博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
- 技术栈:python语言、YOLOv8模型、ByteTrack算法、深度学习、多目标检测与跟踪、pyqt界面、YOLOv5模型、PySide6、SQLite数据库、5542张行人车辆训练图片
- 这个项目的研究背景:当前多目标检测跟踪场景(如人群监控、交通流量分析)中,传统系统存在检测精度低、模型适配性差的问题,单一模型难以满足不同场景需求,且缺乏便捷的模型切换功能。同时,多数系统操作界面复杂,不支持图像、视频、摄像头多源输入,也缺乏用户身份验证机制,导致使用门槛高、数据安全性不足,无法高效支撑实际监控与流量分析需求,亟需一体化的高精度检测跟踪系统解决这些痛点。
- 这个项目的研究意义:技术层面,通过YOLOv8/v5双模型提升检测精度,结合ByteTrack算法优化跟踪稳定性,借助PySide6搭建友好UI,解决传统技术短板;用户层面,支持多源输入处理(图像、视频、摄像头、批量文件),可点击切换模型,搭配SQLite登录注册保障安全,降低使用难度;行业层面,为人群监控、交通流量分析提供高精度数据支撑,推动监控场景智能化升级,具备实际应用价值。
2、项目界面
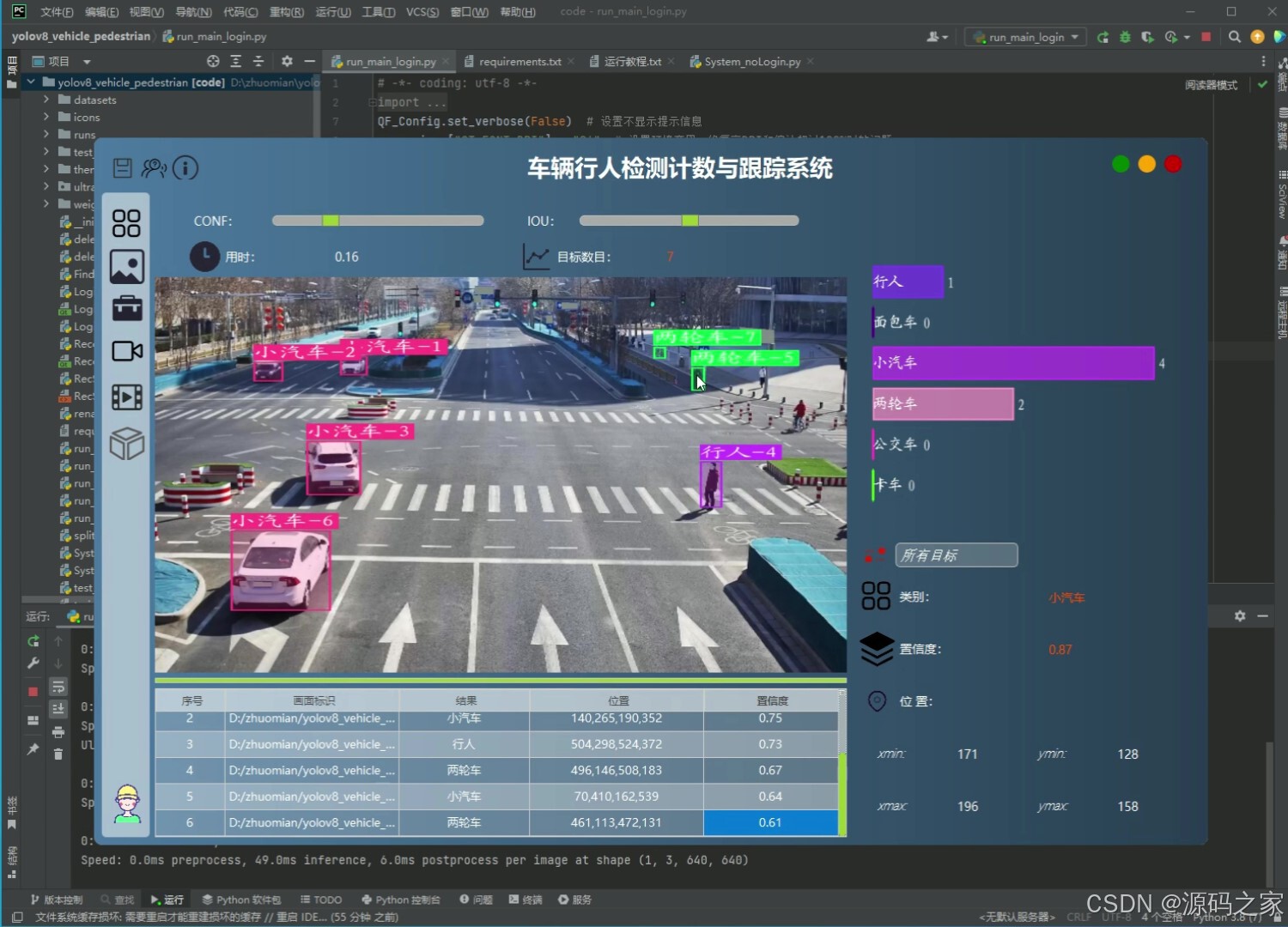
(1)车辆行人检测计数与跟踪(上传图片)
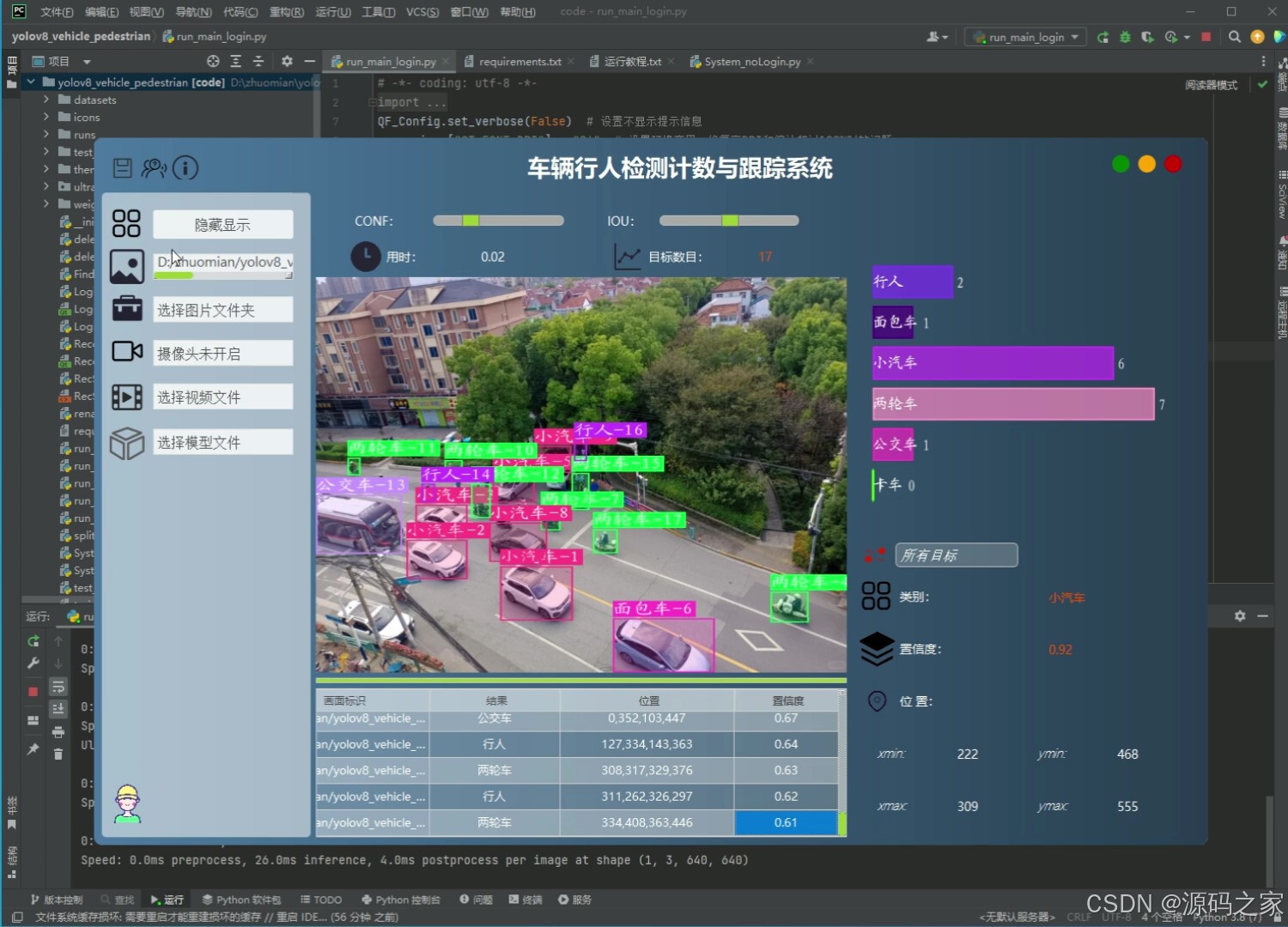
(2)车辆行人检测计数与跟踪(上传视频)
