1.2.1 梯度下降(原理 + 直觉 + 代码框架)
梯度下降(Gradient Descent)是机器学习中最基础的参数优化算法,核心思想是"沿着成本函数的梯度反方向迭代更新参数,逐步找到成本最小的参数组合"。它适用于几乎所有机器学习模型(线性回归、逻辑回归、神经网络等),尤其在成本函数为凸函数时,能稳定收敛到全局最优解。
1. 核心原理
假设我们要最小化的成本函数为J(θ)J(\theta)J(θ)(θ\thetaθ是待优化的参数向量,如线性回归中的θ=θ0,θ1,...,θnT\theta = \\theta_0, \\theta_1, ..., \\theta_n^Tθ=θ0,θ1,...,θnT),梯度下降的参数更新公式为:
θj=θj−α⋅∂J(θ)∂θj(对所有参数 j 同时更新)\theta_j = \theta_j - \alpha \cdot \frac{\partial J(\theta)}{\partial \theta_j} \quad (\text{对所有参数 } j \text{ 同时更新})θj=θj−α⋅∂θj∂J(θ)(对所有参数 j 同时更新)
其中:
- ∂J(θ)∂θj\frac{\partial J(\theta)}{\partial \theta_j}∂θj∂J(θ):成本函数J(θ)J(\theta)J(θ)对参数θj\theta_jθj的偏导数(即"梯度"),表示θj\theta_jθj变化时J(θ)J(\theta)J(θ)的变化率;
- α\alphaα:学习率(Learning Rate),控制每次参数更新的步长;
- "同时更新":所有参数的新值必须基于上一轮的旧值计算,不能用已更新的参数计算其他参数(避免迭代偏差)。
2. 直觉理解:"下山" analogy
梯度下降的过程可以类比为"盲人下山":
- 成本函数J(θ)J(\theta)J(θ)的图像是一座山,目标是找到山底(成本最小值);
- 盲人(当前参数θ\thetaθ)不知道山底在哪,但能感知脚下的"坡度"(梯度);
- 梯度的方向是"坡度最陡的上坡方向",因此反方向就是"最陡的下坡方向";
- 每次迈出一步(步长由α\alphaα决定),重复这一过程,最终到达山底。
单参数场景示例 :
对于线性回归的成本函数J(θ1)=12m∑(hθ(x)−y)2J(\theta_1) = \frac{1}{2m}\sum(h_\theta(x)-y)^2J(θ1)=2m1∑(hθ(x)−y)2(固定θ0=0\theta_0=0θ0=0),其图像是抛物线。梯度∂J∂θ1\frac{\partial J}{\partial \theta_1}∂θ1∂J的符号决定了更新方向:
- 当θ1\theta_1θ1在最优值左侧(θ1<θ1∗\theta_1 < \theta_1^*θ1<θ1∗),梯度为负,θj=θj−α⋅(负数)\theta_j = \theta_j - \alpha \cdot (\text{负数})θj=θj−α⋅(负数) → θj\theta_jθj增大(向右移动);
- 当θ1\theta_1θ1在最优值右侧(θ1>θ1∗\theta_1 > \theta_1^*θ1>θ1∗),梯度为正,θj=θj−α⋅(正数)\theta_j = \theta_j - \alpha \cdot (\text{正数})θj=θj−α⋅(正数) → θj\theta_jθj减小(向左移动);
- 最终收敛到θ1∗\theta_1^*θ1∗(梯度为0,不再更新)。
3. 梯度下降的三要素
- 初始化参数:通常从随机值或全零开始(线性回归中全零初始化是安全的,因为成本函数是凸函数);
- 计算梯度 :求成本函数对每个参数的偏导数(手动推导或自动求导工具如PyTorch的
autograd); - 迭代更新:按公式同时更新所有参数,直到梯度接近0(成本不再明显下降)。
4. 批量梯度下降(Batch Gradient Descent)
最基础的梯度下降变体,每次迭代使用全部样本计算梯度,适用于小规模数据集。
(1)线性回归中的梯度推导
