Pandas 综合实战案例(零售数据分析)
本文以零售业务为例,完整展示 Pandas 在数据导入、清洗、汇总分析与可视化中的综合应用。从原始数据到分析洞察,帮助读者掌握一条清晰、系统的数据分析流程,提升从"看懂数据"到"用好数据"的实战能力。
1. 数据导入与清洗
假设我们拥有一份零售交易数据,包含订单编号、客户地区、产品类别、销售额与数量等信息。
python
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", font="SimHei", rc={"axes.unicode_minus": False})
# 模拟零售数据
data = {
"订单ID": range(1,11),
"客户地区": ["北京","上海","北京","深圳","上海","北京","广州","深圳","广州","上海"],
"产品类别": ["电子","服装","电子","食品","电子","服装","食品","电子","服装","食品"],
"销售额": [200, 150, 300, 100, 250, 180, 120, 220, 160, 130],
"数量": [2, 1, 3, 1, 2, 1, 1, 2, 1, 1]
}
df = pd.DataFrame(data)
print("原始数据:\n", df.head())结果显示前几行订单记录:
txt
原始数据:
订单ID 客户地区 产品类别 销售额 数量
0 1 北京 电子 200 2
1 2 上海 服装 150 1
2 3 北京 电子 300 3
3 4 深圳 食品 100 1
4 5 上海 电子 250 2在任何分析前,都应首先进行缺失值检查:
python
print("缺失值统计:\n", df.isnull().sum())
# 如果有缺失值,可使用 fillna 或 dropna 处理
# df['销售额'].fillna(df['销售额'].mean(), inplace=True)
txt
缺失值统计:
订单ID 0
客户地区 0
产品类别 0
销售额 0
数量 0
dtype: int64输出结果表明数据完整,无需进一步清洗处理。
2. 分类汇总与趋势分析
2.1 按地区汇总销售额
不同地区销售额的总量往往反映了区域市场的活跃度。
python
region_sales = df.groupby('客户地区')['销售额'].sum().sort_values(ascending=False)
print("按地区汇总销售额:\n", region_sales)
txt
按地区汇总销售额:
客户地区
北京 680
上海 530
深圳 320
广州 280
Name: 销售额, dtype: int64北京与上海销售额明显领先,说明一线城市依旧是主要市场。
2.2 按产品类别汇总数量
进一步分析不同产品类型的销售数量:
python
category_quantity = df.groupby('产品类别')['数量'].sum()
print("按产品类别汇总数量:\n", category_quantity)
txt
按产品类别汇总数量:
产品类别
服装 3
电子 9
食品 3
Name: 数量, dtype: int64电子类产品销量遥遥领先,体现出更高的市场需求。
2.3 透视表多维分析
通过透视表可同时观察地区与产品类别两个维度的销售表现:
python
pivot_table = df.pivot_table(
values='销售额',
index='客户地区',
columns='产品类别',
aggfunc='sum',
fill_value=0
)
print("透视表(地区×产品类别销售额):\n", pivot_table)
