广度优先搜索
广度优先搜索就是基于 队列 去一层一层地遍历二叉树,最常见的方式就是层序遍历 ,使用的是迭代法 。假如每一层元素的值都用一个数组去存储,那么最终会是一个二维数组的形式。
为什么要基于队列去实现?
假如存在一个如下二叉树,当我们遍历到第二层时,需要先保存元素 4 与 7,再回过头遍历元素 4 底下的其他元素。也就是说我们需要用一个可以保存元素的容器 - 队列,借助它来保存每一层内我们遍历过的元素。
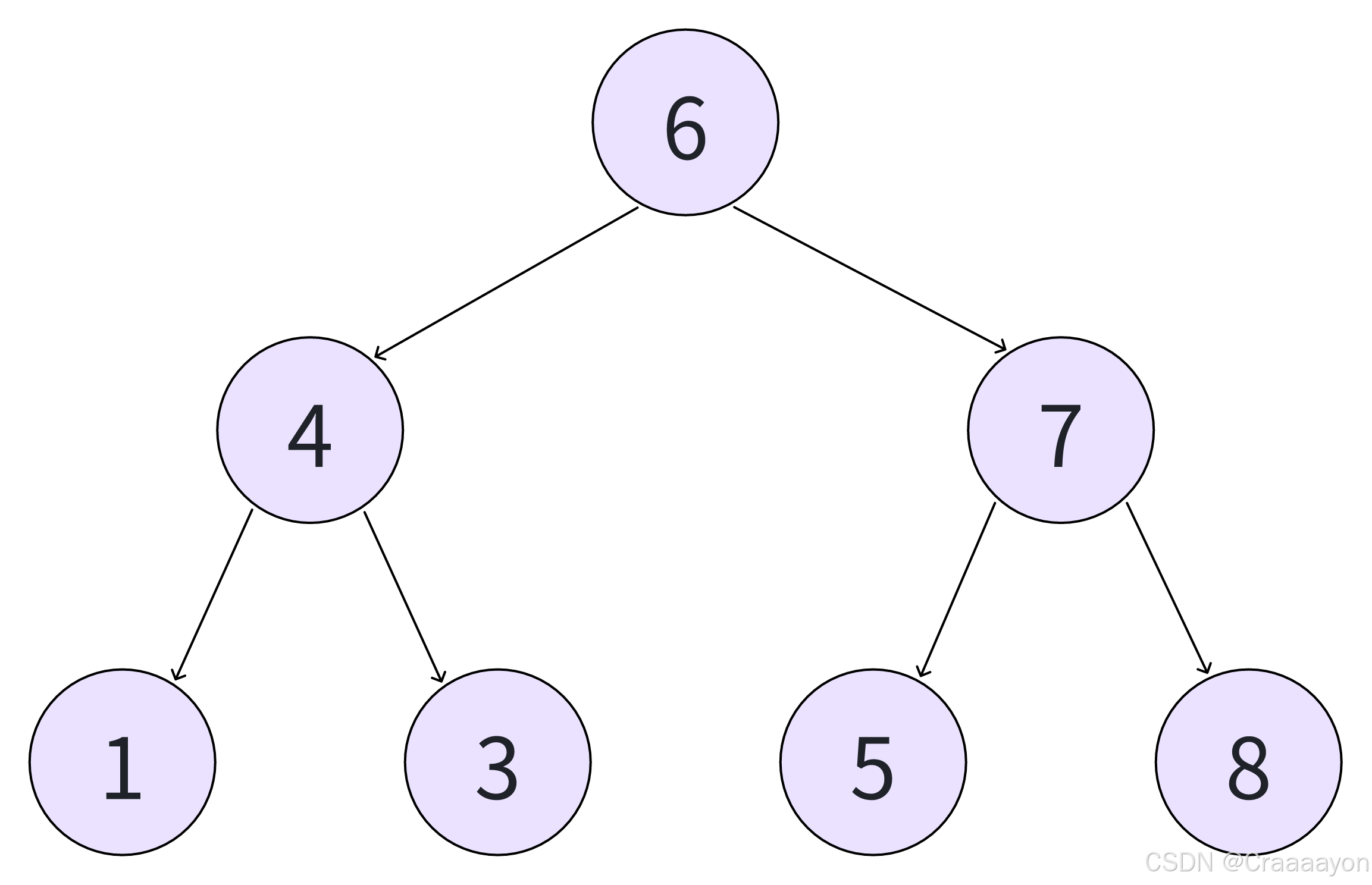
除了读取出元素并直接存入队列以外,还要维护一个 size 值,用于表示当前层的元素数量,借助 size 就可以准确从队列当中弹出对应数量的元素。接下来将以流程图形式展示层序遍历的流程:
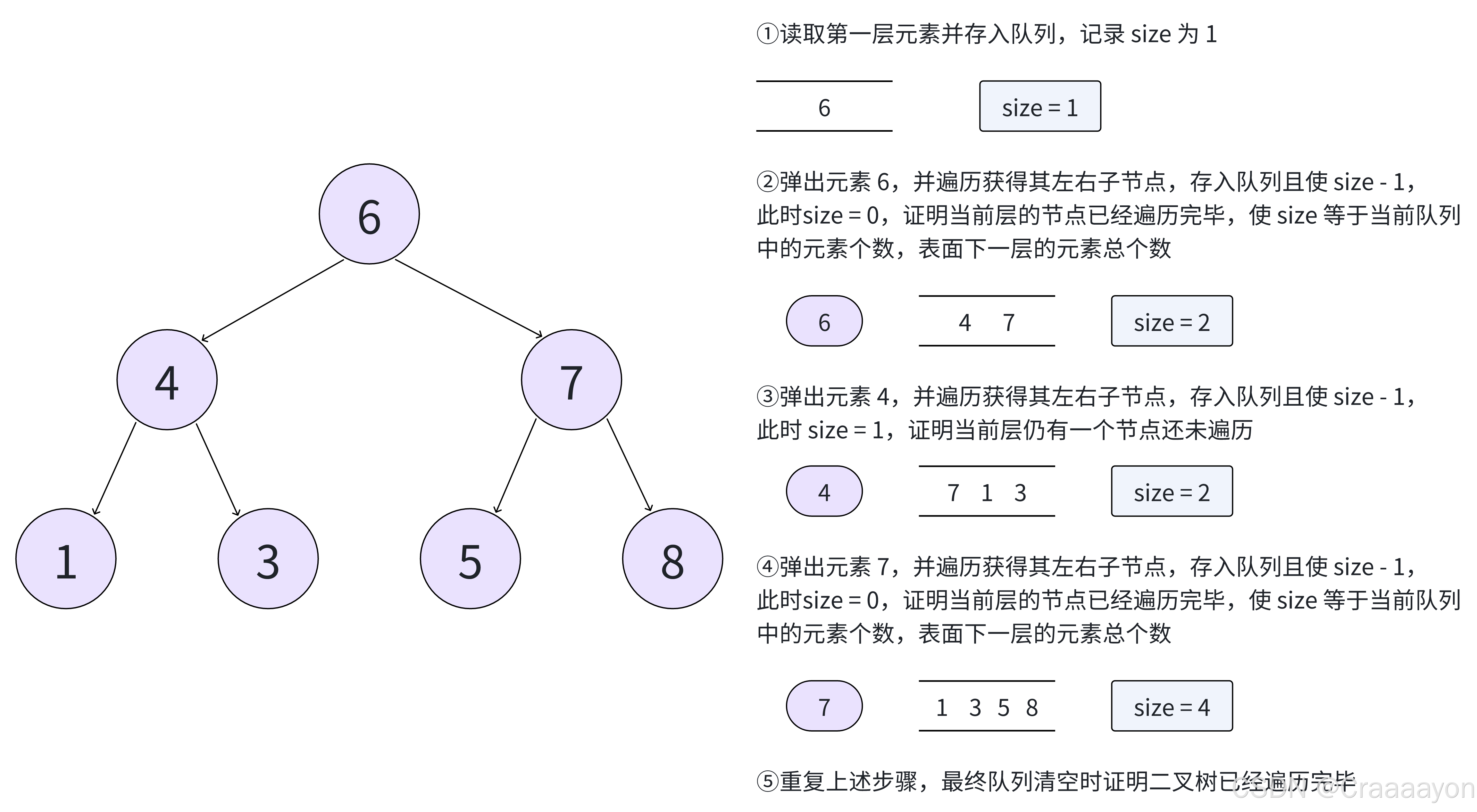
代码实现:
java
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> res = new ArrayList<>();
if(root == null) return res;
Queue<TreeNode> nodeQueue = new LinkedList<>();
nodeQueue.add(root);
while(!nodeQueue.isEmpty()) {
int size = nodeQueue.size();
List<Integer> nodeList = new ArrayList<>(size);
while(size > 0) {
TreeNode temp = nodeQueue.poll();
nodeList.add(temp.val);
if(temp.left != null) nodeQueue.add(temp.left);
if(temp.right != null) nodeQueue.add(temp.right);
size--;
}
res.add(nodeList);
}
return res;
}