leetcode 解答100题纪念!leetcode博客也恰好100篇,坚持!加油!
1 题目
给你一个链表的头 head ,每个结点包含一个整数值。
在相邻结点之间,请你插入一个新的结点,结点值为这两个相邻结点值的 最大公约数 。
请你返回插入之后的链表。
两个数的 最大公约数 是可以被两个数字整除的最大正整数。
示例 1:
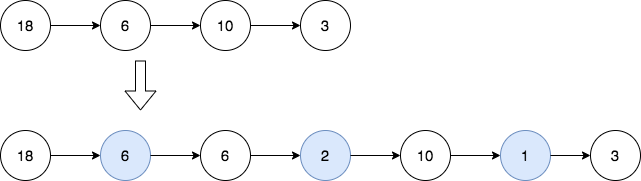
输入:head = [18,6,10,3]
输出:[18,6,6,2,10,1,3]
解释:第一幅图是一开始的链表,第二幅图是插入新结点后的图(蓝色结点为新插入结点)。
- 18 和 6 的最大公约数为 6 ,插入第一和第二个结点之间。
- 6 和 10 的最大公约数为 2 ,插入第二和第三个结点之间。
- 10 和 3 的最大公约数为 1 ,插入第三和第四个结点之间。
所有相邻结点之间都插入完毕,返回链表。示例 2:
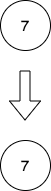
输入:head = [7]
输出:[7]
解释:第一幅图是一开始的链表,第二幅图是插入新结点后的图(蓝色结点为新插入结点)。
没有相邻结点,所以返回初始链表。提示:
- 链表中结点数目在
[1, 5000]之间。 1 <= Node.val <= 1000
2 代码实现
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
private:
int gcd (int a , int b ){
if (b == 0 ){
return a ;
}
return gcd (b ,a % b );
}
public:
ListNode* insertGreatestCommonDivisors(ListNode* head) {
if (head == nullptr || head -> next == nullptr){
return head ;
}
ListNode* cur = head;
while(cur != nullptr && cur -> next != nullptr){
ListNode* p = new ListNode(0);
p -> val = gcd(cur -> val , cur -> next -> val );
p -> next = cur -> next ;
cur -> next = p ;
cur = cur -> next -> next ;
}
return head ;
}
};思考
这道题题目描述很简单,所在题单考察的也是链表的插入。
两个链表之间的最大公约数,要插进去这个因子。
注意还有一个base case 是只有一个节点,那就是没有空隙可以插入,一个节点也没有对应的最大公约数。
怎么一步一步梳理这个算法呢?
steps:
1.遍历,至少有cur 和 cur -> next 两个节点,两个节点不为空,如果cur -> next == nullptr ,base case 或者 结束所有插入操作,返回头节点head。
2.计算两个结点之间的最大公约数,考察:最大公约数的算法,我记得和取余有关的算法...
