管、低增快、小且连;堆手动、高增慢、大且散"
- 栈自管、低增快、小且连:栈由系统自动管理,向低地址增长,效率快,空间小且连续;
- 堆手动、高增慢、大且散:堆需程序员手动管理,向高地址增长,效率慢,空间大且不连续。
题目:堆栈溢出一般是由什么原因导致的?(递归,动态申请内存,数组访问越界,指针非法访问)
堆栈溢出本质是 "储物区超出容量或乱翻别人的空间",具体场景对应生活中 "违规用储物空间" 的行为:
|-------------|---------------|----------------------------------------|------------------------------------------------------------|
| 操作行为 | 可能触发的溢出类型 | 技术原因 | 通俗类比 |
| 递归 | 栈溢出 | 递归调用时,每次都要在栈中保存调用现场 + 局部变量,层数太深会占满栈空间。 | 用临时快递柜存东西,一次存太多件(递归层数多),柜子全满了还想存,放不下就 "溢出"。 |
| 动态申请内存(未释放) | 堆内存耗尽(堆错误) | 堆内存申请后不释放,长期运行会占满堆空间,后续无法再申请。 | 租了储物间却一直不退,所有储物间都被占满,别人想租也租不到(堆耗尽)。 |
| 数组访问越界 | 栈溢出 / 堆溢出 | 局部数组(栈上)越界会踩栈中其他数据;动态数组(堆上)越界会踩堆中其他块。 | 自己的快递柜(栈)只租了 1 格,却硬往第 2 格塞东西(越界);或储物间(堆)只租 10㎡,却用到 15㎡的空间。 |
| 指针非法访问 | 栈溢出 / 堆溢出 | 指针指向栈 / 堆的非法地址,修改时会破坏栈 / 堆的管理结构。 | 拿着别人的快递柜钥匙(非法指针)开柜放东西,或乱翻别人的储物间,打乱了整体存储秩序。 |
3.栈在c语言中有什么作用
C 语言中的栈是 "函数运行的专属助手",就像 "厨师的操作台",支撑函数完成核心工作:
|----------|------------------------------------------------------|-------------------------------------------------|
| 作用维度 | 技术细节 | 通俗类比(厨师操作台) |
| 存储函数参数 | 函数调用时,实参按 "从右到左" 压栈,供函数读取(如add(a,b) 先压b 再压a )。 | 厨师做菜前,把食材(参数)按顺序摆到操作台上,方便后续取用。 |
| 存储函数局部变量 | 函数内的局部变量(如int x; )在栈上分配,函数结束自动释放,不会泄漏。 | 操作台上临时放的调料(局部变量),做完菜(函数结束)就收走,不会留在台上占空间。 |
| 保存函数调用现场 | 保存函数返回地址(函数结束后要回到的代码位置)和寄存器状态,确保能正确返回。 | 厨师做菜时,记下来下一步要做什么(返回地址),避免做完当前步骤后忘了后续流程。 |
| 支撑多线程编程 | 每个线程有专属栈,线程内函数的参数 / 变量存在自己的栈里,互不干扰。 | 餐厅里每个厨师有自己的操作台(线程栈),厨师 A 的食材不会和厨师 B 的混在一起,避免混乱。 |
记忆总结词
"函参局变栈中存,调用现场保返回;线程专属栈隔离,多线程行不混"
核心逻辑:栈为函数存储参数与局部变量、保障调用返回;为线程提供独立栈空间,支撑多线程安全运行。
4.c++的内存管理是怎样的
C++ 的虚拟内存像 "一栋分层的办公楼",每层有明确功能,管理方式各不同:
|----------|----------------------------------------------------|-----------|----------------|-------------------------------------------------------------------|
| 内存分区 | 存储内容 | 生命周期 | 管理方式 | 通俗类比(办公楼分层) |
| 代码段 | 机器指令(程序代码)、字符串常量(如"hello" ),只读不可改。 | 程序整个运行周期 | 操作系统自动管理 | 办公楼的 "机房":放服务器(指令)和只读文件(常量),只能看不能改,保障核心运行。 |
| 数据段 | 已初始化且非零的全局变量、静态变量(如int g=10; static int s=20; )。 | 程序整个运行周期 | 操作系统自动管理 | 办公楼的 "固定档案室":存长期用的重要文件(非零变量),从上班(程序启动)到下班(程序退出)都在。 |