对于线性回归的成本函数J(θ)=12m∑i=1m(hθ(x(i))−y(i))2J(\theta) = \frac{1}{2m}\sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})^2J(θ)=2m1∑i=1m(hθ(x(i))−y(i))2,其中hθ(x)=θTxh_\theta(x) = \theta^T xhθ(x)=θTx,偏导数为:
∂J(θ)∂θj=1m∑i=1m(hθ(x(i))−y(i))⋅xj(i)\frac{\partial J(\theta)}{\partial \theta_j} = \frac{1}{m}\sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)}) \cdot x_j^{(i)}∂θj∂J(θ)=m1i=1∑m(hθ(x(i))−y(i))⋅xj(i)
因此参数更新公式为:
θj=θj−α⋅1m∑i=1m(hθ(x(i))−y(i))⋅xj(i)\theta_j = \theta_j - \alpha \cdot \frac{1}{m}\sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)}) \cdot x_j^{(i)}θj=θj−α⋅m1i=1∑m(hθ(x(i))−y(i))⋅xj(i)
(2)PyTorch手动实现框架
python
import torch
import matplotlib.pyplot as plt
import matplotlib
# 只使用Windows系统默认自带的字体,避免找不到字体的警告
matplotlib.rcParams["font.family"] = ["SimHei", "Microsoft YaHei"] # 系统必装字体
# 1. 构造数据集(单特征房价预测:x=面积,y=价格)
x = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0], dtype=torch.float32).view(-1, 1) # 形状:(5,1)
y = torch.tensor([2.0, 4.0, 5.0, 4.5, 6.0], dtype=torch.float32).view(-1, 1) # 形状:(5,1)
m = x.shape[0] # 样本数
# 2. 初始化参数(添加偏置项x0=1)
x_bias = torch.cat([torch.ones(m, 1), x], dim=1) # 形状:(5,2),第一列全为1(对应θ0)
theta = torch.tensor([0.0, 0.0], dtype=torch.float32, requires_grad=True) # θ0和θ1,需要计算梯度
# 3. 定义超参数
alpha = 0.01 # 学习率
num_iterations = 1000 # 迭代次数
cost_history = [] # 记录成本变化
# 4. 批量梯度下降迭代
for i in range(num_iterations):
# 前向传播:计算预测值和成本
h = torch.matmul(x_bias, theta.view(-1, 1)) # 形状:(5,1),h = θ0*1 + θ1*x
cost = (1/(2*m)) * torch.sum(torch.square(h - y)) # 成本函数
cost_history.append(cost.item())
# 反向传播:计算梯度(自动求导)
cost.backward() # 计算d(cost)/d(theta)
# 参数更新(禁止梯度跟踪)
with torch.no_grad():
theta -= alpha * theta.grad # 按公式更新
# 清空梯度(避免累积)
theta.grad.zero_()
# 5. 输出结果
print(f"最优参数:θ0={theta[0].item():.4f}, θ1={theta[1].item():.4f}")
print(f"最终成本:{cost.item():.4f}")
# 6. 可视化成本下降曲线
plt.figure(figsize=(8, 5))
