目录
- [1. 前言](#1. 前言)
- [2. 数据加载机制整体架构概览](#2. 数据加载机制整体架构概览)
-
- [2.1 整体架构设计](#2.1 整体架构设计)
- [2.2 核心组件关系](#2.2 核心组件关系)
- [3. Dataset类初始化方法设计](#3. Dataset类初始化方法设计)
-
- [3.1 BaseDataset初始化方法](#3.1 BaseDataset初始化方法)
- [3.2 YOLODataset初始化方法](#3.2 YOLODataset初始化方法)
- [4. 数据加载核心流程设计](#4. 数据加载核心流程设计)
-
- [4.1 读取图像与标签](#4.1 读取图像与标签)
-
- [4.1.1 📐图像路径扫描](#4.1.1 📐图像路径扫描)
- [4.1.2 📐标签缓存构建](#4.1.2 📐标签缓存构建)
- [4.1.3 📐单样本标签加载](#4.1.3 📐单样本标签加载)
- [4.2 InfiniteDataLoader设计原理](#4.2 InfiniteDataLoader设计原理)
- [4.3 多进程数据加载优化](#4.3 多进程数据加载优化)
- [4.4 批次合并机制](#4.4 批次合并机制)
- [5. 数据缓存与内存优化](#5. 数据缓存与内存优化)
-
- [5.1 标签缓存策略](#5.1 标签缓存策略)
- [5.2 图像缓存策略](#5.2 图像缓存策略)
- [5.3 图像与标签验证](#5.3 图像与标签验证)
- [5.4 图像加载策略](#5.4 图像加载策略)
- [6. 标签处理与格式转换](#6. 标签处理与格式转换)
-
- [6.1 标签标准化](#6.1 标签标准化)
- [6.2 标签格式化](#6.2 标签格式化)
- [6.3 标签过滤](#6.3 标签过滤)
- [7. 总结](#7. 总结)
1. 前言
从整个计算机视觉任务的流程分类来说,本篇属于训练 部分,准确说是训练的前置工作。
正文开始之前,有2点需要说明:
-
本帖所讲的代码库是我在购买亚博智能的jetson orin super开发套件的时候附赠的代码库,并非官方标准版,但其与Ultralytics官方代码相差不大,对于官方代码的学习仍然具有参考价值。
-
本帖以常见的YOLO V8模型训练过程为例,其他模型训练同理。
在深度学习模型训练的"数据-模型-算力"三角架构中,数据加载环节往往是最容易被忽视却又至关重要的性能瓶颈。当模型部署在GPU上时,单次前向传播仅需毫秒级时间,而若数据加载速度跟不上GPU的计算速度,就会导致"GPU空转"------这种"计算等待数据"的现象会直接拉低整个训练流程的效率,尤其在大批次、高分辨率数据训练场景下更为明显。
Ultralytics 作为 YOLO 系列的官方代码库,其数据加载模块以"高效读取+智能缓存+灵活适配"为设计理念,通过 YOLODataset`类实现数据的精准读取与解析,借助 loader.py完成对 PyTorch DataLoader 的深度封装,最终形成了一套支持多数据集格式、多任务场景、分布式训练的高性能数据加载方案。

上一篇文章(Ultralytics 代码库深度解读【五】:数据预处理与增强Pipeline)已经详细解读了数据预处理与增强Pipeline,本篇将聚焦数据流程的前序核心环节------数据加载机制。我们将从 ultralytics/data 目录下的核心文件入手,逐层拆解数据读取逻辑、缓存策略的实现细节、DataLoader 的定制化封装及分布式适配技巧,最终讲解自定义数据集的加载方法。
按照惯例,我们先来看看函数调用关系图 吧:
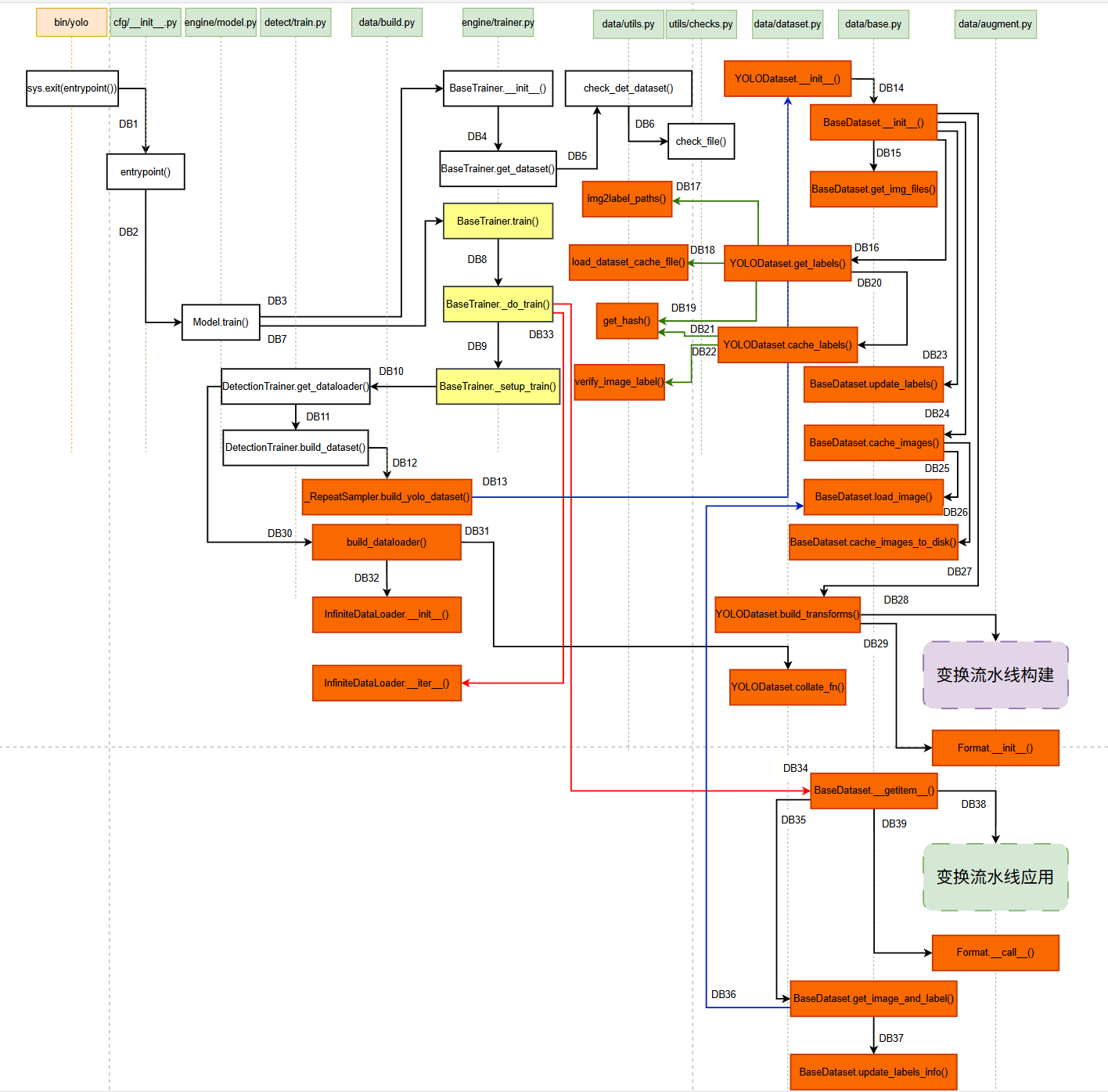
其中:
- 橙色部分:数据加载相关接口,加载训练过程中所需的数据,决定了数据的来源,把握图像和标签的加载细节(本篇的需要讲的重点内容)。
- 虚线框部分:图像加载过程中,为了是实现数据增强,对数据做一些预处理/变换(上一篇已经讲过)。
- 黄色部分:模型训练的"大脑",负责整体训练过程(将在后续章节中继续展开,敬请期待😆)。
2. 数据加载机制整体架构概览
2.1 整体架构设计
Ultralytics的数据加载系统采用了一种分层的、模块化的架构设计,这种设计使得各个组件职责明确、相互独立,同时又能高效协作。整个架构可以分为四个主要层次:
- 💫 数据源层:这一层负责管理原始数据的存储位置,包括图像文件、标签文件、配置文件等。它提供了对数据的访问接口,确保数据能够被正确识别和定位。
- 💫 数据集层:这是整个数据加载系统的核心层,包含了
BaseDataset和YOLODataset等核心类。这一层负责数据的初始化、验证、过滤等操作,是连接原始数据和训练流程的桥梁。 - 💫 数据加载层:这一层使用PyTorch的
DataLoader类以及Ultralytics自定义的InfiniteDataLoader类,负责批量数据的加载、预处理和传输。它管理着多进程数据加载、批次合并、内存管理等关键功能。 - 💫 数据处理层:这一层包含了数据增强、格式转换、标签处理等功能。它在数据加载过程中实时对数据进行处理,确保数据能够满足模型训练的要求。这种分层架构的优势在于每个层次都有明确的职责,便于维护和扩展。当需要修改某个特定功能时,只需要关注相应的层次,而不会影响到其他部分。同时,这种架构也支持不同层次的优化,比如可以在数据加载层优化多进程策略,在数据处理层优化增强算法等。
2.2 核心组件关系
在Ultralytics的数据加载系统中,各个核心组件之间形成了一个复杂但有序的关系网络。理解这些关系对于深入理解整个系统至关重要。
- 🎯
Dataset与DataLoader的关系:Dataset类负责数据的组织和管理,它维护着数据文件列表、标签信息、缓存状态等。DataLoader类则负责从Dataset中批量获取数据,它管理着多进程加载、批次大小、数据打乱等参数。这种设计遵循了单一职责原则,Dataset专注于数据管理,DataLoader专注于数据传输。 - 🎯
Transforms管道:数据增强管道是连接原始数据和模型输入的关键环节。它由多个变换类组成,包括Mosaic、MixUp、RandomHSV、RandomFlip等。这些变换类按照特定顺序组合,形成一个完整的数据增强流程。每个变换类都实现了统一的接口,可以灵活组合和替换。 - 🎯
Format类的作用:Format类负责将处理后的数据转换为模型能够接受的格式。它处理数据类型转换、维度调整、归一化等操作,确保数据在格式上完全符合模型的要求。
当InfiniteDataLoader(继承自DataLoader)在迭代数据时,会自动调用collate_fn来处理一个批次的数据:
DataLoader从数据集中获取一批样本(通过__getitem__()方法)- 每个样本都是一个字典,包含了图像、标签等信息
DataLoader将这些样本组成的列表传递给collate_fncollate_fn将这个样本列表合并成一个批次字典,其中:
- 图像张量通过torch.stack堆叠成批次维度
- 标签张量通过torch.cat连接在一起
- 其他字段相应处理
详细的软件实现过程请移步本文→4.4 批次合并机制。
假设我们需要训练一个YOLO V8的网络。
1.如果我们需要 使用预训练的模型,可以使用这样的命令:
bash
yolo train model=yolov8n.pt data=coco8.yaml epochs=100 batch=16 imgsz=6402.如果我们不需要 使用预训练的模型,就使用这样的命令:
bash
yolo train model=yolov8n.yaml data=coco8.yaml epochs=200 batch=16 imgsz=640 pretrained=False输入命令后,会进行很多步骤的解析,然后将具体的任务分配到各部分软件中进行实施(命令解析的深层次原理和细节,可以参考我写的第一篇帖子Ultralytics代码库深度解读【一】:onnx模型导出中的第二部分:命令解析)。
经过一系列的步骤,命令被解析成了键值对:
train被识别为mode,设置overrides["mode"] = "train"data=coco8.yaml被解析为键值对,设置overrides["data"] = "coco8.yaml"model=yolov8n.pt被解析为键值对,设置overrides["model"] = "yolov8n.pt"epochs=10被解析为键值对,设置overrides["epochs"] = 10
然后创建一个YOLO对象,该对象是用户与Ultralytics框架交互的主要接口。
🚩最后,通过动态方法调用来执行训练:
python
getattr(model, mode)(**overrides) # default args from model等价于调用:
python
model.train(data="coco8.yaml", epochs=10)然后train方法会创建相应的训练器实例并启动训练。
动态方法getattr(model, mode)(**overrides)可以说是整个Ultralytics代码库的亮点和灵魂,这一个动态方法将所有运行模式(训练、验证、预测、导出等)统一了起来,命令行分配的任务,由这一个方法来统一分配。
启动训练后,软件会依次执行以下步骤:
- 设置分布式训练(如果需要)
- 构建模型
- 准备数据加载器
- 设置优化器和学习率调度器
- 启动实际的训练循环
关于数据加载,Ultralytics遵循了清晰的分层设计:
python
数据源文件 → Dataset类 → DataLoader → Transform处理 → 模型输入这种设计使得每个组件都有明确的职责,便于扩展和维护。
3. Dataset类初始化方法设计
3.1 BaseDataset初始化方法
在Ultralytics中,所有数据集类都继承自BaseDataset基类。让我们先查看基类的核心结构:
python
class BaseDataset(Dataset):
def __init__(
self,
img_path,
imgsz=640,
cache=False,
augment=True,
hyp=DEFAULT_CFG,
prefix="",
rect=False,
batch_size=16,
stride=32,
pad=0.5,
single_cls=False,
classes=None,
fraction=1.0,
):
"""Initialize BaseDataset with given configuration and options."""