| BSS 段 | 未初始化的全局 / 静态变量、初始化为 0 的全局 / 静态变量。 | 程序整个运行周期 | 操作系统自动管理 | 办公楼的 "空白档案室":存还没填写内容的文件(未初始化变量),上班时统一整理成空白文档(初始化为 0)。 |
| 堆 | 程序员用new/malloc 申请的动态内存,需手动delete/free 释放。 | 程序员控制 | 手动管理 | 办公楼的 "临时租赁办公室":要自己申请(租)、退租(释放),租期灵活(按需控制),但忘退租会一直占着。 |
| 共享区 | 动态链接库(如.so /.dll )、内存映射文件(如大文件映射)。 | 动态加载到程序退出 | 操作系统 + 程序员辅助管理 | 办公楼的 "共享会议室":多个部门(程序)可以共用,用完就释放,避免每个部门都建一个(减少冗余)。 |
| 栈 | 函数参数、局部变量、调用现场,函数结束自动释放。 | 函数执行周期 | 操作系统自动管理 | 办公楼的 "员工工位":员工(函数)上班(执行)时用,下班(结束)就空出来,工位大小固定(栈大小有限),东西放太多会满(栈溢出)。 |
C++ 内存管理的核心特点(对比 C 语言)
- C++ 风格管理 :用
new/delete替代malloc/free,能自动调用类的构造 / 析构函数(像租办公室时自动配家具 / 退租时自动清家具,C 语言要自己搬家具)。 - 智能指针 :
unique_ptr/shared_ptr等智能指针,能自动释放内存(像租办公室时找了个 "自动退租管家",不用自己记着退租,避免遗忘导致的 "内存泄漏")。
记忆总结词
"代读常、数初非零、BSS 零未初;堆手动、栈自动、共享映库;new/delete 配智能,内存管理不迷路"
核心逻辑:先记各分区存储内容,再区分 "自动管理(代码 / 数据 / BSS / 栈 / 共享区)" 与 "手动管理(堆)",最后结合智能指针保障安全性。
5.什么是内存泄漏
内存泄漏是程序内存管理中的典型错误,本质是动态申请的内存失去控制,无法回收并持续占用,长期运行会严重影响程序与系统稳定性,以下从核心概念、触发场景到危害进行详细拆解:
一、内存泄漏的核心定义
内存泄漏特指堆内存 (需程序员手动申请 / 释放的内存,如 new/malloc 分配的空间)的管理失效:程序通过 new(C++)、malloc(C/C++)等方式申请堆内存后,由于逻辑错误,导致两点关键问题同时发生:
- 该内存不再被程序使用(失去实际业务价值);
- 程序失去了指向该内存的所有指针(无法通过任何方式找到并释放它)。最终,这部分内存被 "闲置占用",既不能被程序复用,也无法被操作系统回收(直到程序退出),成为 "无效内存垃圾"。
通俗类比:就像你从仓库(堆)借了一个箱子(内存块),用过后没归还,还弄丢了箱子的位置标签(指针)------ 仓库管理员(操作系统)不知道箱子在哪,无法回收给别人用,箱子就一直占着仓库空间。
二、触发内存泄漏的典型场景
内存泄漏的根源是 "指针失控" 或 "释放逻辑缺失",常见场景可归纳为三类:
1. 申请后未释放(最直接的泄漏)
程序成功申请堆内存后,未在使用完毕时调用对应释放函数,导致内存长期占用。
C++ 场景:用 new 分配对象后未调用 delete,或用 new[] 分配数组后未调用 delete[](漏写 [] 会导致部分对象析构未执行,同样泄漏)。示例:cpp运行
void func() {
int* p = new int[100]; // 申请100个int的堆内存
// 业务逻辑使用p后,未写 delete[] p;
} // 函数结束后,指针p被销毁(栈上局部变量),堆内存100个int永久泄漏C/C++ 通用场景:用 malloc 分配内存后未调用 free,如 char* buf = (char*)malloc(1024); 后无 free(buf);。
2. 指针 "丢失指向"(间接泄漏)
申请内存后,指向该内存的指针被强制指向其他地址,导致原内存块 "失联",无法释放。
示例 1:指针被覆盖cpp运行
int* p = new int(10); // p指向堆内存A(存储10)
p = new int(20); // p被重新赋值,指向新堆内存B(存储20)
// 原内存A失去所有指针指向,无法释放,造成泄漏
delete p; // 仅释放了内存B,内存A永久泄漏示例 2:指针超出作用域(未传递释放责任)cpp运行
void createData() {
