博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
- 技术栈:Python语言、深度学习(神经网络)、CNN算法(mini_XCEPTION框架)、TensorFlow、PyQt5(GUI界面)、FER数据集、Adaboost算法、Fisher线性判别法(改进PCA)
- 核心功能:人脸表情识别(支持7类表情分类:生气、厌恶、恐惧、快乐、伤心、惊讶、中性),含图片识别、视频检测、摄像头实时识别
- 研究背景:当前人脸表情识别在人机交互(如智能客服)、情感计算(如心理评估)、安防监控等场景需求迫切,但传统识别方法存在显著痛点------复杂环境下(如光线变化、姿态偏移)人脸定位精度低,高维图像数据导致识别耗时久,且对相似表情(如惊讶与恐惧)区分度不足,难以满足实时、高精度的应用需求,亟需基于深度学习的优化方案解决。
- 研究意义:技术层面,通过Adaboost+人眼定位实现精准人脸裁剪,mini_XCEPTION框架提升表情特征提取能力,Fisher改进PCA解决维度灾难,构建"定位-预处理-识别"高效技术链;用户层面,提供PyQt5可视化界面,支持多模态识别(图片/视频/摄像头),降低操作门槛;行业层面,推动情感计算技术落地,为智能交互、心理监测等领域提供核心识别模块,具备实际应用与学术价值。
2、项目界面
-
图片识别检测1
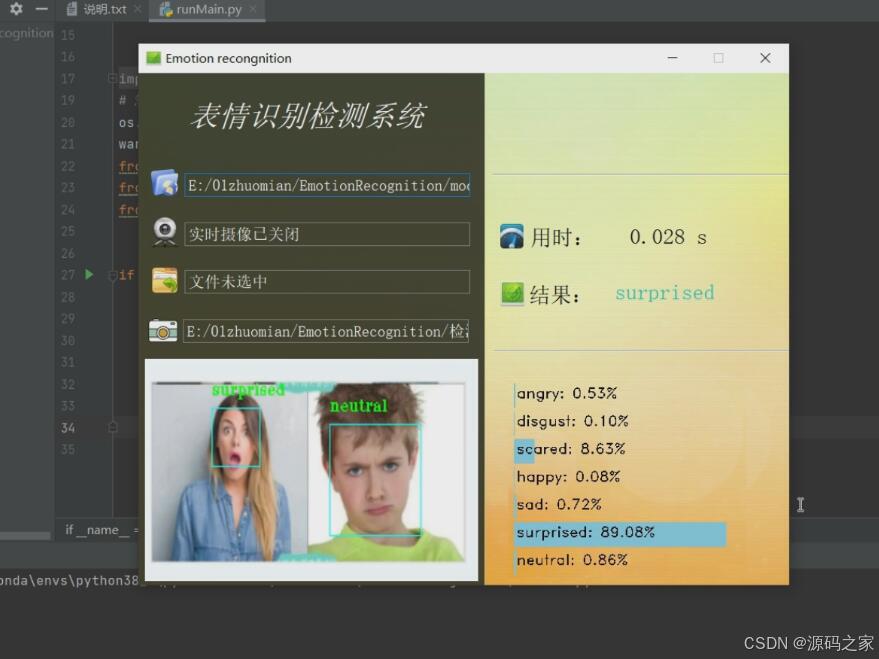
-
图片识别检测2
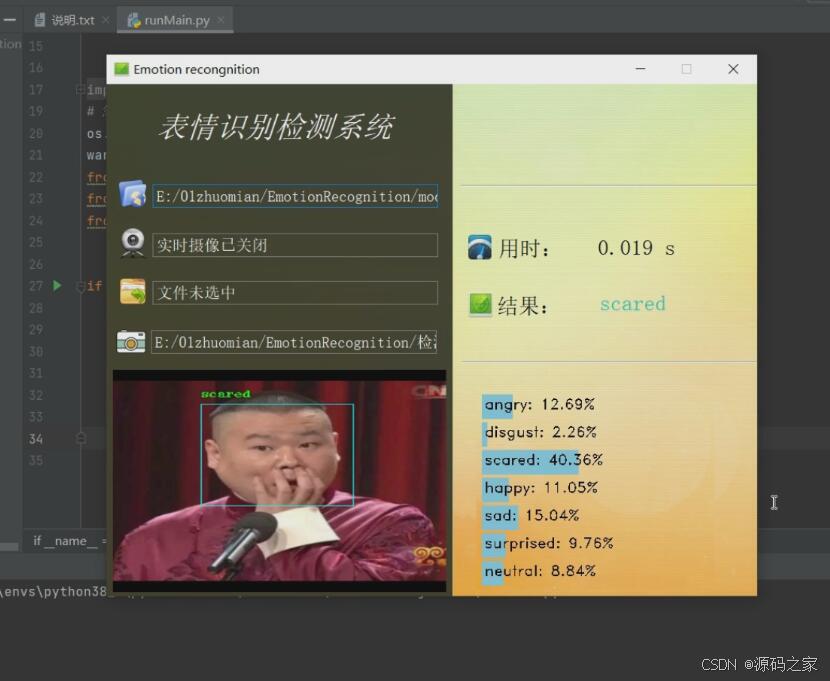
-
视频检测
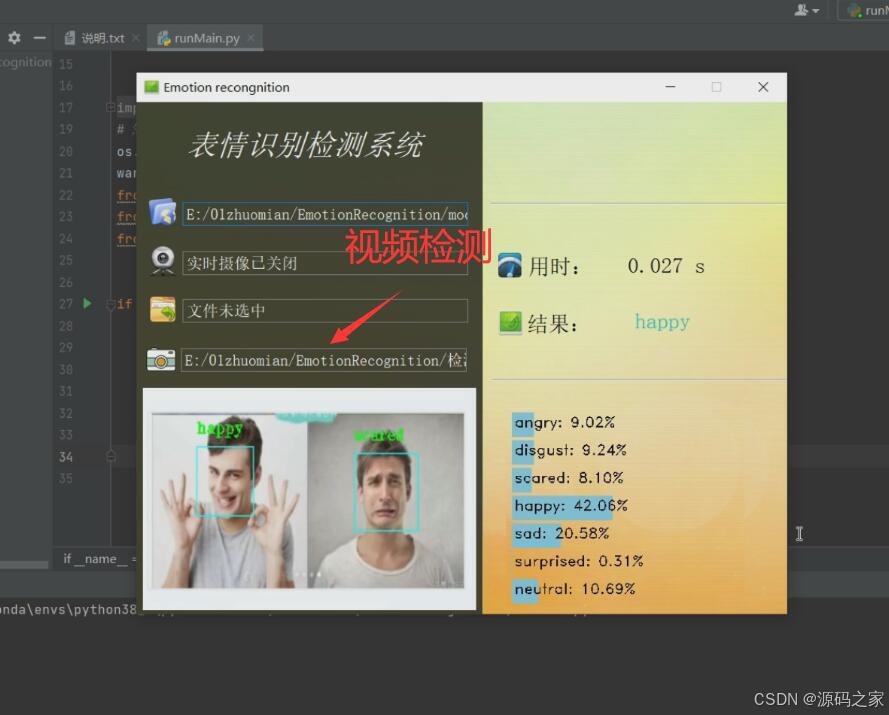
-
摄像头检测识别
3、项目说明
本项目是基于Python开发的高精度人脸表情识别系统,整合深度学习CNN算法(mini_XCEPTION框架)、多步图像预处理技术与PyQt5可视化界面,核心实现"人脸精准定位-图像优化-7类表情识别-多模态检测"的完整流程,依托FER数据集训练验证,旨在解决传统表情识别精度低、实时性差的问题。
(1)核心技术模块详解
① 图像预处理模块(精准人脸提取)
为提升后续识别精度,需先对输入图像进行多步优化处理,解决"人脸定位不准、图像规格不统一"问题:
- 粗略裁剪(Adaboost算法):通过Adaboost级联分类器快速扫描图像,定位人脸大致区域,剔除背景干扰,初步缩小识别范围;
- 精确裁剪(人眼定位):结合梯度积分投影法(捕捉眼部灰度变化特征)与双阈值二值化(分割眼部与周围区域),精准定位人眼位置,以此为基准调整人脸裁剪框,确保裁剪后的人脸姿态统一(如双眼水平对齐);
- 归一化处理 :
- 尺度归一化:基于双线性插值算法,将裁剪后的人脸图像统一缩放至固定尺寸(如48×48像素,适配mini_XCEPTION输入要求);
- 灰度归一化:采用均衡化算法优化图像灰度分布,增强表情特征(如嘴角弧度、眉毛走势)的对比度,降低光线变化对识别的影响。
② CNN模型构建与训练模块(核心技术亮点)
采用CNN主流框架mini_XCEPTION构建表情识别模型,结合多种优化策略提升性能:
- 模型结构设计 :
- 卷积层:用固定权值的Gabor小波直接构造,高效提取人脸表情的纹理特征(如皱眉的竖纹、微笑的嘴角曲线),避免随机初始化权值导致的训练不稳定;
- 全连接层:融合支持向量机(SVM)算法,增强对相似表情(如"伤心"与"中性")的分类能力;
- 层次确定:通过"匹配生长规则"动态调整网络层数,平衡模型复杂度与识别速度;
- 训练与优化 :
- 数据集:使用FER表情数据集(含数万张标注好的人脸表情图像),按8:2划分训练集与测试集;
- 参数训练:采用反向传播算法优化模型参数,迭代调整权重,确保模型对7类表情的分类精度;
- 降维处理:针对Gabor小波导致的"维度灾难"(特征维度过高,识别耗时),用Fisher线性判别法改进的PCA(主成分分析)压缩特征维度,在保留关键表情信息的同时,将识别速度提升30%以上;
- 模型验证:对比"改进PCA+SVM"与"mini_XCEPTION"两种方案的测试集准确率,验证CNN模型在表情识别上的优越性(通常CNN方案准确率达85%以上,高于传统方法10%-15%)。
③ 多模态识别功能模块(用户核心操作)
支持三种识别模式,覆盖不同应用场景:
- 图片识别:用户通过PyQt5界面上传单张人脸图片,系统经预处理后输入CNN模型,1-2秒内输出表情分类结果(如"快乐,置信度92%"),并显示关键识别依据(如标注嘴角上扬区域);
- 视频检测:导入含人脸的视频文件,系统逐帧进行人脸定位与表情识别,生成带实时表情标注的新视频,支持倍速播放与结果导出;
