目录

1.摘要
本文提出了一种自适应强化学习(RL)方法,结合了K-means聚类算法,并通过模拟退火进行优化,旨在解决疫苗分配中的容量车辆路径问题(CVRVD)。该方法为疫苗分配物流提供了一种高效、可扩展的解决方案。通过考虑旅行距离、库存水平和罚款等成本因素,并遵守交付时间窗口,论文方法在提升操作效率的同时,也优化了疫苗的分配效果。
2.疫苗分配问题
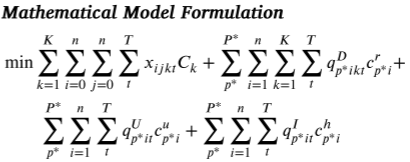
论文提出的疫苗分配数学模型旨在通过最小化运输、燃料消耗和分配费用,同时满足需求和容量约束,优化疫苗从分发中心(VDC)到各接种设施的分配。模型假设每辆卡车只负责一种类型的疫苗,并支持不同的温控要求(如冷藏、低温等)。决策变量包括运输方式、每种疫苗的分配量和车辆使用情况等。通过综合考虑运输成本、库存水平和罚款项,该模型有效提高了疫苗分配的效率和成本效益,尤其在大规模应用场景中表现出显著优势。
数学模型

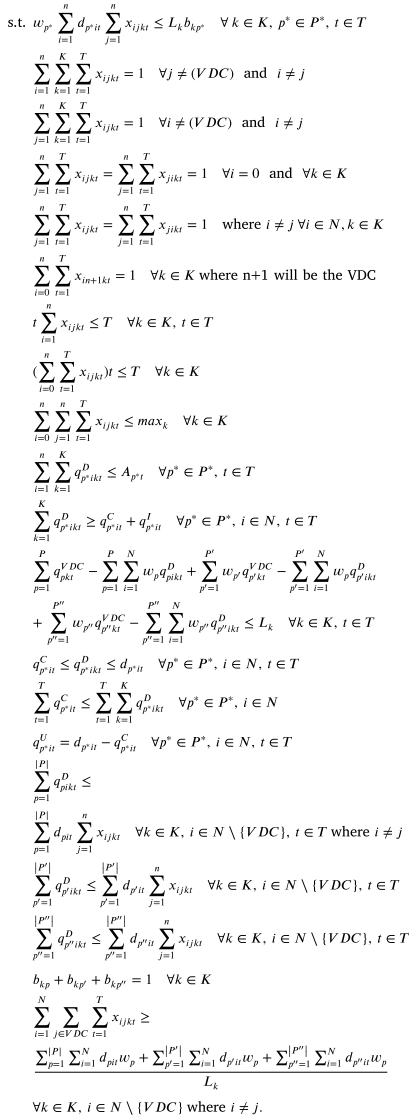
3.自适应K-means和强化学习RL算法
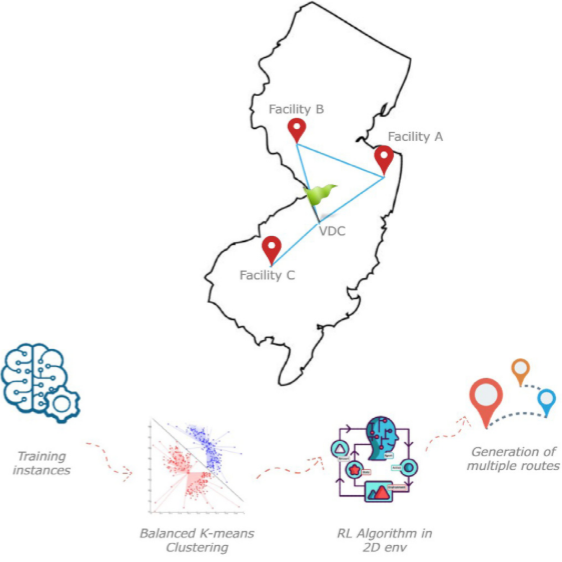
K-means值算法通过将设施分为容量约束的簇,将大问题拆解为更易管理的子问题。在每个簇内,RL算法优化节点访问顺序,模拟退火(SA)则帮助避免局部最优解,提升整体效果。该方法通过动态调整集群中心和设施分配,解决了容量限制和成本约束,同时考虑运输、库存、罚款等费用。在优化过程中,RL通过学习最优路径,提高了整体分配效率,模拟退火进一步改善了路径规划。
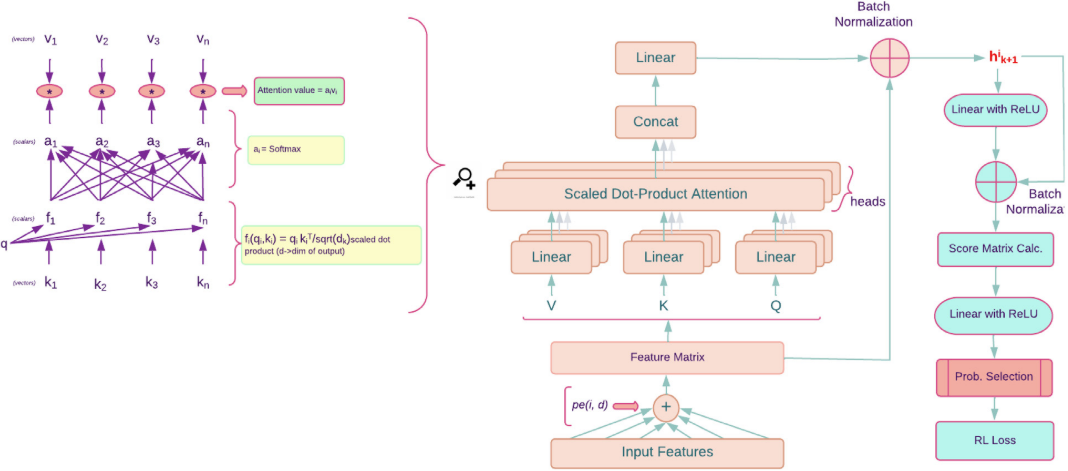
RL算法通过定义状态-行动对和奖励来引导RL智能体的学习,利用策略网络和SA算法优化设施配置。RL智能体根据高斯策略选择行动,探索多种可能的操作,而SA帮助在不断优化过程中避免局部最优。通过迭代更新Actor and Critic Network,算法在每一步通过状态观察和行动选择不断调整路径,优化设施配置。
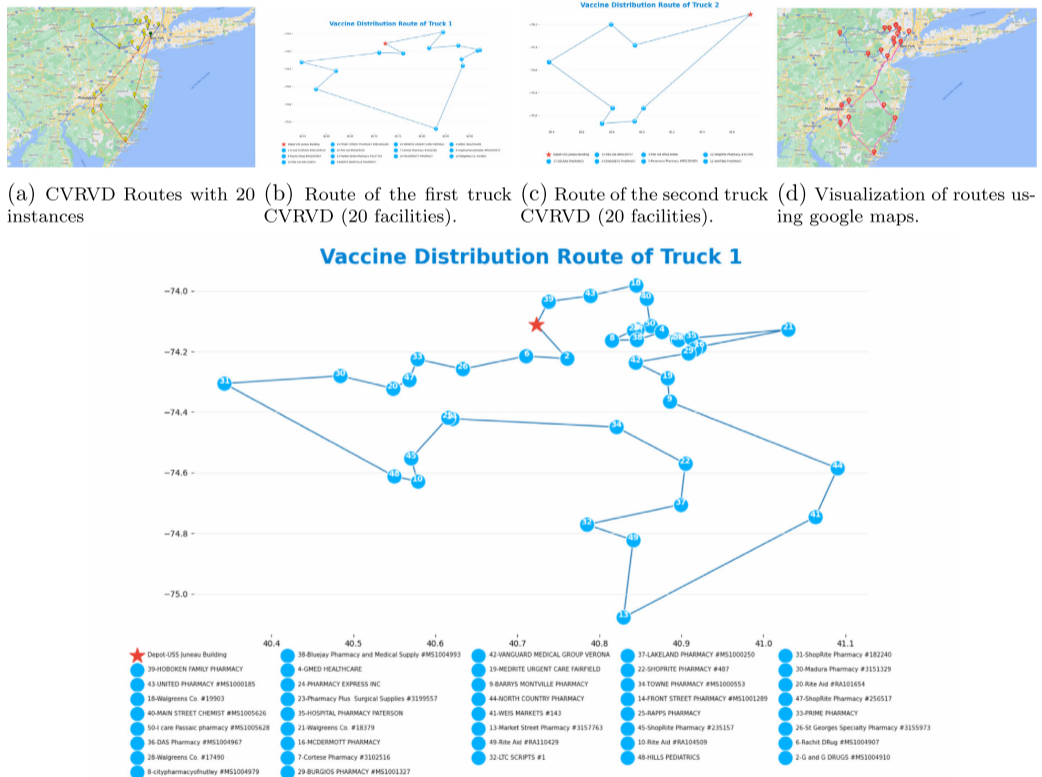
4.结果展示
5.参考文献
1 Cibaku E, Büyüktahtakın İ E. An adaptive K-means and reinforcement learning (RL) algorithm to effective vaccine distributionJ. Computers & Operations Research, 2025: 107275.
6.代码获取
xx
7.算法辅导·应用定制·读者交流
xx