int* p = new int[50]; // 函数内申请堆内存
// 未将p传递给外部函数,也未在函数内释放
} // 函数结束,指针p(栈变量)被销毁,堆内存50个int泄漏3. 异常场景下的释放跳过(隐藏泄漏)
程序执行过程中触发异常(如 throw 抛出异常、数组越界导致崩溃前兆),导致原本计划执行的释放代码被跳过,内存未回收。
示例:cpp运行
void func() {
int* p = new int;
try {
int a = 10 / 0; // 触发除零异常,直接跳转到catch块
delete p; // 这行代码永远不会执行,p指向的内存泄漏
} catch (...) {
// 未在catch中补充释放逻辑
}
}三、内存泄漏的核心影响
内存泄漏的危害具有 "累积性"------ 短期运行的程序(如执行几秒就退出的工具类程序)可能无明显异常,但长期运行的程序(如服务器、后台服务、嵌入式设备程序)会逐渐暴露严重问题:
1. 程序自身性能退化
随着泄漏的内存不断累积,程序占用的物理内存会持续上升(可通过任务管理器 /top 命令观察):
内存占用过高会导致操作系统频繁触发 "页面置换"(将部分内存数据写入磁盘交换区),程序读写数据的速度大幅下降,出现卡顿、响应延迟(如服务器接口超时)。
2. 系统资源耗尽,程序崩溃
当泄漏的内存总量超过系统可用物理内存与虚拟内存上限时:
- 程序后续再调用
new/malloc申请内存时会失败(C++ 抛出bad_alloc异常,C 语言返回NULL); - 若程序未处理内存分配失败的场景,会直接崩溃(如服务器进程意外退出),导致业务中断。
3. 影响其他进程,引发系统不稳定
若泄漏程序是系统级进程(如操作系统服务),其持续占用内存会挤压其他进程的内存空间:
- 其他正常程序可能因无法申请到足够内存而运行异常(如办公软件闪退、浏览器卡死);
- 极端情况下,整个操作系统会因内存耗尽而出现 "假死",需强制重启才能恢复。
四、记忆总结词
"堆存申请未释放,指针失联找不着;内存越用越膨胀,程序卡顿终崩溃"
核心逻辑:内存泄漏只针对堆内存,因 "未释放" 或 "指针丢" 导致,危害随运行时间累积,最终引发程序 / 系统问题。
6.如何判断内存泄漏(如何减少内存泄漏)
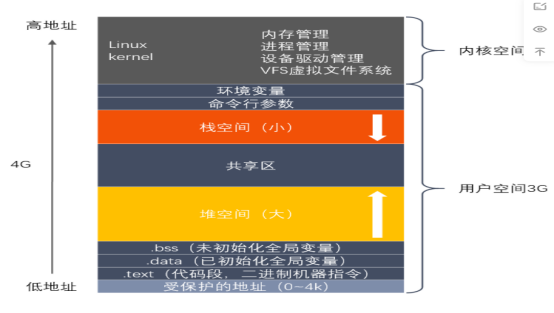
一、如何判断内存泄漏
- 直观观察 :借助系统任务管理器(如 Windows 任务管理器、Linux 的
top命令),查看程序运行时内存占用是否持续攀升且无回落。若像气球持续充气般只胀不缩,大概率存在内存泄漏。 - 代码审查 :逐行检查代码中内存分配(如
malloc、new)与释放(如free、delete)逻辑,看是否有 "只借不还" 的情况,如同借了东西却不归还,东西就一直被占用。 - 工具检测:利用 Valgrind(Linux)、Visual Leak Detector(Windows)等专业工具,它们像 "内存侦探",能精准定位未释放的内存块,揪出泄漏源头。
二、如何减少内存泄漏
- 规范编码:内存分配后,及时用对应函数释放,就像借了工具用完立刻归还,保证 "有借有还"。
- 链表管理指针:把分配的内存指针记录在链表中,使用后从链表删除,程序结束时检查链表,若有剩余则说明内存泄漏,好比用清单管理借出的物品,清单空了才代表都归还了。
- 使用智能指针 :C++ 的智能指针(如
unique_ptr、shared_ptr)如同 "自动归还的智能借物器",对象生命周期结束时自动释放内存,无需手动操作。 - 借助检测插件:使用 ccmalloc 等插件,它们像 "内存泄漏警报器",实时监测内存使用,及时预警泄漏问题。
总结词
"观察代码加工具,揪出泄漏好思路;编码规范管指针,智能插件来辅助,内存不再被'私吞'"
7. 字节对齐问题
一、什么是字节对齐?
字节对齐是指程序中的各种数据类型(如int、double,以及结构体、联合体等复合类型)在内存中存储时,并非简单按顺序连续排列,而是需要遵循特定的位置规则------ 数据的起始地址必须是其 "对齐值"(通常是自身大小或系统默认值)的整数倍。
最典型的场景是结构体大小计算 :例如定义struct Data { char a; int b; };,若不考虑对齐,理论大小应为1 + 4 = 5字节,但实际在 32 位系统中,b会从第 4 个字节开始存储(而非第 2 个),结构体总大小为 8 字节(中间填充了 3 个 "空字节"),这就是字节对齐的结果。
二、为什么需要字节对齐?
