本期我们来学习一个python中的一个常见的应用:爬虫。
相关代码已经上传至作者个人gitee:楼田莉子/Python 学习
目录
[beautiful soup解析库](#beautiful soup解析库)
[beautiful soup解析库](#beautiful soup解析库)
[beautiful soup对象的介绍及其创建](#beautiful soup对象的介绍及其创建)
[1. BeautifulSoup 对象](#1. BeautifulSoup 对象)
[2. Tag 对象](#2. Tag 对象)
[3. NavigableString 对象](#3. NavigableString 对象)
[4. Comment 对象](#4. Comment 对象)
[beautiful soup对象的find方法](#beautiful soup对象的find方法)
[beautiful soup4方法表](#beautiful soup4方法表)
[Unicode 字符类转义](#Unicode 字符类转义)
[re 模块主要函数表](#re 模块主要函数表)
[正则表达式模式对象 (Pattern) 方法表](#正则表达式模式对象 (Pattern) 方法表)
[匹配对象 (Match) 方法表](#匹配对象 (Match) 方法表)
爬虫的介绍
在浏览器上搜索相关的内容是很常见的事情,但是如果我们要进行多轮访问搜索的话就会显得很麻烦,因此便有了爬虫这个东西的存在。
当你使用浏览器的时候,会先发送请求给服务器,随后服务器会获取反馈数据并进行渲染。
但是爬虫只是发送请求给服务器,随后服务器会获取反馈相应的数据
网络爬虫的定义如下:
网络爬虫 (Web Crawler),也被称为网络蜘蛛(Web Spider),是一种按照预设规则,自动、批量地浏览万维网并下载网页内容的计算机程序或自动化脚本。它是搜索引擎的核心组成部分,也是大数据领域进行数据采集的关键技术。
关于爬虫,其核心概念主要有以下几点:
-
种子URL: 爬虫开始抓取的初始网址集合。
-
网页抓取: 通过HTTP/HTTPS协议向目标服务器发送请求,并获取网页原始数据(通常是HTML代码)的过程。
-
解析与提取: 对抓取到的网页进行解析(如使用正则表达式、XPath、CSS选择器等),从中提取出有价值的结构化数据(如文本、链接、图片URL等)和新的URL。
-
URL队列: 一个用于管理待抓取URL的队列,爬虫会从队列中取出URL进行抓取,并将新发现的URL放入队列,遵循一定的策略(如广度优先或深度优先)。
-
去重: 在爬行过程中,通过特定算法(如布隆过滤器)对URL进行判重,避免重复抓取相同页面,提高效率。
-
Robots协议: 网站所有者放置在根目录下的
robots.txt文件,用于告知爬虫哪些目录或文件可以被抓取,哪些应被禁止。遵守该协议是网络爬虫的道德和法律基础。
爬虫的特点是:
-
自动化: 无需人工干预,可7x24小时不间断工作。
-
高效性: 抓取速度远超人工操作,能快速处理海量数据。
-
可扩展性: 可以通过分布式架构,部署多个爬虫节点协同工作,进一步提升抓取能力。
-
按需配置: 爬虫的行为和规则可以根据目标网站的结构和用户的数据需求进行高度定制。
requests请求库
什么是requests请求库
requests 是 Python 中最流行、最简洁易用的 HTTP 库。在爬虫中,它的核心作用就是模拟浏览器向目标网站服务器发送 HTTP 请求,并获取服务器返回的响应数据。
requests请求库的下载
本次我们采用pip下载方式,关于pip的内容在作者前面的博客内容中已经介绍过了,可以去看这篇博客:https://blog.csdn.net/2401_89119815/article/details/151651579?fromshare=blogdetail&sharetype=blogdetail&sharerId=151651579&sharerefer=PC&sharesource=2401_89119815&sharefrom=from_link
下载方式:在终端敲入如下所示的代码
bash
pip install requests验证安装
python
import requests
print(requests.__version__)如果运行没有报错就安装成功
示例:
python
#导入模块
import requests
#发送请求
response=requests.get("https://www.baidu.com")
#获知字符编码格式
#print(response.encoding)
#如果不是utf-8可以这么指定
#response.encoding="utf-8"
#获取响应
print(response.text)#文本数据
print(response.content)#二进制数据
#二进制解码为utf-8字符编码格式
print(response.content.decode("utf-8"))beautiful soup解析库
Beautiful Soup(简称 bs4)是一个 Python 库,其主要功能是从 HTML 或 XML 文档中提取数据。
其作用为:
-
解析混乱的 HTML:即使 HTML 格式不规范、标签未闭合,它也能很好地处理。
-
导航与搜索:提供了一套简单、直观的方法来遍历 HTML 的树形结构,并快速找到所需的标签和内容。
-
数据提取 :从标签中提取文本、属性(如链接的
href、图片的src)。
beautiful soup解析库
beautiful soup3已经停止更新了,所以我们只下载beautiful soup解析库4
bash
pip install beautifulsoup4注意:尽管安装的时候叫beautifulsoup4,但是导入的时候是导入bs4!
