点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年10月13日更新到:
Java-147 深入浅出 MongoDB 分页查询详解:skip() + limit() + sort() 实现高效分页、性能优化与 WriteConcern 写入机制全解析
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
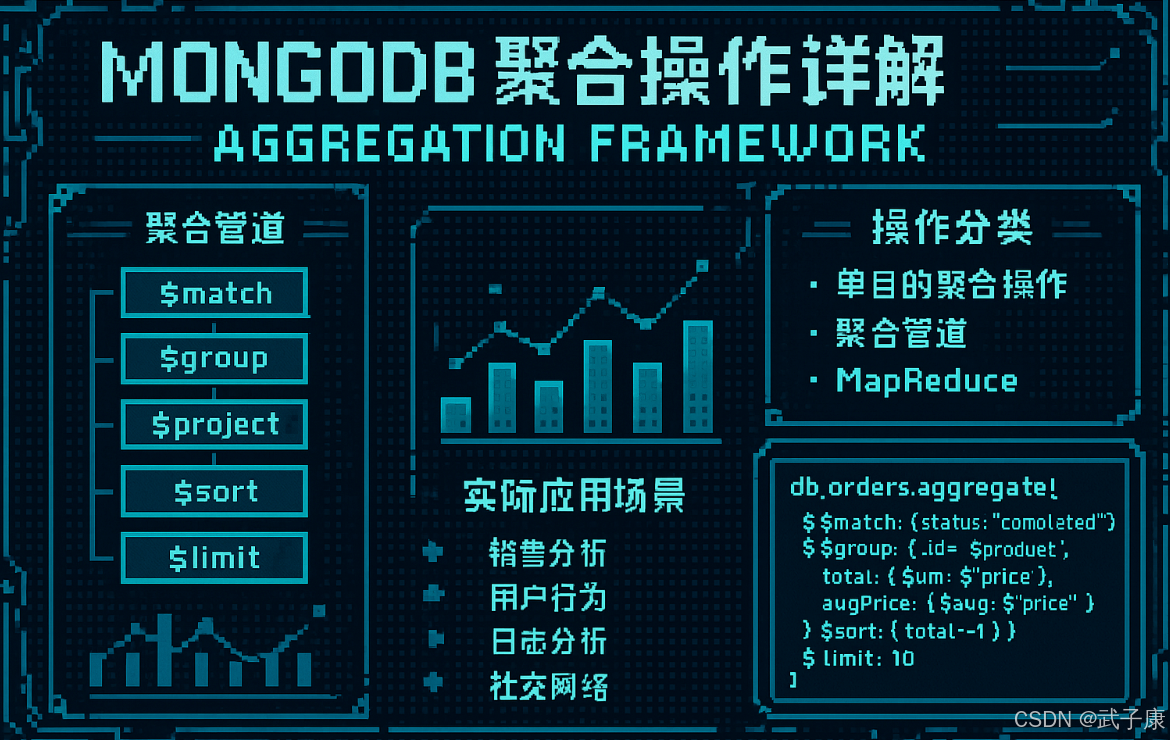
聚合操作
MongoDB 聚合操作详解
聚合操作概述
MongoDB 的聚合框架是一个强大的数据处理工具,它通过构建数据处理管道来对文档进行复杂转换和分析。与简单的查询操作不同,聚合操作能够执行跨多个文档的数据处理,实现类似于 SQL 中的 GROUP BY、JOIN 等复杂操作。
聚合管道工作原理
聚合操作通过将多个处理阶段(stage)串联成一个管道(pipeline)来工作。每个阶段都会对输入的文档进行处理,然后将处理结果传递给下一个阶段。典型的聚合管道包含以下阶段:
- $match:筛选符合条件的文档,类似于 SQL 中的 WHERE 子句
- $group:根据指定字段对文档进行分组
- $project:选择或重命名输出字段
- $sort:对结果进行排序
- $limit:限制输出文档数量
聚合操作能力
-
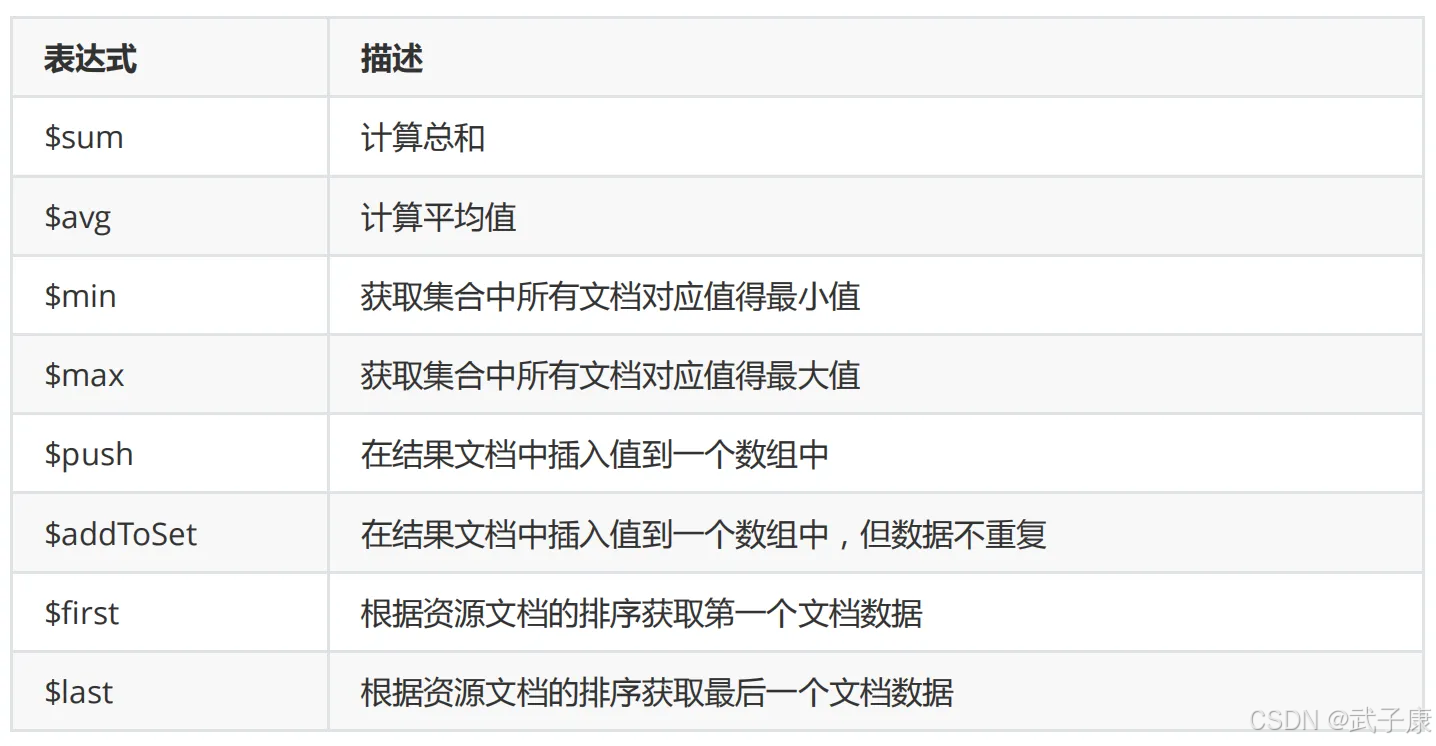
基础统计功能:
- 计算最大值($max)
- 计算最小值($min)
- 计算平均值($avg)
- 计算总和($sum)
- 计数($count)
-
高级分析功能:
- 数据透视(使用group和group和group和project)
- 时间序列分析(配合$dateToString)
- 文本分析(使用$text)
- 地理空间分析(使用$geoNear)
输入输出说明
- 输入:可以是一个集合中的全部文档,也可以是经过筛选的部分文档
- 输出 :根据聚合操作的不同,可能产生:
- 单个文档(如统计总和)
- 多个文档(如分组统计)
- 全新的数据结构(如重组后的文档)
实际应用场景
- 销售分析:按地区、时间段统计销售额
- 用户行为分析:计算用户平均访问时长、最常访问页面
- 日志分析:统计错误发生频率、时段分布
- 社交网络分析:计算用户关系网、影响力排名
性能优化建议
- 尽量在管道前端使用$match减少处理文档数量
- 合理使用索引加速聚合查询
- 避免在$group阶段处理大量数据
- 考虑使用allowDiskOption选项处理大数据集
示例
javascript
db.orders.aggregate([
{ $match: { status: "completed" } },
{ $group: {
_id: "$product",
total: { $sum: "$price" },
avgPrice: { $avg: "$price" }
}
},
{ $sort: { total: -1 } },
{ $limit: 10 }
])这个聚合管道会:
- 先筛选出状态为"completed"的订单
- 按产品分组并计算总销售额和平均价格
- 按总销售额降序排序
- 只返回前10条记录
操作分类
单目的聚合操作(Single Purpose Aggregation Operation)
单目的聚合操作是 MongoDB 提供的简单聚合函数,它们针对特定场景进行了优化。这类操作通常用于执行常见的聚合任务,如计数、求和、平均值等。主要特点包括:
- 执行效率高,针对特定聚合任务进行了优化
- 语法简单,易于使用
- 功能相对单一,适用于简单的聚合需求
常用单目聚合操作包括:
- count(): 计算文档数量
- distinct(): 返回指定字段的不同值
- group(): 按照指定条件分组(在3.4版本后已弃用)
- estimatedDocumentCount(): 快速估计集合中的文档数量
示例场景:
javascript
// 计算orders集合中status为"shipped"的文档数量
db.orders.count({status: "shipped"})
// 获取products集合中category字段的所有不同值
db.products.distinct("category")聚合管道(Aggregation Pipeline)
聚合管道是 MongoDB 最强大的聚合框架,它允许用户通过多个处理阶段对数据进行转换和分析。主要特点包括:
- 基于管道模型,数据依次通过多个处理阶段
- 每个阶段对输入文档进行处理并输出结果
- 支持丰富的操作符和表达式
- 可以处理复杂的数据分析需求
典型的聚合管道阶段包括:
- $match: 过滤文档(类似于find)
- $group: 分组聚合
- $project: 重塑文档结构
- $sort: 排序
- $limit: 限制输出数量
- $lookup: 执行类似SQL的join操作
示例场景:
javascript
// 计算每个类别的产品平均价格
db.products.aggregate([
{
$group: {
_id: "$category",
avgPrice: { $avg: "$price" }
}
},
{
$sort: { avgPrice: -1 }
}
])MapReduce 编程模型
MapReduce 是 MongoDB 提供的用于处理大规模数据集的编程模型,适用于复杂的聚合任务。主要特点包括:
- 基于JavaScript实现
- 包含map和reduce两个主要阶段
- 灵活性高,可以处理复杂的计算逻辑
- 执行效率通常低于聚合管道
- 适合处理不适合用聚合管道表达的计算
典型应用场景:
- 复杂的数据分析
- 自定义聚合逻辑
- 大规模数据处理
示例场景:
javascript
// 使用MapReduce计算每个类别的产品数量
var mapFunction = function() {
emit(this.category, 1);
};
var reduceFunction = function(key, values) {
return Array.sum(values);
};
db.products.mapReduce(
mapFunction,
reduceFunction,
{ out: "product_counts" }
)注意:在MongoDB 5.0版本后,MapReduce已被标记为废弃功能,建议使用聚合管道替代。
单目聚合
单目聚合的命令常用的有:count()和 distinct()
shell
db.wzk.find({}).count();
聚合管道
MongoDB 聚合管道(Aggregation Pipeline)
基本语法
shell
db.collection_name.aggregate([
{ $stage1: { /* 操作 */ } },
{ $stage2: { /* 操作 */ } },
...
])聚合管道概述
MongoDB 的聚合管道是一种强大的数据处理工具,主要用于对集合中的文档进行多阶段的转换和处理,最终输出统计或加工后的数据结果。聚合管道可以:
- 执行复杂的数据分析和统计操作(如平均值、求和、最大值等)
- 对数据进行分组、筛选和排序
- 转换和重组文档结构
- 实现多表关联查询
表达式特点
- 每个表达式只能处理当前聚合管道阶段的文档
- 表达式不能直接访问其他文档或集合
- 常见的表达式类型包括:
- 布尔表达式(and, or, $not)
- 比较表达式(eq, gt, $lt)
- 算术表达式(add, subtract, $multiply)
- 字符串表达式(concat, substr)
- 日期表达式(year, month, $dayOfMonth)
常用聚合阶段
-
$match:过滤文档,类似于find()方法
shell{ $match: { status: "A" } } -
$group:按指定表达式分组文档
shell{ $group: { _id: "$cust_id", total: { $sum: "$amount" } } } -
$project:重塑文档结构
shell{ $project: { name: 1, age: 1, _id: 0 } } -
$sort:对文档排序
shell{ $sort: { age: -1 } } -
$limit:限制文档数量
shell{ $limit: 5 }
实际应用示例
统计订单表中每个客户的消费总额:
shell
db.orders.aggregate([
{ $match: { status: "completed" } },
{ $group: {
_id: "$customer_id",
total: { $sum: "$amount" },
avg: { $avg: "$amount" },
count: { $sum: 1 }
} },
{ $sort: { total: -1 } },
{ $limit: 10 }
])
MongoDB 使用 db.collection_name.aggregate() 方法来构建和执行聚合管道操作。聚合管道是一个功能强大的数据处理框架,它允许我们对文档进行多阶段的转换和处理。
聚合管道的工作原理
- 管道阶段(Stages):每个聚合管道由一个或多个阶段组成,每个阶段对输入的文档进行特定的处理
- 数据处理流程 :
- 文档依次通过管道中的每个阶段
- 每个阶段的输出作为下一个阶段的输入
- 最后一个阶段的输出即为最终结果
- 常见管道阶段 :
$match:过滤文档,类似于查询条件$project:选择/重命名/计算字段$group:按指定字段分组$sort:排序文档$limit:限制返回文档数量$lookup:执行类似关联查询的操作
聚合管道的特点
- 灵活性:可以组合多个阶段实现复杂的数据处理需求
- 高效性:MongoDB 会对聚合管道进行优化,提高执行效率
- 可重复性 :相同的阶段可以多次出现在管道中(如多次
$project)
应用示例
- 数据分析:计算销售数据统计、用户行为分析等
- 数据转换:将文档转换为更适合前端展示的格式
- 复杂查询:实现SQL中的多表关联、子查询等功能
javascript
// 示例:计算每个部门的平均工资
db.employees.aggregate([
{ $match: { status: "active" } }, // 阶段1:筛选活跃员工
{ $group: { // 阶段2:按部门分组
_id: "$department",
avgSalary: { $avg: "$salary" },
count: { $sum: 1 }
}
},
{ $sort: { avgSalary: -1 } }, // 阶段3:按平均工资降序排序
