文章目录
- 一、MNIST数据集详解
- 二、CNN与全连接层网络的区别与原理
-
- [1. 全连接层网络(Fully Connected Network)](#1. 全连接层网络(Fully Connected Network))
- [2. 卷积神经网络(CNN,Convolutional Neural Network)](#2. 卷积神经网络(CNN,Convolutional Neural Network))
- 三、代码与网络架构详细解释
-
- [1. 完整代码](#1. 完整代码)
- [2. 库导入部分](#2. 库导入部分)
- [3. 随机种子设置](#3. 随机种子设置)
- [4. 超参数定义](#4. 超参数定义)
- [5. 数据预处理与加载](#5. 数据预处理与加载)
- [6. CNN网络架构](#6. CNN网络架构)
- [7. 模型初始化、损失函数与优化器](#7. 模型初始化、损失函数与优化器)
- [8. 训练函数(train)](#8. 训练函数(train))
- [9. 测试函数(test)](#9. 测试函数(test))
- [10. 执行训练与可视化](#10. 执行训练与可视化)
- [11. 展示预测结果与保存模型](#11. 展示预测结果与保存模型)
下面我将按照你的要求,分三部分详细解释代码及相关概念:
一、MNIST数据集详解
MNIST(Modified National Institute of Standards and Technology database)是一个经典的手写数字识别数据集,被广泛用作机器学习和深度学习的入门级数据集。
- 组成结构 :
包含70,000张手写数字图像,其中60,000张为训练集(用于模型训练),10,000张为测试集(用于评估模型性能)。 - 图像特点 :
每张图像是28×28像素的灰度图(单通道),像素值范围为0-255(0表示白色背景,255表示黑色笔迹),对应数字0-9共10个类别。 - 数据集意义 :
数据规模适中(训练成本低)、任务明确(10分类)、噪声少,适合验证算法有效性,是深度学习入门的"Hello World"级数据集。
二、CNN与全连接层网络的区别与原理
1. 全连接层网络(Fully Connected Network)
全连接层是最基础的神经网络结构,其核心特点是:每一层的每个神经元与前一层的所有神经元完全连接。
- 工作方式:将输入数据(如图像)展平为一维向量,通过矩阵乘法进行特征变换,最终输出分类结果。
- 缺点 :
- 丢失空间信息:图像的像素位置关系(如"横"和"竖"的空间组合)在展平后被破坏。
- 参数过多:对于28×28的图像,展平后有784个特征,若第一层有1000个神经元,仅这一层就有784×1000=784,000个参数,容易过拟合。
2. 卷积神经网络(CNN,Convolutional Neural Network)
CNN是专为处理网格结构数据(如图像)设计的网络,核心优势是保留空间信息并减少参数数量,通过"局部感受野"和"权值共享"实现。
-
核心组件:
- 卷积层(Conv2d):通过滑动的卷积核对输入图像进行局部特征提取(如边缘、纹理、形状)。每个卷积核共享权重,大幅减少参数。
- 激活函数(如ReLU):引入非线性,使网络能拟合复杂特征。
- 池化层(如MaxPool2d):对特征图降采样(缩小尺寸),保留重要特征的同时减少计算量。
- 全连接层(Linear):将卷积提取的高级特征展平后,通过全连接层输出分类结果。
-
优势 :
能捕捉图像的空间局部相关性(如数字"8"的上下两个圈),参数更少,在图像任务上性能远超全连接网络。
三、代码与网络架构详细解释
1. 完整代码
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
# 设置随机种子,确保结果可复现
torch.manual_seed(42)
np.random.seed(42)
# 1. 定义超参数
batch_size = 64 # 每次训练的批次大小
learning_rate = 0.001 # 学习率
num_epochs = 10 # 训练轮数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# 2. 数据预处理和加载
# 定义数据转换:将图像转换为张量并归一化
transform = transforms.Compose([
transforms.ToTensor(), # 转换为张量 (0-255 -> 0.0-1.0)
transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])
# 加载MNIST数据集
train_dataset = datasets.MNIST(
root='./data', # 数据保存路径
train=True, # 训练集
download=True, # 如果本地没有则下载
transform=transform # 应用转换
)
test_dataset = datasets.MNIST(
root='./data',
train=False, # 测试集
download=True,
transform=transform
)
# 创建数据加载器
train_loader = DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True # 训练时打乱数据
)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=batch_size,
shuffle=False # 测试时不需要打乱
)