同时为了更好的兼容性,建议安装lxml解析器,安装方式如下
bash
pip install lxmlbeautiful soup对象的介绍及其创建
BeautifulSoup对象:代表要解析整个文档树。
它支持 遍历文档树 和 搜索文档树 中描述的大部分的方法。
测试:
python
#导入模块
from bs4 import BeautifulSoup
import lxml
#创建对象
soup=BeautifulSoup("<html>data</html>",'lxml')
#打印对象
print(soup)beautiful soup对象主要有以下几个部分组成: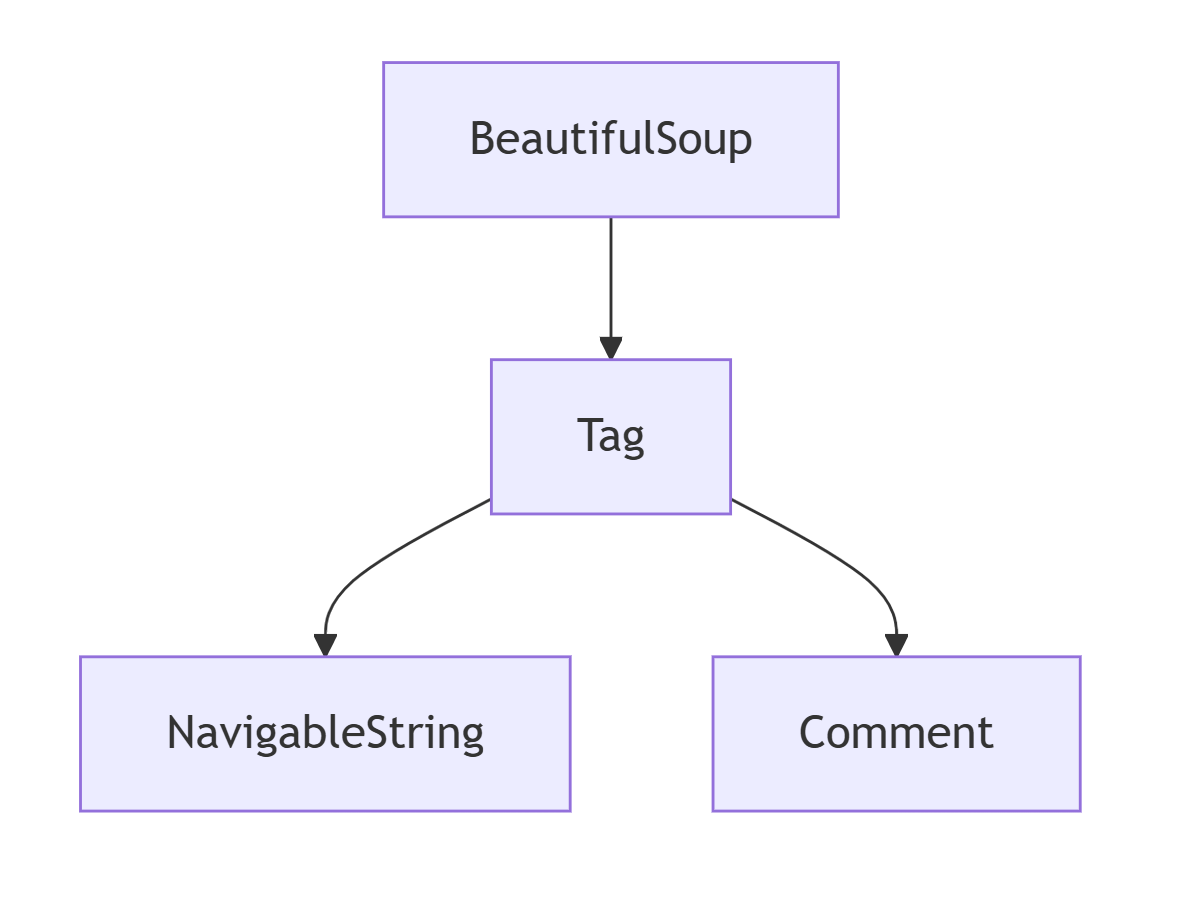
1. BeautifulSoup 对象
作用:代表整个解析后的文档,是解析树的根节点。
特点:
-
可以像 Tag 对象一样进行遍历和搜索
-
包含了文档的所有内容
-
通常是我们创建的第一个对象
python#创建对象 from bs4 import BeautifulSoup html_doc = """ <html> <head><title>示例页面</title></head> <body> <p class="content">这是一个段落</p> </body> </html> """ soup = BeautifulSoup(html_doc, 'lxml') print(type(soup)) # <class 'bs4.BeautifulSoup'> #常见方法 # 获取文档标题 print(soup.title) # <title>示例页面</title> # 获取文档的字符串表示 print(soup.prettify()) # 格式化的HTML # 查找所有元素(与Tag对象方法相同) all_ps = soup.find_all('p')2. Tag 对象
作用:对应 HTML/XML 中的标签,是 BeautifulSoup 中最常用的对象。
特点:
-
具有名称和属性
-
可以包含其他 Tag 对象或字符串
-
支持遍历和搜索方法
python
#创建对象
# 获取第一个 <p> 标签
p_tag = soup.p
print(type(p_tag)) # <class 'bs4.element.Tag'>
# 标签名称
print(p_tag.name) # 'p'
# 标签属性(返回字典)
print(p_tag.attrs) # {'class': ['content']}
# 获取特定属性
print(p_tag['class']) # ['content']
print(p_tag.get('class')) # ['content']
#常见方法
# 查找后代标签
p_tag.find_all('span')
# 获取所有直接子标签
list(p_tag.children)
# 获取所有后代标签
list(p_tag.descendants)
# 获取父标签
parent = p_tag.parent
# 获取兄弟标签
next_sibling = p_tag.next_sibling
prev_sibling = p_tag.previous_sibling3. NavigableString 对象
作用:代表标签内的文本内容,是特殊的字符串对象。
特点:
-
可以像普通字符串一样操作
-
支持在解析树中导航
-
不包含任何子节点
python# 获取标签的文本内容 text_content = p_tag.string print(type(text_content)) # <class 'bs4.element.NavigableString'> print(text_content) # '这是一个段落' # 或者使用 .text 属性(获取所有后代文本) print(p_tag.text) # '这是一个段落' # NavigableString 可以转换为普通字符串 normal_string = str(text_content) print(type(normal_string)) # <class 'str'>
重要区别:
-
.string:如果标签只有一个子节点且是字符串,返回该字符串,否则返回 None -
.text或.get_text():返回标签及其所有后代标签中的文本内容
python
html = '<div>Hello <span>World</span></div>'
soup = BeautifulSoup(html, 'lxml')
div_tag = soup.div
print(div_tag.string) # None(因为包含多个子节点)
print(div_tag.text) # 'Hello World'(所有文本内容)4. Comment 对象
作用:特殊类型的 NavigableString,表示 HTML 注释。
特点:
-
继承自 NavigableString
-
在输出时不会显示注释符号
-
需要特殊处理来识别
python
html_with_comment = '<p>正常文本<!-- 这是一个注释 --></p>'
soup = BeautifulSoup(html_with_comment, 'lxml')
p_tag = soup.p
# 遍历所有子节点
for child in p_tag.children:
print(f"类型: {type(child)}, 内容: {repr(child)}")
# 输出:
# 类型: <class 'bs4.element.NavigableString'>, 内容: '正常文本'
# 类型: <class 'bs4.element.Comment'>, 内容: ' 这是一个注释 '
# 检查是否为注释
comment = list(p_tag.children)[1]
print(isinstance(comment, str)) # True(Comment也是字符串)
print(hasattr(comment, 'comment')) # 检查是否有comment属性对象关系与示例
python
from bs4 import BeautifulSoup
# 复杂HTML示例
complex_html = """
<html>
<body>
<div id="main">
<h1>标题</h1>
<p class="content">第一段<strong>重点</strong>内容</p>
<!-- 这是注释 -->
<p>第二段内容</p>
</div>
</body>
</html>
"""
soup = BeautifulSoup(complex_html, 'lxml')
# 1. 获取BeautifulSoup对象
print("=== BeautifulSoup对象 ===")
print(f"文档类型: {type(soup)}")
# 2. 获取Tag对象
div_tag = soup.find('div', id='main')
print("\n=== Tag对象 ===")
print(f"标签名: {div_tag.name}")
print(f"标签属性: {div_tag.attrs}")
# 3. 遍历Tag对象的子节点
print("\n=== 遍历子节点 ===")
for i, child in enumerate(div_tag.children):
print(f"子节点 {i}: 类型={type(child).__name__}, 内容={repr(str(child)[:30])}")
# 4. 处理NavigableString
print("\n=== NavigableString ===")
first_p = div_tag.find('p')
print(f"段落文本: {repr(first_p.text)}")
# 5. 处理混合内容
print("\n=== 混合内容分析 ===")
for element in first_p.contents:
element_type = type(element).__name__
content = repr(str(element).strip())