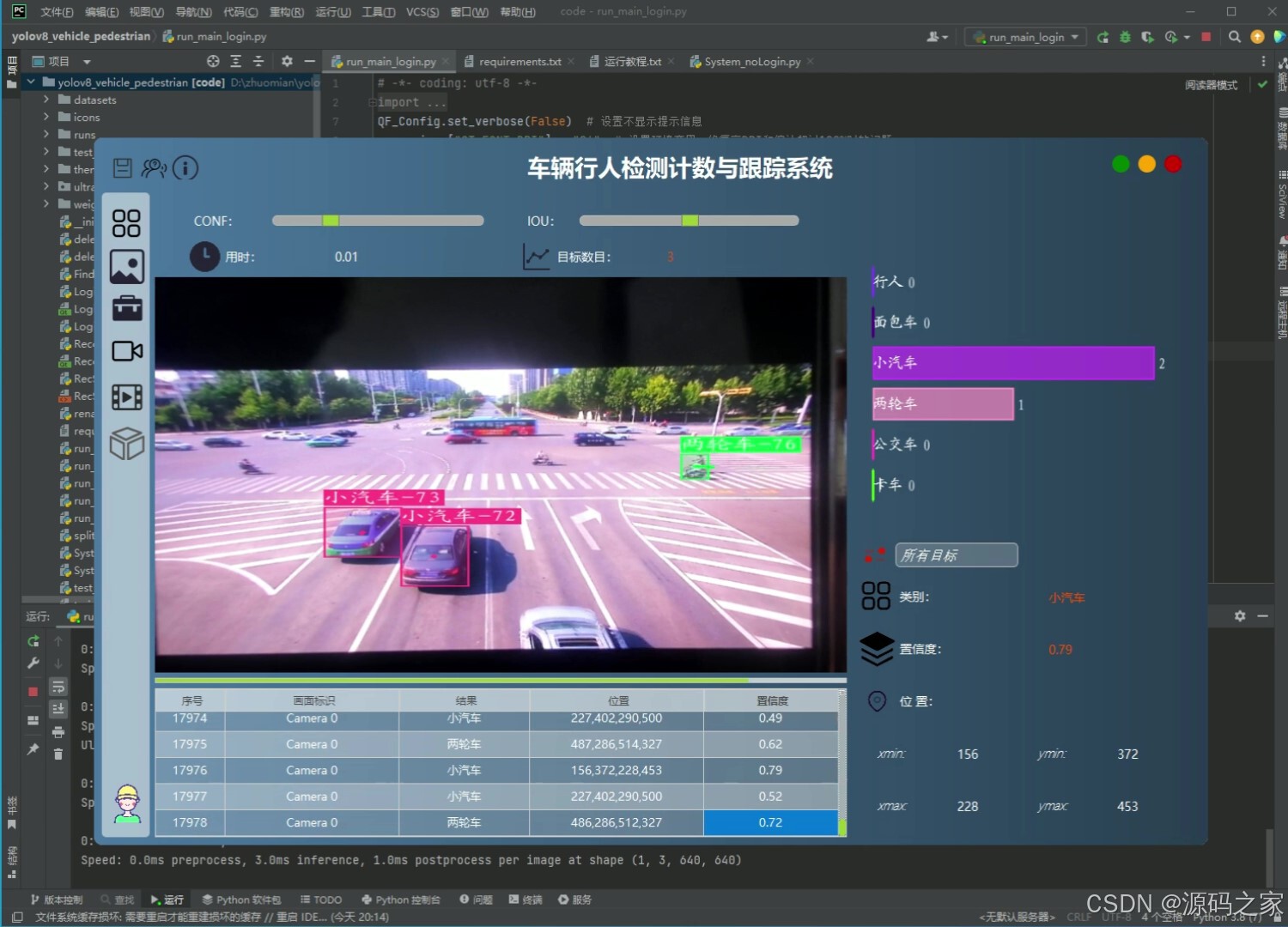
(3)车辆行人检测计数与跟踪(摄像头实时检测)
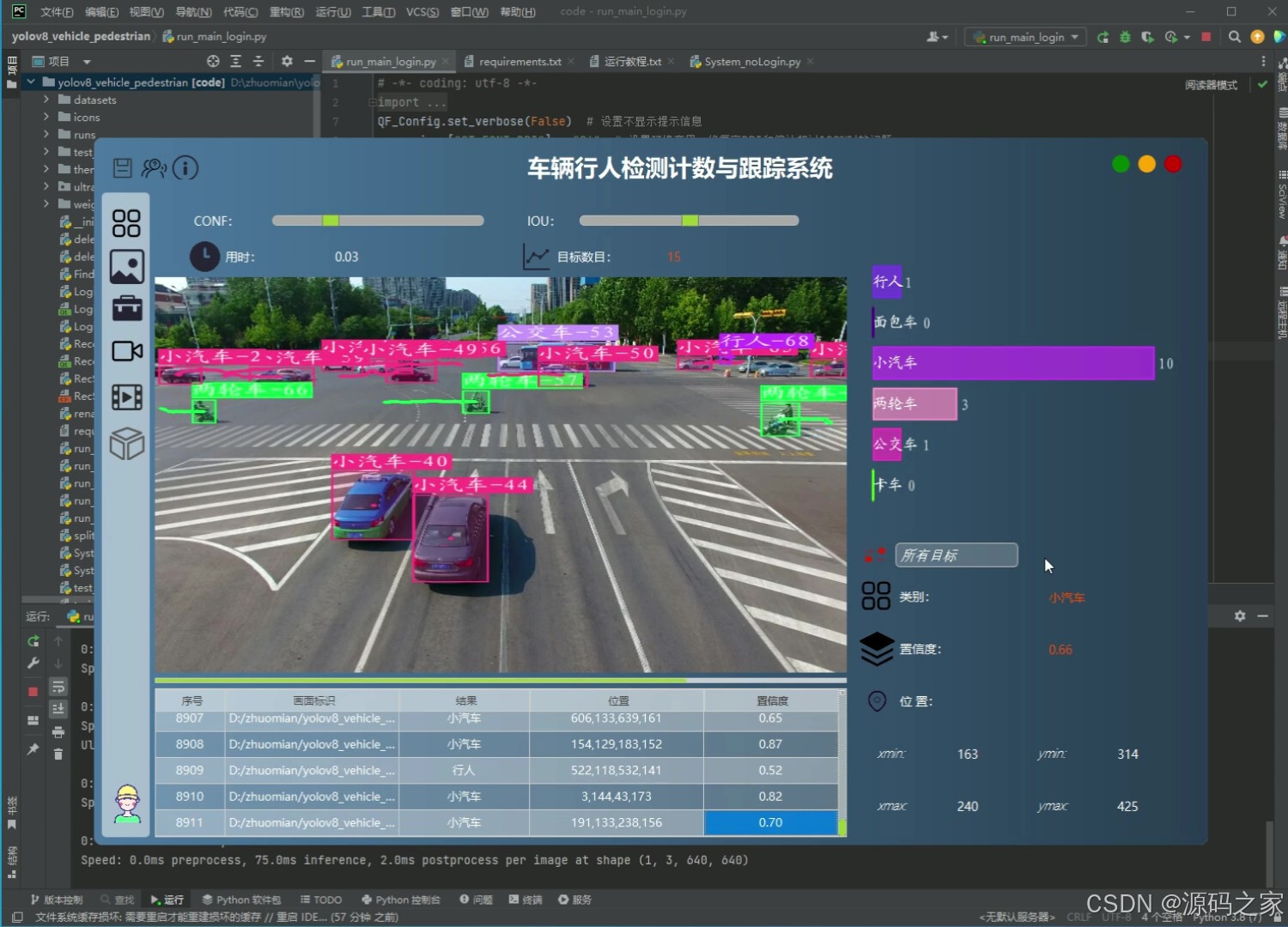
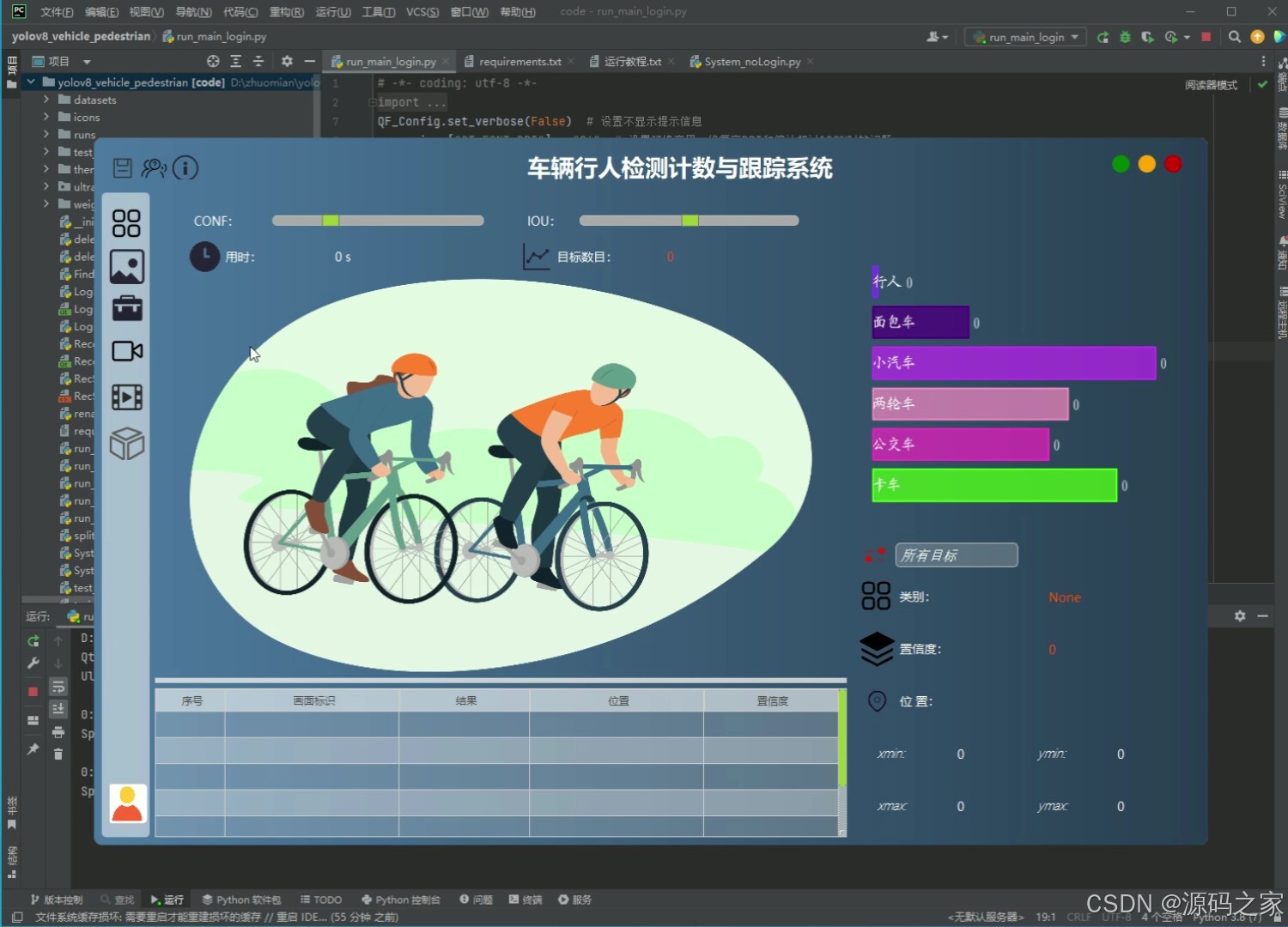
(4)车辆行人检测计数与跟踪
(5)系统界面
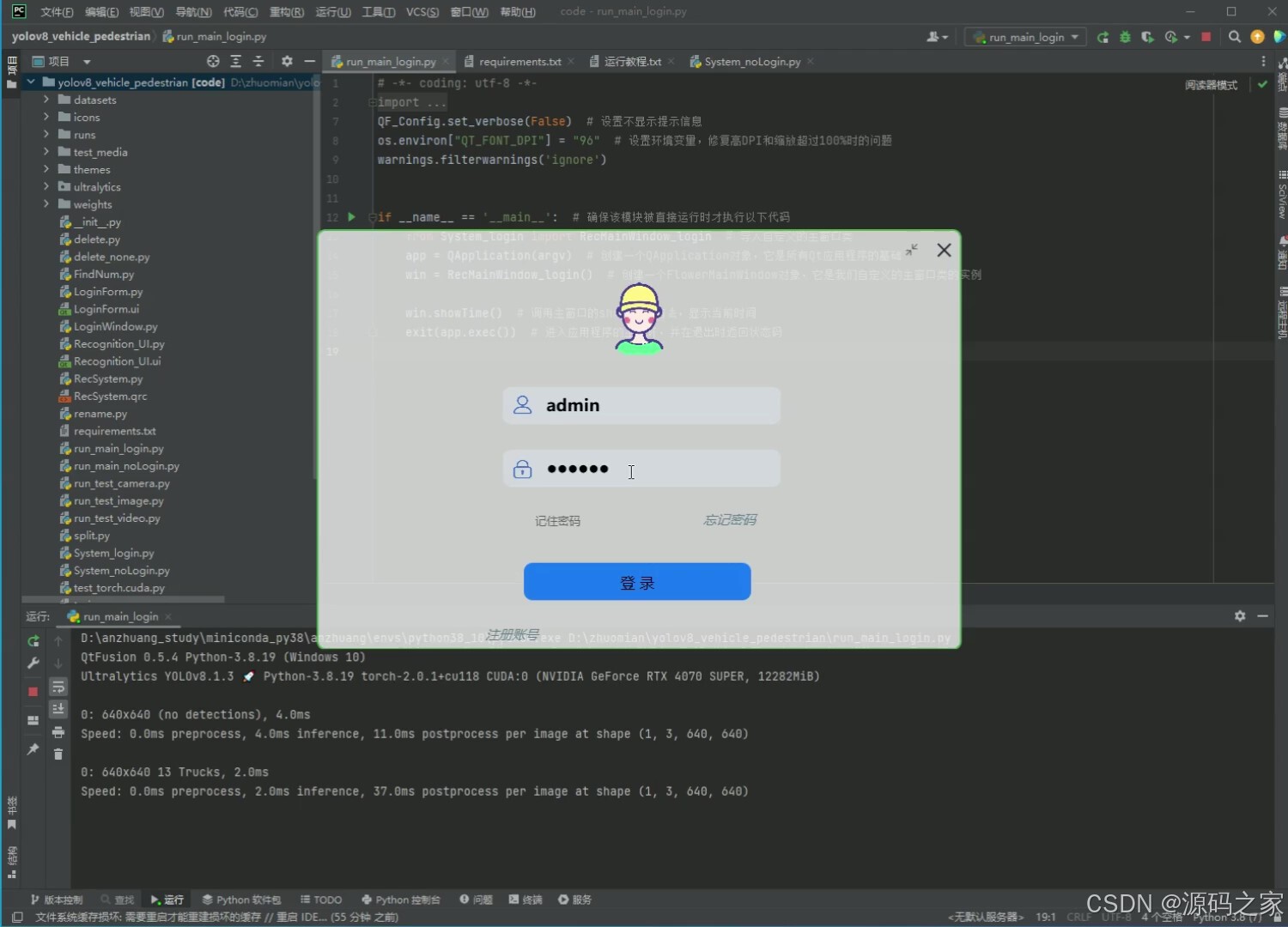
(6)注册登录
3、项目说明
本项目是基于Python语言开发的多目标检测计数与跟踪系统,整合YOLOv8/v5双模型、ByteTrack跟踪算法、PySide6界面框架与SQLite数据库,核心实现行人与车辆(含自行车、小汽车、摩托车等7类目标)的高精度检测、跟踪与计数,适用于人群监控、交通流量分析等场景,旨在解决传统系统检测精度低、功能单一、使用不便的问题。项目前期使用5542张行人车辆图片数据进行模型训练,对比分析YOLOv8与YOLOv5的性能差异,通过mAP、F1 Score等指标评估模型精度,确保检测效果满足实际需求。系统架构围绕"检测-跟踪-交互"构建:检测环节调用YOLOv8/v5模型识别目标,支持用户点击按钮切换模型以适配不同场景;跟踪环节通过ByteTrack算法对检测到的目标分配唯一ID,实现连续轨迹跟踪与计数;数据存储与安全方面,采用SQLite数据库搭建登录注册功能,保障用户身份验证与系统数据安全。