plt.plot(range(num_iterations), cost_history, color='#1f77b4')
plt.xlabel('迭代次数', fontsize=12)
plt.ylabel('成本 J(θ)', fontsize=12)
plt.title('批量梯度下降:成本随迭代变化', fontsize=14)
plt.grid(alpha=0.3)
plt.savefig('batch_gd_cost_curve.png', dpi=300)
plt.show()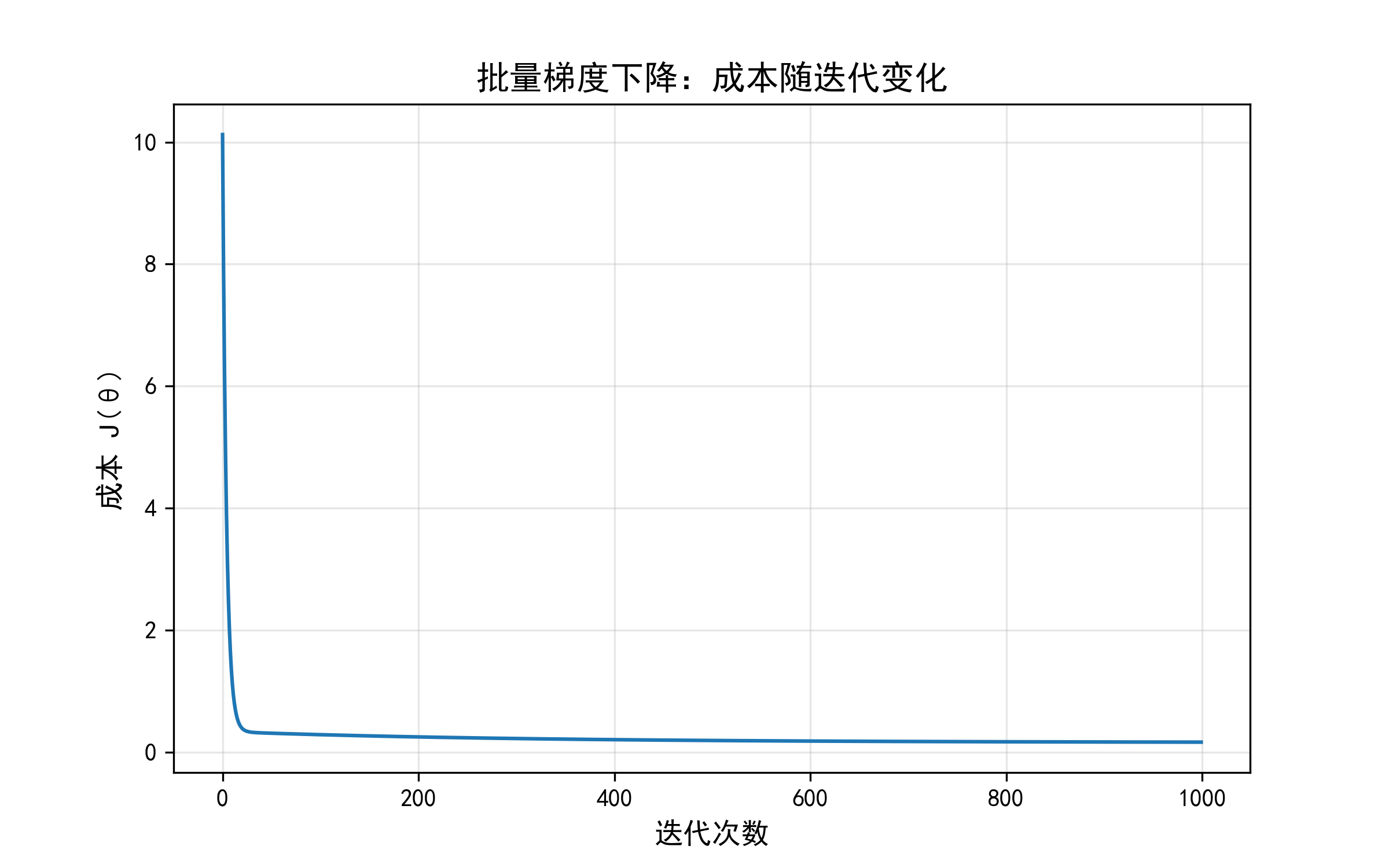
(3)关键代码解析
requires_grad=True:标记参数需要计算梯度;cost.backward():自动计算成本函数对所有参数的偏导数(存储在theta.grad中);with torch.no_grad():更新参数时暂时关闭梯度跟踪(避免计算图冗余);theta.grad.zero_():每次迭代后清空梯度(PyTorch会累积梯度,必须手动清零)。
5. 梯度下降的三种变体
除了批量梯度下降,还有两种常用变体,适用于不同场景:
| 变体 | 每次迭代使用的样本数 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 批量梯度下降 | 全部样本(m) | 梯度准确,收敛稳定 | 计算慢(尤其m大时),内存消耗大 | 小规模数据集 |
| 随机梯度下降(SGD) | 单个样本(1) | 计算快,适合在线学习 | 梯度噪声大,收敛路径曲折 | 大规模数据集 |
| 小批量梯度下降 | 小批量样本(b,如32) | 平衡速度与稳定性,利用GPU并行计算 | 需要调参(批量大小b) | 绝大多数场景(推荐) |
1.2.2 学习率(选择方法 + 影响分析)
学习率(α\alphaα)是梯度下降中最重要的超参数,直接决定了参数更新的步长。选择不当会导致收敛缓慢、不收敛或跳过最优解。
1. 学习率对收敛的影响
-
学习率过小(α\alphaα太小) :
每次更新步长太小,需要极多次迭代才能收敛(效率低)。
例:α=0.0001\alpha=0.0001α=0.0001时,可能需要10万次迭代才能达到α=0.01\alpha=0.01α=0.01时1000次迭代的效果。
-
学习率过大(α\alphaα太大) :
步长过大,可能导致参数在最优值附近震荡,甚至发散(成本越来越大)。
例:α=1.0\alpha=1.0α=1.0时,线性回归可能出现参数更新后成本反而增大的情况。
-
合适的学习率 :
成本函数值快速下降,逐渐趋于稳定(收敛)。
2. 学习率影响的可视化(PyTorch代码)
python
import torch
import matplotlib.pyplot as plt
import matplotlib
# 只使用Windows系统默认自带的字体,避免找不到字体的警告
matplotlib.rcParams["font.family"] = ["SimHei", "Microsoft YaHei"] # 系统必装字体
# 1. 数据集(同前:单特征房价)
x = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0], dtype=torch.float32).view(-1, 1)
y = torch.tensor([2.0, 4.0, 5.0, 4.5, 6.0], dtype=torch.float32).view(-1, 1)
m = x.shape[0]
x_bias = torch.cat([torch.ones(m, 1), x], dim=1)
# 2. 定义梯度下降函数(返回成本历史)
def gradient_descent(alpha, iterations=100):
theta = torch.tensor([0.0, 0.0], dtype=torch.float32, requires_grad=True)
cost_history = []
for _ in range(iterations):
h = torch.matmul(x_bias, theta.view(-1, 1))