核心原因是提升 CPU 访问内存的效率,这与硬件的底层设计密切相关:
- CPU 的内存访问特性:CPU 读取内存时,并非按单个字节逐个读取,而是以 "块" 为单位(如 32 位 CPU 每次读取 4 字节,64 位 CPU 每次读取 8 字节)。若数据恰好完整存放在一个 "块" 内,CPU 一次就能读取完毕;若数据跨两个 "块"(未对齐),CPU 需要读取两次,再拼接数据,效率会降低。
- 硬件限制:部分硬件架构(如某些嵌入式处理器)甚至不支持 "非对齐访问",强行读取未对齐的数据会直接触发硬件错误(如程序崩溃)。
通俗类比 :把内存想象成按 "4 格一组" 排列的储物柜(类似 32 位 CPU 的 4 字节访问块)。若要存放一个 "4 格大的箱子"(int类型):
- 对齐存放:箱子正好放进一组储物柜(占 1-4 格),一次就能取走;
- 未对齐存放:箱子跨两组储物柜(占 3-6 格),需要先打开第 1 组取 3-4 格,再打开第 2 组取 5-6 格,最后拼起来,既麻烦又耗时。
字节对齐就是让 "箱子"(数据)都规矩地放进完整的 "储物柜组"(内存块),减少 CPU 的 "搬运拼接" 工作。
记忆总结词
"数据存储按规排,起始地址倍数来;CPU 块读效率高,硬件兼容不崩坏"
核心逻辑:字节对齐是数据按规则存储的方式,根本目的是提升 CPU 访问效率并兼容硬件限制。
8.C语言函数参数压栈顺序是怎样的
在 C 语言中,函数参数的压栈顺序遵循 "从右向左" 的规则,这一机制与栈的内存扩展方向密切相关,共同决定了参数在内存中的存储布局。
压栈顺序与内存布局
- 压栈顺序 :当调用函数时,参数会按照 "从右到左" 的顺序依次被压入栈中。例如调用
func(a, b, c)时,压栈顺序是c先入栈,然后是b,最后是a。 - 与栈扩展方向的关系:栈在内存中是从高地址向低地址扩展的。因此,先入栈的右参数会占据更高的内存地址,后入栈的左参数则位于较低的内存地址。
- 访问方式 :函数内部通过栈指针偏移来访问参数,由于左参数位于栈的较低位置,更容易通过固定偏移量访问,这为实现可变参数函数(如
printf)提供了便利。
典型例子 :printf 函数
printf函数的参数处理是压栈顺序的经典体现:
printf("%d, %d, %d", 10, 20, 30);调用时,参数按30→20→10→格式字符串的顺序入栈。虽然参数从右向左入栈,但printf通过格式字符串从左到右解析,最终正确输出10, 20, 30,这正是对从右向左压栈机制的巧妙运用。
记忆总结词
"右先压,地址高,左后入,偏移找"
- 右先压:参数从右向左依次入栈
- 地址高:先入栈的右参数位于更高内存地址
- 左后入:左参数后入栈,位于较低内存地址
- 偏移找:函数通过栈指针偏移访问参数
9.C++如何处理返回值
C++ 处理返回值的逻辑,本质是 "根据数据类型和使用场景,选择最高效的'传递方式'"。我们用生活中 "传递物品" 的场景类比,就能轻松理解不同返回机制的差异:
一、基本数据类型返回(int/float/char 等):用 "寄存器传小物件"
核心逻辑: 基本数据类型体积小(如 int 占 4 字节),直接存入 CPU 的专用寄存器(如 x86 架构的 EAX 寄存器),调用者从寄存器中读取,无需额外内存开销。
通俗类比 : 你在便利店(函数 add**)买一瓶可乐(返回值** 8**),店员不用找袋子装,直接把可乐递给你(存入寄存器);你(** main****函数)接过就能喝(赋值给 result**),全程快速无多余步骤。**
代码示例解析
cpp
int add(int a, int b) {
return a + b; // 计算结果8存入EAX寄存器
}
int main() {
int result = add(3, 5); // 从EAX寄存器读取8,赋值给result
return 0;
}关键优势:效率最高,无内存拷贝,直接通过硬件寄存器传递。
二、复杂数据类型返回(类对象):从 "多次拷贝" 到 "优化省成本"
类对象体积可能很大(如含动态数组、多个成员变量),返回时的核心问题是 "如何避免重复拷贝导致的性能浪费",分为 "未优化" 和 "优化" 两种情况:
1. 未优化情况:"多次打包传递"(两次拷贝构造)
核心逻辑: 函数内创建的对象(如obj),不能直接返回给调用者,需先拷贝到临时对象 (中间载体),再从临时对象拷贝到调用者的接收对象(如result),两次触发拷贝构造函数。
通俗类比
你在蛋糕店(函数 createObject**)订了一个定制蛋糕(** obj**):**
- 店员先把蛋糕放进 "临时包装盒"(临时对象),第一次打包(第一次拷贝构造);
- 你拿到临时包装盒后,再把蛋糕倒进自己的 "家用保鲜盒"( result**),第二次打包(第二次拷贝构造);**
- 两次打包不仅费时间(性能开销),还浪费包装材料(临时内存)。
代码示例解析
cpp
class MyClass {
public:
MyClass(const MyClass& other) {
std::cout << "Copy constructor called" << std::endl; // 拷贝构造触发时打印
