这次刷题是为了展示map和set的使用,并不是单纯追求效率。
一、两个数组的交集

set我们已经学习过了,大致也了解过了底层是二叉查找树,底层不允许重复数据的插入,因此如果将两个数组都扔进去就可以实现去重。

去重以后直接遍历即可:
cpp
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
//去重
set<int> s1;
set<int> s2;
for(auto e:nums1)
s1.insert(e);
for(auto e:nums2)
s2.insert(e);
//遍历其中一个
vector<int> v;
for(auto e:s2)
if(s1.find(e) != s1.end())
v.push_back(e);
return v;
}
};
时间复杂度O(N),空间复杂度大概也是O(N),毕竟有容器的存在。
二、环形链表Ⅱ

这个题用C语言就解答过,之前用的是快慢指针,环形链表Ⅰ是判断有没有环,只要快慢指针会相遇就有环,如果会判断有没有环的进阶就是这道题了:
当时的解法是快慢指针是相遇以后直接让一个指针从头开始遍历,再次相遇点就是入环点,其实蛮可以用set暴力解决:

因为用一个指针去遍历整个链表,遍历一个结点就扔set里面,啥时候插入失败了那不就找到入环结点了。
cpp
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
set<ListNode*> s;
ListNode* pcur = head;
while(pcur)
{
if(!(s.insert(pcur)).second)
return pcur;
pcur = pcur->next;
}
return NULL;
}
};
三、随机链表的复制