cost = (1/(2*m)) * torch.sum(torch.square(h - y))
cost_history.append(cost.item())
cost.backward()
with torch.no_grad():
theta -= alpha * theta.grad
theta.grad.zero_()
return cost_history
# 3. 测试不同学习率
alphas = [0.001, 0.01, 0.1, 0.5] # 过小、合适、较大、过大
cost_histories = [gradient_descent(alpha) for alpha in alphas]
# 4. 可视化对比
plt.figure(figsize=(10, 6))
for i, alpha in enumerate(alphas):
plt.plot(range(100), cost_histories[i], label=f'α={alpha}')
plt.xlabel('迭代次数', fontsize=12)
plt.ylabel('成本 J(θ)', fontsize=12)
plt.title('不同学习率对收敛的影响', fontsize=14)
plt.legend()
plt.grid(alpha=0.3)
plt.ylim(0, 2) # 聚焦成本下降区域
plt.savefig('learning_rate_impact.png', dpi=300)
plt.show()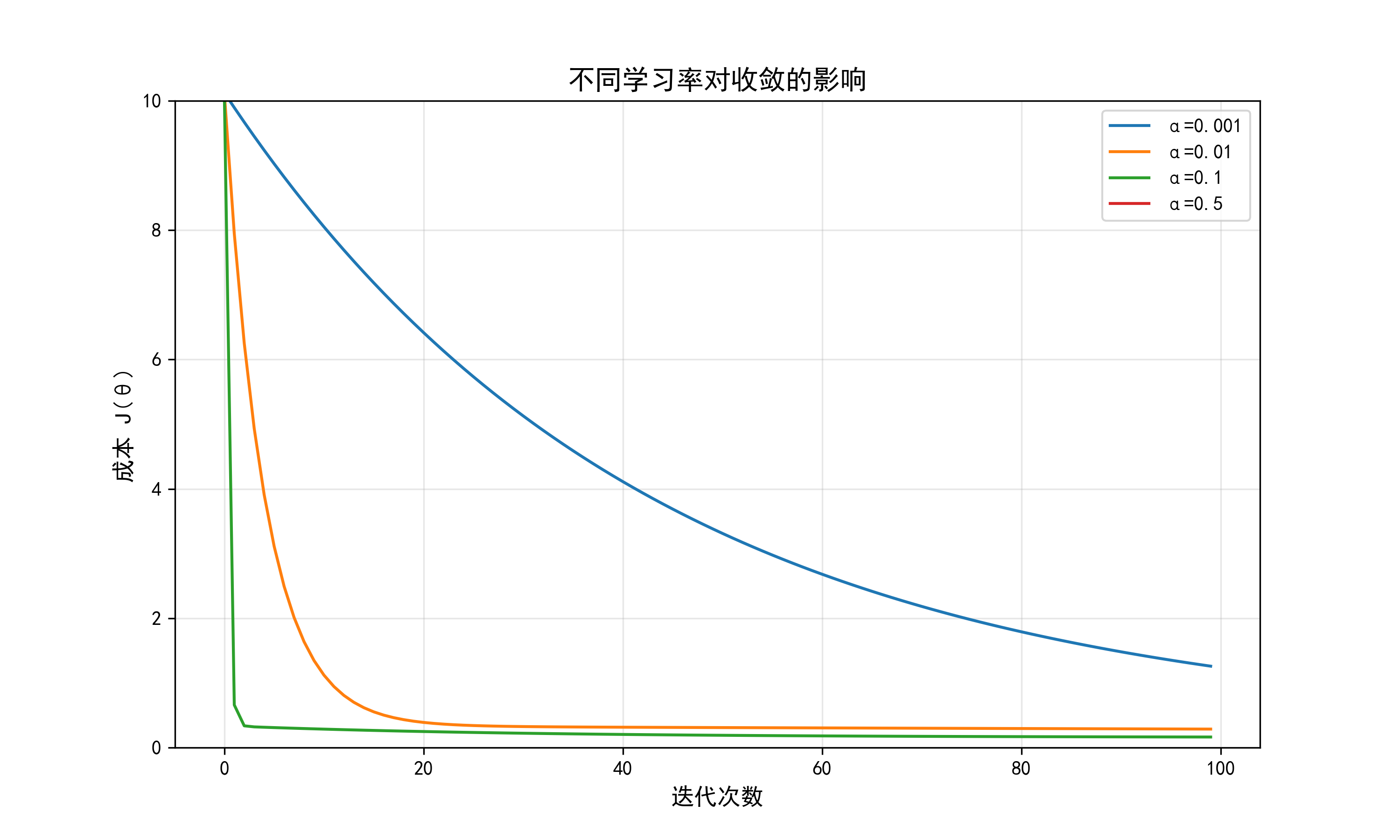
结果解读:
- α=0.001\alpha=0.001α=0.001:成本下降极慢,100次迭代后仍未收敛;
- α=0.01\alpha=0.01α=0.01:成本快速下降并趋于稳定(最佳选择);
- α=0.1\alpha=0.1α=0.1:前期下降快,但后期震荡(接近收敛但不稳定);
- α=0.5\alpha=0.5α=0.5:成本波动上升(发散,完全不收敛)。
3. 学习率的选择方法
没有通用的"最佳学习率",需根据具体问题调试,推荐流程:
-
初步筛选 :
从α=0.001,0.01,0.1,1.0\alpha=0.001, 0.01, 0.1, 1.0α=0.001,0.01,0.1,1.0等数量级开始测试,观察成本曲线:
- 若成本不下降,减小学习率;
- 若成本震荡,减小学习率;
- 若成本下降慢,增大学习率。
-
精细调整 :
在初步筛选的有效区间内(如0.005∼0.050.005 \sim 0.050.005∼0.05),进一步测试中间值(如0.02,0.030.02, 0.030.02,0.03)。
-
自适应学习率 :
复杂场景可使用"学习率衰减"(随迭代次数减小α\alphaα)或自适应算法(如Adam,自动调整学习率)。
4. 梯度下降的收敛判断
迭代何时停止?通常通过以下指标判断:
- 当成本函数的变化量小于某个阈值(如∣J(θ(t+1))−J(θ(t))∣<10−6|J(\theta^{(t+1)}) - J(\theta^{(t)})| < 10^{-6}∣J(θ(t+1))−J(θ(t))∣<10−6);
- 固定最大迭代次数(如1000次),适用于成本下降缓慢但已接近最优的场景。
1.2.3 线性回归的梯度下降(运行流程)
结合线性回归模型,完整梳理梯度下降的运行流程,以"单特征房价预测"为例,从数据准备到参数收敛,一步一步展示优化过程。
1. 完整流程拆解
步骤1:数据准备与预处理
- 输入特征xxx:房屋面积(如1,2,3,4,51, 2, 3, 4, 51,2,3,4,5);
- 输出标签yyy:对应房价(如2,4,5,4.5,62, 4, 5, 4.5, 62,4,5,4.5,6);
- 特征扩展:添加偏置项x0=1x_0=1x0=1,使x=x0,x1=1,面积x = x_0, x_1 = 1, 面积x=x0,x1=1,面积(适配θ0\theta_0θ0)。
步骤2:初始化参数与超参数
- 参数θ=θ0,θ1T\theta = \\theta_0, \\theta_1^Tθ=θ0,θ1T:初始化为0,00, 00,0;