}
};
MyClass createObject() {
MyClass obj(10); // 第一步:创建函数内对象obj
return obj; // 第二步:拷贝obj到临时对象(第一次打印)
}
int main() {
MyClass result = createObject(); // 第三步:拷贝临时对象到result(第二次打印)
return 0;
}
// 输出:两次"Copy constructor called"2. 编译器优化(RVO/NRVO):"直接原地制作"(零拷贝)
核心逻辑: 现代编译器(如 GCC、Clang)会通过返回值优化(RVO) 或命名返回值优化(NRVO),跳过临时对象,直接在 "调用者的接收对象内存空间" 中构造函数内的对象,彻底避免拷贝。
- RVO:针对 "直接返回临时对象"(如
return MyClass(10)); - NRVO:针对 "返回函数内已命名的对象"(如
return obj)。
通俗类比
还是订蛋糕,但店员知道你会用 "家用保鲜盒"( result**):**
- 直接把你的保鲜盒拿到后厨,在保鲜盒里直接制作蛋糕(直接在 result****的内存中构造对象);
- 省去临时包装盒和两次打包,一步到位,零浪费。
代码示例解析(RVO 情况)
cpp
MyClass createObject() {
return MyClass(10); // 编译器直接在result的内存中构造对象,无临时对象
}
int main() {
MyClass result = createObject(); // 无拷贝,直接使用构造好的result
return 0;
}
// 输出:无"Copy constructor called"(零拷贝)3. 移动语义(std::move):"转让所有权"(一次移动,替代拷贝)
核心逻辑: C++11 引入移动语义 ,当函数内的对象(如str)即将被销毁(函数结束后生命周期结束)时,用std::move标记它为 "可移动的右值",此时返回的不是 "拷贝对象内容",而是 "转让对象的资源所有权"(如动态数组的地址),仅需修改指针指向,无需拷贝数据。
通俗类比: 你买了一杯未开封的奶茶( str**),但临时有事要离开:**
- 你不需要把奶茶里的液体倒到另一个杯子里(拷贝),而是直接把整杯奶茶(资源所有权)送给朋友( result**);**
- 朋友拿到后直接喝,你不再拥有这杯奶茶( str****被置为 "空状态",但不会触发析构释放资源),一步完成传递,无浪费。
代码示例解析
cpp
#include <utility> // std::move所在头文件
#include <string>
std::string createString() {
std::string str = "Hello"; // str含动态分配的字符数组(资源)
return std::move(str); // 转让str的资源所有权给返回值,无拷贝
}
int main() {
std::string result = createString(); // 接收资源,无需拷贝
return 0;
}关键区别:拷贝是 "复制内容",移动是 "转移资源",前者时间复杂度 O (n),后者 O (1)(仅改指针)。
三、返回指针或引用:"传递地址 / 位置"(避免对象重构)
当返回的对象生命周期较长(如动态分配内存、类的成员变量)时,返回 "指针" 或 "引用",本质是 "传递对象的地址 / 位置",而非对象本身,彻底避免拷贝。
1. 返回指针:"传递仓库地址"(需手动管理内存)
核心逻辑: 函数内通过new动态分配内存(如数组arr),返回该内存的地址(指针) ,调用者通过指针访问对象;但需注意:必须手动delete释放内存,否则会内存泄漏。
通俗类比: 你租了一个仓库(动态内存),存放一批货物(数组 arr**):**
- 仓库管理员(函数 createArray**)把 "仓库地址"(指针** arr**)写给你,你不用搬货物(拷贝数组),直接按地址去仓库取货(访问** ptr[i]****);
- 但你用完后必须主动退租( delete[] ptr**),否则仓库会一直被你占用(内存泄漏)。**
代码示例解析
cpp
int* createArray() {
int* arr = new int[5]; // 动态分配5个int的内存(仓库)
for (int i = 0; i < 5; i++) arr[i] = i; // 往仓库放货物
return arr; // 返回仓库地址(指针)
}
int main() {
int* ptr = createArray(); // 拿到仓库地址,访问货物(ptr[0]~ptr[4])
delete[] ptr; // 退租(释放内存),避免泄漏
return 0;
}关键风险:不能返回 "函数内局部变量的指针"(如int a; return &a;),因为局部变量在函数结束后会被销毁,指针变成 "野指针"(指向无效内存)。
2. 返回引用:"传递具体位置"(安全无野指针风险)