print(f"元素: {element_type:15} -> {content}")打印结果为:
bash
=== BeautifulSoup对象 ===
文档类型: <class 'bs4.BeautifulSoup'>
=== Tag对象 ===
标签名: div
标签属性: {'id': 'main'}
=== 遍历子节点 ===
子节点 0: 类型=NavigableString, 内容='\n'
子节点 1: 类型=Tag, 内容='<h1>标题</h1>'
子节点 2: 类型=NavigableString, 内容='\n'
子节点 3: 类型=Tag, 内容='<p class="content">第一段<strong>'
子节点 4: 类型=NavigableString, 内容='\n'
子节点 5: 类型=Comment, 内容=' 这是注释 '
子节点 6: 类型=NavigableString, 内容='\n'
子节点 7: 类型=Tag, 内容='<p>第二段内容</p>'
子节点 8: 类型=NavigableString, 内容='\n'
=== NavigableString ===
段落文本: '第一段重点内容'
=== 混合内容分析 ===
元素: NavigableString -> '第一段'
元素: Tag -> '<strong>重点</strong>'
元素: NavigableString -> '内容'beautiful soup对象的find方法
find方法的作用:搜索文档树
语法格式:
python
find(name=None, attrs={}, recursive=True, string=None, **kwargs)参数为以下含义:
| 参数 | 类型 | 说明 | 默认值 |
|---|---|---|---|
name |
字符串/列表/正则表达式/函数 | 要查找的标签名称 | None |
attrs |
字典 | 要匹配的属性键值对 | {} |
recursive |
布尔值 | 是否递归搜索所有子节点 | True |
string |
字符串/正则表达式/函数 | 要匹配的文本内容 | None |
**kwargs |
键值参数 | 属性的快捷方式(如 id="main") |
- |
返回值内容:
-
找到匹配元素:返回 Tag 对象
-
未找到匹配元素:返回 None
一个案例讲遍find所有方法:
python
#导入模块
from bs4 import BeautifulSoup
#准备文档字符串
html='''<!DOCTYPE html>
<html>
<head>
<title>简单测试页面</title>
</head>
<body>
<h1>商品列表</h1>
<div class="product">
<h2 class="name">笔记本电脑</h2>
<p class="price">¥5999</p>
<p class="category">电子产品</p>
</div>
<div class="product">
<h2 class="name">Python编程书</h2>
<p class="price">¥89</p>
<p class="category">图书</p>
</div>
<div class="product sale">
<h2 class="name">无线鼠标</h2>
<p class="price">¥129 <span class="old-price">¥199</span></p>
<p class="category">电子产品</p>
</div>
<table border="1">
<tr>
<th>商品</th>
<th>库存</th>
</tr>
<tr>
<td>笔记本电脑</td>
<td>15</td>
</tr>
<tr>
<td>Python编程书</td>
<td>32</td>
</tr>
</table>
<div class="pagination">
<a href="/page1">上一页</a>
<a href="/page2">1</a>
<a href="/page3">2</a>
<a href="/page4">下一页</a>
</div>
</body>
</html>'''
#创建对象
soup=BeautifulSoup(html,"lxml")
#查找title标签
title=soup.find('title')
print(title)
#查找a标签
a=soup.find('a')
print(a)
#查找所有的a标签
a_s=soup.find_all('a')
print(a_s)
#根据属性查找
#方式一:命名参数指定
link1=soup.find(id="name")
print(link1)
#方式二:attrs指定属性字典,更推荐这个方法
link1_2 =soup.find(attrs={"id":"name"})
print(link1_2)
#查找文本
text=soup.find(text="Python编程书")
print(text)
#tag对象
print(type(a))
#标签名
print("标签名>",a.name)
print("标签属性>",a.attrs)
print("标签文本内容>",a.text)beautiful soup4方法表
| 方法类别 | 方法名称 | 功能描述 | 返回值类型 |
|---|---|---|---|
| 文档解析 | BeautifulSoup(html, 'parser') |
创建BeautifulSoup对象,解析HTML/XML文档 | BeautifulSoup对象 |
| 搜索方法 | find(name, attrs, recursive, string, **kwargs) |
查找第一个匹配的标签 | Tag对象 或 None |
find_all(name, attrs, recursive, string, limit, **kwargs) |
查找所有匹配的标签 | ResultSet(Tag对象列表) | |
find_parent(name, attrs, string, **kwargs) |
在父标签中查找第一个匹配的标签 | Tag对象 或 None | |
find_parents(name, attrs, string, limit, **kwargs) |
在祖先标签中查找所有匹配的标签 | ResultSet(Tag对象列表) | |
find_next_sibling(name, attrs, string, **kwargs) |
查找后一个兄弟标签 | Tag对象 或 None | |
find_previous_sibling(name, attrs, string, **kwargs) |
查找前一个兄弟标签 | Tag对象 或 None | |
select(css_selector) |
使用CSS选择器查找所有匹配的标签 | ResultSet(Tag对象列表) | |
select_one(css_selector) |
使用CSS选择器查找第一个匹配的标签 | Tag对象 或 None | |
| 遍历方法 | contents |
获取标签的直接子节点列表 | 列表 |
children |
获取标签的直接子节点的迭代器 | 生成器 | |
descendants |
获取标签所有后代节点的迭代器 | 生成器 | |
parent |
获取标签的父节点 | Tag对象 或 BeautifulSoup对象 | |
parents |
获取标签所有祖先节点的迭代器 | 生成器 | |
next_sibling |
获取后一个兄弟节点 | PageElement 或 None | |
previous_sibling |
获取前一个兄弟节点 | PageElement 或 None | |
next_siblings |
获取后面所有兄弟节点的迭代器 | 生成器 | |
previous_siblings |
获取前面所有兄弟节点的迭代器 | 生成器 | |
| 数据提取 | get_text(separator, strip) |
获取标签及其所有后代的文本内容 | 字符串 |
