点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年10月07日更新到:
Java-141 深入浅出 MySQL Spring事务失效的常见场景与解决方案详解(3)
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

NoSQL
NoSQL(Not Only SQL)是与传统关系型数据库(Relational Database)相辅相成的一类数据库系统。它不仅支持类似SQL的查询功能,还提供了更丰富的特性:
- 性能优势
- 通过分布式架构实现高吞吐量(如MongoDB单节点可处理10万+ QPS)
- 采用内存计算模式(如Redis的读写性能可达10万+/秒)
- 支持水平扩展(如Cassandra可轻松扩展到数百个节点)
- 灵活的数据模型
- 文档型(MongoDB的BSON格式)
- 键值型(Redis的简单键值存储)
- 列族型(HBase的列式存储)
- 图数据库(Neo4j的节点关系模型)
- 典型的应用场景
- 电商购物车(Redis临时存储)
- 社交网络关系(Neo4j图形处理)
- 物联网时序数据(InfluxDB时间序列)
- 内容管理系统(MongoDB文档存储)
- 与SQL数据库的协作
- 混合架构(MySQL+Redis)
- 数据分层(热数据用NoSQL)
- 特定场景优化(全文检索用Elasticsearch)
- 非结构化的优势
- 动态schema(可随时添加字段)
- 嵌套数据结构(JSON文档)
- 无固定表结构约束
这些特性使NoSQL在大数据、实时应用、快速迭代等场景中展现出独特价值,同时通过适当的技术选型可以与关系型数据库形成互补。
NoSQL数据库四大家族及其应用场景:
-
列存储 - HBase
基于Google Bigtable论文设计,适用于海量结构化数据存储
典型应用:金融交易记录、电信通话数据、物联网传感器数据
特点:高扩展性、支持PB级数据、强一致性
示例:Facebook消息系统底层存储
-
键值存储 - Redis
内存数据库,支持持久化
典型应用:会话缓存、排行榜系统、实时分析
特点:超高性能(10万+QPS)、支持丰富数据结构(字符串/哈希/列表等)
示例:Twitter使用Redis存储用户时间线
-
图存储 - Neo4j
原生图数据库,使用属性图模型
典型应用:社交网络、推荐系统、欺诈检测
特点:直观的图查询语言Cypher、高效处理复杂关系
示例:LinkedIn的人际关系网络分析
-
文档存储 - MongoDB
BSON格式存储,类JSON结构
典型应用:内容管理系统、产品目录、用户配置
特点:动态schema、支持索引和聚合查询
示例:eBay的商品目录管理系统
各类型数据库选择建议:
- 需要处理大量关联数据 → Neo4j
- 要求极高性能缓存 → Redis
- 非结构化内容存储 → MongoDB