super().__init__()
self.img_path = img_path
self.imgsz = imgsz
self.augment = augment
self.single_cls = single_cls
self.prefix = prefix
self.fraction = fraction
self.im_files = self.get_img_files(self.img_path)
self.labels = self.get_labels()
self.update_labels(include_class=classes) # single_cls and include_class
self.ni = len(self.labels) # number of images
self.rect = rect
self.batch_size = batch_size
self.stride = stride
self.pad = pad
if self.rect:
assert self.batch_size is not None
self.set_rectangle()
# Buffer thread for mosaic images
self.buffer = [] # buffer size = batch size
self.max_buffer_length = min((self.ni, self.batch_size * 8, 1000)) if self.augment else 0
# Cache images (options are cache = True, False, None, "ram", "disk")
self.ims, self.im_hw0, self.im_hw = [None] * self.ni, [None] * self.ni, [None] * self.ni
self.npy_files = [Path(f).with_suffix(".npy") for f in self.im_files]
self.cache = cache.lower() if isinstance(cache, str) else "ram" if cache is True else None
if self.cache == "ram" and self.check_cache_ram():
if hyp.deterministic:
LOGGER.warning(
"WARNING ⚠️ cache='ram' may produce non-deterministic training results. "
"Consider cache='disk' as a deterministic alternative if your disk space allows."
)
self.cache_images()
elif self.cache == "disk" and self.check_cache_disk():
self.cache_images()
# Transforms
self.transforms = self.build_transforms(hyp=hyp)- 初始化参数解析 :
BaseDataset的初始化方法接受多个参数,每个参数都有其特定的作用。
⚡️img_path参数指定图像数据的路径,这个路径可以是单个图像文件、图像目录或数据集配置文件。
⚡️imgsz参数指定图像的处理尺寸,这影响着后续的所有处理步骤。
⚡️cache参数控制是否启用缓存,这对于大数据集的训练效率至关重要。
⚡️augment参数决定是否应用数据增强,这直接影响训练数据的多样性。
⚡️hyp参数包含超参数,控制各种数据增强的强度和概率。
⚡️prefix参数用于日志输出,便于调试和监控。
有个参数比较难找到,就是hyp参数:
python
hyp=DEFAULT_CFG,然后看看DEFAULT_CFG的定义:
python
# Default configuration
DEFAULT_CFG_DICT = yaml_load(DEFAULT_CFG_PATH)
DEFAULT_CFG = IterableSimpleNamespace(**DEFAULT_CFG_DICT)默认配置来自于默认配置字典,配置字典比较丰富,我们只看一部分:
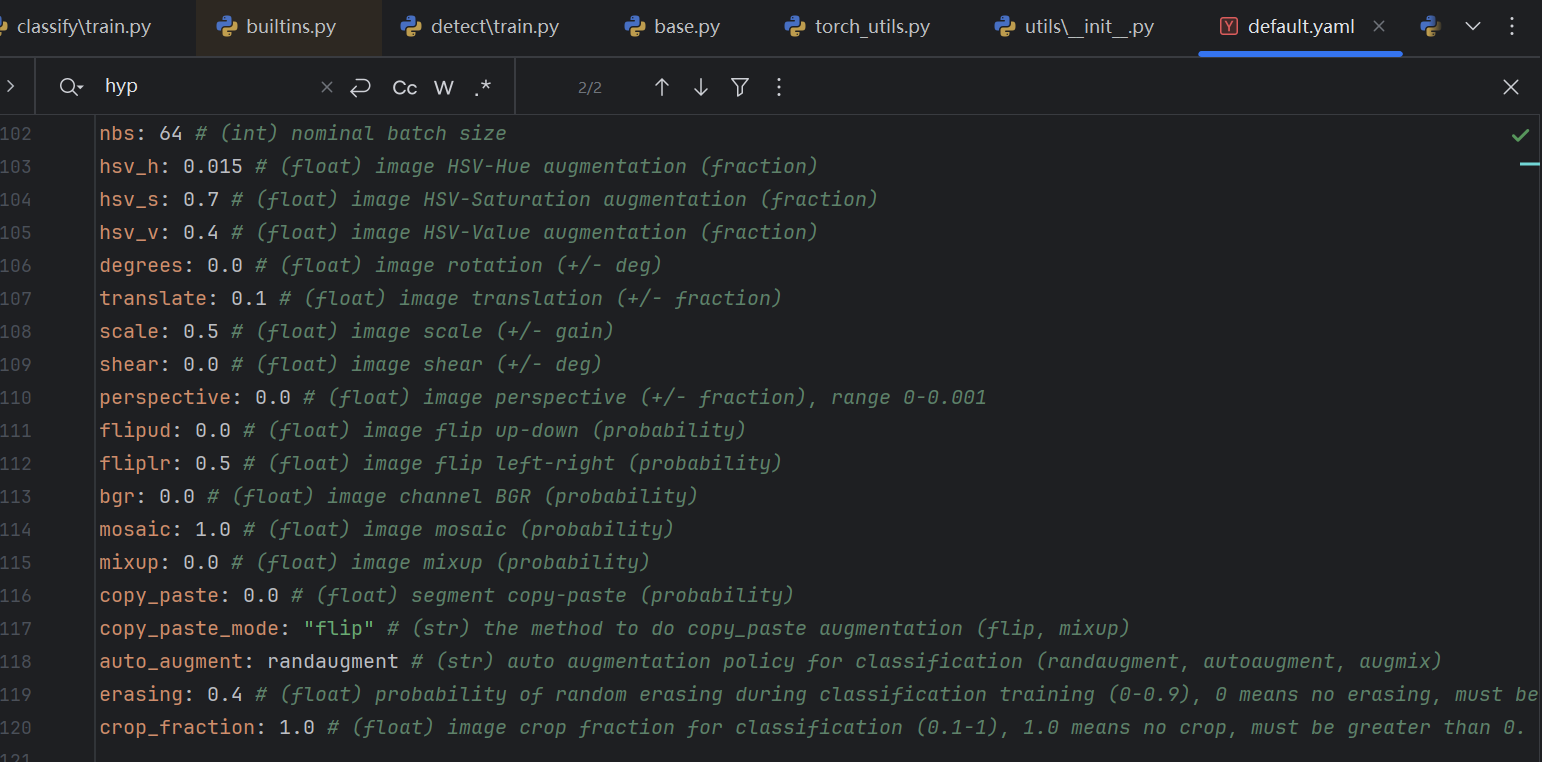
比方说,这里配置了马赛克变换和mixup变换的概率,分别是1和0,也就是说,所有的输入图像都进行马赛克变换,而不进行mixup变换(关于这两个变换的具体内容请参考我上一篇文章 Ultralytics 代码库深度解读【五】:数据预处理与增强Pipeline)。
- 路径处理机制 :在初始化过程中,系统需要将输入的路径转换为标准格式。Ultralytics使用
Path类来处理路径,这确保了跨平台的兼容性。路径处理不仅仅是简单的字符串操作,还包括路径验证、格式转换、相对路径转换为绝对路径等复杂操作。 - 图像文件发现 :
get_img_files()方法负责发现数据集中所有的图像文件。这个过程需要遍历指定的目录,识别有效的图像文件格式。Ultralytics支持多种图像格式,包括JPG、PNG、BMP等。文件发现过程还需要处理子目录、符号链接、文件过滤等复杂情况。
python
self.im_files = self.get_img_files(self.img_path)- 解析标签 :在YOLODataset中,
get_labels()方法会解析YOLO格式的标签文件(.txt),将图像和标签关联起来。update_labels()根据classes参数过滤特定类别,支持single_cls模式(将所有类别视为同一类),同步更新边界框、分割掩码、关键点等标签信息。
python
self.labels = self.get_labels()
self.update_labels(include_class=classes) # single_cls and include_class- 矩形训练设置:将具有相似宽高比的图像组织在同一批次中,减少填充,提高训练效率。
python
self.rect = rect
self.batch_size = batch_size
self.stride = stride
self.pad = pad
if self.rect:
assert self.batch_size is not None
self.set_rectangle()- 内存管理策略:BaseDataset在初始化时就考虑了内存管理问题。它创建了ims列表来存储图像缓存,这个列表的初始值都是None,表示图像尚未加载。这种延迟加载策略可以有效控制内存使用,避免在初始化时就加载所有图像数据。
- 缓存机制初始化 :缓存是数据加载性能优化的关键技术。
BaseDataset初始化时会根据cache参数设置缓存策略。
🎨 如果启用RAM缓存,系统会创建一个与图像文件数量相同的列表,用于存储加载的图像数据。
🎨 如果启用disk缓存,系统会为每个图像文件创建对应的.npy缓存文件路径。
python
# Cache images (options are cache = True, False, None, "ram", "disk")
self.ims, self.im_hw0, self.im_hw = [None] * self.ni, [None] * self.ni, [None] * self.ni
self.npy_files = [Path(f).with_suffix(".npy") for f in self.im_files]
self.cache = cache.lower() if isinstance(cache, str) else "ram" if cache is True else None
if self.cache == "ram" and self.check_cache_ram():
if hyp.deterministic:
LOGGER.warning(
"WARNING ⚠️ cache='ram' may produce non-deterministic training results. "
"Consider cache='disk' as a deterministic alternative if your disk space allows."
)
self.cache_images()
elif self.cache == "disk" and self.check_cache_disk():
self.cache_images()- 创建增强Pipeline:创建创建增强Pipeline,对加载的数据集进行统一数据变换,这样可以丰富数据集,提升神经网络的鲁棒性。这部分在上一篇文章中有详细介绍,不再赘述。
yaml
self.transforms = self.build_transforms(hyp=hyp)3.2 YOLODataset初始化方法
YOLODataset继承自BaseDataset,实现了YOLO特定的数据加载逻辑:
python
class YOLODataset(BaseDataset):
def __init__(self, *args, data=None, task="detect", **kwargs):
"""Initializes the YOLODataset with optional configurations for segments and keypoints."""
self.use_segments = task == "segment"
self.use_keypoints = task == "pose"
self.use_obb = task == "obb"
self.data = data
assert not (self.use_segments and self.use_keypoints), "Can not use both segments and keypoints."
super().__init__(*args, **kwargs)相较而言,YOLODataset类的初始化方法就比较简单了,由于单纯的目标检测并不涉及分割和关键点检测,所以最开始的几个属性都是None:
python
self.use_segments = None
self.use_keypoints = None
self.use_obb = None其中,"obb"的含义为旋转目标框检测任务,因此这个属性也是空。
python
assert not (self.use_segments and self.use_keypoints), "Can not use both segments and keypoints."
super().__init__(*args, **kwargs)💊assert 断言,当任务同时配置为目标分割和关键点检测的时候,会抛出异常。
💊调用父类(BaseDataset)的初始化方法,让父类完成初始化
4. 数据加载核心流程设计
4.1 读取图像与标签
目标检测是YOLO的核心任务,其数据加载有特定的要求。
4.1.1 📐图像路径扫描
获取图像文件的函数在BaseDataset类中,其实现具体如下:
python
def get_img_files(self, img_path):
"""Read image files."""
