由清华大学、字节跳动提出的 HuMo 是一个统一的、以人为本的视频生成框架,旨在通过多模态输入(包括文本、图像和音频)生成高质量、细粒度且可控的真人视频。它支持强大的文本提示跟随功能、一致的主体保留以及同步的音频驱动动作。
-
来自文本图像的 VideoGen - 使用文本提示结合参考图像定制角色外观、服装、化妆、道具和场景。
-
VideoGen from Text-Audio - 仅通过文本和音频输入即可生成音频同步的视频,无需图像参考,从而实现更大的创作自由。
-
来自文本-图像-音频的 VideoGen - 通过结合文本、图像和音频指导实现更高级别的定制和控制。

效果展示
从文本和图像生成视频(TI)
可以生成高质量、文本对齐且主题一致的视频。

从文本、图像和音频生成视频 (TIA)
可以生成文本对齐、主题一致且音频同步的视频

文本控制/编辑
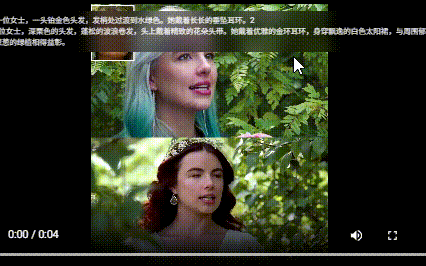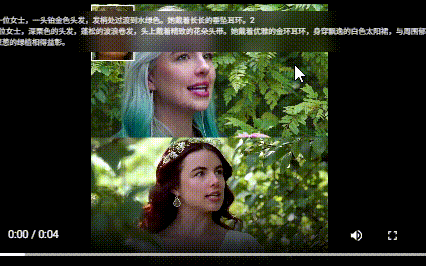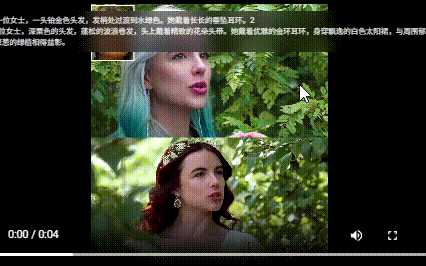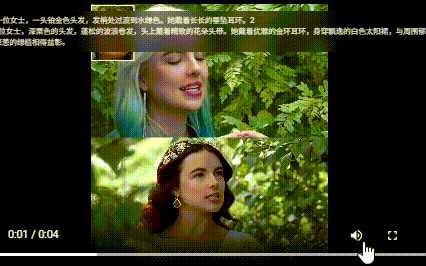
相关链接
论文阅读

-
论文标题: HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
-
作者: Liyang Chen, Tianxiang Ma, Jiawei Liu, Bingchuan Li, Zhuowei Chen, Lijie Liu, Xu He, Gen Li, Qian He, Zhiyong Wu
-
机构: 清华大学、字节跳动智能创作实验室 以人为中心的视频生成 (HCVG) 方法旨在从多模态输入(包括文本、图像和音频)合成人体视频。现有方法难以有效地协调这些异构模态,原因在于两个挑战:具有成对三元组条件的训练数据稀缺,以及难以将主体保存和视听同步子任务与多模态输入协同。
论文提出的 HuMo 是一个用于协作多模态控制的统一 HCVG 框架。针对第一个挑战构建了一个包含多样化且成对的文本、参考图像和音频的高质量数据集。针对第二个挑战提出了一种两阶段渐进式多模态训练范式,并采用针对特定任务的策略。
对于主体保存任务,为了保持基础模型的快速跟踪和视觉生成能力,采用了微创图像注入策略。对于视听同步任务,除了常用的音频交叉注意力层外,我们还提出了一种预测聚焦策略,该策略隐式地引导模型将音频与面部区域关联起来。
为了实现跨多模态输入的可控性联合学习,在先前获得的能力基础上,逐步融入视听同步任务。在推理过程中,为了实现灵活且细粒度的多模态控制,设计了一种时间自适应的无分类器引导策略,该策略可在去噪步骤中动态调整引导权重。大量的实验结果表明,HuMo 在子任务中超越了现有的特定 SOTA 方法,从而为协作式多模态条件化 HCVG 构建了一个统一的框架。
方法概述
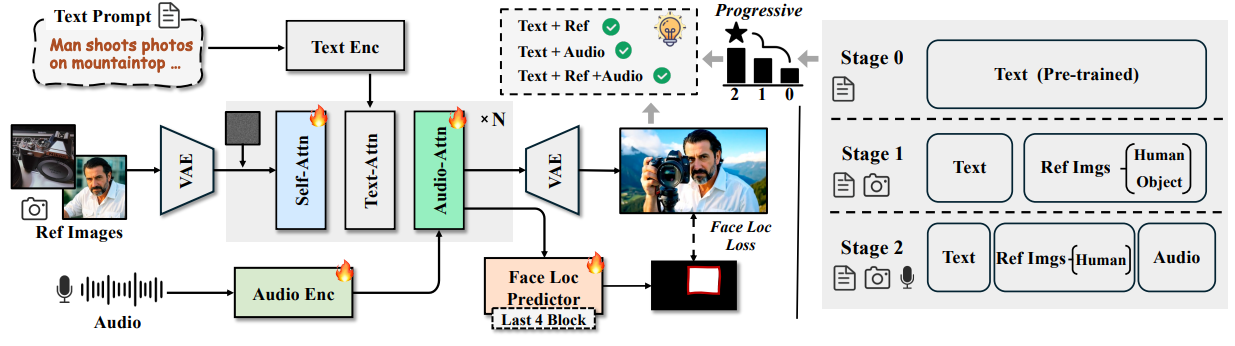
框架概览。 HuMo 模型(左)基于建议的数据处理流程(右)进行训练。该模型基于第 0 阶段基于 DiT 的 T2V 主干网络构建,并在第 1 阶段和第 2 阶段逐步学习主体保留和视听同步功能。HuMo 实现了跨不同模态组合的协同生成。