- 海量结构化数据 → HBase
实际生产中常采用多类型组合方案,如:
"Redis+MongoDB"组合:Redis处理高速缓存,MongoDB持久化存储
MongoDB简介
MongoDB 是一个开源的 NoSQL 数据库,它采用文档型数据模型,在数据库分类中处于关系型数据库(如 MySQL)和传统非关系型数据库(如 Redis)之间的位置。作为非关系型数据库中最接近关系型数据库的产品,MongoDB 具有以下显著特点:
- 文档存储结构
- 使用类似 JSON 的 BSON 格式存储数据
- 支持嵌套文档和数组等复杂数据结构
- 文档模式灵活,不需要预先定义表结构
- 强大的查询能力
- 支持丰富的查询表达式
- 提供索引功能(包括复合索引、全文索引等)
- 支持聚合管道进行复杂数据分析
- 分布式架构
- 原生支持分片(Sharding)技术
- 可水平扩展,通过添加更多节点来提升性能
- 自动处理数据分区和负载均衡
典型应用场景包括:
- 内容管理系统(CMS)
- 实时分析和大数据处理
- 移动应用后端
- 物联网(IoT)数据存储
与传统关系型数据库相比,MongoDB 特别适合处理以下类型的数据:
- 半结构化数据
- 快速增长的数据集
- 需要频繁变更模式的数据
- 高并发读写场景
在性能方面,MongoDB 通过副本集(Replica Set)提供自动故障转移机制,确保高可用性;同时其分片集群架构能够有效应对 PB 级数据存储需求,是处理海量数据的理想选择。
体系架构
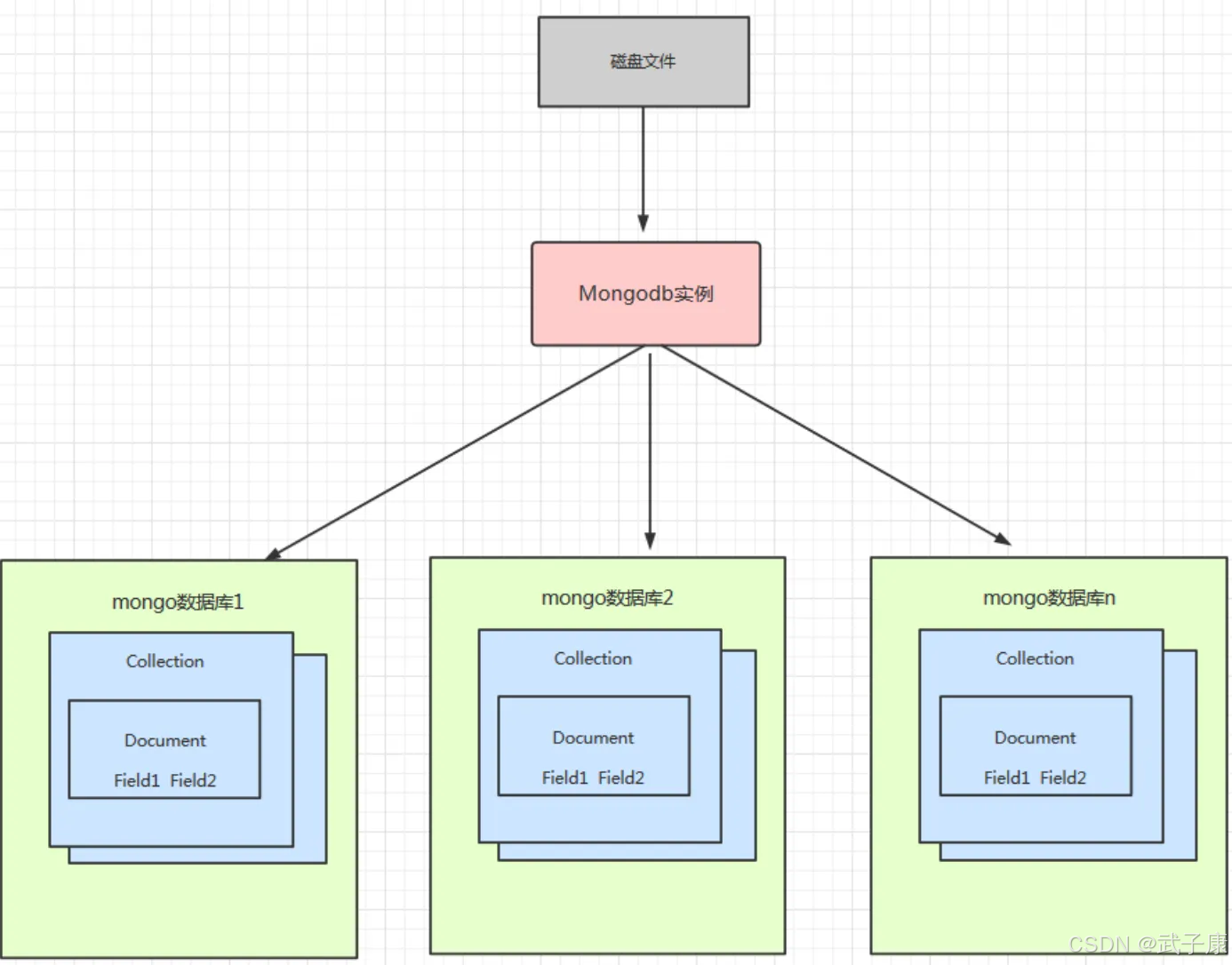
MongoDB 的体系架构
MongoDB 是一个分布式文档数据库,采用灵活的文档存储模型,其体系架构设计旨在提供高性能、高可用性和易扩展性。以下是 MongoDB 体系架构的主要组成部分:
1. 数据存储层
1.1 存储引擎
- WiredTiger (默认引擎):支持文档级并发控制、压缩和检查点功能
- In-Memory:专为需要极致性能的场景设计,所有数据保存在内存中
- MMAPv1 (旧版引擎):基于内存映射文件的传统存储引擎
1.2 存储格式
- 使用 BSON (Binary JSON) 格式存储数据,比 JSON 更高效
- 数据文件存储在
/data/db目录下(默认路径),包含:.wt文件(WiredTiger数据文件).ns文件(命名空间文件)- 日志文件
2. 查询处理层
2.1 查询引擎
- 支持丰富的查询操作:CRUD、聚合管道、文本搜索、地理空间查询
- 查询优化器评估并选择最高效的查询计划
- 支持二级索引(包括复合索引、多键索引、文本adv索引等)
ئات##Penjel不分
초기新时代中国特色社会主义思想学习
1. cutaneous Revolution
- ** allowances之主** ( default 引擎支书谎言): 支持文档级并发控制、压缩连线检查点 rhs