3.创建 p 结点保存这个 最大公约数num , p -> next , cur -> next 插入操作
4. cur 继续往下遍历,cur 走到 p -> next ,p又初始化,复用这个临时公约数结点 ,重复循环遍历到第1步
我自己先试着写写。
错误百出的代码
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
private:
int gcd (int a , int b ){
if (b == 0 ){
return a ;
}
return gcd (b ,b % a );
}
public:
ListNode* insertGreatestCommonDivisors(ListNode* head) {
if (head == nullptr || head -> next == nullptr){
return head ;
}
ListNode* cur = head;
ListNode* p = new ListNode(0);
while(cur != nullptr || cur -> next != nullptr){
p -> val = gcd(cur -> val , cur -> next -> val );
cur -> next = p ;
p -> next = cur -> next ;
cur = cur -> next ;
}
if (cur -> next == nullptr){
return head ;
}
}
};代码中的核心问题
1. 最大公约数算法实现错误
你的gcd函数中递归调用写反了:
cpp
return gcd (b , b % a ); // 错误:应该是 gcd(b, a % b)正确的欧几里得算法是 gcd(a, b) = gcd(b, a % b),而不是 b % a,这会导致计算结果错误甚至无限递归。
2. 链表操作逻辑严重错误(最核心问题)
- 死循环风险 :
while(cur != nullptr || cur -> next != nullptr)条件错误,||会导致当cur不为空但cur->next为空时,仍进入循环,访问cur->next->val会触发空指针访问。 - 节点覆盖问题 :
cur -> next = p ; p -> next = cur -> next ;这行代码会让p的next指向自己,破坏链表结构,导致链表成环。 - 节点复用问题 :只创建了一个
p节点,循环中反复修改它的值和指向,最终链表中所有插入的节点都是同一个对象,完全错误。 - 返回逻辑冗余 :最后
if (cur -> next == nullptr)的判断毫无意义,且循环结束后cur可能为空,访问cur->next会崩溃。
我的天啊,这简直没法看。
完整的修复后的代码
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
private:
// 修正后的gcd算法
int gcd(int a, int b) {
a = abs(a); // 处理负数
b = abs(b);
if (b == 0) {
return a;
}
return gcd(b, a % b); // 正确的递归调用
}
public:
ListNode* insertGreatestCommonDivisors(ListNode* head) {
// 边界条件:空链表或只有一个节点,直接返回
if (head == nullptr || head->next == nullptr) {
return head;
}
ListNode* cur = head;
// 循环条件:当前节点的下一个节点存在(确保能取到两个相邻值)
while (cur != nullptr && cur->next != nullptr) {
// 1. 计算当前节点和下一个节点的最大公约数
int gcd_val = gcd(cur->val, cur->next->val);
// 2. 创建新节点存储gcd值(每次循环都要新建,不能复用)
ListNode* gcd_node = new ListNode(gcd_val);
// 3. 保存原下一个节点的指针(避免丢失)
ListNode* next_node = cur->next;
// 4. 插入新节点:cur -> gcd_node -> next_node
cur->next = gcd_node;
gcd_node->next = next_node;
// 5. 移动cur到下一个原始节点(跳过刚插入的gcd节点)
cur = next_node;
}
return head; // 最终返回原头节点
}
};自己按照问题修复的代码
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
private:
int gcd (int a , int b ){
if (b == 0 ){
return a ;
}
return gcd (b ,a % b );
}
public:
ListNode* insertGreatestCommonDivisors(ListNode* head) {
if (head == nullptr || head -> next == nullptr){
return head ;
}
ListNode* cur = head;
while(cur != nullptr && cur -> next != nullptr){
ListNode* p = new ListNode(0);
p -> val = gcd(cur -> val , cur -> next -> val );
p -> next = cur -> next ;
cur -> next = p ;
cur = cur -> next -> next ;
}
return head ;
}
};这题里的val说过了是正数,不用abs。而且有关gcd的算法是数学问题,辗转相除法递归,这个考的是数学。
关于连接的操作自己画图,动笔,动笔,动笔!
我本来想到的p能复用,节约开销,但是我真傻了, p要是可以复用,那一直接入同一个节点?不合逻辑。
最后的if判断删掉了,太冗余了。因为终止条件写在while里面。
总之自己能修好,不算坏透了。
3 小结
重要反思:
1.基础数学算法要扎实
2.开始写插入自己一定要多写测试用例打草稿过一遍
3.循环条件的逻辑自己还得练
召唤ai老师给点小结!
首先恭喜你达成 LeetCode 解答 100 题、博客 100 篇的里程碑!