所提出的时间自适应 CFG 平衡了文本引导和身份保存。
实验结果
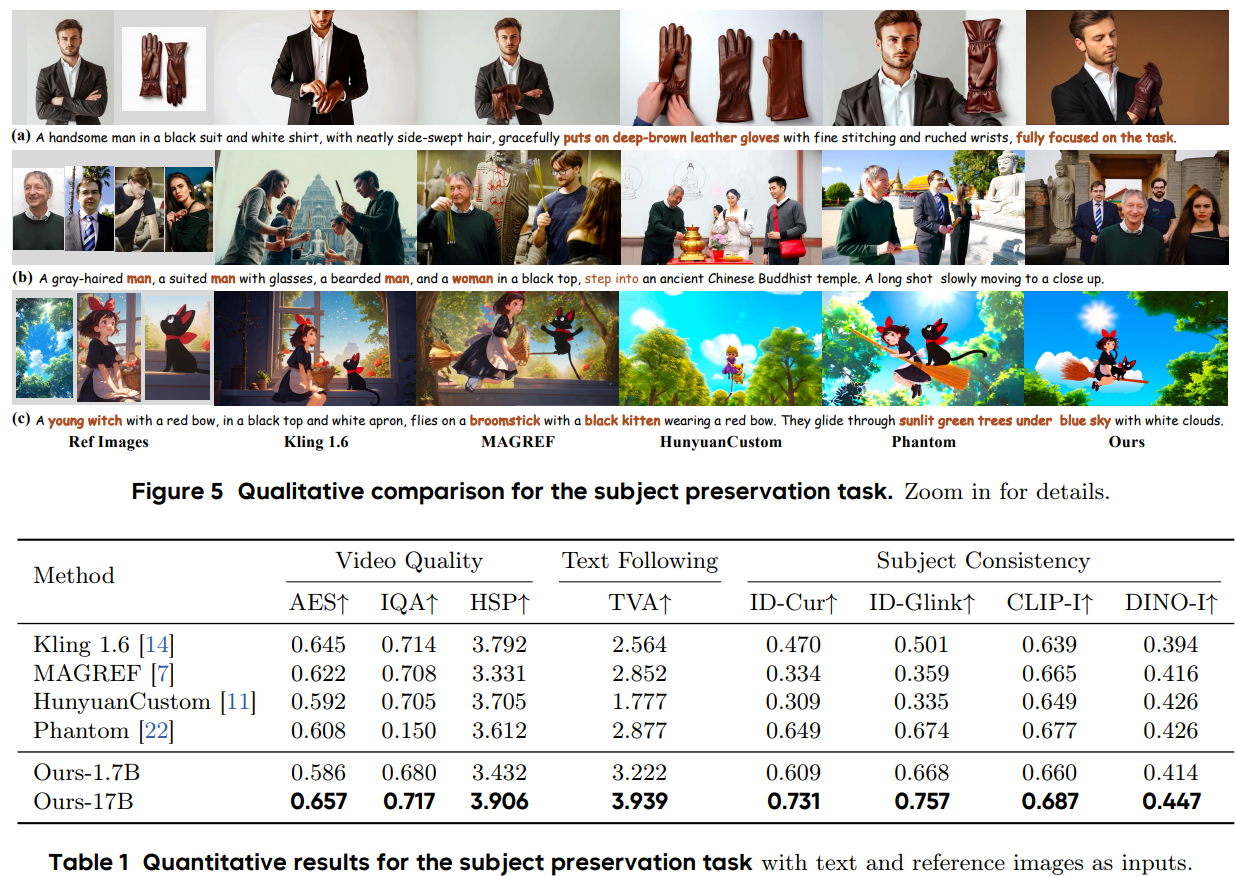



结论
HuMo 是一个以人为本、支持多模态条件的全新视频生成框架。HuMo 建立了多模态数据处理流程,以生成包含成对文本提示、参考图像和音频的高质量多样化数据集。所提出的渐进式多模态训练范式成功地将文本、图像和音频模态的控制能力集成到一个统一的模型中。利用所提出的时间自适应 CFG 策略,模型能够在推理过程中对这三种模态进行灵活、细粒度和协同的控制。HuMo 满足了以人为本的短视频创作中对文本提示跟随、主题保留和视听同步的多重需求。