- 学习率α\alphaα:选择0.010.010.01(经测试有效);
- 迭代次数:1000次(确保收敛)。
步骤3:迭代优化(核心步骤)
单次迭代流程:
- 前向计算:h=θ0⋅x0+θ1⋅x1h = \theta_0 \cdot x_0 + \theta_1 \cdot x_1h=θ0⋅x0+θ1⋅x1(预测房价);
- 计算成本:J(θ)=12m∑(h−y)2J(\theta) = \frac{1}{2m}\sum(h - y)^2J(θ)=2m1∑(h−y)2(衡量预测误差);
- 反向求导:∂J∂θ0=1m∑(h−y)\frac{\partial J}{\partial \theta_0} = \frac{1}{m}\sum(h - y)∂θ0∂J=m1∑(h−y),∂J∂θ1=1m∑(h−y)⋅x1\frac{\partial J}{\partial \theta_1} = \frac{1}{m}\sum(h - y) \cdot x_1∂θ1∂J=m1∑(h−y)⋅x1;
- 更新参数:θ0=θ0−α⋅∂J∂θ0\theta_0 = \theta_0 - \alpha \cdot \frac{\partial J}{\partial \theta_0}θ0=θ0−α⋅∂θ0∂J,θ1=θ1−α⋅∂J∂θ1\theta_1 = \theta_1 - \alpha \cdot \frac{\partial J}{\partial \theta_1}θ1=θ1−α⋅∂θ1∂J;
- 清空梯度,重复上述步骤。
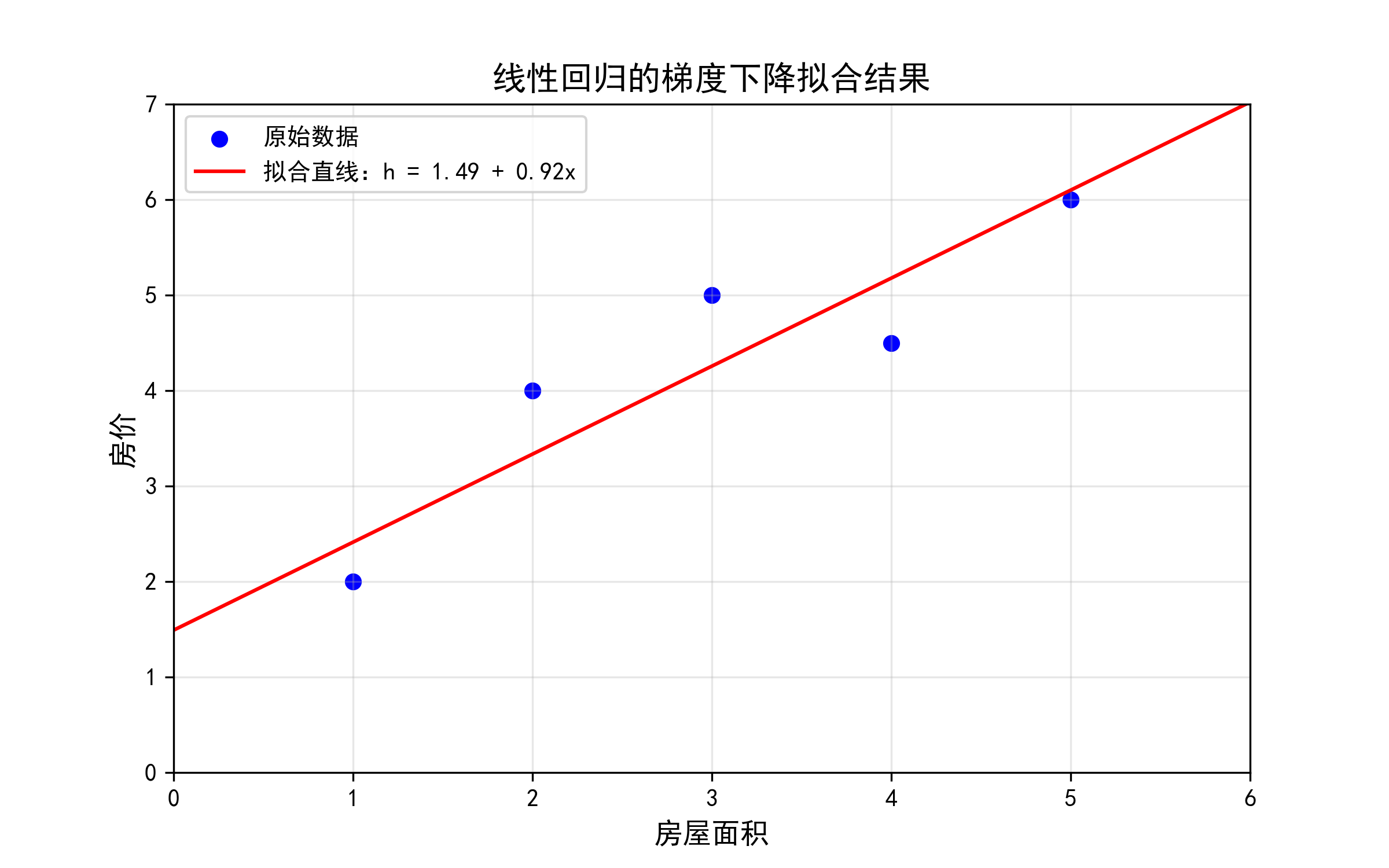
步骤4:收敛验证与结果可视化
- 成本曲线:随迭代次数增加,成本逐渐下降并趋于稳定;
- 拟合曲线:将最优参数代入h=θ0+θ1xh = \theta_0 + \theta_1 xh=θ0+θ1x,绘制拟合直线与原始数据对比。
2. 拟合效果可视化(PyTorch代码)
python
import torch
import matplotlib.pyplot as plt
import matplotlib
# 字体配置
matplotlib.rcParams["font.family"] = ["SimHei", "Microsoft YaHei"]
# 1. 准备数据
x = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0], dtype=torch.float32).view(-1, 1)
y = torch.tensor([2.0, 4.0, 5.0, 4.5, 6.0], dtype=torch.float32).view(-1, 1)
m = x.shape[0] # 样本数量
# 2. 添加偏置项并计算最优参数(通过梯度下降)
x_bias = torch.cat([torch.ones(m, 1), x], dim=1) # 添加偏置项x0=1
theta = torch.tensor([0.0, 0.0], dtype=torch.float32, requires_grad=True) # 初始化参数
# 梯度下降参数
alpha = 0.01 # 学习率
num_iterations = 1000 # 迭代次数
# 执行梯度下降计算最优参数
for _ in range(num_iterations):
h = torch.matmul(x_bias, theta.view(-1, 1)) # 预测值
cost = (1 / (2 * m)) * torch.sum(torch.square(h - y)) # 成本函数
cost.backward() # 反向传播计算梯度
with torch.no_grad():
theta -= alpha * theta.grad # 更新参数
theta.grad.zero_() # 清空梯度
# 3. 提取最优参数
theta0_opt = theta[0].item() # 偏置项
theta1_opt = theta[1].item() # 特征系数