try:
f = [] # image files
for p in img_path if isinstance(img_path, list) else [img_path]:
p = Path(p) # os-agnostic
if p.is_dir(): # dir
f += glob.glob(str(p / "**" / "*.*"), recursive=True)
# F = list(p.rglob('*.*')) # pathlib
elif p.is_file(): # file
with open(p) as t:
t = t.read().strip().splitlines()
parent = str(p.parent) + os.sep
f += [x.replace("./", parent) if x.startswith("./") else x for x in t] # local to global path
# F += [p.parent / x.lstrip(os.sep) for x in t] # local to global path (pathlib)
else:
raise FileNotFoundError(f"{self.prefix}{p} does not exist")
im_files = sorted(x.replace("/", os.sep) for x in f if x.split(".")[-1].lower() in IMG_FORMATS)
# self.img_files = sorted([x for x in f if x.suffix[1:].lower() in IMG_FORMATS]) # pathlib
assert im_files, f"{self.prefix}No images found in {img_path}. {FORMATS_HELP_MSG}"
except Exception as e:
raise FileNotFoundError(f"{self.prefix}Error loading data from {img_path}\n{HELP_URL}") from e
if self.fraction < 1:
im_files = im_files[: round(len(im_files) * self.fraction)] # retain a fraction of the dataset
return im_files首先对需要加载的图片路径类型进行判断,如果是列表,则直接遍历,如果不是,则将其封装成列表后再遍历。
python
for p in img_path if isinstance(img_path, list) else [img_path]:然后做了路径标准化,确保在Windows、Linux、macOS上行为一致。
python
p = Path(p) # os-agnostic不同的系统中,路径的表示方法可能会不同,则会影响到数据集的读取。
python
# Windows
p = Path("data\\images\\train") # 自动处理反斜杠
# Linux
p = Path("data/images/train") # 自动处理正斜杠对路径进行统一化处理:
📏p.is_dir(): 检查路径是否为目录
📏p / "**" / "*.*": Path对象的连接操作,**: 递归匹配所有子目录,*.*: 匹配所有带扩展名的文件。
📏recursive=True: 启用递归搜索
📏str(): 将Path对象转换为字符串以供glob使用
python
if p.is_dir(): # dir
f += glob.glob(str(p / "**" / "*.*"), recursive=True)对文件进行统一化处理:
python
elif p.is_file(): # file
with open(p) as t:
t = t.read().strip().splitlines()
parent = str(p.parent) + os.sep
f += [x.replace("./", parent) if x.startswith("./") else x for x in t] # local to global path
# F += [p.parent / x.lstrip(os.sep) for x in t] # local to global path (pathlib)如果文件是./images这样的相对路径 方式对图片进行描述,将其修改为绝对路径 。
比方说,数据集中常有 image_list.txt这样的描述文件,读取有,t的取值如下:
python
# t = ["./images/train2017/000000000001.jpg",
# "./images/train2017/000000000002.jpg",
# "./images/val2017/000000000139.jpg"]修改后变成了:
python
# t = [""project/data/images/train2017/000000000001.jpg",
# ""project/data/images/train2017/000000000002.jpg",
# ""project/data/images/val2017/000000000139.jpg"]这样做,可以有效防止在后续的图像处理中,读取不到图像文件。
f会逐个将其加起来,方便后续读取:
python
# 最终 f = ["project/data/images/train2017/000000000001.jpg",
# "project/data/images/train2017/000000000002.jpg",
# "project/data/images/val2017/000000000139.jpg"]为了保证在处理中不出错,还要检查读取到的图像格式是否支持,且为避免后续处理出现问题,还对整理后的结果进行了排序。
python
im_files = sorted(x.replace("/", os.sep) for x in f if x.split(".")[-1].lower() in IMG_FORMATS)找到变量的定义,可以看到,其实支持了很多种的图片格式:
python
IMG_FORMATS = {"bmp", "dng", "jpeg", "jpg", "mpo", "png", "tif", "tiff", "webp", "pfm", "heic"} # image suffixespython的sorted()方法底层,是归并排序 与插入排序 相结合的Timsort 算法。其核心思路是:
🔨先扫描数组,找出已经有序的子序列(称为 "run");
🔨对短的 run 用插入排序补全到指定长度(默认 64);
🔨用归并排序将这些 run 合并成更大的有序序列,直到整个数组有序。
排序属于非常基础的知识,关于基础的排序算法,可以看我的另一篇文章:十大经典排序算法(C语言实现)
最后,根据需要的比例,读取需要的样本数量。并返回读取结果。
python
if self.fraction < 1:
im_files = im_files[: round(len(im_files) * self.fraction)] # retain a fraction of the dataset🍡 应用举例
假设我们要使用COCO数据集进行YOLOv8训练,其目录结构如下:
yaml
coco_dataset/
├── images/
│ ├── train2017/
│ │ ├── 000000000001.jpg
│ │ ├── 000000000002.jpg
│ │ └── ...
│ └── val2017/
│ ├── 000000000139.jpg
│ ├── 000000000285.jpg
│ └── ...
├── labels/
│ ├── train2017/
│ │ ├── 000000000001.txt
│ │ ├── 000000000002.txt
│ │ └── ...
│ └── val2017/
│ ├── 000000000139.txt
│ ├── 000000000285.txt
│ └── ...
└── dataset.yaml具体执行过程如下:
python
img_path = "coco_dataset/images/train2017"
# 1. 初始化f列表
f = []
# 2. 检查路径类型
p = Path("coco_dataset/images/train2017")
if p.is_dir(): # True
# 3. 递归搜索所有文件
f = glob.glob(str(p / "**" / "*.*"), recursive=True)
# f现在包含类似这样的路径:
# ['coco_dataset/images/train2017/000000000001.jpg',
# 'coco_dataset/images/train2017/000000000002.jpg',
# ...]
# 4. 过滤图像文件
from ultralytics.data.utils import IMG_FORMATS # IMG_FORMATS = {"bmp", "dng", "jpeg", "jpg", "mpo", "png", "tif", "tiff", "webp", "pfm", "heic"}
im_files = sorted(x.replace("/", os.sep) for x in f if x.split(".")[-1].lower() in IMG_FORMATS)
# 只保留有效的图像文件,例如:
# ['coco_dataset\\images\\train2017\\000000000001.jpg',
# 'coco_dataset\\images\\train2017\\000000000002.jpg',
# ...]
# 5. 检查是否找到图像
assert im_files, "No images found in coco_dataset/images/train2017"
# 6. 如果设置了fraction参数,只取部分数据
# 例如fraction=0.1,只取10%的数据
if self.fraction < 1:
im_files = im_files[: round(len(im_files) * self.fraction)]
# 7. 返回图像文件列表
return im_files4.1.2 📐标签缓存构建
python
def get_labels(self):
"""Returns dictionary of labels for YOLO training."""
self.label_files = img2label_paths(self.im_files)
cache_path = Path(self.label_files[0]).parent.with_suffix(".cache")
try:
cache, exists = load_dataset_cache_file(cache_path), True # attempt to load a *.cache file
assert cache["version"] == DATASET_CACHE_VERSION # matches current version
assert cache["hash"] == get_hash(self.label_files + self.im_files) # identical hash
except (FileNotFoundError, AssertionError, AttributeError):
cache, exists = self.cache_labels(cache_path), False # run cache ops
# Display cache
nf, nm, ne, nc, n = cache.pop("results") # found, missing, empty, corrupt, total
if exists and LOCAL_RANK in {-1, 0}:
d = f"Scanning {cache_path}... {nf} images, {nm + ne} backgrounds, {nc} corrupt"
TQDM(None, desc=self.prefix + d, total=n, initial=n) # display results
if cache["msgs"]:
LOGGER.info("\n".join(cache["msgs"])) # display warnings
# Read cache
[cache.pop(k) for k in ("hash", "version", "msgs")] # remove items
labels = cache["labels"]
if not labels:
LOGGER.warning(f"WARNING ⚠️ No images found in {cache_path}, training may not work correctly. {HELP_URL}")
self.im_files = [lb["im_file"] for lb in labels] # update im_files
# Check if the dataset is all boxes or all segments
lengths = ((len(lb["cls"]), len(lb["bboxes"]), len(lb["segments"])) for lb in labels)
len_cls, len_boxes, len_segments = (sum(x) for x in zip(*lengths))
if len_segments and len_boxes != len_segments:
LOGGER.warning(
f"WARNING ⚠️ Box and segment counts should be equal, but got len(segments) = {len_segments}, "
f"len(boxes) = {len_boxes}. To resolve this only boxes will be used and all segments will be removed. "
"To avoid this please supply either a detect or segment dataset, not a detect-segment mixed dataset."
)
for lb in labels:
lb["segments"] = []
if len_cls == 0:
LOGGER.warning(f"WARNING ⚠️ No labels found in {cache_path}, training may not work correctly. {HELP_URL}")
return labels🚩1. 生成标签文件路径
首先,生成标签文件路径,将图像路径中的"/images/"替换为"/labels/",移除原扩展名,添加".txt"扩展名。
python
self.label_files = img2label_paths(self.im_files)
cache_path = Path(self.label_files[0]).parent.with_suffix(".cache")这里调用了一个转换函数,我们看看转换函数的定义:
python
def img2label_paths(img_paths):
"""Define label paths as a function of image paths."""
sa, sb = f"{os.sep}images{os.sep}", f"{os.sep}labels{os.sep}" # /images/, /labels/ substrings
return [sb.join(x.rsplit(sa, 1)).rsplit(".", 1)[0] + ".txt" for x in img_paths]虽然函数只有2行,但细节还是比价多。
首先,sa,sb是2个字符串,但字符串的具体内容会根据操作系统进行适配,比方说,Linux/Mac下:
c
# sa = "/images/"
# sb = "/labels/"再就是后续较为复杂的语句,首先会通过for循环依次遍历此前我们生成的图像路径,也就是im_files。
其中x.rsplit(sa, 1)意思就是将图像路径以image为边界进行拆分:
"data/coco/images/train2017/000000000001.jpg"→ "data/coco"+ "train2017/000000000001.jpg"
然后,sb.join()很好理解,就是用"/labels/"对其进行拼接,也就是:
"data/coco"+ "train2017/000000000001.jpg"→ "data/coco/labels/train2017/000000000001.jpg"
再然后,rsplit(".", 1)[0]按最后一个.分割,并取前半部分,也就是说,将文件的扩展名去掉。
"data/coco/labels/train2017/000000000001.jpg"→ "data/coco/labels/train2017/000000000001"
最后,加上.txt,完成路径修改。
"data/coco/labels/train2017/000000000001"→ "data/coco/labels/train2017/000000000001.txt"
比如输入的图像路径列表是这样的:
python
self.im_files = [
"data/coco/images/train2017/000000000001.jpg",
"data/coco/images/train2017/000000000002.jpg"
]那么转换后的标签路径列表就是这样的:
python
# 生成标签路径列表
self.label_files = [
"data/coco/labels/train2017/000000000001.txt",
"data/coco/labels/train2017/000000000002.txt"
]🚩2. 缓存文件创建与验证
🔨 尝试加载已缓存的标签数据
🔨 验证缓存版本和哈希值
🔨 如果缓存不存在或无效,重新生成缓存
先定义缓存路径:
python
cache_path = Path(self.label_files[0]).parent.with_suffix(".cache")读取当前列表首元素路径的父路径:
data/coco/labels/train2017/000000000001.txt→data/coco/labels/train2017
添加.cache扩展名:
data/coco/labels/train2017→data/coco/labels/train2017.cache
python
try:
cache, exists = load_dataset_cache_file(cache_path), True # attempt to load a *.cache file
assert cache["version"] == DATASET_CACHE_VERSION # matches current version
assert cache["hash"] == get_hash(self.label_files + self.im_files) # identical hash
except (FileNotFoundError, AssertionError, AttributeError):
cache, exists = self.cache_labels(cache_path), False # run cache ops尝试加载缓存文件,
如果有 缓存文件,则会加载缓存文件,且读取其版本与哈希值与当前已有的是否匹配,不匹配则抛出异常。
如果没有 缓存文件,则会创建缓存文件。创建缓存文件的相关代码解读请跳转本文→3.3 数据验证与过滤机制
有三种异常会被except 捕获:
- FileNotFoundError:缓存文件找不到。
- AssertionError:断言错误,版本检查不通过或者哈希值不匹配。
- AttributeError:属性错误,cache文件中读不到这两个属性的值。
找到版本宏定义,发现版本号是1.0.3
python
DATASET_CACHE_VERSION = "1.0.3"哈希值的计算,理论上是非常繁琐的,只是代码中python调用了库,显得比较简单。哈希检验是文件传输中非常常见的一种校验方式。
python
def get_hash(paths):
"""Returns a single hash value of a list of paths (files or dirs)."""
size = sum(os.path.getsize(p) for p in paths if os.path.exists(p)) # sizes
h = hashlib.sha256(str(size).encode()) # hash sizes
h.update("".join(paths).encode()) # hash paths
return h.hexdigest() # return hash💥那么,什么是sha256呢?这与sha512有什么区别呢?
