一、研究背景
RAG通过检索外部知识库增强大LLM的事实性,但**当知识库包含敏感数据时:**攻击者可通过提示攻击(prompt injection)或推理攻击提取个人信息;即便是正常用户提问,模型的回答也可能无意泄露数据库内容(如病人姓名、地址等)。
现有防御方法通常采用查询时差分隐私 ,对每次回答都注入噪声,但这样隐私预算会随着查询次数线性累积,导致响应质量下降。
二、本文贡献
论文提出新框架DP-SynRAG, 先生成一个差分隐私保护的合成文本数据库,再让RAG使用该数据库进行检索。合成文本生成只需一次DP处理,后续可无限次查询,不再消耗隐私预算。适用于多查询场景,解决了DP-RAG中隐私预算随查询次数增长的问题。
三、方法
3.1 阶段一:差分隐私聚类 Soft Clustering
1. 关键词提取:从每篇文档中提取K个关键词,构建关键词直方图,并加入高斯噪声以满足DP。
**2. 关键词聚类:**基于关键词将文档划分为多个主题簇
**3. 基于嵌入的相似度筛选:**对每个簇计算均值嵌入,用指数机制选出与主题最相似的文档集合。
3.2 阶段二:合成文本生成 Text Generation
**1. 私有预测:**对每个簇的文档用 LLM 进行"重述",并对输出logits进行裁剪与聚合;
**2. 生成差分隐私文本:**通过指数机制从加噪 logits 采样 token,生成 DP 保证的文本;
**3. 自过滤:**再由 LLM 判断生成的文本是否对下游任务(如问答、推荐)有用,剔除低质量文本。
eg:小型的**医疗问答系统,**知识库里有以下几条病人记录。
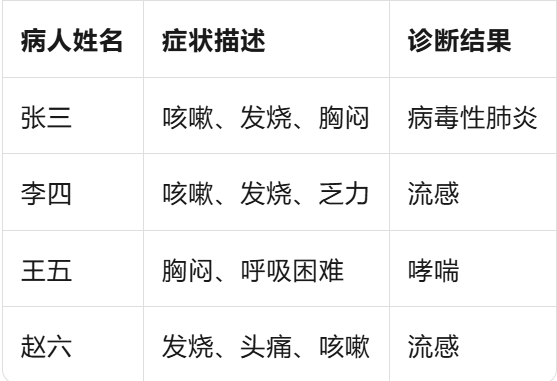
用户提问:"我最近咳嗽、发烧,可能得了什么病?"。
希望系统能回答:"你可能得了流感" 或 "你可能得了病毒性肺炎",但不能泄露任何病人姓名。
**step1:**关键词提取,比如"咳嗽"、"发烧"、"胸闷",构建关键词频率表
原始频率:
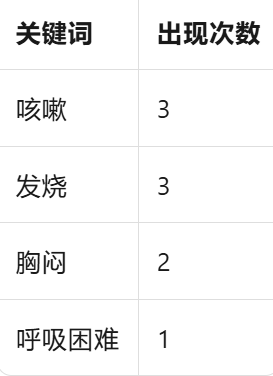
为了保护隐私,加入一些随机噪声(比如给"咳嗽"加上 -1,变成 2),得到"带噪声的直方图"
**step2:**选几个出现频率高的关键词作为"主题中心"
主题 A:"咳嗽 + 发烧";
主题 B:"胸闷";
然后把包含这些关键词的文档归到对应主题中,

**step3:**嵌入筛选(去异常),用文档的语义向量(embedding)进一步筛选,去掉和主题不太相关的文档。
**step4:**私有预测。对每个簇中的文档进行"改写"
原始文档比如:张三,症状:咳嗽、发烧、胸闷,诊断为病毒性肺炎。
改写后:某患者出现咳嗽、发烧、胸闷等症状,最终被诊断为病毒性肺炎。
确保改写过程满足差分隐私,也就是说,哪怕原始文档少一条记录,生成的文本也不会有太大变化。系统会对LLM的输出logits做"裁剪 + 加噪 + 聚合",然后用概率采样生成token
**step5:**自过滤
生成的合成文本中,删除 "某患者有点不舒服,医生给他开了点药。" ,这种文本太模糊,对RAG任务没用,质量差的文本:
最终得到一组隐私安全的合成文本:
某患者出现咳嗽、发烧、胸闷等症状,被诊断为病毒性肺炎。
一名病人因咳嗽和发烧就诊,最终确诊为流感。
有患者因胸闷和呼吸困难被诊断为哮喘。
现回答用户问题:
现在用户问:"我最近咳嗽、发烧,可能得了什么病?"