这道题最麻烦的点不就是random的问题嘛,普通链表的复制遍历一遍new出来再链接起来就可以了。
但是random的值你又不知道是谁:
假如你想先搞个普通链表的复制,再直接记录下来所有random指向的值
比如这个例子,你说你直接记录下来13的random指向的是7,到时候直接给再套一层遍历去find指定的7就行,效率基本上就是就不说了,问题是如果:
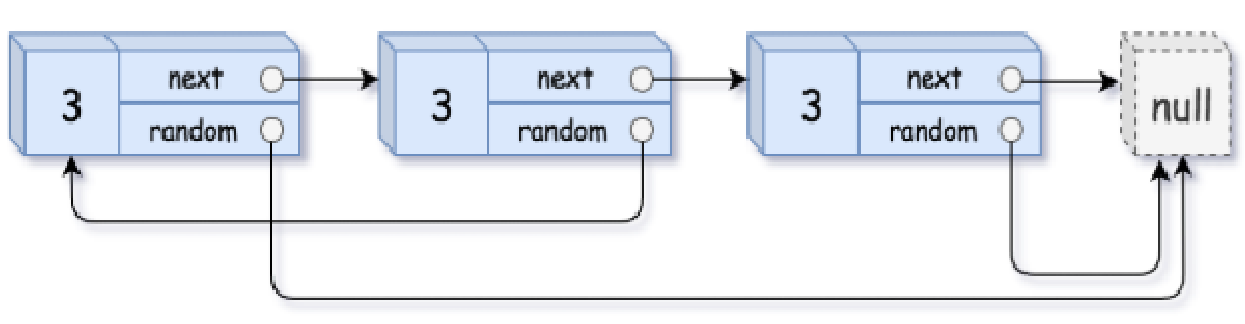
一旦有重复值,那你不炸了,很可能random指向的结点就不对。
这条路走不通还有可能会想,那直接死记住random算了,但是原链表的random和copy链表的random又不一样,人家要求深拷贝,你拿着原链表的random直接给肯定不行。如果拿着原链表的random可以找到copy链表里对应结点就好了。
因此不计空间复杂度情况下map绝对是你建立映射的不二之选:
思路就是:
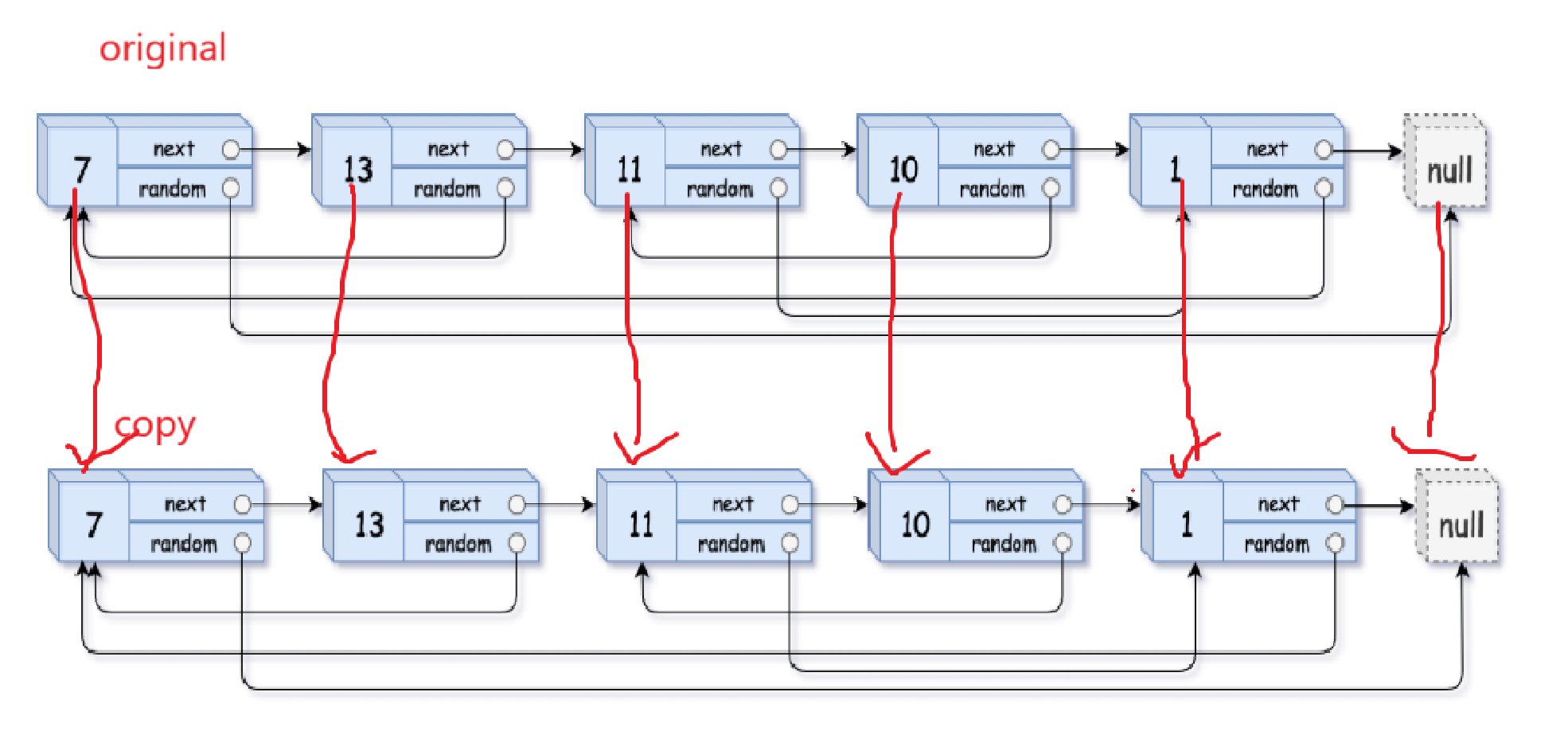
如果原链表和拷贝出来的链表可以一一建立联系,那么拿着原链表的random指向的结点很容易找到对应的现在拷贝链表中对应的结点。
cpp
class Solution {
public:
Node* copyRandomList(Node* head) {
map<Node*,Node*> ori_copy_map;
Node* pcur = head;
Node* copyhead = nullptr;
Node* copycur = nullptr;
//普通链表的拷贝+原链表结点和拷贝链表结点建立关系
while(pcur)
{
if(copyhead == nullptr)
{
copyhead = new Node(pcur->val);
copycur = copyhead;
}
else
{
copycur->next = new Node(pcur->val);
copycur = copycur->next;
}
ori_copy_map.insert({pcur,copycur});
pcur = pcur->next;
}
//通过map搞定copy链表random
pcur = head;
copycur = copyhead;
while(pcur)
{
copycur->random = ori_copy_map[pcur->random];
pcur = pcur->next;
copycur = copycur->next;
}
return copyhead;
}
};
四、前K个高频单词

统计单词频率对我们来说洒洒水了:
cpp
map<string,int> countm;
for(auto& e:words)
{
countm[e]++;
}有了单词频率那么接下来就得按照频次从高到低输出K个值,但是问题是在map中存放的时候完全是按照字典的顺序来搞的,如果我们想要前K个,那肯定得按照频次来排序,还得按照降序排取的时候才舒服。
可能上手直接就搞个:
cpp
sort(countm.begin(),countm.end());但是这玩意其实是有问题的。
要点1
sort传参要求的是啥

随机迭代器,等于我们学过的容器就string、vector,最多加上个数组能用这玩意,所以如果真想用,首先就是倒到vector里头:
cpp
vector<pair<string,int>> mapv;
for(auto& e: countm)
{
mapv.push_back(e);
}
sort(mapv.begin(),mapv.end());这里又能体现我们了解容器底层有啥好处,我们知道范围for底层是迭代器,每次把*iterator给e用,而map的iterator底层operator*肯定是给的底层的数据,也就是pair,所以vector存的内容也就得是pair。如果不学底层,vector搞成什么类型的容器都不知道。
要点2
sort你不传仿函数底层用的应该是pair的比较逻辑,pair有比较逻辑吗?