{ $limit: 5 } // 阶段4:只返回前5个部门
])常用操作
聚合管道是MongoDB最强大的特性之一,能够处理各种复杂的数据处理需求,特别适合大数据分析和报表生成场景。
MongoDB 聚合框架常用操作详解
group 分组操作
group 操作是聚合框架中最核心的功能之一,它允许将集合中的文档按照特定字段进行分组,并可以对每个分组执行各种统计计算。例如:
- 统计每个产品类别的销售总额
- 计算每个部门的平均薪资
- 按地区分组统计用户数量
javascript
db.sales.group({
key: { product: 1 },
reduce: function(curr, result) {
result.total += curr.amount
},
initial: { total: 0 }
})project 投影操作
project 操作可以重塑文档结构,功能包括:
- 重命名字段(如将"userName"改为"name")
- 添加计算字段(如将"price"和"quantity"相乘得到"total")
- 排除/包含特定字段
- 创建嵌套文档结构
javascript
db.orders.aggregate([
{
$project: {
customer: 1,
total: { $multiply: ["$price", "$quantity"] },
_id: 0
}
}
])match 匹配过滤
match 操作相当于SQL中的WHERE子句,用于筛选符合条件的文档:
- 数值范围筛选(如价格在100-500之间的商品)
- 文本匹配(如用户名包含"john")
- 日期范围查询
- 组合条件查询(与、或、非)
javascript
db.users.aggregate([
{
$match: {
age: { $gt: 18 },
status: "active"
}
}
])limit 限制结果数量
limit 操作限制返回的文档数量,常用于:
- 分页查询
- 获取前N条记录
- 性能优化(减少网络传输量)
javascript
db.products.aggregate([
{ $limit: 10 }
])skip 跳过文档
skip 操作与limit配合使用实现分页:
- 跳过前N条记录
- 实现"加载更多"功能
- 大数据集分批处理
javascript
db.orders.aggregate([
{ $skip: 20 },
{ $limit: 10 }
])sort 排序操作
sort 操作对结果进行排序:
- 单字段排序(如按价格从高到低)
- 多字段排序(如先按类别再按价格)
- 文本索引排序
- 地理空间排序
javascript
db.employees.aggregate([
{
$sort: {
department: 1,
salary: -1
}
}
])geoNear 地理位置查询
geoNear 操作基于地理位置查询文档:
- 查找附近的地点(如5公里内的餐厅)
- 按距离排序结果
- 计算每个结果与中心点的距离
- 支持球面和平面几何计算
javascript
db.places.aggregate([
{
$geoNear: {
near: { type: "Point", coordinates: [-73.99279, 40.719296] },
distanceField: "dist.calculated",
maxDistance: 2000,
spherical: true
}
}
])这些操作可以灵活组合使用,构建复杂的聚合管道,满足各种数据分析需求。