# 4. 绘制原始数据与拟合直线
plt.figure(figsize=(8, 5))
plt.scatter(x.numpy(), y.numpy(), color='blue', label='原始数据')
# 生成拟合直线的x范围(0到6,更完整展示)
x_range = torch.linspace(0, 6, 100)
h_range = theta0_opt + theta1_opt * x_range # 拟合直线公式
plt.plot(x_range.numpy(), h_range.numpy(), color='red',
label=f'拟合直线:h = {theta0_opt:.2f} + {theta1_opt:.2f}x')
# 图表配置
plt.xlabel('房屋面积', fontsize=12)
plt.ylabel('房价', fontsize=12)
plt.title('线性回归的梯度下降拟合结果', fontsize=14)
plt.legend()
plt.grid(alpha=0.3)
plt.xlim(0, 6)
plt.ylim(0, 7)
plt.savefig('linear_regression_fit.png', dpi=300)
plt.show()
1.2.4 多重线性回归的梯度下降
当输入特征不止1个时(如房价预测还考虑"房间数""楼层"等),称为多重线性回归 。此时参数更新逻辑与单特征类似,但需处理高维特征,通常通过向量化提高计算效率。
1. 模型与梯度公式
(1)假设函数(向量化形式)
设输入特征为nnn维(含偏置项x0=1x_0=1x0=1),则:
hθ(X)=X⋅θh_\theta(X) = X \cdot \thetahθ(X)=X⋅θ
其中:
- XXX:特征矩阵,形状为(m,n+1)(m, n+1)(m,n+1)(mmm个样本,n+1n+1n+1个特征);
- θ\thetaθ:参数向量,形状为(n+1,1)(n+1, 1)(n+1,1);
- hθ(X)h_\theta(X)hθ(X):预测向量,形状为(m,1)(m, 1)(m,1)。
(2)成本函数(向量化形式)
J(θ)=12m(Xθ−y)T(Xθ−y)J(\theta) = \frac{1}{2m} (X\theta - y)^T (X\theta - y)J(θ)=2m1(Xθ−y)T(Xθ−y)
其中yyy是真实标签向量(形状(m,1)(m, 1)(m,1))。
(3)梯度与更新公式(向量化形式)
∂J(θ)∂θ=1mXT(Xθ−y)\frac{\partial J(\theta)}{\partial \theta} = \frac{1}{m} X^T (X\theta - y)∂θ∂J(θ)=m1XT(Xθ−y)
θ=θ−α⋅1mXT(Xθ−y)\theta = \theta - \alpha \cdot \frac{1}{m} X^T (X\theta - y)θ=θ−α⋅m1XT(Xθ−y)
向量化的优势:避免循环,利用PyTorch的矩阵运算加速计算(尤其GPU环境下)。
2. 多特征梯度下降的PyTorch实现
以"双特征房价预测"为例(特征:面积x1x_1x1、房间数x2x_2x2):
python
import torch
import matplotlib.pyplot as plt
# 1. 双特征数据集(m=5样本:[面积, 房间数] → 房价)
X = torch.tensor([
[1.0, 2.0], # 样本1:面积1,房间数2
[2.0, 3.0], # 样本2:面积2,房间数3
[3.0, 2.0], # 样本3:面积3,房间数2
[4.0, 4.0], # 样本4:面积4,房间数4
[5.0, 3.0] # 样本5:面积5,房间数3
], dtype=torch.float32)
y = torch.tensor([[2.0], [4.0], [5.0], [7.0], [6.0]], dtype=torch.float32) # 房价
m, n = X.shape # m=5, n=2(特征数)
# 2. 添加偏置项x0=1(特征矩阵变为(m, n+1))
X_bias = torch.cat([torch.ones(m, 1), X], dim=1) # 形状:(5, 3)
# 3. 初始化参数与超参数
theta = torch.tensor([0.0, 0.0, 0.0], dtype=torch.float32, requires_grad=True) # θ0,θ1,θ2
alpha = 0.01
num_iterations = 2000
cost_history = []
# 4. 多特征梯度下降(向量化计算)
for _ in range(num_iterations):
h = torch.matmul(X_bias, theta.view(-1, 1)) # 向量化预测:(5,3) × (3,1) → (5,1)
cost = (1/(2*m)) * torch.matmul((h - y).T, (h - y)) # 向量化成本计算
cost_history.append(cost.item())
cost.backward() # 自动计算梯度(无需手动推导多特征偏导数)
with torch.no_grad():
theta -= alpha * theta.grad # 同时更新所有参数
theta.grad.zero_()
# 5. 输出结果
print(f"最优参数:θ0={theta[0].item():.4f}, θ1={theta[1].item():.4f}, θ2={theta[2].item():.4f}")
print(f"最终成本:{cost.item():.4f}")
# 6. 可视化成本下降
plt.figure(figsize=(8, 5))
plt.plot(range(num_iterations), cost_history, color='#1f77b4')
plt.xlabel('迭代次数', fontsize=12)
plt.ylabel('成本 J(θ)', fontsize=12)
plt.title('多重线性回归的梯度下降成本曲线', fontsize=14)
plt.grid(alpha=0.3)
plt.savefig('multi_linear_gd_cost.png', dpi=300)
plt.show()关键说明:
- 多特征场景下,特征缩放(如标准化)至关重要,否则不同特征的量纲差异会导致梯度更新不平衡;
- 向量化计算(
torch.matmul)比循环效率高10~100倍,尤其特征数nnn较大时。
1.2.5 高级优化算法(框架适配)
批量梯度下降虽然原理简单,但收敛速度慢,实际工程中更常用高级优化算法 ,它们通过自适应调整学习率或利用历史梯度信息,加速收敛。PyTorch的torch.optim模块内置了多种高效优化器,可直接调用。
1. 常用高级优化算法对比
| 算法 | 核心思想 | 优点 | 适用场景 |
|---|---|---|---|
| 动量法(Momentum) | 模拟物理"动量",积累历史梯度方向,加速收敛并抑制震荡 | 收敛快,减少震荡 | 大多数场景,尤其非凸函数 |
| RMSprop | 自适应调整学习率:对频繁更新的参数用小学习率,稀疏参数用大学习率 | 适合处理稀疏数据 | NLP、推荐系统等稀疏特征场景 |
| Adam | 结合动量法和RMSprop的优点,同时跟踪梯度的一阶矩(均值)和二阶矩(方差) | 收敛快、稳定,几乎无需调参 | 绝大多数场景(推荐首选) |
2. PyTorch中高级优化器的使用
以"线性回归"为例,对比不同优化器的收敛速度:
python
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import matplotlib
# 字体配置
matplotlib.rcParams["font.family"] = ["SimHei", "Microsoft YaHei"]
# 1. 数据集(单特征房价)
x = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0], dtype=torch.float32).view(-1, 1)
y = torch.tensor([2.0, 4.0, 5.0, 4.5, 6.0], dtype=torch.float32).view(-1, 1)
# 2. 定义线性回归模型(添加reset_parameters方法)
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1) # 输入1维,输出1维(自动包含偏置项)
# 添加重置参数的方法,调用内部linear层的reset_parameters
def reset_parameters(self):
self.linear.reset_parameters()
def forward(self, x):
return self.linear(x)
# 3. 初始化模型、损失函数和优化器
model = LinearRegression()
criterion = nn.MSELoss() # 均方误差损失
# 定义不同优化器(学习率统一为0.01)
optimizers = {
'SGD': torch.optim.SGD(model.parameters(), lr=0.01),
'Momentum': torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9), # 动量法
'RMSprop': torch.optim.RMSprop(model.parameters(), lr=0.01),
'Adam': torch.optim.Adam(model.parameters(), lr=0.01)
}
# 4. 训练不同优化器并记录成本
num_epochs = 200
cost_histories = {name: [] for name in optimizers}
for name, optimizer in optimizers.items():
model.reset_parameters() # 重置模型参数(现在可以正常调用)
for epoch in range(num_epochs):
# 前向传播
outputs = model(x)
loss = criterion(outputs, y)
cost_histories[name].append(loss.item())
# 反向传播与优化
optimizer.zero_grad() # 清空梯度
loss.backward() # 计算梯度
optimizer.step() # 更新参数
# 5. 可视化不同优化器的收敛速度
plt.figure(figsize=(10, 6))
for name, history in cost_histories.items():
plt.plot(range(num_epochs), history, label=name)
plt.xlabel('迭代次数', fontsize=12)
plt.ylabel('损失(MSE)', fontsize=12)
plt.title('不同优化器的收敛速度对比', fontsize=14)
plt.legend()
plt.grid(alpha=0.3)
plt.savefig('optimizer_comparison.png', dpi=300)
plt.show()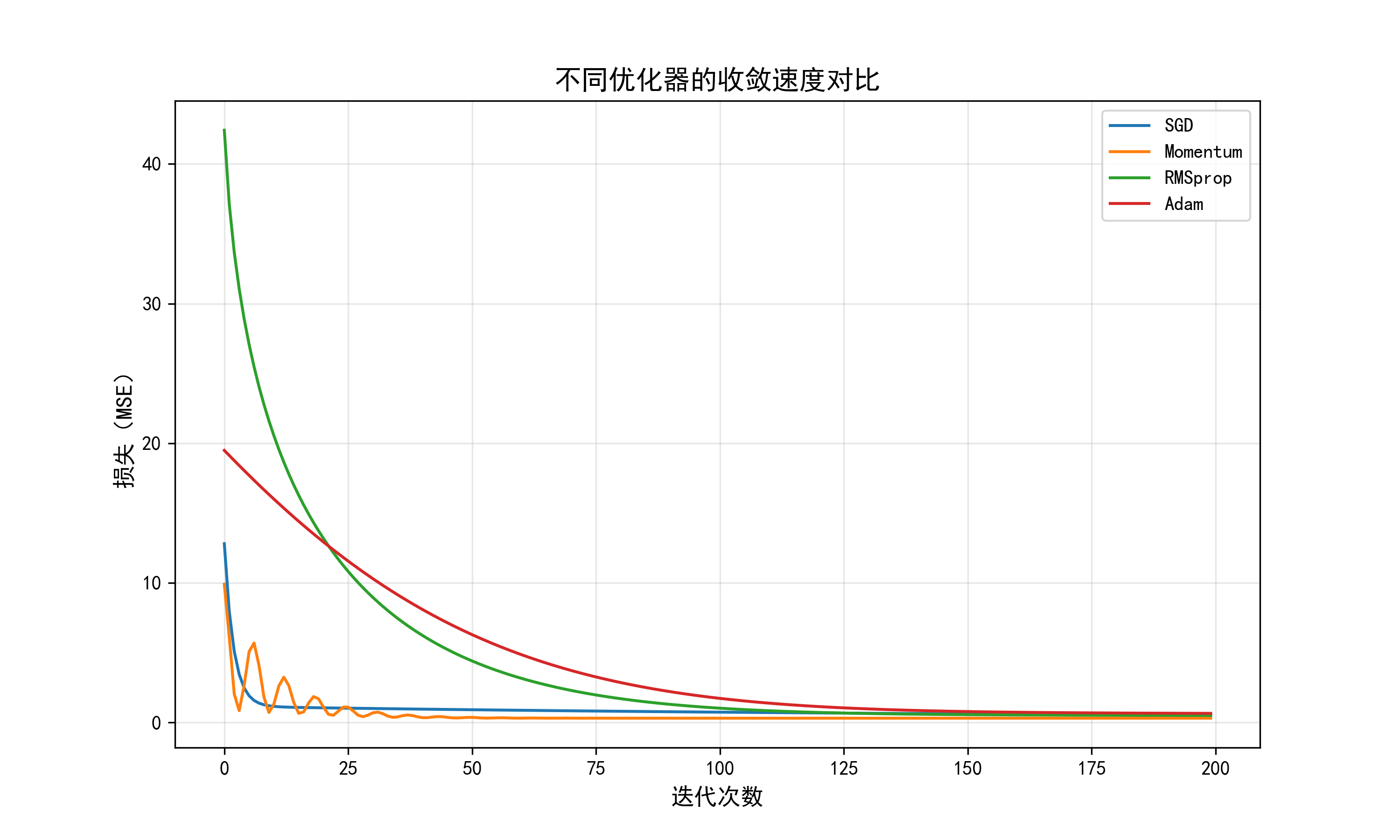
3. 工程实践建议
- 优先使用Adam:对大多数任务表现最优,调参成本低;
- 如需精细优化,可尝试RMSprop (适合稀疏数据)或动量法(适合计算机视觉任务);
- 避免手动实现优化器:PyTorch的
torch.optim经过高度优化,效率远高于手动实现; - 学习率仍需调试:高级优化器虽减少了对学习率的敏感度,但仍需根据任务调整(通常默认
lr=0.001或0.01)。
小结
- 梯度下降核心:沿成本函数梯度反方向更新参数,三要素为初始化、梯度计算、迭代更新;
- 学习率选择 :过小收敛慢,过大不收敛,需通过成本曲线调试,推荐从0.010.010.01开始测试;
- 多特征适配:通过向量化计算处理高维特征,利用矩阵运算提升效率;
- 高级优化器:Adam、RMSprop等收敛更快,实际应用中优先使用PyTorch内置优化器,避免重复造轮子。