# 3. 定义卷积神经网络模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 第一个卷积块:卷积层 + 激活函数 + 池化层
self.conv1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1), # 卷积层:输入1通道,输出32通道,3×3卷积核
nn.ReLU(), # 激活函数
nn.MaxPool2d(kernel_size=2, stride=2) # 池化层:2×2池化核,步长2,输出14×14
)
# 第二个卷积块
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1), # 输入32通道,输出64通道
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2) # 输出7×7
)
# 全连接层
self.fc1 = nn.Linear(7 * 7 * 64, 128) # 输入维度为7×7×64,输出128
self.fc2 = nn.Linear(128, 10) # 输出10个类别(0-9)
self.dropout = nn.Dropout(0.5) # Dropout层防止过拟合
def forward(self, x):
# 前向传播
x = self.conv1(x)
x = self.conv2(x)
x = x.view(-1, 7 * 7 * 64) # 展平操作,将特征图转换为向量
x = self.dropout(x) # 应用dropout
x = torch.relu(self.fc1(x)) # 全连接层+激活
x = self.fc2(x) # 输出层
return x
# 4. 初始化模型、损失函数和优化器
model = CNN().to(device)
criterion = nn.CrossEntropyLoss() # 交叉熵损失,适用于分类问题
optimizer = optim.Adam(model.parameters(), lr=learning_rate) # Adam优化器
# 5. 训练模型
def train():
model.train() # 设置为训练模式
total_loss = 0
correct = 0
total = 0
for batch_idx, (images, labels) in enumerate(train_loader):
# 将数据移动到指定设备
images, labels = images.to(device), labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad() # 清零梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 统计信息
total_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
# 打印训练进度
if (batch_idx + 1) % 100 == 0:
print(f'Train Batch: [{batch_idx+1}/{len(train_loader)}], Loss: {loss.item():.4f}, '
f'Train Accuracy: {100.*correct/total:.2f}%')
# 计算平均损失和准确率
avg_loss = total_loss / len(train_loader)
train_acc = 100. * correct / total
return avg_loss, train_acc
# 6. 测试模型
def test():
model.eval() # 设置为评估模式
total_loss = 0
correct = 0
total = 0
# 不计算梯度,节省内存和计算时间
with torch.no_grad():
for batch_idx, (images, labels) in enumerate(test_loader):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
total_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
avg_loss = total_loss / len(test_loader)
test_acc = 100. * correct / total
print(f'Test Loss: {avg_loss:.4f}, Test Accuracy: {test_acc:.2f}%')
return avg_loss, test_acc
# 7. 执行训练和测试
train_losses = []
train_accuracies = []
test_losses = []
test_accuracies = []
for epoch in range(num_epochs):
print(f'\nEpoch [{epoch+1}/{num_epochs}]')
print('-' * 50)
train_loss, train_acc = train()
test_loss, test_acc = test()
train_losses.append(train_loss)
train_accuracies.append(train_acc)
test_losses.append(test_loss)
test_accuracies.append(test_acc)
# 8. 绘制训练过程中的损失和准确率曲线
plt.figure(figsize=(12, 4))
# 损失曲线
plt.subplot(1, 2, 1)
plt.plot(range(1, num_epochs+1), train_losses, label='Train Loss')
plt.plot(range(1, num_epochs+1), test_losses, label='Test Loss')
plt.title('Loss vs Epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
# 准确率曲线
plt.subplot(1, 2, 2)
plt.plot(range(1, num_epochs+1), train_accuracies, label='Train Accuracy')
plt.plot(range(1, num_epochs+1), test_accuracies, label='Test Accuracy')
plt.title('Accuracy vs Epochs')
plt.xlabel('Epochs')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.tight_layout()
plt.show()
# 9. 展示一些测试样本的预测结果
def show_predictions(num_samples=5):
model.eval()
with torch.no_grad():
# 获取一些测试样本
images, labels = next(iter(test_loader))
images, labels = images[:num_samples], labels[:num_samples]
images = images.to(device)
# 预测
outputs = model(images)
_, predicted = outputs.max(1)
# 显示结果
plt.figure(figsize=(10, 4))
for i in range(num_samples):
plt.subplot(1, num_samples, i+1)
plt.imshow(images[i].cpu().squeeze().numpy(), cmap='gray')
plt.title(f'Pred: {predicted[i].item()}\nTrue: {labels[i].item()}')
plt.axis('off')
plt.tight_layout()
plt.show()
# 展示预测结果
show_predictions(5)
# 保存模型
torch.save(model.state_dict(), 'mnist_cnn.pth')
print("模型已保存为 'mnist_cnn.pth'")2. 库导入部分
python
import torch # PyTorch核心库,提供张量操作和神经网络功能
import torch.nn as nn # 神经网络模块,包含各种层和损失函数
import torch.optim as optim # 优化器模块,如Adam、SGD
from torch.utils.data import DataLoader # 数据加载工具,用于批量处理数据
from torchvision import datasets, transforms # 计算机视觉工具,包含数据集和数据转换
import matplotlib.pyplot as plt # 可视化工具,用于绘制损失曲线和图像
import numpy as np # 数值计算库,辅助数据处理3. 随机种子设置
python
torch.manual_seed(42) # 设置PyTorch随机种子
np.random.seed(42) # 设置NumPy随机种子- 作用:确保每次运行代码时,随机过程(如数据打乱、参数初始化)的结果一致,便于调试和结果复现。
4. 超参数定义
python
batch_size = 64 # 每次训练的样本数:一次加载64张图像进行计算,平衡效率和内存
learning_rate = 0.001 # 学习率:控制参数更新的步长,过大会导致不收敛,过小会导致训练慢
num_epochs = 10 # 训练轮数:整个训练集被重复使用10次,确保模型充分学习
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备选择:优先使用GPU加速5. 数据预处理与加载
python
# 数据转换管道:将图像转为模型可处理的格式
transform = transforms.Compose([
transforms.ToTensor(), # ① 转换为PyTorch张量:(H, W, C)→(C, H, W),并将像素值从0-255归一化到0-1
transforms.Normalize((0.1307,), (0.3081,)) # ② 标准化:用MNIST全局均值(0.1307)和标准差(0.3081)处理,使数据分布更稳定
])
# 加载训练集和测试集
train_dataset = datasets.MNIST(
root='./data', # 数据保存路径
train=True, # 选择训练集
download=True, # 本地没有则自动从网上下载
transform=transform # 应用上述转换
)
test_dataset = datasets.MNIST(
root='./data',
train=False, # 选择测试集
download=True,
transform=transform
)
# 数据加载器:批量加载数据,支持打乱和多线程
train_loader = DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True # 训练时打乱数据顺序,避免模型学习到数据顺序规律
)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=batch_size,
shuffle=False # 测试时无需打乱,按顺序评估即可
)6. CNN网络架构
python
class CNN(nn.Module): # 继承nn.Module,自定义网络必须实现的基类
def __init__(self):
super(CNN, self).__init__() # 初始化父类
# 第一个卷积块:提取低级特征(如边缘、线条)
self.conv1 = nn.Sequential( # Sequential将多个层组合为一个模块
# 卷积层:输入1通道(灰度图),输出32通道(32个不同的卷积核),3×3卷积核
nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
nn.ReLU(), # 激活函数:引入非线性,过滤负特征
nn.MaxPool2d(kernel_size=2, stride=2) # 池化层:2×2窗口,步长2,输出尺寸减半(28→14)
)
# 第二个卷积块:提取高级特征(如数字的局部形状)
self.conv2 = nn.Sequential(
# 卷积层:输入32通道(来自conv1),输出64通道,3×3卷积核
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2) # 输出尺寸再减半(14→7)
)
# 全连接层:将卷积特征映射到分类结果
self.fc1 = nn.Linear(7 * 7 * 64, 128) # 输入:64个7×7的特征图展平(7×7×64),输出128维特征
self.fc2 = nn.Linear(128, 10) # 输出10个类别(0-9)
self.dropout = nn.Dropout(0.5) # 随机失活50%神经元,防止过拟合
def forward(self, x): # 前向传播:定义数据在网络中的流动路径
x = self.conv1(x) # 输入x:(batch_size, 1, 28, 28) → 输出:(batch_size, 32, 14, 14)
x = self.conv2(x) # 输出:(batch_size, 64, 7, 7)
x = x.view(-1, 7 * 7 * 64) # 展平:(batch_size, 64, 7, 7) → (batch_size, 7×7×64=3136)
x = self.dropout(x) # 随机失活部分神经元
x = torch.relu(self.fc1(x)) # 全连接+激活:(batch_size, 3136) → (batch_size, 128)
x = self.fc2(x) # 输出层:(batch_size, 128) → (batch_size, 10)(10个类别的得分)
return x
网络维度变化详解 :
输入图像(28×28×1)→ conv1(32个3×3卷积核,输出28×28×32)→ MaxPool2d(输出14×14×32)→ conv2(64个3×3卷积核,输出14×14×64)→ MaxPool2d(输出7×7×64)→ 展平(7×7×64=3136)→ 全连接层→输出10个类别得分。
7. 模型初始化、损失函数与优化器
python
model = CNN().to(device) # 初始化模型,并移动到GPU/CPU
criterion = nn.CrossEntropyLoss() # 交叉熵损失:适用于多分类问题,内置softmax函数
optimizer = optim.Adam(model.parameters(), lr=learning_rate) # Adam优化器:自适应学习率,收敛快8. 训练函数(train)
python
def train():
model.train() # 设为训练模式:启用dropout和批归一化的训练行为
total_loss = 0 # 累计损失
correct = 0 # 累计正确预测数
total = 0 # 累计样本数
for batch_idx, (images, labels) in enumerate(train_loader):
# 将数据移动到训练设备(GPU/CPU)
images, labels = images.to(device), labels.to(device)
# 前向传播:计算模型输出
outputs = model(images) # outputs形状:(batch_size, 10)
loss = criterion(outputs, labels) # 计算损失
# 反向传播与参数更新
optimizer.zero_grad() # 清零梯度(避免累积)
loss.backward() # 反向传播:计算梯度
optimizer.step() # 更新参数:根据梯度调整权重
# 统计训练效果
total_loss += loss.item() # 累加损失(.item()将张量转为Python数值)
_, predicted = outputs.max(1) # 取得分最高的类别作为预测结果(维度1是类别)
total += labels.size(0) # 累加样本数
correct += predicted.eq(labels).sum().item() # 累加正确数
# 每100个批次打印一次进度
if (batch_idx + 1) % 100 == 0:
print(f'Train Batch: [{batch_idx+1}/{len(train_loader)}], Loss: {loss.item():.4f}, '
f'Train Accuracy: {100.*correct/total:.2f}%')
# 计算本轮平均损失和准确率
avg_loss = total_loss / len(train_loader)
train_acc = 100. * correct / total
return avg_loss, train_acc9. 测试函数(test)
python
def test():
model.eval() # 设为评估模式:关闭dropout,固定批归一化参数
total_loss = 0
correct = 0
total = 0
with torch.no_grad(): # 禁用梯度计算:节省内存,加速计算(测试无需更新参数)
for batch_idx, (images, labels) in enumerate(test_loader):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
total_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
avg_loss = total_loss / len(test_loader)
test_acc = 100. * correct / total
print(f'Test Loss: {avg_loss:.4f}, Test Accuracy: {test_acc:.2f}%')
return avg_loss, test_acc10. 执行训练与可视化
python
# 记录每轮的损失和准确率
train_losses = []
train_accuracies = []
test_losses = []
test_accuracies = []
# 循环训练10轮
for epoch in range(num_epochs):
print(f'\nEpoch [{epoch+1}/{num_epochs}]')
print('-' * 50)
# 训练并测试
train_loss, train_acc = train()
test_loss, test_acc = test()
# 保存结果
train_losses.append(train_loss)
train_accuracies.append(train_acc)
test_losses.append(test_loss)
test_accuracies.append(test_acc)
# 绘制损失曲线和准确率曲线
plt.figure(figsize=(12, 4))
# 损失曲线:观察是否收敛(损失是否下降并稳定)
plt.subplot(1, 2, 1)
plt.plot(range(1, num_epochs+1), train_losses, label='Train Loss')
plt.plot(range(1, num_epochs+1), test_losses, label='Test Loss')
plt.title('Loss vs Epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
# 准确率曲线:观察模型性能提升
plt.subplot(1, 2, 2)
plt.plot(range(1, num_epochs+1), train_accuracies, label='Train Accuracy')
plt.plot(range(1, num_epochs+1), test_accuracies, label='Test Accuracy')
plt.title('Accuracy vs Epochs')
plt.xlabel('Epochs')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.tight_layout()
plt.show()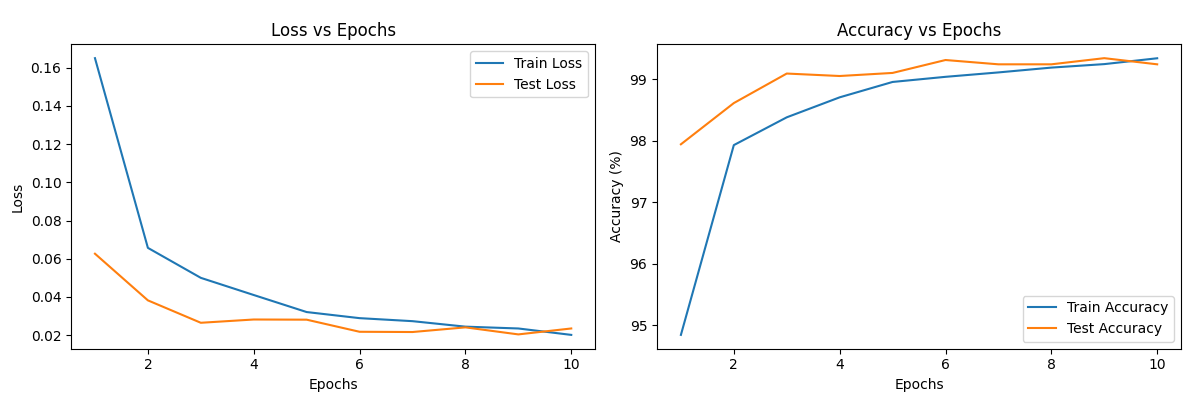
11. 展示预测结果与保存模型
python
def show_predictions(num_samples=5):
model.eval()
with torch.no_grad():
# 取测试集的前5个样本
images, labels = next(iter(test_loader))
images, labels = images[:num_samples], labels[:num_samples]
images = images.to(device)
# 预测
outputs = model(images)
_, predicted = outputs.max(1)
# 可视化:显示图像、预测值和真实值
plt.figure(figsize=(10, 4))
for i in range(num_samples):
plt.subplot(1, num_samples, i+1)
# 转换为numpy图像(需从GPU移回CPU,去除通道维度)
plt.imshow(images[i].cpu().squeeze().numpy(), cmap='gray')
plt.title(f'Pred: {predicted[i].item()}\nTrue: {labels[i].item()}')
plt.axis('off')
plt.tight_layout()
plt.show()
# 展示5个样本的预测结果
show_predictions(5)
# 保存模型参数(仅保存权重,不保存整个模型,节省空间)
torch.save(model.state_dict(), 'mnist_cnn.pth')
print("模型已保存为 'mnist_cnn.pth'")