text |
获取标签及其所有后代的文本内容(get_text()的别名) |
字符串 | |
string |
如果标签只有一个NavigableString子节点,则返回该节点 | NavigableString 或 None | |
strings |
获取标签内所有字符串的迭代器 | 生成器 | |
stripped_strings |
获取标签内所有去空白的字符串迭代器 | 生成器 | |
get(attribute_name, default) |
获取标签属性的值 | 属性值字符串 或 default | |
has_attr(attribute_name) |
检查标签是否包含指定属性 | 布尔值 | |
attrs |
获取标签的所有属性字典 | 字典 | |
| 文档操作 | prettify(encoding, formatter) |
返回格式化的文档字符串 | 字符串 |
decode(pretty, encoding, formatter) |
将文档渲染为字符串 | 字符串 | |
encode(encoding, indent, formatter) |
将文档编码为字节 | 字节 | |
append(tag) |
向标签中添加内容 | None | |
extract() |
将标签从文档树中移除 | Tag对象 | |
decompose() |
将标签从文档树中移除并完全销毁 | None | |
replace_with(content) |
用指定内容替换当前标签 | None | |
wrap(tag) |
用指定标签包装当前标签 | 新Tag对象 | |
unwrap() |
移除当前标签的包装,保留其内容 | 被移除的Tag对象 |
正则表达式
正则表达式(Regular Expression)是一种强大的文本处理工具,用于在字符串中进行模式匹配和搜索操作。Python 通过 re 模块提供了完整的正则表达式功能。
python
import re正则表达式是由普通字符和特殊字符(元字符)组成的文本模式,用于描述、匹配一系列符合某个句法规则的字符串。
正则表达式基本语法
元字符表
| 类别 | 元字符 | 描述 | 示例 | 匹配结果 |
|---|---|---|---|---|
| 基本匹配 | . |
匹配除换行符外的任意字符 | a.c |
"abc", "a c", "a-c" |
\ |
转义字符 | a\.c |
"a.c" (不匹配 "abc") | |
| 位置锚点 | ^ |
匹配字符串开始 | ^abc |
"abc" (仅在开头) |
$ |
匹配字符串结束 | abc$ |
"abc" (仅在结尾) | |
\b |
单词边界 | \bword\b |
"word" (作为独立单词) | |
\B |
非单词边界 | \Bword\B |
"swordfish" 中的 "word" | |
| 量词 | * |
匹配前元素0次或多次 | ab*c |
"ac", "abc", "abbc" |
+ |
匹配前元素1次或多次 | ab+c |
"abc", "abbc" (不匹配 "ac") | |
? |
匹配前元素0次或1次 | ab?c |
"ac", "abc" | |
{n} |
匹配前元素恰好n次 | a{3} |
"aaa" | |
{n,} |
匹配前元素至少n次 | a{2,} |
"aa", "aaa", ... | |
{n,m} |
匹配前元素n到m次 | a{2,4} |
"aa", "aaa", "aaaa" | |
| 字符类 | [] |
字符集合 | [aeiou] |
任意元音字母 |
[^] |
否定字符集合 | [^aeiou] |
任意非元音字符 | |
- |
字符范围 | [a-z] |
任意小写字母 | |
| 预定义字符类 | \d |
数字字符 | \d+ |
"123", "45" |
\D |
非数字字符 | \D+ |
"abc", "!@#" | |
\s |
空白字符 | \s+ |
空格, 制表符, 换行 | |
\S |
非空白字符 | \S+ |
"abc", "123" | |
\w |
单词字符 | \w+ |
"hello", "word123" | |
\W |
非单词字符 | \W+ |
"!", "?*" | |
| 分组与引用 | () |
捕获分组 | (abc)+ |
"abc", "abcabc" |
(?:) |
非捕获分组 | (?:abc)+ |
"abc" (不捕获分组) | |
| ` | ` | 或操作 | `cat | |
\n |
反向引用 | (a)b\1 |
"aba" | |
| 特殊字符 | \n |
换行符 | \n |
换行 |
\t |
制表符 | \t |
制表符 | |
\r |
回车符 | \r |
回车 |
量词模式表
| 模式 | 描述 | 示例 | 匹配结果 |
|---|---|---|---|
| 贪婪匹配 | 默认模式,尽可能多匹配 | a.*b |
"axxxbxxxb" → "axxxbxxxb" |
| 懒惰匹配 | 尽可能少匹配 | a.*?b |
"axxxbxxxb" → "axxxb" |
| 独占匹配 | 不回溯的匹配 | a.*+b |
"axxxb" → 匹配成功 |
标志修饰符表
| 标志 | 简写 | 描述 | 示例 |
|---|---|---|---|
re.IGNORECASE |
re.I |
忽略大小写 | [a-z] 匹配 "A", "B", "C" |
re.MULTILINE |
re.M |
多行模式 | ^ 匹配每行开头 |
re.DOTALL |
re.S |
让.匹配所有字符 |
. 匹配换行符 |
re.VERBOSE |
re.X |
忽略空白和注释 | 允许格式化正则表达式 |
re.ASCII |
re.A |
仅ASCII字符 | \w 只匹配ASCII字符 |
常用模式示例表
| 用途 | 正则表达式 | 说明 |
|---|---|---|
| 邮箱 | ^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$ |
基本邮箱验证 |
| URL | https?://[^\s]+ |
匹配HTTP/HTTPS链接 |
| 中文 | [\u4e00-\u9fff] |
匹配中文字符 |
| IP地址 | \b(?:\d{1,3}\.){3}\d{1,3}\b |
简单IP地址匹配 |
| 日期 | \d{4}-\d{2}-\d{2} |
YYYY-MM-DD格式 |
| 手机号 | 1[3-9]\d{9} |
中国手机号格式 |
转义字符表
| 字符 | 正则表达式写法 | 匹配内容 | 示例 |
|---|---|---|---|
. |
\. |
句点字符 | a\.b 匹配 "a.b" |
* |
\* |
星号字符 | a\*b 匹配 "a*b" |
+ |
\+ |
加号字符 | a\+b 匹配 "a+b" |
? |
\? |
问号字符 | a\?b 匹配 "a?b" |
$ |
\$ |
美元符号 | \$100 匹配 "$100" |
^ |
\^ |
脱字符 | \^start 匹配 "^start" |
[ |
\[ |
左方括号 | \[abc\] 匹配 "abc" |
] |
\] |
右方括号 | \[abc\] 匹配 "abc" |
( |
\( |
左圆括号 | \(group\) 匹配 "(group)" |
) |
\) |
右圆括号 | \(group\) 匹配 "(group)" |
{ |
\{ |
左花括号 | \{3\} 匹配 "{3}" |
} |
\} |
右花括号 | \{3\} 匹配 "{3}" |
| ` | ` | ` | ` |
\\ |
\\\\ |
反斜杠字符 | C:\\\\Windows 匹配 "C:\Windows" |
特殊转义序列表
| 转义序列 | 描述 | 示例 | 匹配结果 |
|---|---|---|---|
\n |
换行符 | line1\nline2 |
匹配两行文本 |
\r |
回车符 | \r\n |
Windows 换行符 |
\t |
制表符 | col1\tcol2 |