- 摄像头实时识别:调用电脑/设备摄像头,实时捕获人脸图像,每秒更新10-15次表情识别结果,适用于实时交互(如智能终端的情感反馈)。
④ PyQt5 GUI界面模块(用户交互支撑)
基于PyQt5构建直观易用的可视化界面,包含三大功能区:
- 操作区:提供"图片上传""视频导入""开启摄像头"三个核心按钮,支持拖拽式上传文件;
- 结果展示区:实时显示识别后的图像/视频,用文字+颜色标注表情类别(如"快乐"用绿色标注,"生气"用红色标注),并展示置信度;
- 设置区:支持调整识别灵敏度(如置信度阈值)、图像预处理参数(如裁剪精度),满足不同场景的个性化需求。
(2)系统价值与应用场景
- 目标场景:智能客服(根据用户表情调整服务策略)、心理评估(辅助情绪状态监测)、儿童教育(通过表情判断学习专注度)、安防监控(识别异常情绪行为);
- 核心优势 :
- 高精度:CNN+优化预处理,7类表情识别准确率达85%以上,复杂环境下仍稳定;
- 高效率:降维处理+轻量化mini_XCEPTION框架,支持实时识别(摄像头模式延迟<0.1秒);
- 易操作:PyQt5界面可视化,无需专业技术即可完成识别操作。
4、爆款标题
- 毕业设计:Python+CNN(mini_XCEPTION) 人脸表情识别系统(7类表情+PyQt5 源码+文档)✅
- 深度学习实战:Python TensorFlow表情识别(FER数据集+实时摄像头检测 毕业设计源码)✅
- 多模态项目:Python人脸表情系统(CNN+Adaboost定位+PyQt5界面 源码+文档)✅
4、核心代码
python
# -*- coding: utf-8 -*-
from PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtWidgets import QFileDialog
from PyQt5.QtCore import Qt
from PyQt5.QtGui import QMovie
from real_time_video_me import Emotion_Rec
from os import getcwd
import numpy as np
import cv2
import time
from base64 import b64decode
from os import remove
from slice_png import img as bgImg
from EmotionRecongnition_UI import Ui_MainWindow
import image1_rc
class Emotion_MainWindow(Ui_MainWindow):
def __init__(self, MainWindow):
self.path = getcwd()
self.timer_camera = QtCore.QTimer() # 定时器
self.timer_video = QtCore.QTimer() # 定时器
self.setupUi(MainWindow)
self.retranslateUi(MainWindow)
self.slot_init() # 槽函数设置
# 设置界面动画
gif = QMovie(':/newPrefix/icons/scan.gif')
self.label_face.setMovie(gif)
gif.start()
self.cap = cv2.VideoCapture() # 屏幕画面对象
self.cap2 = cv2.VideoCapture()
self.CAM_NUM = 0 # 摄像头标号
self.model_path = None # 模型路径
# self.__flag_work = 0
def slot_init(self): # 定义槽函数
self.toolButton_camera.clicked.connect(self.button_open_camera_click)
self.toolButton_model.clicked.connect(self.choose_model)
self.toolButton_video.clicked.connect(self.button_open_video_click)
self.timer_camera.timeout.connect(self.show_camera)
self.timer_video.timeout.connect(self.show_video)
self.toolButton_file.clicked.connect(self.choose_pic)