核心逻辑: 返回 "已存在且生命周期足够长的对象" 的引用(如类的成员变量data),调用者通过引用直接访问原对象,无需拷贝;且引用必须绑定到 "存活的对象"(如obj未被销毁),不会像指针那样成为野指针。
通俗类比
你去朋友家( obj**)借东西,朋友不用把东西递给你(拷贝),而是告诉你:"东西在客厅茶几的第一个抽屉里"(引用** data**);**
- 你按位置直接取( ref = 20**),修改的是原东西(** obj.data****变成 20);
- 只要朋友家没拆( obj****存活),这个位置就一直有效(引用安全)。
代码示例解析
cpp
class MyClass {
private:
int data; // 类的成员变量,生命周期与obj一致
public:
int& getData() { return data; } // 返回data的引用(位置)
};
int main() {
MyClass obj(10); // obj存活期间,data一直有效
int& ref = obj.getData(); // 绑定data的位置,无拷贝
ref = 20; // 直接修改obj.data,变成20
return 0;
}常见场景:类的成员函数返回成员变量(如getData)、返回全局变量 / 静态变量的引用(生命周期与程序一致)。
四、总结:返回值处理的核心逻辑(结合类比记忆)
用一句通俗的话概括:"小物件直接递(基本类型→寄存器),大物件少打包(类对象→优化 / RVO),地址位置省成本(指针 / 引用→无拷贝)",对应官方总结词的拆解:
|-----------|-------------------------------------|
| 总结词片段 | 通俗解读 |
| 基类返值各不同 | 基本类型(小物件)和类对象(大物件)的传递方式不同,按需选择 |
| 基本寄存对象拷 | 基本类型用寄存器传递,未优化的类对象需多次拷贝(多次打包) |
| 优化移动省开销 | RVO/NRVO(直接原地制作)和移动语义(转让所有权),减少拷贝开销 |
| 指针引用避重造 | 返回指针(仓库地址)或引用(具体位置),避免对象重复构造(重复制作) |
通过类比,能快速记住不同返回方式的适用场景和核心风险(如指针需手动释放、引用需绑定有效对象),在实际开发中根据性能需求和安全性选择合适的返回方式。
10.栈的空间值最大是多少
栈空间大小在不同操作系统和编译环境下会有所差异,它对程序中函数调用深度、局部变量的存储等有着重要影响。以下为你详细介绍:
不同操作系统下栈空间的常见默认值
- Windows 系统:在 Visual C++ 等常见开发环境中,栈空间的默认大小一般是 1MB 到 2MB。不过,这个值可以在项目的属性设置中进行调整。比如在 Visual Studio 里,通过配置链接器选项中的 "堆栈保留大小" 来修改栈空间的初始值。
- Linux 系统 :默认栈空间大小通常是 8MB ,但这也并非固定不变。可以使用
ulimit -s命令查看当前用户进程的栈空间大小限制, 并且可以通过ulimit -s <新大小>(单位是 KB)的方式临时修改栈空间大小,如ulimit -s 16384可将栈空间大小设置为 16MB。如果希望永久修改,对于使用 bash 作为默认 shell 的系统,可在.bashrc或.bash_profile文件中添加ulimit -s <目标大小>。
影响栈空间大小设置的因素
- 程序需求:如果程序中存在深度递归调用,或者需要定义大量的局部变量(比如大数组),就需要更大的栈空间,否则容易导致栈溢出错误。例如,一个进行复杂树状结构遍历的递归算法,如果栈空间过小,可能在遍历到较深层节点时,就因为栈空间不足而崩溃。
- 系统资源:增大栈空间会占用更多的内存资源,在服务器等对内存资源要求较高的环境中,若每个进程都分配过大的栈空间,可能导致系统内存不足,影响其他进程的正常运行。所以,系统管理员需要在满足程序需求的前提下,合理设置栈空间大小,以平衡资源利用。
栈空间大小对程序的影响
- 栈溢出风险:当程序实际需要的栈空间超过了系统设置的最大值时,就会发生栈溢出,导致程序崩溃。比如在一个递归函数中,没有正确设置终止条件,随着递归层数不断增加,栈空间被持续占用,最终超出限制引发栈溢出。
- 局部变量存储 :栈空间大小决定了函数中能够定义的局部变量的最大数量和大小。如果栈空间较小,就无法定义过大的局部数组,否则也会导致栈空间不足。例如,在一个函数中试图定义
int arr[10000000];这样一个超大数组,若栈空间不够大,就会出现问题。
总结词
"栈空大小各不同,Win 一到二 Linux 八,按需调整避溢出,资源平衡要兼顾"
- 栈空大小各不同:栈空间大小在不同操作系统下存在差异。
- Win 一到二 Linux 八:Windows 默认栈空间通常在 1MB 到 2MB,Linux 默认一般是 8MB。
- 按需调整避溢出:根据程序需求合理调整栈空间大小,避免出现栈溢出错误。
- 资源平衡要兼顾:调整栈空间大小时要兼顾系统资源的合理分配 。
11. 在1G内存的计算机中能否malloc(1.2G)?为什么?