制表符分隔的文本 |
\f |
换页符 | \f |
换页字符 |
\v |
垂直制表符 | \v |
垂直制表符 |
\a |
响铃符 | \a |
响铃字符 |
\e |
转义符 | \e |
ESC 字符 |
\0 |
空字符 | \0 |
NULL 字符 |
字符类转义表
| 转义序列 | 描述 | 等价写法 | 示例 |
|---|---|---|---|
\d |
任意数字 | [0-9] |
\d+ 匹配 "123" |
\D |
任意非数字 | [^0-9] |
\D+ 匹配 "abc" |
\s |
任意空白字符 | [ \t\n\r\f\v] |
\s+ 匹配空格和制表符 |
\S |
任意非空白字符 | [^ \t\n\r\f\v] |
\S+ 匹配 "word" |
\w |
单词字符 | [a-zA-Z0-9_] |
\w+ 匹配 "hello_123" |
\W |
非单词字符 | [^a-zA-Z0-9_] |
\W+ 匹配 "!@#" |
Unicode 字符类转义
| 转义序列 | 描述 | 示例 |
|---|---|---|
\p{Lu} |
大写字母 | 匹配大写字母(需 regex 模块) |
\p{Ll} |
小写字母 | 匹配小写字母(需 regex 模块) |
\p{N} |
数字字符 | 匹配数字(需 regex 模块) |
\p{P} |
标点符号 | 匹配标点(需 regex 模块) |
正则表达式方法
re 模块主要函数表
| 方法 | 语法 | 功能描述 | 返回值 | 使用场景 |
|---|---|---|---|---|
| re.match() | re.match(pattern, string, flags=0) |
从字符串起始位置匹配模式 | 匹配对象(成功)或 None(失败) | 验证字符串开头格式 |
| re.search() | re.search(pattern, string, flags=0) |
扫描整个字符串,返回第一个匹配 | 匹配对象(成功)或 None(失败) | 查找字符串中的第一个匹配项 |
| re.findall() | re.findall(pattern, string, flags=0) |
返回字符串中所有非重叠匹配的列表 | 字符串列表(无分组)或元组列表(有分组) | 提取所有符合模式的子串 |
| re.finditer() | re.finditer(pattern, string, flags=0) |
返回匹配对象的迭代器 | 匹配对象迭代器 | 处理大量匹配时节省内存 |
| re.sub() | re.sub(pattern, repl, string, count=0, flags=0) |
替换字符串中的匹配项 | 替换后的新字符串 | 文本替换和清洗 |
| re.subn() | re.subn(pattern, repl, string, count=0, flags=0) |
替换匹配项并返回替换次数 | (新字符串, 替换次数) 元组 | 需要知道替换次数的场景 |
| re.split() | re.split(pattern, string, maxsplit=0, flags=0) |
根据模式分割字符串 | 分割后的字符串列表 | 复杂分隔符的分割操作 |
| re.compile() | re.compile(pattern, flags=0) |
编译正则表达式模式 | 正则表达式模式对象 | 重复使用同一模式时提高效率 |
| re.escape() | re.escape(pattern) |
转义模式中的特殊字符 | 转义后的字符串 | 处理用户输入作为正则表达式时 |
| re.fullmatch() | re.fullmatch(pattern, string, flags=0) |
整个字符串完全匹配模式 | 匹配对象(完全匹配)或 None | 验证字符串完全符合格式 |
正则表达式模式对象 (Pattern) 方法表
| 方法 | 语法 | 功能描述 | 返回值 |
|---|---|---|---|
| Pattern.match() | pattern.match(string, pos=0, endpos=-1) |
从指定位置开始匹配 | 匹配对象或 None |
| Pattern.search() | pattern.search(string, pos=0, endpos=-1) |
在指定范围内搜索第一个匹配 | 匹配对象或 None |
| Pattern.findall() | pattern.findall(string, pos=0, endpos=-1) |
返回指定范围内所有匹配 | 字符串列表或元组列表 |
| Pattern.finditer() | pattern.finditer(string, pos=0, endpos=-1) |
返回匹配对象的迭代器 | 匹配对象迭代器 |
| Pattern.sub() | pattern.sub(repl, string, count=0) |
替换匹配项 | 替换后的字符串 |
| Pattern.subn() | pattern.subn(repl, string, count=0) |
替换匹配项并返回次数 | (新字符串, 替换次数) |
| Pattern.split() | pattern.split(string, maxsplit=0) |
分割字符串 | 分割后的字符串列表 |
| Pattern.fullmatch() | pattern.fullmatch(string, pos=0, endpos=-1) |
完全匹配字符串 | 匹配对象或 None |
匹配对象 (Match) 方法表
| 方法 | 语法 | 功能描述 | 返回值 |
|---|---|---|---|
| Match.group() | match.group([group1, ...]) |
返回一个或多个匹配的子组 | 字符串或字符串元组 |
| Match.groups() | match.groups(default=None) |
返回所有匹配子组的元组 | 字符串元组 |
| Match.groupdict() | match.groupdict(default=None) |
返回命名分组的字典 | 字典 {组名: 匹配值} |
| Match.start() | match.start([group]) |
返回指定组匹配的开始位置 | 整数索引 |
| Match.end() | match.end([group]) |
返回指定组匹配的结束位置 | 整数索引 |
| Match.span() | match.span([group]) |
返回指定组的 (开始, 结束) 位置 | (start, end) 元组 |
| Match.expand() | match.expand(template) |
根据模板返回扩展字符串 | 扩展后的字符串 |
方法参数详解表
| 参数 | 适用方法 | 描述 | 默认值 | 示例 |
|---|---|---|---|---|
pattern |
所有 re 函数 | 正则表达式模式字符串 | 必需 | r"\d+" |
string |
所有匹配方法 | 要搜索的目标字符串 | 必需 | "abc123" |
flags |
所有 re 函数 | 匹配标志(位掩码) | 0 | re.IGNORECASE |
repl |
sub(), subn() | 替换字符串或函数 | 必需 | "replacement" |
count |
sub(), subn() | 最大替换次数 | 0(无限制) | 1 |
maxsplit |
split() | 最大分割次数 | 0(无限制) | 2 |
pos |
Pattern 方法 | 搜索起始位置 | 0 | 5 |
endpos |
Pattern 方法 | 搜索结束位置 | -1(到结尾) | 10 |
group |
Match 方法 | 分组编号或名称 | None(整个匹配) | 1 或 'name' |
标志参数表
| 标志 | 简写 | 描述 | 示例用法 |
|---|---|---|---|
re.IGNORECASE |
re.I |