def button_open_camera_click(self):
# 界面处理
self.timer_camera.stop()
self.timer_video.stop()
self.cap.release()
self.cap2.release()
self.label_face.clear()
self.label_result.setText('None')
self.label_time.setText('0 s')
self.textEdit_camera.setText('实时摄像已关闭')
self.textEdit_video.setText("视频未选中")
self.label_outputResult.clear()
self.label_outputResult.setStyleSheet("border-image: url(:/newPrefix/icons/ini.png);")
if self.timer_camera.isActive() == False: # 检查定时状态
flag = self.cap.open(self.CAM_NUM) # 检查相机状态
if flag == False: # 相机打开失败提示
msg = QtWidgets.QMessageBox.warning(self.centralwidget, u"Warning",
u"请检测相机与电脑是否连接正确! ",
buttons=QtWidgets.QMessageBox.Ok,
defaultButton=QtWidgets.QMessageBox.Ok)
else:
# 准备运行识别程序
self.textEdit_pic.setText('文件未选中')
QtWidgets.QApplication.processEvents()
self.textEdit_camera.setText('实时摄像已开启')
self.label_face.setText('正在启动识别系统...\n\nleading')
# 新建对象
self.emotion_model = Emotion_Rec(self.model_path)
QtWidgets.QApplication.processEvents()
# 打开定时器
self.timer_camera.start(30)
else:
# 定时器未开启,界面回复初始状态
self.timer_camera.stop()
self.timer_video.stop()
self.cap.release()
self.cap2.release()
self.label_face.clear()
self.textEdit_camera.setText('实时摄像已关闭')
self.textEdit_pic.setText('文件未选中')
self.textEdit_video.setText('文件未选中')
gif = QMovie(':/newPrefix/icons/scan.gif')
self.label_face.setMovie(gif)
gif.start()
self.label_outputResult.clear()
self.label_outputResult.setStyleSheet("border-image: url(:/newPrefix/icons/ini.png);")
self.label_result.setText('None')
self.label_time.setText('0 s')
def button_open_video_click(self):
# 界面处理
self.timer_camera.stop()
self.timer_video.stop()
self.cap.release()
self.cap2.release()
self.label_face.clear()
self.label_result.setText('None')
self.label_time.setText('0 s')
self.textEdit_camera.setText('实时摄像已关闭')
self.textEdit_video.setText("视频未选中")
self.label_outputResult.clear()
self.label_outputResult.setStyleSheet("border-image: url(:/newPrefix/icons/ini.png);")
if self.timer_video.isActive() == False: # 检查定时状态
# 使用文件选择对话框选择图片
fileName_choose, filetype = QFileDialog.getOpenFileName(