在 1G 物理内存的计算机中,有可能成功执行 malloc(1.2G),核心原因在于现代操作系统的 "虚拟内存" 机制,使得程序申请的内存与实际物理内存之间没有直接绑定关系。
关键原理:虚拟内存与物理内存的分离
- malloc 的本质 :
malloc函数向操作系统申请的是虚拟内存地址空间,而非直接直接分配物理内存。操作系统会为每个进程分配独立的虚拟地址空间(如 32 位系统通常为 4GB),这个空间远实际受限于物理内存大小。 - 物理内存的延迟分配 :即使虚拟内存申请成功,操作系统也不会立即分配对应的物理内存,而是在程序实际访问该内存时(如写入数据),才通过 "页面置换" 机制从物理内存或磁盘交换区中分配实际存储空间。
具体场景分析
- 申请成功的可能 :若进程的虚拟地址空间尚有 1.2G 空闲(32 位系统虚拟地址空间足够),
malloc(1.2G)会返回有效指针(表示虚拟内存申请成功)。此时时仅占用了少量量物理内存用于记录虚拟地址映射关系,而非 1.2G 实际物理内存。 - 实际使用的限制 :若程序后续真的要写入 1.2G 数据,当物理内存(1G)+ 磁盘交换区的总容量不足 1.2G 时,会触发 "内存分配失败"(如 C 语言返回
NULL,C++ 抛出bad_alloc异常)。
通俗类比
把虚拟内存比作一本 "无限页的笔记本"(虚拟地址空间),物理内存是 "桌面"(1G 大小),磁盘交换区是 "抽屉"。 **malloc(1.2G)**相当于在笔记本上 "预留 120 页空白纸"------ 这一步只需在目录上做记录(不占用桌面空间),完全可行;但当你真的要在这 120 页上写内容时,若桌面 + 抽屉放不下 120 页纸,就会无法继续书写(实际分配失败)。
总结词
"malloc 申虚拟,物理延迟给;1G 物理存,1.2G 虚拟可申请,真用才看总空间"
核心逻辑:malloc申请的是虚拟内存,与物理内存直接大小无关,能否最终使用取决于物理内存 + 交换区的总容量。
12.strcat、strncat、strcmp、strcpy哪些函数会导致内存溢出?如何改进
在 C 语言字符串处理函数中,部分函数因缺乏边界检查机制,容易导致内存溢出。以下是具体分析:
可能内存溢出风险的函数
- strcat:字符串拼接函数
- 风险:
strcat(dest, src)会将src字符串追加到dest末尾,但不检查 dest****的剩余空间是否足够 。如果dest容量不足,会越界写入后续内存,导致溢出。 - 示例:
char buf[5] = "abc"; strcat(buf, "def");,buf仅能容纳 5 字节(含结束符),拼接后需要 7 字节,必然溢出。
- strcmp:字符串比较函数
- 风险:
strcmp(s1, s2)通过寻找'\0'判断字符串结束,若比较的字符串未正确包含结束符(如未初始化的字符数组),会持续访问超出边界的内存,导致未定义行为(可能触发溢出)。
- strcpy:字符串复制函数
- 风险:
strcpy(dest, src)将src完整复制到dest,包括结束符,但不检查 dest****的容量是否大于 src。若src长度超过dest,会越界写入,导致溢出。 - 示例:
char buf[5]; strcpy(buf, "hello world");,源字符串长度 11,目标仅 5 字节,直接溢出。
相对安全的函数
strncat:带长度限制的拼接函数
strncat(dest, src, n)会最多复制n个字符(实际复制n和src长度的较小值),并自动添加结束符,只要 n****设置合理(不超过 dest****剩余空间),可避免溢出。- 注意:需确保
dest原有长度 +n+ 1(结束符)≤dest总容量。
改进方案
- 使用带长度限制的安全函数
- 用
strncpy替代strcpy:strncpy(dest, src, size-1); dest[size-1] = '\0';(手动确保结束符) - 用
strncmp替代strcmp:strncmp(s1, s2, n)(限制比较的最大长度n) - 坚持使用
strncat,并严格计算目标缓冲区剩余空间。
- 提前计算字符串长度
操作前用strlen获取源字符串长度,确保目标缓冲区足够:c运行
if (strlen(src) + 1 <= dest_size) {
strcpy(dest, src); // 确认安全后再使用
}- 使用 C11 标准的安全函数
如strcpy_s、strcat_s等(需定义__STDC_WANT_LIB_EXT1__),这些函数强制要求传入目标缓冲区大小,内部会做边界检查,溢出时返回错误码。
- 采用动态内存分配
根据源字符串长度动态分配足够的目标内存:c运行
char* dest = malloc(strlen(src) + 1);
if (dest) strcpy(dest, src); // 确保分配成功后再复制记忆总结词
"strcat/cpy 无边界,溢出风险常相伴;n 开头加限制,安全函数记心间,长度检查是关键"
核心逻辑:strcat、strcpy和未正确使用的strcmp有溢出风险,应使用带长度限制的函数并做好边界检查。
13.malloc、calloc、realloc内存申请函数