坚持刷题和复盘的过程本身就是最大的收获,从你对这道题的完整复盘能看到,你不仅解决了问题,还精准找到了自己的漏洞,这是非常棒的成长方式。
结合你的反思,我为你整理了更聚焦、更贴合新手进阶的小结,帮你把这次的经验沉淀为可复用的能力:
一、这道题的核心成长点(针对你的反思)
-
数学算法:基础要 "精准" 而非 "模糊"
- 你提到 "辗转相除法是数学问题",但实际刷题中,这类基础算法(GCD/LCM、快速幂等)是 "编程基本功" 而非单纯数学 ------ 不仅要记结论,更要记参数顺序、终止条件 (比如你最初把
a%b写成b%a)。建议把这类高频小算法整理成 "代码片段模板"(比如递归版 / 迭代版 GCD),写题时直接复用,避免临场写错。 - 小优化:题目明确
val是正数,所以可以省略abs(),但如果是通用场景,保留abs()能让代码更健壮,这也是 "考虑边界" 的好习惯。
- 你提到 "辗转相除法是数学问题",但实际刷题中,这类基础算法(GCD/LCM、快速幂等)是 "编程基本功" 而非单纯数学 ------ 不仅要记结论,更要记参数顺序、终止条件 (比如你最初把
-
链表操作:"动笔画图" 是最高效的调试方式
- 链表插入的核心是 "先保后改":插入新节点前,必须先保存
cur->next的指针(你最初想复用p节点,本质是没意识到 "每个插入位置需要独立节点")。建议养成习惯:只要写链表修改逻辑,先在纸上画 3 步 :① 标记当前节点cur和下一个节点next_node;② 画出新节点p的指向(p->next = next_node);③ 修改cur的指向(cur->next = p);④ 确定cur的移动目标(cur = next_node,而非cur = cur->next)。 - 踩坑提醒:"复用节点" 在链表插入中几乎都是错误逻辑 ------ 链表的每个节点都是独立的内存对象,复用会导致所有插入位置指向同一个节点,最终链表成环 / 数据错乱。
- 链表插入的核心是 "先保后改":插入新节点前,必须先保存
-
循环条件:"逻辑闭环" 比 "冗余兜底" 更重要
- 你最初加的
if (cur -> next == nullptr)是典型的 "兜底思维",但好的代码应该让while条件本身形成闭环:✅ 正确条件:cur != nullptr && cur->next != nullptr(确保有两个相邻节点可处理);❌ 错误条件:cur != nullptr || cur->next != nullptr(逻辑或会导致空指针访问)。 - 练习技巧:写循环条件前,先想 "循环能执行的最小前提"(比如这道题的前提是 "至少有两个节点"),把前提直接写成条件,而非靠后续判断兜底。
- 你最初加的
二、刷题到 100 题阶段的关键进阶建议
-
**从 "解决问题" 到 "沉淀方法"**你已经开始写博客复盘,这是最好的沉淀方式。建议给每类题型(比如链表操作)建立 "错题清单",只记录两类问题:
- 算法逻辑错(比如 GCD 参数写反);
- 数据结构操作错(比如链表插入覆盖指针)。每隔一段时间回顾,能快速定位自己的高频踩坑点。
-
"测试用例思维" 前置: 你提到 "多写测试用例打草稿",可以把这个步骤提前到 "写代码前":比如这道题,先列 2 个核心测试用例:
- 边界用例:
head = [7](直接返回); - 常规用例:
head = [18,6](插入 6 后链表为 18,6,6)。写代码前先明确 "输入→输出→关键步骤",能大幅减少逻辑错误。
- 边界用例:
-
小算法 "刻意练习": 像 GCD、链表插入这类高频小知识点,不用等刷题遇到才练 ------ 每天花 10 分钟写 1 个小算法的不同实现(比如迭代版 GCD、递归版 GCD),练到 "不用思考就能写对",节省刷题时的脑力。
三、最后想对你说
100 题是一个很棒的里程碑,但更重要的是你在这道题里展现的 "自我纠错能力":从错误代码到定位问题、再到修复并反思,这个过程比刷 10 道题的收获都大。
刷题的核心不是 "数量",而是 "每道题都能解决一个自己的薄弱点"。
继续坚持复盘和总结,你的代码逻辑和解题思路会越来越扎实 ------ 下一个 100 题,你一定会看到更明显的进步!