有的有的,它里面还是大部分都搞个复用,只需要看:

first小就小,first大于等于second小就小。
问题是咱们现在要求的是按照int比啊,也就是只拿second比,并且我们要求的还是降序,所以干脆自己写一个仿函数传过去,sort是支持的:

cpp
struct Compare
{
bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2)
{
return kv1.second > kv2.second;
}
};
cpp
vector<pair<string,int>> mapv;
for(auto& e: countm)
{
mapv.push_back(e);
}
sort(mapv.begin(),mapv.end(),Compare());问题解决以后就直接搞:
cpp
class Solution {
public:
struct Compare
{
bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2)
{
return kv1.second > kv2.second;
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> countm;
for(auto& e:words)
{
countm[e]++;
}
vector<pair<string,int>> mapv;
for(auto& e: countm)
{
mapv.push_back(e);
}
sort(mapv.begin(),mapv.end(),Compare());
vector<string> ret;
for(int i = 0;i < k;i++)
{
ret.push_back(mapv[i].first);
}
return ret;
}
};测试一下没毛病噢:
提交一下吧:
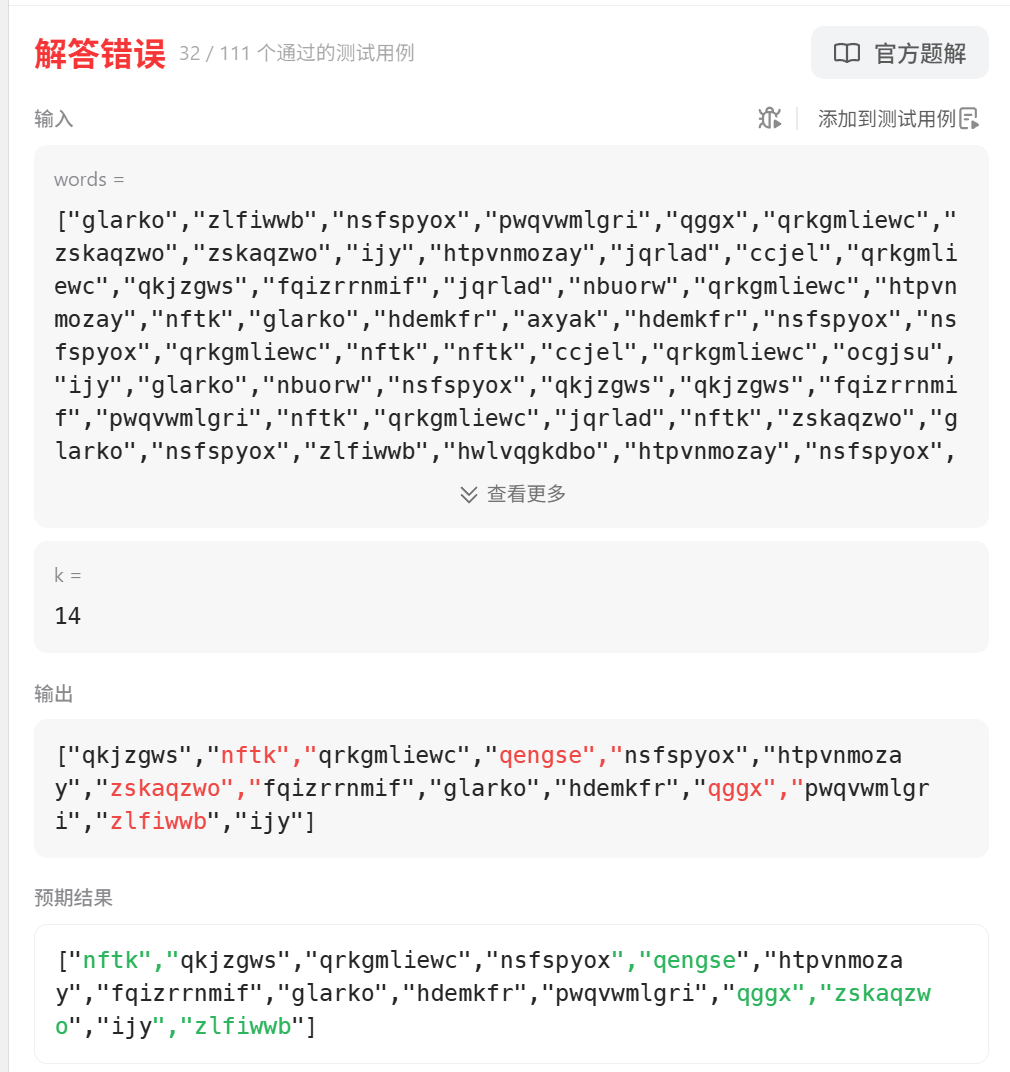
咋回事,咋错了呢?