忽略大小写 | re.search("abc", "ABC", re.I) |
re.MULTILINE |
re.M |
多行模式 | re.findall("^abc", text, re.M) |
re.DOTALL |
re.S |
让 . 匹配换行符 | re.search("a.b", text, re.S) |
re.VERBOSE |
re.X |
忽略空白和注释 | 复杂正则表达式的格式化 |
re.ASCII |
re.A |
让 \w, \W 等只匹配 ASCII | re.findall(r"\w+", text, re.A) |
re.LOCALE |
re.L |
依赖本地设置的匹配 | 已不推荐使用 |
re.DEBUG |
- | 显示调试信息 | re.compile(pattern, re.DEBUG) |
使用示例对比表
| 场景 | 推荐方法 | 示例代码 | 输出结果 |
|---|---|---|---|
| 验证字符串格式 | re.match() |
re.match(r"\d{3}", "123abc") |
匹配对象 |
| 查找第一个匹配 | re.search() |
re.search(r"\d+", "abc123def") |
<re.Match object> |
| 提取所有数字 | re.findall() |
re.findall(r"\d+", "a1b23c456") |
['1', '23', '456'] |
| 处理大文件匹配 | re.finditer() |
for match in re.finditer(r"\w+", text): |
迭代处理 |
| 替换文本 | re.sub() |
re.sub(r"\d+", "#", "a1b2") |
"a#b#" |
| 分割复杂文本 | re.split() |
re.split(r"[,;]\s*", "a,b; c") |
['a', 'b', 'c'] |
| 重复使用模式 | re.compile() |
pattern = re.compile(r"\d+") |
模式对象 |
findall方法中flag参数详解
| 标志常量 | 缩写 | 数值 | 描述 | Python版本 |
|---|---|---|---|---|
re.IGNORECASE |
re.I |
2 | 忽略大小写 | 所有版本 |
re.MULTILINE |
re.M |
8 | 多行模式 | 所有版本 |
re.DOTALL |
re.S |
16 | 让 . 匹配换行符 | 所有版本 |
re.VERBOSE |
re.X |
64 | 详细模式,忽略空白和注释 | 所有版本 |
re.ASCII |
re.A |
256 | 让 \w, \W, \b, \B, \d, \D, \s, \S 只匹配 ASCII | Python 3.6+ |
re.LOCALE |
re.L |
4 | 依赖本地设置(不推荐使用) | 所有版本 |
re.DEBUG |
- | 128 | 显示调试信息 | 所有版本 |
re.UNICODE |
re.U |
32 | Unicode 匹配(Python 3 默认) | Python 2 |
r原串
r原串是原始字符串,是Python中一种特殊的字符串字面量,以 r 或 R 为前缀,表示字符串中的反斜杠 \ 不会被当作转义字符处理。
语法格式为:
python
r"字符串内容"
R"字符串内容"尽管转义字符也可以,但是相比之下很麻烦,以下是对比
| 描述 | 普通字符串写法 | 原始字符串写法 | 实际匹配内容 |
|---|---|---|---|
| 匹配数字 | "\\d+" |
r"\d+" |
一个或多个数字 |
| 匹配单词边界 | "\\bword\\b" |
r"\bword\b" |
独立的单词"word" |
| 匹配反斜杠 | "\\\\" |
r"\\" |
单个反斜杠字符 |
| 匹配制表符 | "\\t" |
r"\t" |
制表符(原始字符串中\t仍被解释) |
正则表达式中的应用:
python
import re
# 复杂的正则表达式示例
# 匹配Windows文件路径
path = r"C:\Users\Documents\file.txt"
# 错误:普通字符串(反斜杠被转义)
wrong_pattern = "C:\\Users\\Documents\\.*" # \f 被转义为换页符
# 正确:原始字符串
correct_pattern = r"C:\\Users\\Documents\\.*"
result = re.findall(correct_pattern, path)
print(result) # ['C:\\Users\\Documents\\file.txt']
# 匹配邮箱中的特殊字符
email_pattern = r"user\.name@example\.com"
text = "联系 user.name@example.com"
result = re.findall(email_pattern, text)
print(result) # ['user.name@example.com']文件路径处理
python
import re
# Windows 文件路径匹配
windows_path = r"C:\Users\John\Documents\file.txt"
pattern = r"[A-Z]:\\(?:[^\\]+\\)*[^\\]+"
result = re.findall(pattern, windows_path)
print(result) # ['C:\\Users\\John\\Documents\\file.txt']
# Unix 文件路径匹配
unix_path = "/home/user/documents/file.txt"
pattern = r"/(?:[^/]+/)*[^/]+"
result = re.findall(pattern, unix_path)
print(result) # ['/home/user/documents/file.txt']json模块
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,具有以下特点:
-
人类可读:文本格式,易于阅读和编写
-
语言无关:独立于编程语言
-
自描述性:数据结构清晰明确
-
高效:解析和生成速度快
在python中json可以实现数据的相互交换
基础数据类型转换
| JSON 数据类型 | JSON 示例 | Python 数据类型 | Python 示例 | 转换说明 |
|---|---|---|---|---|
| object | {"name": "John"} |
dict | {"name": "John"} |
对象直接转换为字典 |
| array | [1, 2, 3] |
list | [1, 2, 3] |
数组转换为列表 |
| string | "hello" |
str | "hello" |
字符串直接对应 |
| number (整数) | 42 |
int | 42 |
整数直接对应 |
| number (浮点数) | 3.14 |
float | 3.14 |
浮点数直接对应 |
| true | true |
bool | True |
true → True |
| false | false |
bool | False |
false → False |
| null | null |
NoneType | None |
null → None |
Python 到 JSON 的特殊类型处理
| Python 数据类型 | 默认 JSON 转换结果 | 是否支持直接转换 | 处理方法 |
|---|---|---|---|
| tuple | 转换为 array | ✅ 支持 | (1, 2, 3) → [1, 2, 3] |
| set | 抛出 TypeError | ❌ 不支持 | 需先转换为 list |
| frozenset | 抛出 TypeError | ❌ 不支持 | 需先转换为 list |