- In-Memory:ensor为需要连续的极致性能场景设计,所有数据保存在内存中
- MMAPv1 (旧版引擎):基于内存映射文件的传统存储引擎
1.2 存储格式
- 使用 BSON (Binary JSON) 格式存储数据,比 JSON 更高效
- 数据天山存储在
/data/db目录下(默认路径),包含:.祈福生産(WbenzTiger数据文件).ns文件(命名琵传递文件)- 日志文件 Eind我们再
2. 查询处理层
2.1 查询引擎
- 支持丰富的盖章操作:CRUD、聚合管道 IS、文本搜索、地理空间查询
- 查询优化器评估并选择最高效的查询计划
- 支持二级索引(此番复合索引、多键索引、文本索引等)
модуль 2处分
3. 分片与复制层
3.1 复制集(Replica Set)
- 由 3个 Parlay更节点组成(1个主节点 + 2个从节点)
- 自动故障转移:主节点不可用时,从节点自动选举新主节点
- 数据同步:通过操作日志(oplog)实现节点 underlying数据同步
3.2 分片集群(Sharded Cluster)
- 包含三大组件:
IS - ** truncated片**: casually数据分片的 MongoDB实例 - 查询路由 :(range路由的主人 room)
Mosqueijs - 配置服务器:存储集群元数据 - 支持也表示分 convergence方式:
- 基于 తెలుగsegment分片
- mig ánństwo分片
- <|place▁holder▁no▁404|> 分片
4. 应用连接层
4. thawMAP收纳
-流血支持awia多种ுற்றம்语言驱动生産:
- Node.js、Python、Java、C#、Go、PHP等
- 连接方式:
миллионов - 标准连接字符串- 连接池管理
- 支持 TLS/SSL 加密连接
4.2 监控与管理工具
- MongoDB Atlas (云服务管理平台)
- MongoDB Compass (图形化管理工具)
- mongostat/mongot destro 命令行监控 pizzicato
5. 安全体系
5.1 认证机制
- SCRAM (默认认证机制)
- x.509 证书认证
- LDAP 集成认证
- Kerberos 认证
czenia 5 strongbox Cruise
心跳机制:
- 角色基于访问控制(RBAC)
- 支持数据库级、集合级和字段级的访问控制
- 审计日志功能
5.3 数据保护
- 传输 Zukunft 加密(TLS测评)
-句号存储加密(企业оприя式为提供 set点了点头)
MongoDB 的体系架构使其能够灵活应对各种规模的应用穩定,从单机部署到各不相同的大规模分布式系统,同时_genre_実施ensor高可用性和横向扩展能力。
对于RDBMS
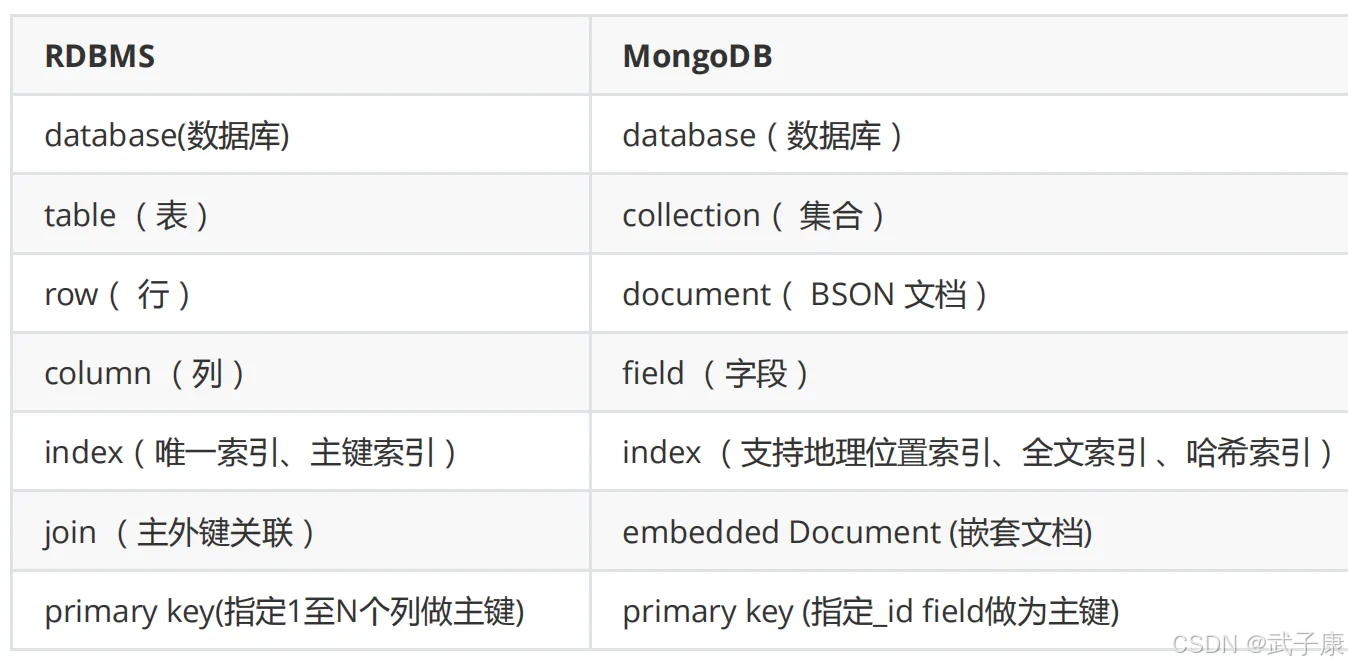