要点3
仔细观察发现其实我们输出的结果跟它正确答案其实就是差了一个顺序的问题。
等于没有完成它的:

如果频次相同,按照字典顺序排序,等于频次相同先比字母再比长段,但是很奇怪啊,我们刚开始把vector里的string倒到map里不就是按照的字典序吗?因为默认的排序顺序就是根据key也就是string的升序,那么到时候插入的单词用中序遍历倒到vector里面也就严格按照string升序来搞了,不就是字典序吗?

问题只能出到这里了,因为后面一个一个取又不改变顺序。
曲折中前进
细细一想,其实sort是个不稳定排序,也就是有可能造成相同频次数据的相对顺序改变,稳定的排序有插入排序、冒泡排序、归并排序,而sort底层快排堆排混合来着,都不稳定,因此搞成库里的:
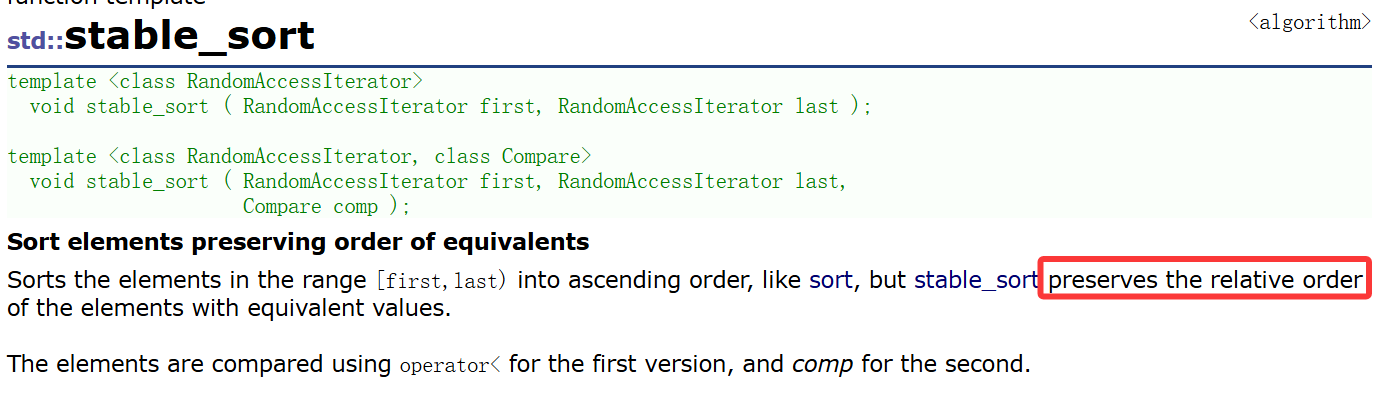
保证相对顺序不变。
我测过这玩意,跟sort效率差不多,所以大概率底层搞的是归并排序,要是搞冒泡时间复杂度也确实大的不行。
cpp
class Solution {
public:
struct Compare
{
bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2)
{
return kv1.second > kv2.second;
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> countm;
for(auto& e:words)
{
countm[e]++;
}
vector<pair<string,int>> mapv;
for(auto& e: countm)
{
mapv.push_back(e);
}
stable_sort(mapv.begin(),mapv.end(),Compare());
vector<string> ret;
for(int i = 0;i < k;i++)
{
ret.push_back(mapv[i].first);
}
return ret;
}
};
出来了嗷,没毛病。
另外的修改
当然,其实既然问题出在排序,那么其实可以尝试控制仿函数来控制:
cpp
struct Compare
{
bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2)
{
return kv1.second > kv2.second || ((kv1.second == kv2.second)&&(kv1.first<kv2.first));
}
};也就是频次大的在前面,如果频次相同,那么字典序小的在前面,完美控制:
cpp
class Solution {
public:
struct Compare
{
bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2)
{
return kv1.second > kv2.second || ((kv1.second == kv2.second)&&(kv1.first<kv2.first));
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> countm;
for(auto& e:words)
{
countm[e]++;
}
vector<pair<string,int>> mapv;
for(auto& e: countm)
{
mapv.push_back(e);
}
sort(mapv.begin(),mapv.end(),Compare());
vector<string> ret;
for(int i = 0;i < k;i++)
{
ret.push_back(mapv[i].first);
}
return ret;
}
};