| datetime | 抛出 TypeError | ❌ 不支持 | 需自定义序列化 |
| date | 抛出 TypeError | ❌ 不支持 | 需自定义序列化 |
| time | 抛出 TypeError | ❌ 不支持 | 需自定义序列化 |
| decimal.Decimal | 抛出 TypeError | ❌ 不支持 | 需转换为 float 或 str |
| bytes | 抛出 TypeError | ❌ 不支持 | 需编码为 base64 或 str |
| complex | 抛出 TypeError | ❌ 不支持 | 需转换为 dict 或 str |
| range | 抛出 TypeError | ❌ 不支持 | 需转换为 list |
| 自定义类对象 | 抛出 TypeError | ❌ 不支持 | 需实现 __json__ 或自定义序列化 |
JSON 到 Python 的转换细节
| JSON 输入 | Python 输出 | 数据类型 | 注意事项 |
|---|---|---|---|
{"a": 1, "b": 2} |
{'a': 1, 'b': 2} |
dict | 键始终转换为字符串 |
[1, "text", true] |
[1, 'text', True] |
list | 保持元素顺序 |
"unicode文本" |
'unicode文本' |
str | 支持 Unicode 字符 |
123456789012345 |
123456789012345 |
int | 支持大整数 |
1.23e-10 |
1.23e-10 |
float | 科学计数法支持 |
true / false |
True / False |
bool | 布尔值转换 |
null |
None |
NoneType | 空值转换 |
编码参数对转换的影响
| json.dumps() 参数 | 对 Python → JSON 转换的影响 | 示例对比 |
|---|---|---|
ensure_ascii=True (默认) |
非ASCII字符被转义 | "中文" → "\u4e2d\u6587" |
ensure_ascii=False |
非ASCII字符保持原样 | "中文" → "中文" |
indent=None (默认) |
紧凑格式,无换行缩进 | 单行输出 |
indent=2 |
格式化输出,2空格缩进 | 多行易读格式 |
sort_keys=False (默认) |
保持字典原有键顺序 | 输入顺序保留 |
sort_keys=True |
按键名字典序排序 | 稳定输出顺序 |
separators=(', ', ': ') (默认) |
标准分隔符 | {"a": 1, "b": 2} |
separators=(',', ':') |
紧凑分隔符 | {"a":1,"b":2} |
json转python
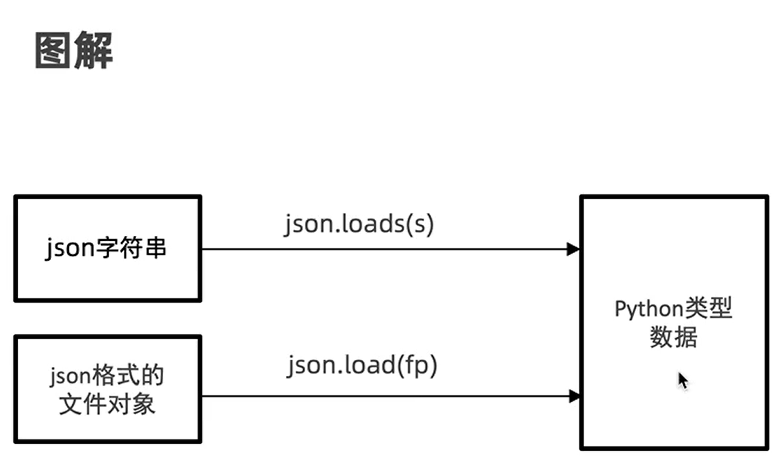
json对象转python分为以下两种
python
import json
json_str = '''{
"user_profile": {
"id": 12345,
"username": "john_doe",
"full_name": "张三",
"age": 28,
"is_active": true,
"is_premium": false,
"registration_date": "2023-05-15",
"last_login": null
}
}'''
rs = json.loads(json_str)
print(rs)
print(type(rs))
print(type(rs["user_profile"]))
#打开json文件转为python数据
with open('data.txt') as fp
python_list =json.load(fp)
print(python_list)
print(type(python_list))
print(type(python_list[0]))python转json
转换形式类似于这样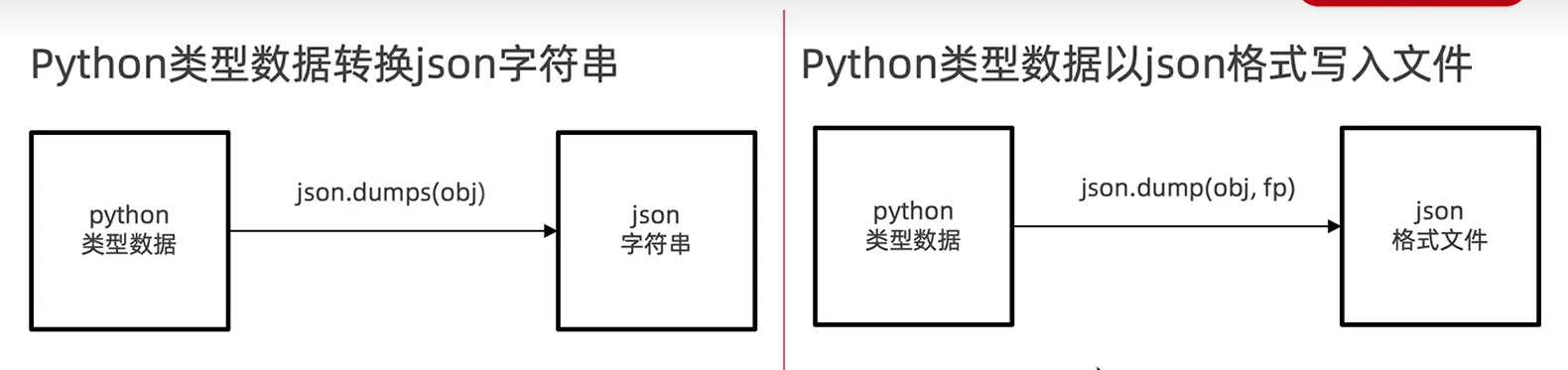
python
import json
json_str = '''{
"user_profile": {
"id": 12345,
"username": "john_doe",
"full_name": "张三",
"age": 28,
"is_active": true,
"is_premium": false,
"registration_date": "2023-05-15",
"last_login": null
}
}'''
rs = json.loads(json_str)
print(rs)
#rs为python数据
#python转json
json_str= json.dumps(rs)
#默认为TRUE,这个状态下无法显示中文
print(json_str)
#默认为TRUE,这个状态下无法显示中文
# json_str= json.dumps(rs,ensure_ascii=True)
json_str= json.dumps(rs,ensure_ascii=False)
print(json_str)
#将构建对象写入文件
with open('data.txt','w') as fp:
json_str=json.dumps(rs,fp,ensure_ascii=False)项目测试:爬取图片
以下代码为AI创作,仅供参考。
python
import requests
from bs4 import BeautifulSoup
import os
import time
from urllib.parse import urljoin, urlparse
import re
class ImageCrawler:
"""
图片爬虫类,用于从多个网页爬取图片并保存到本地
"""
def __init__(self, save_folder="downloaded_images"):
"""
初始化爬虫
参数:
save_folder: 图片保存的文件夹路径
"""
self.save_folder = save_folder
# 设置请求头,模拟浏览器访问,避免被网站屏蔽
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# 创建会话对象,可以保持cookie和连接,提高效率
self.session = requests.Session()
self.session.headers.update(self.headers)
# 创建保存文件夹,如果不存在则创建
if not os.path.exists(self.save_folder):
os.makedirs(self.save_folder)
print(f"✅ 创建保存文件夹: {self.save_folder}")
def download_image(self, img_url, filename=None):
"""
下载单张图片到本地
参数:
img_url: 图片的完整URL地址
filename: 自定义文件名,如果为None则自动生成
返回:
(成功状态, 文件名或错误信息)
"""
try:
# 如果没有提供文件名,从URL中提取文件名
if not filename:
parsed_url = urlparse(img_url)
filename = os.path.basename(parsed_url.path)
# 如果提取的文件名无效,使用时间戳生成唯一文件名
if not filename or '.' not in filename:
filename = f"image_{int(time.time())}.jpg"
# 处理文件名,确保在文件夹中唯一,避免覆盖
base_name, ext = os.path.splitext(filename)
counter = 1
final_filename = filename
save_path = os.path.join(self.save_folder, final_filename)