在 C 语言中,malloc、calloc、realloc是用于堆内存管理的核心函数,它们在内存分配方式、初始化行为和功能侧重上各有特点,共同支撑动态内存的灵活使用。
一、函数功能与核心差异
|-------------------------------------------|--------------------------------------------|---------------------------------------------------------------------|--------------------------|
| 函数原型 | 功能描述 | 关键特性 | 典型场景 |
| void *malloc(size_t size) | 申请size 字节的连续堆内存 | 1. 内存未初始化(内容为随机值)2. 仅需指定总字节数3. size=0 时返回NULL 或可释放的独特指针 | 通用内存分配(如动态数组、结构体) |
| void *calloc(size_t nmemb, size_t size) | 申请nmemb 个块,每块size 字节(总大小nmemb×size ) | 1. 内存自动初始化为 02. 需要指定块数量和单块大小3. 本质是 "分配 + 清零" 的组合操作 | 需要初始化为 0 的场景(如统计数组、链表节点) |
| void *realloc(void *ptr, size_t size) | 调整ptr 指向的内存块大小为size 字节 | 1. 可扩大或缩小已有内存块2. 可能原地扩容或迁移数据(见下文详解)3. ptr=NULL 时等价于malloc(size) | 动态调整内存大小(如数组扩容、缓冲区收缩) |
二、关键特性深度解析
1. malloc**:基础内存分配**
未初始化特性 :分配的内存保留原内存空间的随机值(如之前释放的垃圾数据),使用前需手动初始化(如memset),否则可能读取到脏数据。示例:c
int* p = (int*)malloc(10 * sizeof(int));
if (p != NULL) {
memset(p, 0, 10 * sizeof(int)); // 手动清零,避免脏数据
}返回值处理 :成功返回指向内存块的指针,失败返回NULL,必须检查返回值避免野指针。
2. calloc**:带清零的分配**
自动初始化 :分配后内存被自动置为 0,省去手动初始化步骤,适合对初始值有要求的场景。示例:c
// 分配10个int(40字节),并自动清零
int* arr = (int*)calloc(10, sizeof(int));
// 此时arr[0]~arr[9]均为0,无需额外初始化与 malloc****的关系 :calloc(n, s)等价于malloc(n×s) + memset(..., 0, n×s),但calloc效率可能更高(部分系统直接分配零页内存)。
3. realloc**:内存大小调整(最复杂)**
realloc的核心逻辑是 "尝试以最小代价调整内存大小",行为分三种情况:
(1)扩大内存(size > 原大小)
-
原地扩容:若原内存块后续有足够连续空间,直接在原地址后追加内存,返回原指针(高效,无数据拷贝)。
-
迁移扩容 :若后续空间不足,在新地址分配
size字节内存,拷贝原数据到新地址,释放原内存,返回新指针(有数据拷贝开销)。示例:cint* p = (int*)malloc(100); // 原大小100字节
int* new_p = (int*)realloc(p, 200); // 尝试扩至200字节
if (new_p != NULL) {
p = new_p; // 若地址变更,更新指针
}
(2)缩小内存(size < 原大小)
直接截断原内存块,仅保留前size字节,释放超出部分,返回原指针(地址不变)。示例:c
int* p = (int*)malloc(100); // 原大小100字节
p = (int*)realloc(p, 50); // 缩小至50字节,地址不变(3)特殊情况
ptr = NULL:等价于malloc(size),直接分配size字节新内存。size = 0:等价于free(ptr),释放内存并返回NULL(部分实现)。
4. 共性注意事项
- 释放内存 :三者分配的内存均需用
free释放(realloc迁移时会自动释放原内存),否则导致内存泄漏。 - 类型转换 :返回
void*,需强制转换为目标类型指针(如(int*)malloc(...))。 - 对齐保证 :分配的内存满足任何基本类型的对齐要求,可安全存储
int、double等数据。
三、通俗类比理解
- malloc**:像租一个未装修的空房间,里面可能有前任租客留下的杂物(随机数据),需要自己清理(手动初始化)。**
- calloc**:像租一个全新装修的空房间,房东已提前打扫干净(自动清零),可直接入住。**
- realloc**:像调整租房面积 ------ 若隔壁房间空着,直接打通扩容(原地调整);若隔壁有人,就搬到一个更大的新房间,并把旧家具搬过去(迁移扩容)。**
总结词
"malloc 未初始化,calloc 清零行;realloc 调大小,原地迁移看情形,用完记得 free 清"
核心逻辑:三者均用于堆内存分配,calloc带清零,realloc可调整大小,共同需注意内存释放与指针安全。