- SHA-256输出长度为 256 位(32 字节)的哈希值,是 SHA-2 家族中最常用的算法,广泛用于数字签名、区块链(如比特币)、文件校验等场景。底层基于64轮迭代运算,初始哈希值为 8 个 32 位常数。
- SHA-384输出长度为 384 位(48 字节)的哈希值,可看作是 SHA-512 的 "截断版本"------ 它使用与 SHA-512 相同的运算逻辑,但初始哈希值不同,且最终输出舍弃 SHA-512 结果的后 128 位。适用于对安全性要求高于 SHA-256、但输出长度不需要 512 位的场景(如证书签名)。
- SHA-512输出长度为 512 位(64 字节)的哈希值,是 SHA-2 家族中安全性最高的算法之一。底层基于 80 轮 迭代运算,初始哈希值为 8 个 64 位常数,运算效率在 64 位处理器上优于 SHA-256(因为按 64 位字长处理数据)。
可以看到,软件中是基于文件路径大小和路径本身生成的哈希值,如果恰好是文件本身发生了改变,而文件大小和路径都没变,则会出现校验漏洞。但这种概率很小,忽略不计。况且软件中设计了其他很多方法,避免出现数据不完整的问题,比如verify_image_label()这种函数。
🚩3. 显示缓存加载信息
这部分代码,主要是为了给开发者显示目前的缓存文件加载状态。
python
# Display cache
nf, nm, ne, nc, n = cache.pop("results") # found, missing, empty, corrupt, total
if exists and LOCAL_RANK in {-1, 0}:
d = f"Scanning {cache_path}... {nf} images, {nm + ne} backgrounds, {nc} corrupt"
TQDM(None, desc=self.prefix + d, total=n, initial=n) # display results
if cache["msgs"]:
LOGGER.info("\n".join(cache["msgs"])) # display warnings- nf (found):找到的图像数量
- nm (missing):缺失的标签文件数量
- ne (empty):空的标签文件数量
- nc (corrupt):损坏的图像/标签数量
- n (total):总图像数量
如果缓存文件存在,且软件是在单机训练或分布式训练的主进程(rank 0)中执行的,则显示加载情况,否则不加载。
python
LOCAL_RANK = int(os.getenv("LOCAL_RANK", -1)) 找到LOCAL_RANK 的定义,可以发现,它的值是实时从OS中读取的。
LOCAL_RANK = -1:单机训练
LOCAL_RANK = 0:分布式训练的主进程
再重新整理数据,生成进度条显示:
- cache_path:缓存文件路径
- {nf} images:找到的有效图像数量
- {nm + ne} backgrounds:背景数量(缺失标签+空标签)
- {nc} corrupt:损坏文件数量
🍒举个例子:
python
"Scanning data/coco/labels/train2017.cache... 118000 images, 150 backgrounds, 27 corrupt"然后显示进度条:
python
TQDM(None, desc=self.prefix + d, total=n, initial=n) # display resultsTQDM(None, ...):创建一个静态显示,不进行实际迭代
- desc=self.prefix + d:进度条描述文本
- total=n:总数(总图像数)
- initial=n:初始值(设置为总数,表示已完成)
如果有警告,打印出警告⚠️信息:
举个例子:
python
cache["msgs"] = [
"WARNING: image size (480, 640) <10 pixels",
"WARNING: corrupt JPEG restored and saved",
"WARNING: label class 81 exceeds dataset class count 80"🚩4. 读取缓存文件
依次读取哈希值,版本号,警告⚠️信息,组合成list。并加载缓存中的标签,如果标签为空,则弹出相应警告信息。然后再更新当前im_files,用于后续处理。
python
# Read cache
[cache.pop(k) for k in ("hash", "version", "msgs")] # remove items
labels = cache["labels"]
if not labels:
LOGGER.warning(f"WARNING ⚠️ No images found in {cache_path}, training may not work correctly. {HELP_URL}")
self.im_files = [lb["im_file"] for lb in labels] # update im_files🚩5. 检查文件信息
依次读取标签文件中的类别数,边界框数,分割边界,对其进行判别。
如果边界框数≠分割边界数,则打印出告相关警告⚠️信息。
如果类别数为0,肯定也是有问题的,印出告相关警告⚠️信息。
最后返回标签。
python
# Check if the dataset is all boxes or all segments
lengths = ((len(lb["cls"]), len(lb["bboxes"]), len(lb["segments"])) for lb in labels)
len_cls, len_boxes, len_segments = (sum(x) for x in zip(*lengths))
if len_segments and len_boxes != len_segments:
LOGGER.warning(
f"WARNING ⚠️ Box and segment counts should be equal, but got len(segments) = {len_segments}, "
f"len(boxes) = {len_boxes}. To resolve this only boxes will be used and all segments will be removed. "
"To avoid this please supply either a detect or segment dataset, not a detect-segment mixed dataset."
)
for lb in labels:
lb["segments"] = []
if len_cls == 0:
LOGGER.warning(f"WARNING ⚠️ No labels found in {cache_path}, training may not work correctly. {HELP_URL}")
return labels4.1.3 📐单样本标签加载
python
def get_image_and_label(self, index):
"""Get and return label information from the dataset."""
label = deepcopy(self.labels[index]) # requires deepcopy() https://github.com/ultralytics/ultralytics/pull/1948
label.pop("shape", None) # shape is for rect, remove it
label["img"], label["ori_shape"], label["resized_shape"] = self.load_image(index)
label["ratio_pad"] = (
label["resized_shape"][0] / label["ori_shape"][0],
label["resized_shape"][1] / label["ori_shape"][1],
) # for evaluation
if self.rect:
label["rect_shape"] = self.batch_shapes[self.batch[index]]
return self.update_labels_info(label)🚩1. 深拷贝标签数据
使用深拷贝避免修改原始标签数据,防止数据污染。
python
label = deepcopy(self.labels[index]) # requires deepcopy() 🚩2. 移除形状信息
"shape"字段仅在矩形训练时使用,避免后续处理中的冲突。
python
label.pop("shape", None) # shape is for rect, remove it🚩3. 加载图像数据
获取原始图像、原始尺寸和调整后尺寸,将这些信息添加到标签字典中。
python
label["img"], label["ori_shape"], label["resized_shape"] = self.load_image(index)🚩4. 计算比例填充参数
计算图像缩放比例,用于后续评估和坐标转换,(高缩放比, 宽缩放比)
python
label["ratio_pad"] = (
label["resized_shape"][0] / label["ori_shape"][0],
label["resized_shape"][1] / label["ori_shape"][1],
) # for evaluation🚩5. 矩形训练支持
如果启用矩形训练,添加批次形状信息,用于保持批次内图像的宽高比。
python
if self.rect:
label["rect_shape"] = self.batch_shapes[self.batch[index]]🚩6. 更新标签信息格式
调用update_labels_info方法,将标签数据转换为训练所需的格式,返回最终的标签数据。
python
return self.update_labels_info(label)关于update_labels_info()的详细解读,请跳转→6.1 标签标准化
🍒举个例子:
输入信息为:
python
self.labels[0] = {
"im_file": "data/coco/images/train2017/000000000001.jpg",
"shape": (480, 640),
"cls": array([[0], [1]]),
"bboxes": array([[0.45, 0.55, 0.2, 0.3], [0.75, 0.35, 0.15, 0.25]]),
"segments": [],
"keypoints": None,
"normalized": True,
"bbox_format": "xywh"
}输出信息为:
python
{
"img": image_array, # 加载的图像
"ori_shape": (480, 640), # 原始图像尺寸
"resized_shape": (640, 640), # 调整后图像尺寸
"ratio_pad": (1.333, 1.0), # 缩放比例
"instances": Instances_object, # 统一格式的实例数据
# ... 其他字段
}4.2 InfiniteDataLoader设计原理
Ultralytics使用自定义的InfiniteDataLoader来优化训练过程,这种设计解决了传统DataLoader在训练过程中可能出现的数据耗尽问题。
python
class InfiniteDataLoader(dataloader.DataLoader):
"""
Dataloader that reuses workers.
Uses same syntax as vanilla DataLoader.
"""
def __init__(self, *args, **kwargs):
"""Dataloader that infinitely recycles workers, inherits from DataLoader."""
super().__init__(*args, **kwargs)
object.__setattr__(self, "batch_sampler", _RepeatSampler(self.batch_sampler))
self.iterator = super().__iter__()
def __len__(self):
"""Returns the length of the batch sampler's sampler."""
return len(self.batch_sampler.sampler)
def __iter__(self):
"""Creates a sampler that repeats indefinitely."""
for _ in range(len(self)):
yield next(self.iterator)
def reset(self):
"""
Reset iterator.
This is useful when we want to modify settings of dataset while training.
"""
self.iterator = self._get_iterator()- 💥 无限迭代的必要性 :在深度学习训练中,通常需要多个epoch来充分训练模型。如果数据集较小,传统的DataLoader可能在训练过程中就遍历完所有数据,导致训练提前结束。InfiniteDataLoader通过无限循环确保训练可以持续进行,直到达到预设的训练步数。
- 💥 内存效率考虑:InfiniteDataLoader不是简单地重复加载所有数据,而是通过智能的迭代器管理,在数据集遍历完毕后重新开始,但保持内存中的缓存数据。这种设计在保证无限迭代的同时,最大化了内存使用效率。
- 💥 训练稳定性:无限数据加载器确保了训练过程的连续性,避免了因数据耗尽导致的训练中断。这对于长时间训练和大规模模型训练尤为重要。
🚩 1. InfiniteDataLoader类的__init__方法
python
def __init__(self, *args, **kwargs):
"""Dataloader that infinitely recycles workers, inherits from DataLoader."""
super().__init__(*args, **kwargs)
object.__setattr__(self, "batch_sampler", _RepeatSampler(self.batch_sampler))
self.iterator = super().__iter__()父类是底层的dataloader.DataLoader,看不到底层的实现细节的,但是并不影响对这部分代码的理解。
先调用了父类的初始化方法,将相关参数传入,然后创建了一个重复采样器,自己的迭代器也是源自父类。所以我们看看这个重复采样器。
python
class _RepeatSampler
def __init__(self, sampler):
"""Initializes an object that repeats a given sampler indefinitely."""
self.sampler = sampler
def __iter__(self):
"""Iterates over the 'sampler' and yields its contents."""
while True:
yield from iter(self.sampler)这个也不难理解,就是在死循环中放置了一个生成器,然后可以一直产生训练样本。
紧接着,自己定义了一个迭代器,继承自父类。
🚩 2. InfiniteDataLoader类的__iter__方法
python
def __iter__(self):
"""Creates a sampler that repeats indefinitely."""
for _ in range(len(self)):
yield next(self.iterator)此方法在类的实例被迭代的时候被自动调用。用生成器生成训练所需样本。更加确切地说,是在BaseTrainer._do_train()函数中,在训练过程中被调用。
python
pbar = TQDM(enumerate(self.train_loader), total=nb)4.3 多进程数据加载优化
多进程数据加载是现代深度学习框架中提高数据加载效率的关键技术。Ultralytics在这一方面做了大量优化。
python
def build_dataloader(dataset, batch, workers, shuffle=True, rank=-1):
"""Return an InfiniteDataLoader or DataLoader for training or validation set."""
batch = min(batch, len(dataset))
nd = torch.cuda.device_count() # number of CUDA devices
nw = min(os.cpu_count() // max(nd, 1), workers) # number of workers
sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
generator = torch.Generator()
generator.manual_seed(6148914691236517205 + RANK)
return InfiniteDataLoader(
dataset=dataset,
batch_size=batch,
shuffle=shuffle and sampler is None,
num_workers=nw,
sampler=sampler,
pin_memory=PIN_MEMORY,
collate_fn=getattr(dataset, "collate_fn", None),
worker_init_fn=seed_worker,
generator=generator,
)该函数是数据加载的核心配置函数,为训练 和验证提供优化的DataLoader配置。具体来说,具有以下特点:
- 💫工作进程管理:workers参数控制并行加载数据的工作进程数量。合理设置这个参数对训练效率至关重要。如果设置过小,CPU利用率不足,GPU会等待数据;如果设置过大,进程切换开销会增加,反而降低效率。
- 💫进程间通信:多进程加载需要解决进程间的数据传输问题。PyTorch使用共享内存和队列机制来实现高效的数据传输。Ultralytics在此基础上进一步优化,减少通信开销。
- 💫负载均衡:系统确保各个工作进程之间的负载均衡,避免某些进程过载而其他进程空闲的情况。这通过智能的数据分配算法实现。
- 💫持久化工作进程 :
persistent_workers=True参数确保工作进程在数据集遍历完毕后不被销毁,而是保持活跃状态。这减少了进程创建和销毁的开销,提高了长期训练的效率。 - 💫内存共享:在多进程环境中,系统需要考虑内存的共享和复制。Ultralytics使用共享内存技术减少数据复制的开销,同时确保数据的安全性。
🚩1. 参数处理
💊确定样本数量
每次加载的样本数量,限制批次大小不超过数据集大小。
python
batch = min(batch, len(dataset))💊检测CUDA设备数量
检测可用的CUDA设备数量,用于优化多线程设置。
python
nd = torch.cuda.device_count() # number of CUDA devices💊进程数量计算
python
nw = min(os.cpu_count() // max(nd, 1), workers) # number of workers假设: CPU核心数=8, GPU数量=2, workers=4,经计算 nw = 4,这个时候会创建4个进程。
💊分布式采样器设置
python
sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)- rank == -1:单机训练,不使用采样器
- rank != -1:分布式训练,使用
DistributedSampler
分布式训练中确保每个GPU处理不同的数据子集,避免数据重复。
💊随机数生成器设置
创建独立的随机数生成器,使用固定种子 + RANK 确保可重现性,每个进程有不同但可预测的种子。
python
generator = torch.Generator()
generator.manual_seed(6148914691236517205 + RANK)🚩2. DataLoader参数配置
python
return InfiniteDataLoader(
dataset=dataset,
batch_size=batch,
shuffle=shuffle and sampler is None,
num_workers=nw,
sampler=sampler,
pin_memory=PIN_MEMORY,
collate_fn=getattr(dataset, "collate_fn", None),
worker_init_fn=seed_worker,
generator=generator,
)参数解释:
python
shuffle=shuffle and sampler is None- 如果使用采样器(分布式训练),采样器负责打乱
- 如果不使用采样器,DataLoader负责打乱
python
pin_memory=PIN_MEMORY,启用内存锁定,加速GPU传输,提高数据传输效率
python
collate_fn=getattr(dataset, "collate_fn", None),尝试从数据集中获取自定义批次合并函数,如果不存在,使用默认函数。
python
worker_init_fn=seed_worker,使用seed_worker函数初始化工作进程,确保每个工作进程的随机种子不同。
4.4 批次合并机制
批次合并是数据加载过程中的关键步骤,它将多个单独的样本合并成一个批次,供模型训练使用。
python
@staticmethod
def collate_fn(batch):
"""Collates data samples into batches."""