在功能设计上,系统支持多源输入处理,可上传图像、视频文件,调用摄像头进行实时检测,还能处理批量文件,满足多样化使用需求;界面基于PySide6设计,简洁直观,降低操作门槛,用户可清晰查看检测结果、跟踪轨迹与计数数据。整体而言,系统通过技术整合实现了"高精度检测+灵活跟踪+便捷交互+安全管理"的一体化功能,既为监控与交通领域提供可靠的数据采集工具,也为多目标检测跟踪技术的实际应用提供了完整方案,具备较强的实用性与可扩展性。
4、核心代码
python
# -*- coding: utf-8 -*-
import cv2 # 导入OpenCV库,用于处理图像和视频
import torch
from QtFusion.models import Detector, HeatmapGenerator # 从QtFusion库中导入Detector抽象基类
from datasets.DAIRV2X.label_name import Chinese_name # 从本地datasets文件夹中导入Chinese_name字典,用于获取类别的中文名称
from ultralytics import YOLO # 从ultralytics库中导入YOLO类,用于加载YOLO模型
from ultralytics.utils.torch_utils import select_device # 从ultralytics库中导入select_device函数,用于选择设备
device = "cuda:0" if torch.cuda.is_available() else "cpu"
ini_params = {
'device': device, # 设备类型,这里设置为CPU
'conf': 0.25, # 物体置信度阈值
'iou': 0.5, # 用于非极大值抑制的IOU阈值
'classes': None, # 类别过滤器,这里设置为None表示不过滤任何类别
'verbose': False,
'persist': True,
'tracker': "bytetrack.yaml"
}
def count_classes(det_info, class_names):
"""
Count the number of each class in the detection info.
:param det_info: List of detection info, each item is a list like [class_name, bbox, conf, class_id]
:param class_names: List of all possible class names
:return: A list with counts of each class
"""
count_dict = {name: 0 for name in class_names} # 创建一个字典,用于存储每个类别的数量
for info in det_info: # 遍历检测信息
class_name = info['class_name'] # 获取类别名称