系统从合成知识库中检索到:
"某患者出现咳嗽、发烧、胸闷等症状,被诊断为病毒性肺炎。"
"一名病人因咳嗽和发烧就诊,最终确诊为流感。"
LLM生成回答:
"根据类似病例,您可能患有流感或病毒性肺炎,建议尽快就医。"
四、实验验证
4.1 数据集
3 个典型任务场景,覆盖医疗 Medical Synth、推荐系统 Movielens-1M、问答 SearchQA
4.2 生成模型
Phi-4-mini-3.8B、Gemma-2-2B、Llama-3.1-8B
4.3 对比方法
Non-RAG(ε=0,仅使用 LLM 自身知识,无外部数据库)
RAG(ε=∞,普通检索增强生成,无隐私保护)
DP-RAG(每查询 ε=10,查询时差分隐私,对每个查询注入噪声)
DP-Synth(一次性 ε=10,使用 DP 生成合成文本,但未针对 RAG 优化)
DP-SynRAG ( ε=10 本文提出的差分隐私合成文本生成框架)
4.4 实验结果
1. 三数据集 × 三模型的平均准确率(%) :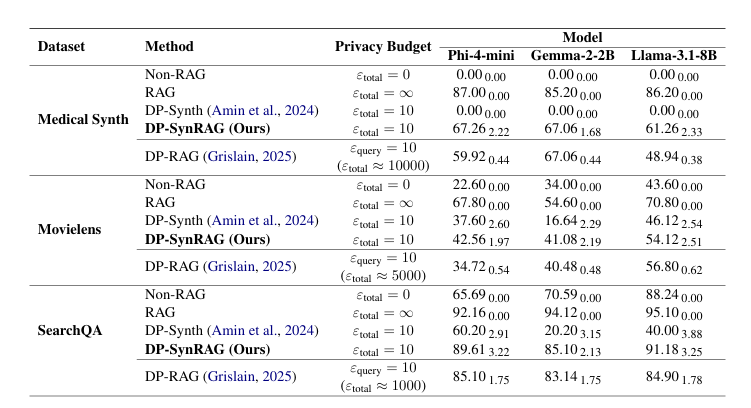
DP-SynRAG 的性能稳定接近非隐私 RAG;
在相同隐私预算下,DP-SynRAG > DP-RAG > DP-Synth;
DP-Synth 仅能保留平均语义,缺乏局部信息,因此几乎无法用于 RAG;