txt
透视表(地区×产品类别销售额):
产品类别 服装 电子 食品
客户地区
上海 150 250 130
北京 180 500 0
广州 160 0 120
深圳 0 220 100这张表能直观发现,北京电子类销售额占据主导,而深圳食品类销售额相对突出。
3. 区间分组分析(cut)
为评估订单价值分布,可使用 pd.cut 对销售额分层:
python
bins = [0, 150, 200, 300, 400]
labels = ['低', '中', '高', '超高']
df['销售额等级'] = pd.cut(df['销售额'], bins=bins, labels=labels)
sales_level_count = df['销售额等级'].value_counts().sort_index()
print("销售额等级分布:\n", sales_level_count)
txt
销售额等级分布:
销售额等级
低 4
中 3
高 3
超高 0
Name: count, dtype: int64大多数订单集中在中低区间,说明高价值订单比例偏少。
4. 可视化展示
4.1 销售额趋势(柱状图)
python
region_sales.plot(kind='bar', title='各地区销售额汇总', color='skyblue')
plt.ylabel('销售额')
plt.show()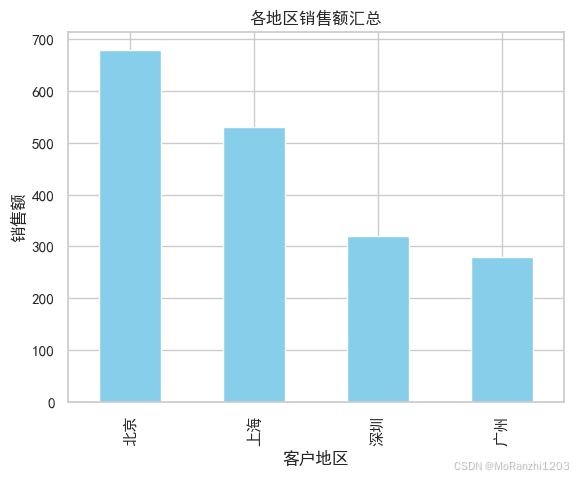
从图中可以明显看到,北京与上海形成高峰区。
4.2 产品类别数量分布(饼图)
python
category_quantity.plot(kind='pie', autopct='%1.1f%%', startangle=90, title='产品类别销售数量占比')
plt.ylabel('')
plt.show()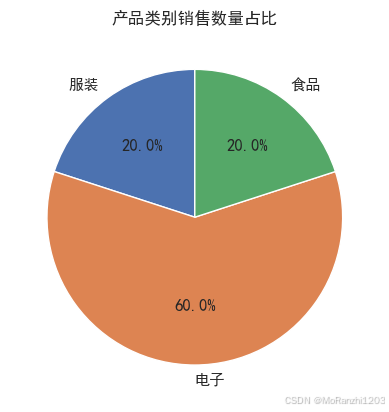
电子类占比接近三分之二,是主要销售来源。
4.3 销售额等级分布(柱状图)
python
sales_level_count.plot(kind='bar', title='销售额等级分布', color='orange')
plt.ylabel('订单数量')
plt.show()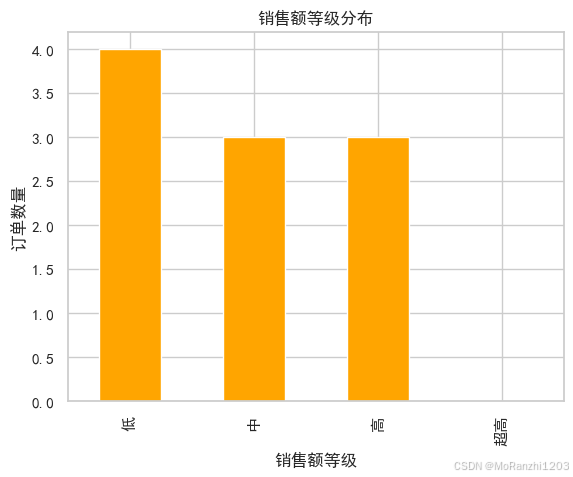
"中""高"两档占比最高,提示适合发展中端价位策略。
4.4 地区×产品类别销售额(堆叠柱状图)
python
pivot_table.plot(kind='bar', stacked=True, title='地区与产品类别销售额分布')
plt.ylabel('销售额')
plt.show()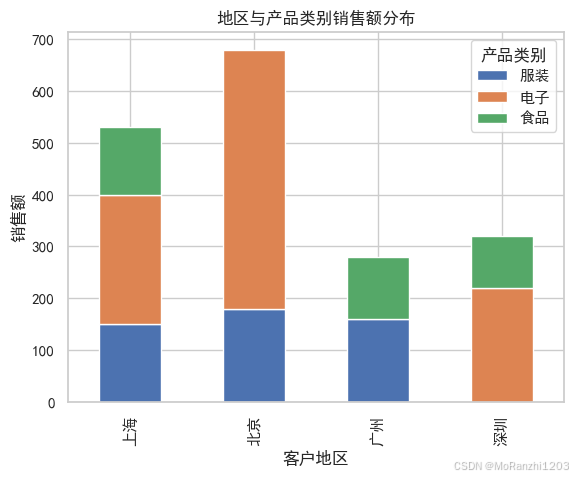
堆叠图让不同地区产品结构一目了然,北京、深圳以电子类为主,广州食品类占比较高。
5. 分析洞察
- 地区销售差异:北京、上海的销售额较高,深圳和广州次之,表明销售策略可针对高销售地区加强促销。
- 产品类别分布:电子类销售额和数量均占主导,可考虑重点补货与营销。
- 订单销售额分级:大部分订单集中在中高销售额段,说明高价值订单比例较低,可开发会员或大额促销策略。
- 可视化洞察:堆叠柱状图和饼图清晰展示了销售结构,为数据驱动决策提供直观依据。
6. 小结
本案例完整展示了从数据导入与清洗 到汇总分析与可视化展示的全过程,体现了 Pandas 在零售业务分析中的高效性与实用性。借助分组统计与透视表,我们能够快速洞察数据背后的结构特征,而可视化分析则进一步强化了结果的直观表达,使决策依据更具说服力。