if class_name in count_dict: # 如果类别名称在字典中
count_dict[class_name] += 1 # 将该类别的数量加1
# Convert the dictionary to a list in the same order as class_names
count_list = [count_dict[name] for name in class_names] # 将字典转换为列表,列表的顺序与class_names相同
return count_list # 返回列表
class YOLOv8v5Tracker(Detector): # 定义YOLOv8Detector类,继承自Detector类
def __init__(self, params=None): # 定义构造函数
super().__init__(params) # 调用父类的构造函数
self.model = None
self.img = None # 初始化图像为None
self.names = list(Chinese_name.values()) # 获取所有类别的中文名称
self.params = params if params else ini_params # 如果提供了参数则使用提供的参数,否则使用默认参数
def load_model(self, model_path): # 定义加载模型的方法
self.device = select_device(self.params['device']) # 选择设备
self.model = YOLO(model_path, )
names_dict = self.model.names # 获取类别名称字典
self.names = [Chinese_name[v] if v in Chinese_name else v for v in names_dict.values()] # 将类别名称转换为中文
self.model(torch.zeros(1, 3, *[self.imgsz] * 2).to(self.device).
type_as(next(self.model.model.parameters()))) # 预热
self.model(torch.rand(1, 3, *[self.imgsz] * 2).to(self.device).
type_as(next(self.model.model.parameters()))) # 预热
def preprocess(self, img): # 定义预处理方法
self.img = img # 保存原始图像
return img # 返回处理后的图像
def predict(self, img): # 定义预测方法
results = self.model.track(img, **ini_params)
return results
def postprocess(self, pred): # 定义后处理方法
results = [] # 初始化结果列表
for res in pred[0].boxes:
for box in res:
# 提前计算并转换数据类型
class_id = int(box.cls.cpu())
bbox = box.xyxy.cpu().squeeze().tolist()
bbox = [int(coord) for coord in bbox] # 转换边界框坐标为整数
# 检查 box.id 是否为 None,如果是,则将 track_id 设置为 -1 或其他适当的默认值
track_id = None if box.id is None else int(box.id.int().cpu().item())
result = {
"class_name": self.names[class_id], # 类别名称
"bbox": bbox, # 边界框
"score": box.conf.cpu().squeeze().item(), # 置信度
"class_id": class_id, # 类别ID
"track_id": track_id # 添加跟踪ID
}
results.append(result) # 将结果添加到列表
return results # 返回结果列表
def set_param(self, params):
self.params.update(params)🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