2. 展示了在 3 个数据集上,Llama-3.1 模型下的对比
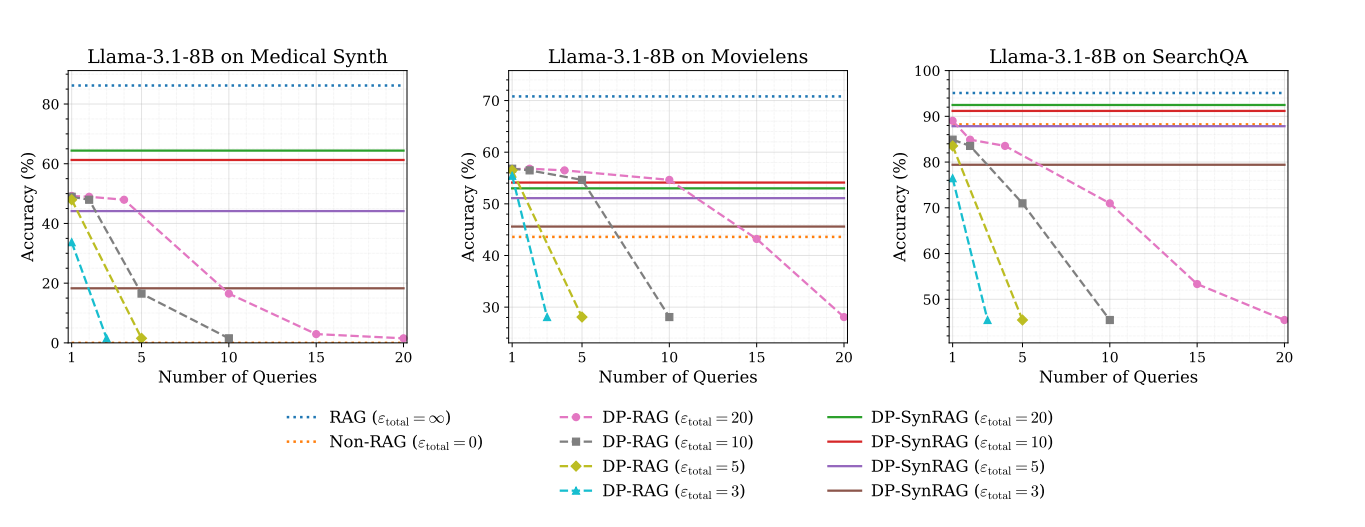
当查询次数达到 20 时:
DP-RAG 的准确率骤降至 0--40%;DP-SynRAG 始终保持稳定
DP-SynRAG 能实现 "可无限次查询的隐私保护 RAG"。
3.模型回答中泄露敏感信息(如病人姓名)的次数
在 Medical Synth 数据集上,设置两类测试:
1000 条正常查询(begin);100 条攻击性查询(attack)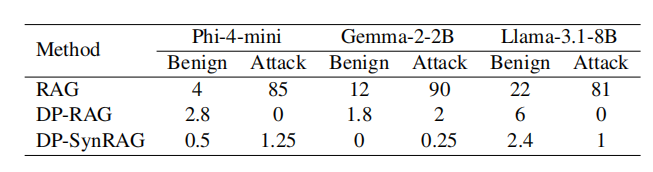
DP-SynRAG 几乎完全消除了敏感信息泄露风险。
4.消融实验
为了验证各组件(无 嵌入检索Embedding 检索,无 自过滤Self-filtering,改为Hard Clustering (L=1))的重要性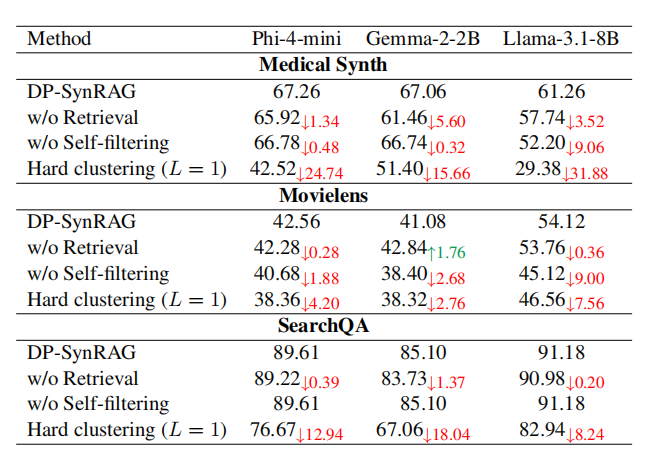
分析:
嵌入检索使聚类语义更精确,略微提升效果。
自过滤能有效去除低质量文本,显著提高任务表现;
硬聚类导致许多文档错误归类,生成文本质量急剧下降;
五、总结
本文提出 DP-SynRAG 框架 :首次实现"差分隐私的合成数据库"用于 RAG。生成的合成文本在保护隐私的同时保持高语义保真。实现了兼顾隐私保护、性能保持与可扩展性。