new_batch = {}
keys = batch[0].keys()
values = list(zip(*[list(b.values()) for b in batch]))
for i, k in enumerate(keys):
value = values[i]
if k == "img":
value = torch.stack(value, 0)
if k in {"masks", "keypoints", "bboxes", "cls", "segments", "obb"}:
value = torch.cat(value, 0)
new_batch[k] = value
new_batch["batch_idx"] = list(new_batch["batch_idx"])
for i in range(len(new_batch["batch_idx"])):
new_batch["batch_idx"][i] += i # add target image index for build_targets()
new_batch["batch_idx"] = torch.cat(new_batch["batch_idx"], 0)
return new_batch- 💫批次大小控制:batch_size参数决定了每个批次包含的样本数量。批次大小的选择需要平衡内存使用和训练效率。较大的批次可以提高GPU利用率,但需要更多的内存;较小的批次内存需求少,但可能无法充分利用GPU的并行计算能力。
🔑batch_size默认值为16,在get_dataloader()函数的定义中可以看到。
python
def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode="train"):- 💫数据类型统一:批次合并需要确保所有样本的数据类型一致。图像数据通常转换为PyTorch张量,标签数据也需要转换为相应的格式。这种转换需要保持数据的精度和完整性。
- 💫形状对齐:不同样本的图像可能有不同的原始尺寸,批次合并需要将它们调整为相同的尺寸。这通常通过填充或裁剪实现,同时需要相应地调整标签信息。
- 💫标签索引管理:在批次合并过程中,需要为每个样本在批次中的位置建立索引,以便在后续处理中能够正确关联图像和标签。
🍒举个例子:
为方便理解,还是直接举例说明吧。
比方说有2个输入样本,原始样本数据如下:
python
batch = [
# 样本1
{
"img": torch.tensor([3, 640, 640]), # 图像: [C, H, W]
"cls": torch.tensor([[0], [1]]), # 类别: [n1, 1],2个目标
"bboxes": torch.tensor([[0.45, 0.55, 0.2, 0.3],
[0.75, 0.35, 0.15, 0.25]]), # 边界框: [n1, 4]
"batch_idx": torch.tensor([0,0]) # 批次索引
},
# 样本2
{
"img": torch.tensor([3, 640, 640]), # 图像: [C, H, W]
"cls": torch.tensor([[2]]), # 类别: [n2, 1],1个目标
"bboxes": torch.tensor([[0.3, 0.6, 0.25, 0.3]]), # 边界框: [n2, 4]
"batch_idx": torch.tensor([0]) # 批次索引
}
]💊先提取各个key:
python
keys = batch[0].keys()这个时候keys = (['img', 'cls', 'bboxes', 'batch_idx'])。
💊提取值并转置:
python
values = list(zip(*[list(b.values()) for b in batch]))先逐一取出各个key对应的value:
python
[[img1, cls1, bboxes1, batch_idx1], [img2, cls2, bboxes2, batch_idx2]]然后再进行转置:
python
values = [(img1, img2), (cls1, cls2), (bboxes1, bboxes2), (batch_idx1, batch_idx2)]注:为方便理解,此处的img1, img2只是其中的value代号,不是实际数值。
💊将相同属性的内容合并在一起:
合并image:
python
结果: torch.tensor([2, 3, 640, 640]) # [B, C, H, W]合并类别信息:
python
结果: torch.tensor([[0], [1], [2]])合并边界框:
python
结果: torch.tensor([[0.45, 0.55, 0.2, 0.3],
[0.75, 0.35, 0.15, 0.25],
[0.3, 0.6, 0.25, 0.3]]) 合并批次索引:
new_batch字典会将这些合并后的键值对再统一管理起来,方便后续处理,比方说对于索引,合并后是这样的:
python
new_batch["batch_idx"] = (tensor([0,0]), tensor([0]))批次索引修正:
python
new_batch["batch_idx"] = list(new_batch["batch_idx"])
for i in range(len(new_batch["batch_idx"])):
new_batch["batch_idx"][i] += i # add target image index for build_targets()将批次的索引转换成列表形式,然后再对索引按照顺序加1,这样就可以将检测目标与图像对应起来。
处理后:
python
new_batch["batch_idx"] = tensor([0,0,1])最终输出:
python
new_batch = {
"img": torch.tensor([2, 3, 640, 640]), # [B, C, H, W]
"cls": torch.tensor([[0], [1], [2]]), # [total_objects, 1],总共3个目标
"bboxes": torch.tensor([[0.45, 0.55, 0.2, 0.3],
[0.75, 0.35, 0.15, 0.25],
[0.3, 0.6, 0.25, 0.3]]), # [total_objects, 4]
"batch_idx": torch.tensor([0, 0, 1]) # [total_objects],标识每个目标属于哪个图像
}batch_idx的处理非常巧妙,否则各个检测目标与图像无法准确对应。
5. 数据缓存与内存优化
5.1 标签缓存策略
标签缓存策略是通过cache_labels ()文件来实现的。在get_labels ()中被调用(关于get_labels ()函数具体内容请跳转→4.1.2 📐获取标签)。
python
def cache_labels(self, path=Path("./labels.cache")):
"""
Cache dataset labels, check images and read shapes.
Args:
path (Path): Path where to save the cache file. Default is Path("./labels.cache").
Returns:
(dict): labels.
"""
x = {"labels": []}
nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number missing, found, empty, corrupt, messages
desc = f"{self.prefix}Scanning {path.parent / path.stem}..."
total = len(self.im_files)
nkpt, ndim = self.data.get("kpt_shape", (0, 0))
if self.use_keypoints and (nkpt <= 0 or ndim not in {2, 3}):
raise ValueError(
"'kpt_shape' in data.yaml missing or incorrect. Should be a list with [number of "
"keypoints, number of dims (2 for x,y or 3 for x,y,visible)], i.e. 'kpt_shape: [17, 3]'"
)
with ThreadPool(NUM_THREADS) as pool:
results = pool.imap(
func=verify_image_label,
iterable=zip(
self.im_files,
self.label_files,
repeat(self.prefix),
repeat(self.use_keypoints),
repeat(len(self.data["names"])),
repeat(nkpt),
repeat(ndim),
),
)
pbar = TQDM(results, desc=desc, total=total)
for im_file, lb, shape, segments, keypoint, nm_f, nf_f, ne_f, nc_f, msg in pbar:
nm += nm_f
nf += nf_f
ne += ne_f
nc += nc_f
if im_file:
x["labels"].append(
{
"im_file": im_file,
"shape": shape,
"cls": lb[:, 0:1], # n, 1
"bboxes": lb[:, 1:], # n, 4
"segments": segments,
"keypoints": keypoint,
"normalized": True,
"bbox_format": "xywh",
}
)
if msg:
msgs.append(msg)
pbar.desc = f"{desc} {nf} images, {nm + ne} backgrounds, {nc} corrupt"
pbar.close()
if msgs:
LOGGER.info("\n".join(msgs))
if nf == 0:
LOGGER.warning(f"{self.prefix}WARNING ⚠️ No labels found in {path}. {HELP_URL}")
x["hash"] = get_hash(self.label_files + self.im_files)
x["results"] = nf, nm, ne, nc, len(self.im_files)
x["msgs"] = msgs # warnings
save_dataset_cache_file(self.prefix, path, x, DATASET_CACHE_VERSION)
return x- 图像完整性验证:系统使用OpenCV库读取图像文件,验证图像是否能够正确加载。如果图像文件损坏或格式不支持,系统会记录错误并跳过该图像。这种验证机制避免了因图像问题导致的训练中断。
- 标签格式验证:对于YOLO格式的标签,系统验证每一行的格式是否正确,数值是否在有效范围内。边界框的坐标必须在0,1范围内,类别ID必须是有效的整数。这种验证确保了标签数据的正确性。
- 图像-标签匹配验证:系统验证每个图像文件是否都有对应的标签文件,以及标签文件中的信息是否与图像尺寸匹配。这种匹配验证确保了数据的一致性。
- 边界框有效性过滤:系统过滤掉无效的边界框,包括面积为0的边界框、坐标超出图像范围的边界框、格式错误的边界框等。这种过滤提高了训练数据的质量。
- 数据统计与报告:验证过程会生成详细的统计报告,包括有效图像数量、无效数据数量、各类别的分布情况等。这些统计信息有助于了解数据集的质量和特性。
🚩1. 创建变量和keypoints验证
创建并初始化相关变量,检查关键点数据是否有确实。
python
x = {"labels": []}
nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number missing, found, empty, corrupt, messages
desc = f"{self.prefix}Scanning {path.parent / path.stem}..."