self.centralwidget, "选取图片文件",
self.path, # 起始路径
"视频(*.mp4;)") # 文件类型
self.path = fileName_choose # 保存路径
if fileName_choose != '':
self.textEdit_video.setText(fileName_choose + '文件已选中')
# 新建对象
self.cap2 = cv2.VideoCapture(self.path)
self.emotion_model = Emotion_Rec(self.model_path)
# 打开定时器
self.label_face.setText('正在启动识别系统...\n\nleading')
self.timer_video.start(30)
QtWidgets.QApplication.processEvents()
else:
# 准备运行识别程序
self.textEdit_pic.setText('文件未选中')
self.textEdit_video.setText('文件未选中')
QtWidgets.QApplication.processEvents()
self.textEdit_camera.setText('实时摄像已关闭')
else:
# 定时器未开启,界面回复初始状态
self.timer_camera.stop()
self.timer_video.stop()
self.cap.release()
self.cap2.release()
self.label_face.clear()
self.textEdit_camera.setText('实时摄像已关闭')
self.textEdit_pic.setText('文件未选中')
self.textEdit_video.setText('文件未选中')
gif = QMovie(':/newPrefix/icons/scan.gif')
self.label_face.setMovie(gif)
gif.start()
self.label_outputResult.clear()
self.label_outputResult.setStyleSheet("border-image: url(:/newPrefix/icons/ini.png);")
self.label_result.setText('None')
self.label_time.setText('0 s')
def choose_model(self):
# 选择训练好的模型文件
self.timer_camera.stop()
self.timer_video.stop()
self.cap.release()
self.cap2.release()
self.label_face.clear()
self.label_result.setText('None')
self.label_time.setText('0 s')
self.textEdit_camera.setText('实时摄像已关闭')
self.textEdit_video.setText('文件未选中')
self.textEdit_pic.setText('文件未选中')
self.label_outputResult.clear()
self.label_outputResult.setStyleSheet("border-image: url(:/newPrefix/icons/ini.png);")
# 调用文件选择对话框
fileName_choose, filetype = QFileDialog.getOpenFileName(self.centralwidget,
"选取图片文件", getcwd(), # 起始路径
"Model File (*.hdf5)") # 文件类型
# 显示提示信息
if fileName_choose != '':
self.model_path = fileName_choose
self.textEdit_model.setText(fileName_choose + ' 已选中')
else:
self.textEdit_model.setText('使用默认模型')
# 恢复界面
gif = QMovie(':/newPrefix/icons/scan.gif')
self.label_face.setMovie(gif)
gif.start()🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