MongoDB 与传统关系型数据库对比
数据模型差异
MongoDB 采用文档模型(Document Model),存储的是类似 JSON 格式的 BSON 文档,文档内部可以嵌套其他文档或数组。例如:
json
{
"_id": ObjectId("507f1f77bcf86cd799439011"),
"name": "张三",
"age": 28,
"address": {
"street": "科技路123号",
"city": "北京",
"zip": "100000"
},
"hobbies": ["阅读", "游泳", "编程"]
}关系型数据库(如 MySQL)则采用表结构(Table Model),数据存储在规范化表中,通过外键关联。相同数据在关系型数据库中通常需要拆分成多个表(如用户表、地址表、爱好表),并通过 JOIN 操作关联。
查询语言对比
MongoDB 使用基于 JSON 的查询语言:
javascript
db.users.find({
age: {$gt: 25},
"address.city": "北京"
}).sort({age: 1})关系型数据库使用 SQL:
sql
SELECT * FROM users
WHERE age > 25 AND city = '北京'
ORDER BY age ASC主要特性对比
| 特性 | MongoDB | 关系型数据库 |
|---|---|---|
| 数据模型 | 文档模型,无固定模式 | 表结构,需要预定义模式 |
| 扩展性 | 水平扩展容易(分片) | 通常垂直扩展,水平扩展复杂 |
| 事务支持 | 4.0+ 版本支持多文档ACID事务 | 完整ACID事务支持 |
| 连接操作 | 无连接(通过嵌入文档或应用层实现) | 通过JOIN实现表关联 |
| 索引支持 | 支持多种索引类型 | 支持多种索引类型 |
| 灵活性 | 数据结构可动态变化 | 修改表结构需要ALTER操作 |
适用场景
MongoDB 更适用:
- 快速迭代开发,需求频繁变化的项目
- 处理半结构化或非结构化数据
- 需要高可扩展性的场景(如大数据量、高吞吐)
- 地理位置数据处理(内置地理空间索引)
- 内容管理系统、物联网应用、实时分析
关系型数据库更适用:
- 需要复杂事务处理的应用(如金融系统)
- 数据结构稳定、关系明确的场景
- 需要复杂JOIN操作的报表系统
- 已有大量基于SQL的遗留系统
性能考虑
- 写入性能:MongoDB 通常有更高的写入吞吐量,特别是批量插入场景
- 读取性能:对于简单查询两者相当,复杂关联查询关系型数据库通常更优
- 存储效率:MongoDB 由于存储冗余数据可能占用更多空间,但避免了JOIN开销
实际应用示例
电商平台案例:
- 使用 MongoDB 存储产品目录(可变属性多)
- 使用关系型数据库处理订单事务(需要ACID保证)
- 混合使用两种数据库很常见