total = len(self.im_files)
nkpt, ndim = self.data.get("kpt_shape", (0, 0))
if self.use_keypoints and (nkpt <= 0 or ndim not in {2, 3}):
raise ValueError(
"'kpt_shape' in data.yaml missing or incorrect. Should be a list with [number of "
"keypoints, number of dims (2 for x,y or 3 for x,y,visible)], i.e. 'kpt_shape: [17, 3]'"
)- x:初始化缓存数据结构,包含一个空的标签列表
统计变量初始化:
- nm:缺失标签数量
- nf:找到标签数量
- ne:空标签数量
- nc:损坏文件数量
- msgs:警告消息列表
然后再创建进度条需要的变量。
- desc:构建进度条描述文本
- total:总文件数量(用于进度条)
- nkpt, ndim:关键点形状参数 (用于姿态估计任务,当前任务不涉及)
后面if是片段关键点参数是否异常的,当前任务不涉及。
🚩2. 并行处理设置(需补充关于verify_image_label的部分)
创建线程池进行并行处理,使用verify_image_label函数验证每个图像-标签对,通过zip将多个参数打包传递给验证函数。
python
with ThreadPool(NUM_THREADS) as pool:
results = pool.imap(
func=verify_image_label,
iterable=zip(
self.im_files,
self.label_files,
repeat(self.prefix),
repeat(self.use_keypoints),
repeat(len(self.data["names"])),
repeat(nkpt),
repeat(ndim),
),
)我的jetson orin super总共有6个CPU内核,所以NUM_THREADS的值是5,也就是说,会创建5个线程(剩下的一个留给其他任务)。
python
NUM_THREADS = min(8, max(1, os.cpu_count() - 1)) # number of YOLO multiprocessing threads🚩3. 构建标签数据
python
pbar = TQDM(results, desc=desc, total=total)
for im_file, lb, shape, segments, keypoint, nm_f, nf_f, ne_f, nc_f, msg in pbar:
nm += nm_f
nf += nf_f
ne += ne_f
nc += nc_f
if im_file:
x["labels"].append(
{
"im_file": im_file,
"shape": shape,
"cls": lb[:, 0:1], # n, 1
"bboxes": lb[:, 1:], # n, 4
"segments": segments,
"keypoints": keypoint,
"normalized": True,
"bbox_format": "xywh",
}
)
if msg:
msgs.append(msg)
pbar.desc = f"{desc} {nf} images, {nm + ne} backgrounds, {nc} corrupt"
pbar.close()累加各种统计信息(缺失、找到、空、损坏),构建标签信息,并实时更新进度条显示。
🚩4. 日志输出
python
if msgs:
LOGGER.info("\n".join(msgs))
if nf == 0:
LOGGER.warning(f"{self.prefix}WARNING ⚠️ No labels found in {path}. {HELP_URL}")输出验证中发现的问题。
另外,如果没有找到标签,也会输出警告⚠️信息。
🚩5. 缓存数据添加与保存
python
x["hash"] = get_hash(self.label_files + self.im_files)
x["results"] = nf, nm, ne, nc, len(self.im_files)
x["msgs"] = msgs # warnings
save_dataset_cache_file(self.prefix, path, x, DATASET_CACHE_VERSION)计算数据集哈希值用于后续验证,存储统计结果,保存警告信息,将完整缓存数据保存到文件。
🍒举个例子:
我们还是用熟悉的COCO数据集举例子
初始的输入数据如下:
python
self.im_files = [
"data/coco/images/train2017/000000000001.jpg",
"data/coco/images/train2017/000000000002.jpg"
]
self.label_files = [
"data/coco/labels/train2017/000000000001.txt",
"data/coco/labels/train2017/000000000002.txt"
]并行处理过程中,每个线程会调用:
python
verify_image_label( ("data/coco/images/train2017/000000000001.jpg",
"data/coco/labels/train2017/000000000001.txt",
"Dataset: ", False, 80, 0, 0)输出标签如下:
python
x = {
"labels": [
{
"im_file": "data/coco/images/train2017/000000000001.jpg",
"shape": (480, 640), # 图像原始尺寸 (高, 宽)
"cls": array([[0], [1], [2]]), # 类别: 人(0), 车(1), 猫(2)
"bboxes": array([
[0.45, 0.55, 0.2, 0.3], # 人的边界框 (x_center, y_center, width, height)
[0.75, 0.35, 0.15, 0.25], # 车的边界框
[0.25, 0.85, 0.1, 0.15] # 猫的边界框
]), # 归一化xywh格式
"segments": [], # 分割信息(检测任务为空)
"keypoints": None, # 关键点信息(检测任务为None)
"normalized": True, # 坐标已归一化
"bbox_format": "xywh" # 边界框格式
},
{
"im_file": "data/coco/images/train2017/000000000002.jpg",
"shape": (600, 800), # 图像原始尺寸 (高, 宽)
"cls": array([[3], [4]]), # 类别: 狗(3), 椅子(4)
"bboxes": array([
[0.3, 0.6, 0.25, 0.35], # 狗的边界框
[0.8, 0.7, 0.15, 0.2] # 椅子的边界框
]), # 归一化xywh格式
"segments": [], # 分割信息(检测任务为空)
"keypoints": None, # 关键点信息(检测任务为None)
"normalized": True, # 坐标已归一化
"bbox_format": "xywh" # 边界框格式
}
],
"hash": "a1b2c3d4e5f6...",
"results": (118000, 100, 50, 27, 118287), # (found, missing, empty, corrupt, total)
"msgs": ["WARNING: ..."]
}5.2 图像缓存策略
数据缓存是提高数据加载效率的重要手段,Ultralytics实现了多种缓存策略来适应不同的硬件环境和数据集特性。
python
def cache_images(self):
"""Cache images to memory or disk."""
b, gb = 0, 1 << 30 # bytes of cached images, bytes per gigabytes
fcn, storage = (self.cache_images_to_disk, "Disk") if self.cache == "disk" else (self.load_image, "RAM")
with ThreadPool(NUM_THREADS) as pool:
results = pool.imap(fcn, range(self.ni))
pbar = TQDM(enumerate(results), total=self.ni, disable=LOCAL_RANK > 0)
for i, x in pbar:
if self.cache == "disk":
b += self.npy_files[i].stat().st_size
else: # 'ram'
self.ims[i], self.im_hw0[i], self.im_hw[i] = x # im, hw_orig, hw_resized = load_image(self, i)
b += self.ims[i].nbytes
pbar.desc = f"{self.prefix}Caching images ({b / gb:.1f}GB {storage})"
pbar.close()🚩1. 初始化变量
python
b, gb = 0, 1 << 30 # bytes of cached images, bytes per gigabytesb需要保存的数据大小(字节),初始化为0,gb1GB内存大小的字节数,也就是2^30.
🚩2. 函数和存储位置选择
根据配置的缓存位置更新函数指针fcn以及存储位置变量storage
python
fcn, storage = (self.cache_images_to_disk, "Disk") if self.cache == "disk" else (self.load_image, "RAM")- 如果self.cache == "disk":使用磁盘缓存
fcn = self.cache_images_to_disk
storage = "Disk" - 否则(RAM缓存):使用内存缓存
fcn = self.load_image
storage = "RAM"
🚩3. 并行处理
创建线程池,并执行缓存函数,保存数据。
python
with ThreadPool(NUM_THREADS) as pool:
results = pool.imap(fcn, range(self.ni))🚩4. 处理过程可视化
如果看过前文,这里就相当好理解了,就是在将图像数据保存到相应位置的同时,用进度条实时显示内存占用情况。
python
pbar = TQDM(enumerate(results), total=self.ni, disable=LOCAL_RANK > 0)
for i, x in pbar:
if self.cache == "disk":
b += self.npy_files[i].stat().st_size
else: # 'ram'
self.ims[i], self.im_hw0[i], self.im_hw[i] = x # im, hw_orig, hw_resized = load_image(self, i)
b += self.ims[i].nbytes
pbar.desc = f"{self.prefix}Caching images ({b / gb:.1f}GB {storage})"
pbar.close()如果是保存在RAM中,还需要同步更新三个参数。
self.ims[i]:处理后的图像数组self.im_hw0[i]:原始尺寸(比如(480, 640))self.im_hw[i]:调整后尺寸(比如(640, 640))
🍒举个例子:
我们还是用熟悉的COCO数据集举例子
python
# COCO数据集,2张图片
self.im_files = [
"data/coco/images/train2017/000000000001.jpg", # 150KB
"data/coco/images/train2017/000000000002.jpg" # 200KB
]🍭如果使用RAM缓存
初始化
python
b = 0 # 已缓存字节数
gb = 1073741824 # 1GB
fcn = self.load_image # 缓存函数
storage = "RAM" # 存储类型最终结果
python
# 内存中存储了处理后的图像数据
self.ims = [image_array_1, image_array_2] # 图像数组列表
self.im_hw0 = [(480, 640), (300, 400)] # 原始尺寸列表
self.im_hw = [(640, 640), (400, 400)] # 调整后尺寸列表🍭如果使用磁盘缓存
初始化
python
b = 0 # 已缓存字节数
gb = 1073741824 # 1GB
fcn = self.cache_images_to_disk # 缓存函数
storage = "Disk" # 存储类型最终结果
python
# .npy文件已创建:
# data/coco/images/train2017/000000000001.npy
# data/coco/images/train2017/000000000002.npy磁盘上创建了.npy缓存文件
self.ims[i] 仍为 None,需要时会从.npy文件加载
5.3 图像与标签验证
图像与标签验证主要是通过verify_image_label()函数来实现的,函数内容非常丰富,涉及到诸多细节。
python
def verify_image_label(args):
"""Verify one image-label pair."""
im_file, lb_file, prefix, keypoint, num_cls, nkpt, ndim = args
# Number (missing, found, empty, corrupt), message, segments, keypoints
nm, nf, ne, nc, msg, segments, keypoints = 0, 0, 0, 0, "", [], None
try:
# Verify images
im = Image.open(im_file)
im.verify() # PIL verify
shape = exif_size(im) # image size
shape = (shape[1], shape[0]) # hw
assert (shape[0] > 9) & (shape[1] > 9), f"image size {shape} <10 pixels"
assert im.format.lower() in IMG_FORMATS, f"invalid image format {im.format}. {FORMATS_HELP_MSG}"
if im.format.lower() in {"jpg", "jpeg"}:
with open(im_file, "rb") as f:
f.seek(-2, 2)
if f.read() != b"\xff\xd9": # corrupt JPEG
ImageOps.exif_transpose(Image.open(im_file)).save(im_file, "JPEG", subsampling=0, quality=100)
msg = f"{prefix}WARNING ⚠️ {im_file}: corrupt JPEG restored and saved"
# Verify labels
if os.path.isfile(lb_file):
nf = 1 # label found
with open(lb_file) as f:
lb = [x.split() for x in f.read().strip().splitlines() if len(x)]
if any(len(x) > 6 for x in lb) and (not keypoint): # is segment
classes = np.array([x[0] for x in lb], dtype=np.float32)
segments = [np.array(x[1:], dtype=np.float32).reshape(-1, 2) for x in lb] # (cls, xy1...)
lb = np.concatenate((classes.reshape(-1, 1), segments2boxes(segments)), 1) # (cls, xywh)
lb = np.array(lb, dtype=np.float32)
nl = len(lb)
if nl:
if keypoint:
assert lb.shape[1] == (5 + nkpt * ndim), f"labels require {(5 + nkpt * ndim)} columns each"
points = lb[:, 5:].reshape(-1, ndim)[:, :2]
else:
assert lb.shape[1] == 5, f"labels require 5 columns, {lb.shape[1]} columns detected"
points = lb[:, 1:]
assert points.max() <= 1, f"non-normalized or out of bounds coordinates {points[points > 1]}"
assert lb.min() >= 0, f"negative label values {lb[lb < 0]}"
# All labels
max_cls = lb[:, 0].max() # max label count
assert max_cls <= num_cls, (
f"Label class {int(max_cls)} exceeds dataset class count {num_cls}. "
f"Possible class labels are 0-{num_cls - 1}"
)
_, i = np.unique(lb, axis=0, return_index=True)
if len(i) < nl: # duplicate row check
lb = lb[i] # remove duplicates
if segments:
segments = [segments[x] for x in i]
msg = f"{prefix}WARNING ⚠️ {im_file}: {nl - len(i)} duplicate labels removed"
else:
ne = 1 # label empty
lb = np.zeros((0, (5 + nkpt * ndim) if keypoint else 5), dtype=np.float32)
else:
nm = 1 # label missing
lb = np.zeros((0, (5 + nkpt * ndim) if keypoints else 5), dtype=np.float32)
if keypoint:
keypoints = lb[:, 5:].reshape(-1, nkpt, ndim)
if ndim == 2:
kpt_mask = np.where((keypoints[..., 0] < 0) | (keypoints[..., 1] < 0), 0.0, 1.0).astype(np.float32)
keypoints = np.concatenate([keypoints, kpt_mask[..., None]], axis=-1) # (nl, nkpt, 3)
lb = lb[:, :5]
return im_file, lb, shape, segments, keypoints, nm, nf, ne, nc, msg
except Exception as e:
nc = 1
msg = f"{prefix}WARNING ⚠️ {im_file}: ignoring corrupt image/label: {e}"
return [None, None, None, None, None, nm, nf, ne, nc, msg]总体来说,函数具有以下功能:
- 🍧 图像验证:检查图像文件完整性、格式、尺寸
- 🍧 标签验证:检查标签文件格式、坐标范围、类别ID有效性
- 🍧 格式转换:将标签转换为标准内部格式
- 🍧 错误修复:尝试修复损坏的JPEG文件
- 🍧 数据清理:去除重复标签、验证坐标范围
- 🍧 异常处理:捕获并记录各种错误情况
🚩1. 参数说明
im_file: 图像文件路径lb_file: 标签文件路径prefix: 日志前缀keypoint: 是否为关键点任务(显然不是)num_cls: 类别总数,常见的是80个类别nkpt: 关键点数量 (不相关,略)ndim: 关键点维度 (不相关,略)
🚩2. 变量初始化
nm: 标签缺失数量nf: 标签找到数量ne: 标签空数量nc: 标签损坏数量msg: 消息segments: 分割信息keypoints: 关键点信息
🚩3. 图像验证
python
try:
# Verify images
im = Image.open(im_file)
im.verify() # PIL verify
shape = exif_size(im) # image size
shape = (shape[1], shape[0]) # hw
assert (shape[0] > 9) & (shape[1] > 9), f"image size {shape} <10 pixels"
assert im.format.lower() in IMG_FORMATS, f"invalid image format {im.format}. {FORMATS_HELP_MSG}"
# 修复损坏的JPEG文件
if im.format.lower() in {"jpg", "jpeg"}:
with open(im_file, "rb") as f:
f.seek(-2, 2)
if f.read() != b"\xff\xd9": # corrupt JPEG
ImageOps.exif_transpose(Image.open(im_file)).save(im_file, "JPEG", subsampling=0, quality=100)
msg = f"{prefix}WARNING ⚠️ {im_file}: corrupt JPEG restored and saved"对图像的很多方面进行了检查。
- 首先图像不能太小,如果宽或者高的像素太小,会影响检测效果。视为无效图像,抛出异常。
- 如果加载的图像格式不支持,也会视为无效图像,抛出异常。
python
IMG_FORMATS = {"bmp", "dng", "jpeg", "jpg", "mpo", "png", "tif", "tiff", "webp", "pfm", "heic"} # image suffixes从定义来看,支持的格式还是蛮多的。
- 如果图像的格式是"
jpg"或者"jpeg",还支持图像的修复。
从末尾向前移动2个字节,检查最后2个字节是否为JPEG结束标记。
python
f.seek(-2, 2)
if f.read() != b"\xff\xd9": # corrupt JPEG如果是的话,使用PIL重新解析图像数据,应用EXIF方向变换进行修复。
PIL的修复机制主要针对文件结构轻微损坏(如缺少结束标记)的情况,通过重新编码来恢复文件完整性,而EXIF变换确保图像方向正确。对于核心数据损坏的情况则无法修复。
🚩4. 标签验证
因只涉及目标检测任务,所以将语义分割和关键点检测的相关部分直接删掉,剩余部分如下:
python
# Verify labels
if os.path.isfile(lb_file):
nf = 1 # label found
with open(lb_file) as f:
lb = [x.split() for x in f.read().strip().splitlines() if len(x)]
lb = np.array(lb, dtype=np.float32)
nl = len(lb)
if nl:
assert lb.shape[1] == 5, f"labels require 5 columns, {lb.shape[1]} columns detected"
points = lb[:, 1:]
# 验证坐标范围
assert points.max() <= 1, f"non-normalized or out of bounds coordinates {points[points > 1]}"
assert lb.min() >= 0, f"negative label values {lb[lb < 0]}"
# 验证类别ID
max_cls = lb[:, 0].max() # max label count
assert max_cls <= num_cls, (
f"Label class {int(max_cls)} exceeds dataset class count {num_cls}. "
f"Possible class labels are 0-{num_cls - 1}"
)
# 去除重复标签
_, i = np.unique(lb, axis=0, return_index=True)
if len(i) < nl: # duplicate row check
lb = lb[i] # remove duplicates
if segments:
segments = [segments[x] for x in i]
msg = f"{prefix}WARNING ⚠️ {im_file}: {nl - len(i)} duplicate labels removed"
else:
ne = 1 # label empty
lb = np.zeros((0, (5 + nkpt * ndim) if keypoint else 5), dtype=np.float32)
else:
nm = 1 # label missing
lb = np.zeros((0, (5 + nkpt * ndim) if keypoint else 5), dtype=np.float32)- 如果路径下存在标签文件,则读取标签文件。
- 将标签文件的内容重新整理成list格式。
- 检查标签数据的数据是否完整(每行5个数据),按道理应该有4个数据,分别是目标的类别,以及边界框的4个坐标(
class_id, center_x, center_y, width, height)。 - 验证坐标范围,归一化的数据不能
>1,且标签文件中的所有值不能<0。 - 验证类别ID,获取标签中的类别ID最大值,最大值也不能大于数据集本身的类别数。比方说,COCO数据集有80个类别(
0~79)。
- 去除重复标签:如果标签有重复的情况,则只取第一次出现的数据内容(重复的几个里面)。
举个例子:原始标签数组,包含重复行。
python
lb = np.array([
[0, 0.5, 0.5, 0.2, 0.3], # 第0行:类别0,位置(0.5,0.5),尺寸(0.2,0.3)
[1, 0.3, 0.7, 0.15, 0.25], # 第1行:类别1,位置(0.3,0.7),尺寸(0.15,0.25)
[0, 0.5, 0.5, 0.2, 0.3], # 第2行:与第0行重复
[2, 0.8, 0.2, 0.1, 0.1], # 第3行:类别2,位置(0.8,0.2),尺寸(0.1,0.1)
[1, 0.3, 0.7, 0.15, 0.25] # 第4行:与第1行重复
])那么在执行np.unique()后,返回的i值为[0 1 3]。
经过if判断3<5,说明有重复数据,需要去重 ,重复数据只保留一份。
python
lb = np.array([
[0, 0.5, 0.5, 0.2, 0.3],
[1, 0.3, 0.7, 0.15, 0.25],
[2, 0.8, 0.2, 0.1, 0.1],
])- 空标签处理:如果标签没有读到,则创建空数值,供后续流程处理。
🚩5. 异常处理
python
except Exception as e:
nc = 1
msg = f"{prefix}WARNING ⚠️ {im_file}: ignoring corrupt image/label: {e}"
return [None, None, None, None, None, nm, nf, ne, nc, msg]except Exception as e捕获了verify_image_label函数中可能发生的任何异常(包括AssertionError、ValueError、FileNotFoundError等),确保数据验证过程的健壮性。比方说函数前面流程中读取文件出现异常,或者是断言失败异常等等。然后将nm, nf, ne, nc, msg这些信息统计起来,交给后续的cache_labels做进一步处理。
5.4 图像加载策略
内存优化是数据加载系统设计中的核心考虑因素,特别是在处理大规模数据集时。
python
def load_image(self, i, rect_mode=True):
"""Loads 1 image from dataset index 'i', returns (im, resized hw)."""
im, f, fn = self.ims[i], self.im_files[i], self.npy_files[i]
if im is None: # not cached in RAM
if fn.exists(): # load npy
try:
im = np.load(fn)
except Exception as e:
LOGGER.warning(f"{self.prefix}WARNING ⚠️ Removing corrupt *.npy image file {fn} due to: {e}")
Path(fn).unlink(missing_ok=True)
im = cv2.imread(f) # BGR
else: # read image
im = cv2.imread(f) # BGR
if im is None:
raise FileNotFoundError(f"Image Not Found {f}")
h0, w0 = im.shape[:2] # orig hw
if rect_mode: # resize long side to imgsz while maintaining aspect ratio
r = self.imgsz / max(h0, w0) # ratio
if r != 1: # if sizes are not equal
w, h = (min(math.ceil(w0 * r), self.imgsz), min(math.ceil(h0 * r), self.imgsz))
im = cv2.resize(im, (w, h), interpolation=cv2.INTER_LINEAR)
elif not (h0 == w0 == self.imgsz): # resize by stretching image to square imgsz
im = cv2.resize(im, (self.imgsz, self.imgsz), interpolation=cv2.INTER_LINEAR)
# Add to buffer if training with augmentations
if self.augment:
self.ims[i], self.im_hw0[i], self.im_hw[i] = im, (h0, w0), im.shape[:2] # im, hw_original, hw_resized
self.buffer.append(i)
if 1 < len(self.buffer) >= self.max_buffer_length: # prevent empty buffer
j = self.buffer.pop(0)
if self.cache != "ram":
self.ims[j], self.im_hw0[j], self.im_hw[j] = None, None, None
return im, (h0, w0), im.shape[:2]
return self.ims[i], self.im_hw0[i], self.im_hw[i]🚩1. 参数说明
- i: 图像在数据集中的索引
- rect_mode: 是否启用矩形模式(保持宽高比)
🚩2. 缓存机制检查
python
im, f, fn = self.ims[i], self.im_files[i], self.npy_files[i]
if im is None: # not cached in RAM
# 图像未在RAM中缓存,需要从磁盘加载self.ims[i]: RAM中的图像缓存self.im_files[i]: 原始图像文件路径self.npy_files[i]: 预缓存的.npy文件路径
如果im是空的值,说明并没有在RAM中保存,需要从磁盘加载。否则直接返回当前RAM中的图像和尺寸。
python
return self.ims[i], self.im_hw0[i], self.im_hw[i]🚩3. 图像加载流程
python
if fn.exists(): # 优先加载.npy缓存文件
try:
im = np.load(fn) # 从.npy文件快速加载
except Exception as e:
# 如果.npy文件损坏,删除它并回退到原始图像
LOGGER.warning(f"{self.prefix}WARNING ⚠️ Removing corrupt *.npy image file {fn} due to: {e}")
Path(fn).unlink(missing_ok=True) # 删除损坏的.npy文件
im = cv2.imread(f) # 直接从原始图像加载
else: # 没有.npy缓存文件,直接加载原始图像
im = cv2.imread(f) # BGR格式如果存在文件路径,就去这个路径下读取文件,如果有异常读不到,就直接加载原图像。
🚩4. 图像尺寸处理
python
if rect_mode: # resize长边到imgsz,保持宽高比
r = self.imgsz / max(h0, w0) # 计算缩放比例
if r != 1: # 只有当需要缩放时才处理
w, h = (min(math.ceil(w0 * r), self.imgsz), min(math.ceil(h0 * r), self.imgsz))
im = cv2.resize(im, (w, h), interpolation=cv2.INTER_LINEAR)这个就很好理解了,如果训练中有需要将图像resize到一样的尺寸,就需要这部分软件进行实现。这个很好理解,因为是保持原图宽高比缩放的,所以一旦原图的长或者宽和目标尺寸相等,就不会resize。resize采用的算法是线性插值。
否则就将图像拉伸为正方形。
python
elif not (h0 == w0 == self.imgsz): # 拉伸图像为正方形
im = cv2.resize(im, (self.imgsz, self.imgsz), interpolation=cv2.INTER_LINEAR)resize采用的算法依旧是线性插值。
🚩5. 缓冲区管理
python
# 如果是训练模式且有数据增强
if self.augment:
# 保存图像到缓存
self.ims[i], self.im_hw0[i], self.im_hw[i] = im, (h0, w0), im.shape[:2]
# 添加到缓冲区
self.buffer.append(i)
# 管理缓冲区大小,防止内存溢出
if 1 < len(self.buffer) >= self.max_buffer_length: # 防止空缓冲区
j = self.buffer.pop(0) # 移除最旧的图像索引
if self.cache != "ram":
# 如果不是RAM缓存,释放内存
self.ims[j], self.im_hw0[j], self.im_hw[j] = None, None, None先保存图像到缓存,并将其添加到缓冲区,如果缓冲区溢出,则将最旧的图像一次。
然后判断图像的保存方式如果不是RAM缓存,而是磁盘,则释放缓存,将相关变量置为None。
最后返回处理后的图像,原始尺寸和处理后的尺寸(宽高)。
python
return im, (h0, w0), im.shape[:2]6. 标签处理与格式转换
6.1 标签标准化
将标签数据转换为统一的实例格式,为后续的数据增强和训练做准备。
python
def update_labels_info(self, label):
bboxes = label.pop("bboxes")
segments = label.pop("segments", [])
keypoints = label.pop("keypoints", None)
bbox_format = label.pop("bbox_format")
normalized = label.pop("normalized")
# NOTE: do NOT resample oriented boxes
segment_resamples = 100 if self.use_obb else 1000
if len(segments) > 0:
# make sure segments interpolate correctly if original length is greater than segment_resamples
max_len = max(len(s) for s in segments)
segment_resamples = (max_len + 1) if segment_resamples < max_len else segment_resamples
# list[np.array(segment_resamples, 2)] * num_samples
segments = np.stack(resample_segments(segments, n=segment_resamples), axis=0)
else:
segments = np.zeros((0, segment_resamples, 2), dtype=np.float32)
label["instances"] = Instances(bboxes, segments, keypoints, bbox_format=bbox_format, normalized=normalized)
return label🚩1. 提取标签字段
为了便于处理,先将标签中的数据分别提取出来。
python
bboxes = label.pop("bboxes")
segments = label.pop("segments", [])
keypoints = label.pop("keypoints", None)
bbox_format = label.pop("bbox_format")
normalized = label.pop("normalized")🚩2. 分割信息重采样(不涉及)
python
segment_resamples = 100 if self.use_obb else 1000- OBB任务:使用100个采样点(定向边界框)
- 其他任务:使用1000个采样点(更精细的分割)
在后续的数据增强中,会对原图做各种变换(比方说仿射变换),如果是普通的边界框,只需跟随原图做相同的几何变换即可,但是对于有语义分割任中的边界坐标,在后续的变换后很可能失真或出错,为避免这种情况的出现,需要扩充原本的边界表示,具体的任务由resample_segments()函数来承担。
🚩3. 动态调整采样点数(不涉及)
python
if len(segments) > 0:
# make sure segments interpolate correctly if original length is greater than segment_resamples
max_len = max(len(s) for s in segments)
segment_resamples = (max_len + 1) if segment_resamples < max_len else segment_resamples
# list[np.array(segment_resamples, 2)] * num_samples
segments = np.stack(resample_segments(segments, n=segment_resamples), axis=0)如果现有分割点数超过预设值,动态增加采样点数,确保分割信息的精度。
🚩4. 创建统一实例对象
python
label["instances"] = Instances(bboxes, segments, keypoints, bbox_format=bbox_format, normalized=normalized)该函数通过统一数据结构,将边界框、分割、关键点整合到一个Instances对象中,便于后续数据增强操作。并且将格式标准化,确保分割信息具有统一的点数,保持边界框格式一致性。
python
# 检测任务
Instances(bboxes=bboxes, segments=[], keypoints=None)
# 分割任务
Instances(bboxes=bboxes, segments=segment_points, keypoints=None)
# 姿态估计任务
Instances(bboxes=bboxes, segments=[], keypoints=keypoints)
# OBB任务
Instances(bboxes=bboxes, segments=obb_points, keypoints=None)🍒举个例子:
如果是普通的目标检测任务,则输入的标签信息可能为:
python
{
"img": image_array,
"ori_shape": (480, 640),
"resized_shape": (640, 640),
"ratio_pad": (1.333, 1.0),
"bboxes": array([[0.45, 0.55, 0.2, 0.3], [0.75, 0.35, 0.15, 0.25]]), # 边界框
"segments": [], # 检测任务中为空列表
"keypoints": None, # 检测任务中为None
"cls": array([[0], [1]]), # 类别
"bbox_format": "xywh", # 边界框格式
"normalized": True # 是否归一化
}处理后:
python
{
"img": image_array,
"ori_shape": (480, 640),
"resized_shape": (640, 640),
"ratio_pad": (1.333, 1.0),
"cls": array([[0], [1]]), # 类别保留
"instances": Instances_object({
bboxes: array([[0.45, 0.55, 0.2, 0.3], [0.75, 0.35, 0.15, 0.25]]),
segments: array([], shape=(0, 1000, 2)), # 空分割数组
keypoints: None, # 无关键点
bbox_format: "xywh", # 边界框格式
normalized: True # 归一化标志
})
}6.2 标签格式化
标签格式化是将处理后的标签数据转换为模型训练所需的格式。
python
class Format:
def __init__(
self,
bbox_format="xywh",
normalize=True,
return_mask=False,
return_keypoint=False,
return_obb=False,
mask_ratio=4,
mask_overlap=True,
batch_idx=True,
bgr=0.0,
):
self.bbox_format = bbox_format
self.normalize = normalize
self.return_mask = return_mask # set False when training detection only
self.return_keypoint = return_keypoint
self.return_obb = return_obb
self.mask_ratio = mask_ratio
self.mask_overlap = mask_overlap
self.batch_idx = batch_idx # keep the batch indexes
self.bgr = bgr
def __call__(self, labels):
img = labels.pop("img")
h, w = img.shape[:2]
cls = labels.pop("cls")
instances = labels.pop("instances")
instances.convert_bbox(format=self.bbox_format)
instances.denormalize(w, h)
nl = len(instances)
if self.return_mask:
if nl:
masks, instances, cls = self._format_segments(instances, cls, w, h)
masks = torch.from_numpy(masks)
else:
masks = torch.zeros(
1 if self.mask_overlap else nl, img.shape[0] // self.mask_ratio, img.shape[1] // self.mask_ratio
)
labels["masks"] = masks
labels["img"] = self._format_img(img)
labels["cls"] = torch.from_numpy(cls) if nl else torch.zeros(nl)
labels["bboxes"] = torch.from_numpy(instances.bboxes) if nl else torch.zeros((nl, 4))
if self.return_keypoint:
labels["keypoints"] = torch.from_numpy(instances.keypoints)
if self.normalize:
labels["keypoints"][..., 0] /= w
labels["keypoints"][..., 1] /= h
if self.return_obb:
labels["bboxes"] = (
xyxyxyxy2xywhr(torch.from_numpy(instances.segments)) if len(instances.segments) else torch.zeros((0, 5))
)
# NOTE: need to normalize obb in xywhr format for width-height consistency
if self.normalize:
labels["bboxes"][:, [0, 2]] /= w
labels["bboxes"][:, [1, 3]] /= h
# Then we can use collate_fn
if self.batch_idx:
labels["batch_idx"] = torch.zeros(nl)
return labels- 💫张量格式转换:标签数据最终需要转换为PyTorch张量格式,以便与模型的其他部分无缝集成。这种转换需要保持数据的精度和结构。
- 💫批次维度处理:在批次处理中,需要为每个样本在批次中的位置建立索引,确保模型能够正确处理批量数据。
- 💫标签合并策略:对于包含多个目标的图像,系统需要将多个边界框和类别信息合并到统一的数据结构中。
- 💫数据类型选择:选择合适的数据类型对内存使用和计算效率都有影响。整数类型用于类别ID,浮点数类型用于坐标信息。
当构建完流水线时,会调用__init__()方法,此时只更新Format类的相关属性。
当训练中每次加载数据时,会调用__call__()方法,此时Format类会对标签信息做相关处理。
整个__call__()方法看似内容很长,并不难理解,因为本系列只涉及目标检测任务,并不涉及语义分割等其他任务,因而这部分的代码可简化为:
python
def __call__(self, labels):
img = labels.pop("img")
h, w = img.shape[:2]
cls = labels.pop("cls")
instances = labels.pop("instances")
instances.convert_bbox(format=self.bbox_format)
instances.denormalize(w, h)
nl = len(instances)
labels["img"] = self._format_img(img)
labels["cls"] = torch.from_numpy(cls) if nl else torch.zeros(nl)
labels["bboxes"] = torch.from_numpy(instances.bboxes) if nl else torch.zeros((nl, 4))
# NOTE: need to normalize obb in xywhr format for width-height consistency
if self.normalize:
labels["bboxes"][:, [0, 2]] /= w
labels["bboxes"][:, [1, 3]] /= h
# Then we can use collate_fn
if self.batch_idx:
labels["batch_idx"] = torch.zeros(nl)
return labels🚩1. 边界框表示统一化
首先会对提取图像的宽,高,类别等信息,然后将边界框转换成所需的表示格式(xywh)。这部分内容比较简单,具体可以参考上一篇文章(Ultralytics 代码库深度解读【五】:数据预处理与增强Pipeline)3.2.2 核心逻辑详解

🚩2. 图像反正则化
再将图像宽高反正则化,具体的逻辑为:
python
def denormalize(self, w, h):
"""Denormalizes boxes, segments, and keypoints from normalized coordinates."""
if not self.normalized:
return
self._bboxes.mul(scale=(w, h, w, h))
self.segments[..., 0] *= w
self.segments[..., 1] *= h
if self.keypoints is not None:
self.keypoints[..., 0] *= w
self.keypoints[..., 1] *= h
self.normalized = False也就是将图像的宽高反正则化为具体数值。
🚩3. 图像格式转化
目的是将图像的表示形式从Numpy的数组形式转换为PyTorch的张量形式。
python
def _format_img(self, img):
if len(img.shape) < 3:
img = np.expand_dims(img, -1)
img = img.transpose(2, 0, 1)
img = np.ascontiguousarray(img[::-1] if random.uniform(0, 1) > self.bgr else img)
img = torch.from_numpy(img)
return img如果图像不是3维表示的,会对其进行升维处理。transpose是矩阵的转置操作,最终转换成了PyTorch的张量形式。
🚩4. 边界框正则化
python
bbox_format="xywh",
normalize=True,从参数的默认值可以看出,边界框会统一表示成"xywh"的形式,也就是边界框的中心点and宽高的形式,默认情况下也是需要正则化的,我们看看是如何进行正则化的:
python
if self.normalize:
labels["bboxes"][:, [0, 2]] /= w
labels["bboxes"][:, [1, 3]] /= h具体地,
会将"xw"两个数值➗️图像的宽度
会将"wy"两个数值➗️图像的高度
🚩5. 创建索引0张量
在这里,会根据需要检测目标的数量创建0张量,用来确认每次训练中物体与图片的对应关系,然后通过collate_fn()函数统一处理。
python
# Then we can use collate_fn
if self.batch_idx:
labels["batch_idx"] = torch.zeros(nl)关于后续处理的具体细节,请移步→ 4.4 批次合并机制
最后返回统一处理后的标签即可。
6.3 标签过滤
标签过滤功能是通过update_labels()接口来实现的,当提供classes参数时,只保留指定类别的目标。
python
def update_labels(self, include_class: Optional[list]):
"""Update labels to include only these classes (optional)."""
include_class_array = np.array(include_class).reshape(1, -1)
for i in range(len(self.labels)):
if include_class is not None:
cls = self.labels[i]["cls"]
bboxes = self.labels[i]["bboxes"]
segments = self.labels[i]["segments"]
keypoints = self.labels[i]["keypoints"]
j = (cls == include_class_array).any(1)
self.labels[i]["cls"] = cls[j]
self.labels[i]["bboxes"] = bboxes[j]
if segments:
self.labels[i]["segments"] = [segments[si] for si, idx in enumerate(j) if idx]
if keypoints is not None:
self.labels[i]["keypoints"] = keypoints[j]
if self.single_cls:
self.labels[i]["cls"][:, 0] = 0先将输入的include_class扩展为2维数组,方便后续运算。
python
include_class_array = np.array(include_class).reshape(1, -1)比方说,输入的是[0, 2],那么在进行第一步处理后就变成了([[0,2]])
后续工作就是遍历每张图片中的标签,检查是否有训练任务所需要的标签,有则保留相关标签信息,没有则丢弃。
。只需关注变量j就可以看出其中的具体原理。
python
j = (cls == include_class_array).any(1)其中的.any(1)意思是沿着第1维度取或运算。
比方说输入图片中有4个目标:人,猫,车,飞机(对应标签0,1, 2,3),但任务中只想训练人和车。
python
[0] == [0, 2] -> [True, False]
[1] == [0, 2] -> [False, False]
[2] == [0, 2] -> [False, True]
[3] == [0, 2] -> [False, False]
j = array([True, False, True, False]) # 保留索引0和2这样对比下来,只有人和车的类别运算结果是True,很方便地达到了过滤的目的。
那有重复的目标怎么办呢?比方输入图片中有3个目标:人,人,公交车🚌(对应标签0,0, 5)。
python
[0] == [0, 2] -> [True, False]
[0] == [0, 2] -> [True, False]
[5] == [0, 2] -> [False, False]
j = array([True, True, False]) # 保留索引0, 1可以看到,只保留了两个人,公交车就被去掉了。很好地过滤掉了任务中不需要的目标。
🍒举个例子:
我们采用了COCO数据集,80个类别,但我们只想训练类别0(人)和类别2(车)
python
include_class = [0, 2]
self.labels = [
# 第1张图片
{
"cls": array([[0], [1], [2], [3]]), # 4个目标:人,猫,车,飞机
"bboxes": array([[0.45, 0.55, 0.2, 0.3], # 人
[0.65, 0.45, 0.15, 0.2], # 猫
[0.75, 0.35, 0.1, 0.15], # 车
[0.85, 0.25, 0.05, 0.08]]), # 飞机
"segments": [...], # 分割信息
"keypoints": [...] # 关键点信息
},
# 第2张图片
{
"cls": array([[0], [0], [5]]), # 3个目标:人,人,公交车
"bboxes": array([[0.3, 0.6, 0.25, 0.3], # 人
[0.7, 0.5, 0.15, 0.2], # 人
[0.4, 0.3, 0.4, 0.25]]), # 公交车
"segments": [...],
"keypoints": [...]
}
]处理后的标签数据为:
python
self.labels = [
# 第1张图片(只保留人和车)
{
"cls": array([[0], [2]]), # 2个目标:人,车
"bboxes": array([[0.45, 0.55, 0.2, 0.3], # 人的框
[0.75, 0.35, 0.1, 0.15]]), # 车的框
"segments": [...],
"keypoints": [...]
},
# 第2张图片(只保留人)
{
"cls": array([[0], [0]]), # 2个目标:都是人
"bboxes": array([[0.3, 0.6, 0.25, 0.3], # 第1个人
[0.7, 0.5, 0.15, 0.2]]), # 第2个人
"segments": [...],
"keypoints": [...]
}
]7. 总结
本篇聚焦 Ultralytics 代码库的数据加载机制,从架构到细节展开深度解析。开篇后先概述数据加载的整体架构与核心组件关系,再拆解 Dataset 类初始化逻辑,对比 BaseDataset 与 YOLODataset 的实现差异。
核心部分详解数据加载流程:从图像路径扫描、标签缓存构建等单样本加载环节,到 InfiniteDataLoader 原理、多进程优化及批次合并机制;还补充了标签 / 图像的缓存策略、加载策略与校验逻辑,最后说明标签的标准化、格式化与过滤处理。
Ultralytics 代码库的数据加载机制有2大亮点:
- 数据加载进行了多重校验与检查,从数据校验(比如说哈希算法)到数据完整性检查,再到异常的捕获与处理机制,最大限度确保数据加载准确无误。
- 从数据存储来讲,给开发提供了较大的灵活性,既可以将数据保存在RAM中,也可以保存在磁盘中,还提供了分布式训练模式,进一步提高了软件对硬件平台的适应能力。