# 如果文件名已存在,添加数字后缀
while os.path.exists(save_path):
final_filename = f"{base_name}_{counter}{ext}"
save_path = os.path.join(self.save_folder, final_filename)
counter += 1
# 发送请求下载图片
print(f"⬇️ 正在下载: {img_url}")
response = self.session.get(img_url, timeout=10)
response.raise_for_status() # 检查请求是否成功
# 将图片内容写入文件
with open(save_path, 'wb') as f:
f.write(response.content)
return True, final_filename
except Exception as e:
# 下载失败,返回错误信息
return False, str(e)
def crawl_page(self, url, max_images=50):
"""
爬取单个页面的所有图片
参数:
url: 要爬取的网页URL
max_images: 单页最大下载图片数量
返回:
成功下载的文件名列表
"""
try:
print(f"🔍 正在解析页面: {url}")
# 发送HTTP请求获取网页内容
response = self.session.get(url, timeout=10)
response.raise_for_status() # 如果请求失败会抛出异常
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找页面中所有的img标签
img_tags = soup.find_all('img')
print(f"📷 在页面中找到 {len(img_tags)} 个图片标签")
downloaded_count = 0
successful_downloads = [] # 记录成功下载的文件名
# 遍历所有图片标签
for img in img_tags:
# 如果达到最大下载数量,停止处理
if downloaded_count >= max_images:
break
# 获取图片URL,优先考虑src属性,其次是常见的懒加载属性
img_url = img.get('src') or img.get('data-src') or img.get('data-original')
if not img_url:
continue # 如果没有找到图片URL,跳过这个标签
# 处理相对URL,将其转换为绝对URL
# 例如: '/images/pic.jpg' -> 'https://example.com/images/pic.jpg'
img_url = urljoin(url, img_url)
# 检查URL是否为图片格式,过滤掉非图片链接
if not self.is_image_url(img_url):
continue
# 下载图片
success, result = self.download_image(img_url)
if success:
downloaded_count += 1
successful_downloads.append(result)
print(f"✅ 成功下载第 {downloaded_count} 张图片: {result}")
else:
print(f"❌ 下载失败: {result}")
# 添加延迟,避免请求过于频繁被封IP
time.sleep(0.3)
print(f"📊 页面爬取完成,成功下载 {downloaded_count} 张图片")
return successful_downloads
except Exception as e:
print(f"💥 页面爬取失败: {str(e)}")
return []
def crawl_multiple_pages(self, urls, max_images_per_page=20):
"""
批量爬取多个页面的图片
参数:
urls: 要爬取的URL列表
max_images_per_page: 每个页面最大下载图片数量
返回:
所有成功下载的文件名列表
"""
all_downloads = [] # 存储所有下载成功的文件名
# 遍历URL列表,enumerate用于同时获取索引和URL
for i, url in enumerate(urls, 1):
print(f"\n{'='*50}")
print(f"🌐 正在处理第 {i}/{len(urls)} 个页面: {url}")
print(f"{'='*50}")
# 爬取单个页面
downloads = self.crawl_page(url, max_images_per_page)
all_downloads.extend(downloads) # 将结果添加到总列表中
# 如果不是最后一个页面,添加页面间的延迟
if i < len(urls):
print("⏳ 页面间延迟中...")
time.sleep(1) # 页面间延迟,避免请求过于密集
# 输出最终统计信息
print(f"\n🎉 所有页面爬取完成!")
print(f"📈 总计下载 {len(all_downloads)} 张图片")
print(f"💾 图片保存在: {os.path.abspath(self.save_folder)}")
return all_downloads
@staticmethod
def is_image_url(url):
"""
静态方法:检查URL是否为图片链接
参数:
url: 要检查的URL
返回:
布尔值,True表示是图片URL
"""
# 定义常见的图片文件扩展名模式
image_patterns = [
r'\.jpg$', # 匹配以.jpg结尾
r'\.jpeg$', # 匹配以.jpeg结尾
r'\.png$', # 匹配以.png结尾
r'\.gif$', # 匹配以.gif结尾
r'\.bmp$', # 匹配以.bmp结尾
r'\.webp$', # 匹配以.webp结尾
r'\.jpg\?', # 匹配.jpg后带参数的情况
r'\.jpeg\?', # 匹配.jpeg后带参数的情况
r'\.png\?', # 匹配.png后带参数的情况
r'\.gif\?', # 匹配.gif后带参数的情况
r'\.bmp\?', # 匹配.bmp后带参数的情况
r'\.webp\?' # 匹配.webp后带参数的情况
]
# 检查URL是否匹配任何图片模式,re.I表示忽略大小写
return any(re.search(pattern, url, re.I) for pattern in image_patterns)
# 使用示例和演示
if __name__ == "__main__":
"""
主程序入口,演示如何使用ImageCrawler类
"""
# 创建爬虫实例,指定图片保存文件夹
crawler = ImageCrawler("my_downloaded_images")
# 定义要爬取的页面URL列表
# 注意:请将这些示例URL替换为实际要爬取的网站
urls_to_crawl = [
"https://example.com/page1", # 替换为实际URL
"https://example.com/page2", # 替换为实际URL
"https://example.com/page3" # 替换为实际URL
]
# 开始批量爬取
# 参数1: URL列表
# 参数2: 每个页面最多下载15张图片
downloaded_files = crawler.crawl_multiple_pages(urls_to_crawl, max_images_per_page=15)
# 打印下载结果摘要
if downloaded_files:
print(f"\n📋 下载文件列表:")
for file in downloaded_files:
print(f" 📄 {file}")
else:
print("\n⚠️ 没有成功下载任何图片")本期内容就到这里了,喜欢请点个赞谢谢
封面图自取:
