PGLRNet: target pose-guided and feature loss-reduced network for oriented object detection in remote sensing images
此篇论文本人为第二作者
原文链接
https://doi.org/10.1007/s00371-025-03992-9![]() https://doi.org/10.1007/s00371-025-03992-9
https://doi.org/10.1007/s00371-025-03992-9

一、解决的问题
论文聚焦遥感图像定向目标检测任务,针对现有方法在复杂场景下的核心痛点展开研究,具体需解决的问题包括:
- 固定卷积核的特征错位问题:现有方法多采用水平固定卷积核,其感受野方向与图像坐标轴一致,无法适配遥感图像中舰船、车辆等任意角度旋转的目标,导致提取的特征与目标实际形状、方向错位,关键细节丢失,影响检测精度1。
- 特征聚合过程中的信息损失与退化:传统特征金字塔网络(如 FPN、PAFPN)在跨尺度特征交互时,易出现信息丢失或特征质量退化,尤其在遥感图像高分辨率、宽覆盖度的场景下,难以兼顾多尺度目标的检测性能3。
- 两阶段网络的子任务联动不足:传统两阶段定向目标检测网络中,上游模块与下游模块间协同性差,下游模块性能易受上游模块限制,且整体架构复杂,不利于实时检测需求3。
- 复杂场景下的检测鲁棒性不足:遥感图像存在背景复杂、目标尺度差异大、类间相似性高(如桥梁与立交桥)、类内多样性强(如不同类型舰船)等问题,现有方法对这类场景的适配能力有限,易出现误检、漏检2。
二、主要流程(PGLRNet 网络工作流程)
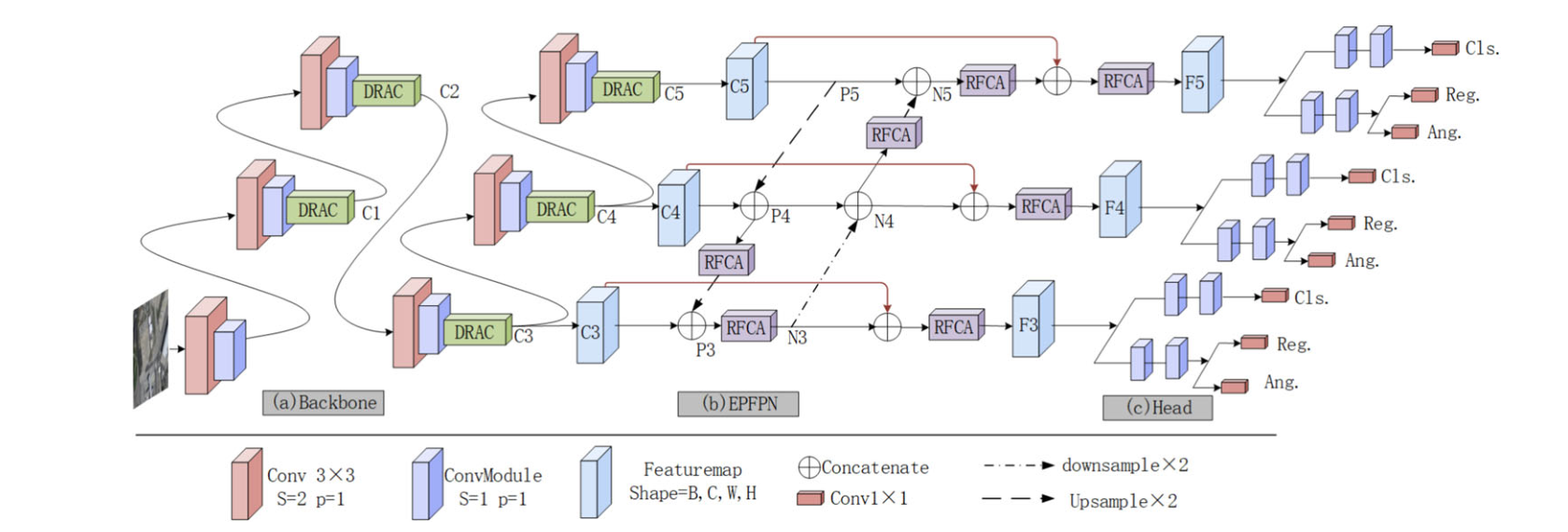
PGLRNet 作为端到端单阶段定向目标检测网络,整体流程围绕 "特征提取 - 特征聚合 - 特征优化 - 检测输出" 展开,具体步骤如下:
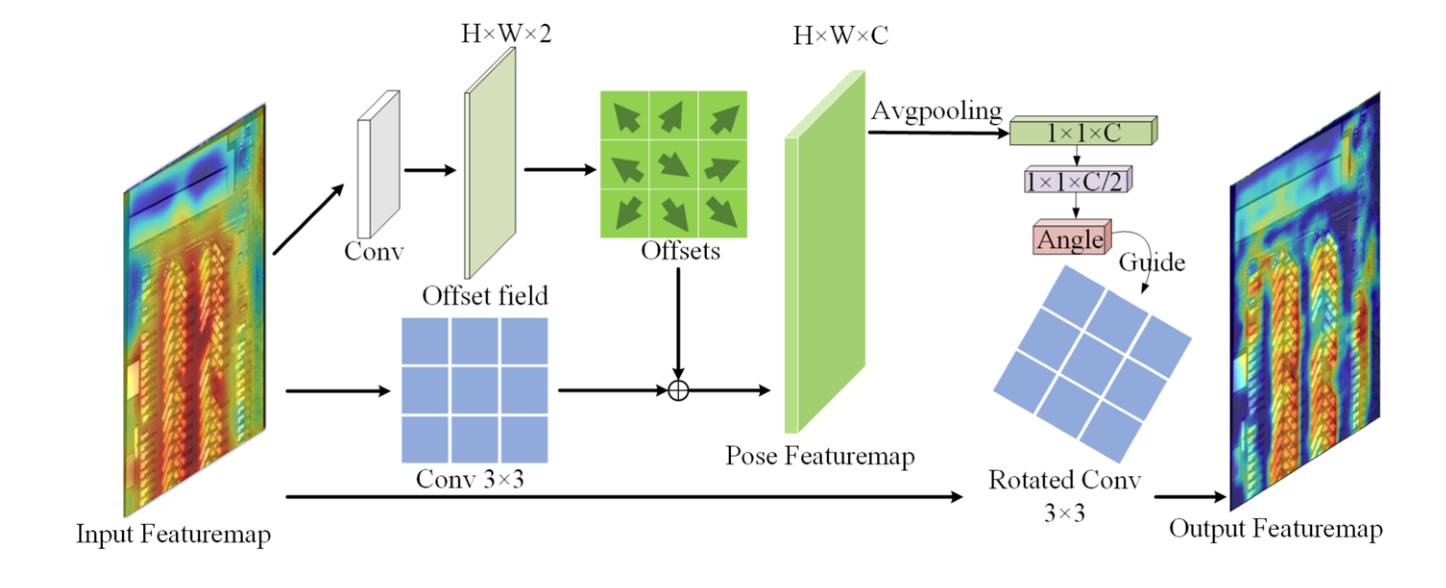
- 输入与骨干网络特征提取 :将遥感图像输入骨干网络(基于 RTMDet 框架),生成 5 个层级的特征图(C1-C5),同时在骨干网络各层嵌入姿态引导特征获取模块(DARC),通过可变形卷积学习目标姿态特征,动态调整卷积核方向,初步增强目标内在特征表达。
- 特征聚合(ENFPN 模块) :选取骨干网络输出的 C3、C4、C5 三层特征,输入增强路径特征金字塔网络(ENFPN) :
- 引入 "自上而下" 特征路径,将骨干网络多层特征与 "自下而上" 路径的低层特征关联,通过横向连接融合不同尺度特征;
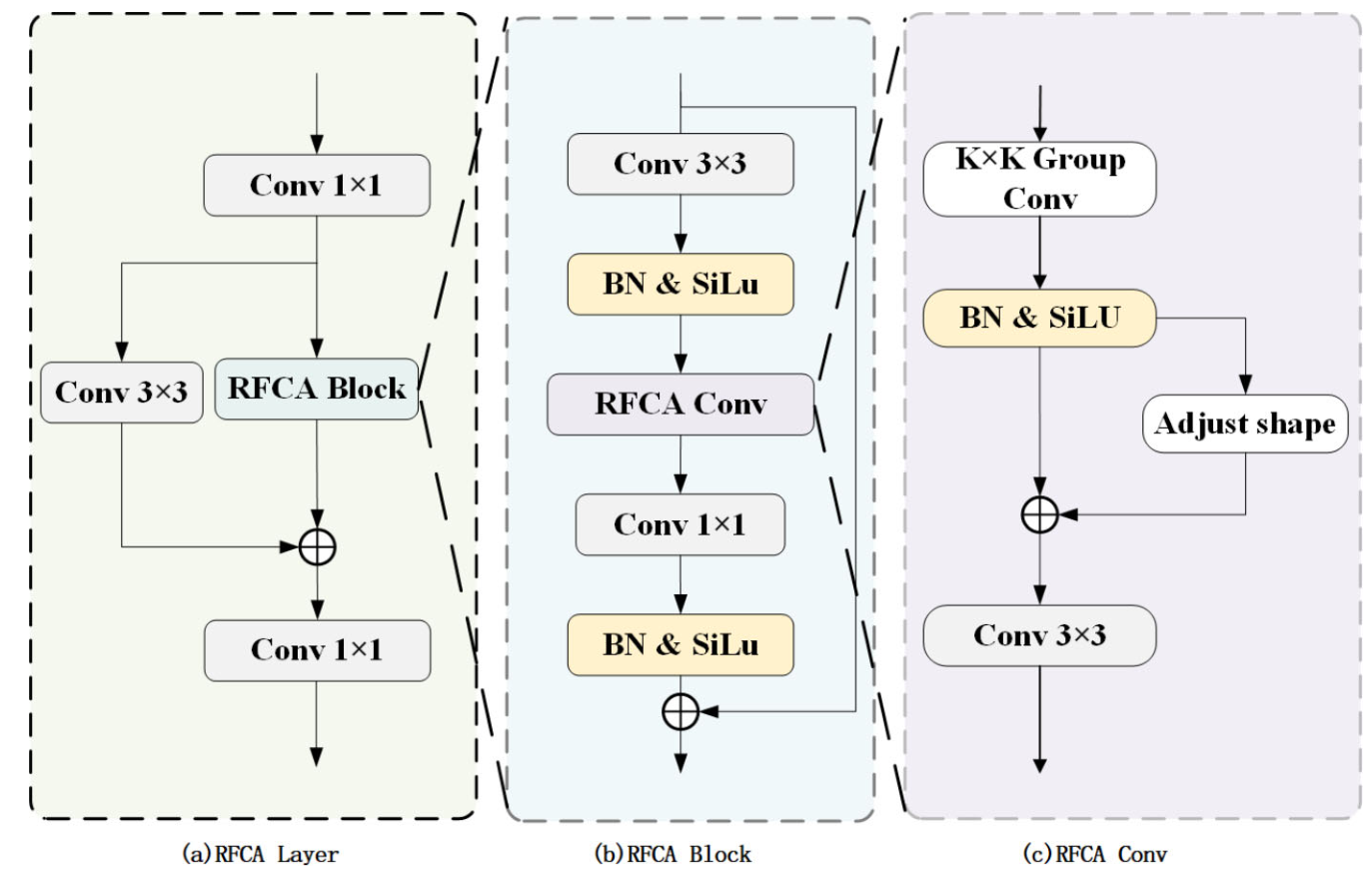
- 在特征融合后嵌入感受野协同注意力层(RFCALayer),对融合特征进行细化,减少无关信息干扰,补偿特征聚合过程中的信息损失。
- 特征优化与检测输出:ENFPN 输出的优化特征(F3、F4、F5)被送入分类与回归头,通过预设的检测逻辑实现目标类别判定与定向边界框回归,最终输出遥感图像中定向目标的检测结果(如目标位置、类别、旋转角度)。
三、核心创新点
-
提出姿态引导特征获取模块(DARC):
- 首次实现基于目标姿态动态调整卷积核方向:先通过可变形卷积感知目标姿态(形状、方向),并通过多层感知机(MLP)学习卷积核旋转角度;再利用该角度驱动卷积核自适应旋转,结合通道注意力机制突出关键特征区域,从根本上解决固定卷积核的特征错位问题,提升对定向目标的方向敏感性4。
- 该模块使卷积核既能适配目标变形(可变形卷积),又能匹配目标方向(旋转卷积核),还能筛选关键通道(通道注意力),三者协同增强定向目标特征表达10。
-
设计增强路径特征金字塔网络(ENFPN):
- 创新引入 "增强路径":在传统特征金字塔基础上,增加 "自上而下" 特征路径,将骨干网络特征与低层特征深度关联,同时在特征聚合后嵌入 RFCALayer,通过 3×3 卷积、批归一化、感受野协同卷积等操作优化特征权重,有效补偿跨尺度特征交互中的信息损失与退化5。
- 对比实验表明,ENFPN 相较于 FPN、PAFPN 等传统金字塔网络,在 DOTA 数据集上 mAP 提升 0.43 以上,显著增强多尺度目标检测性能13。
-
构建端到端单阶段网络架构:
- 突破两阶段网络子任务联动不足的局限,设计单阶段检测框架,将 DARC 模块与 ENFPN 模块深度融合,实现 "特征提取 - 聚合 - 优化 - 检测" 的端到端流程,减少模块间信息传递损耗6。
- 在 DOTA 数据集上实现 82.24% 的 mAP,达到单阶段算法的当前最优性能(SOTA),同时在 DIOR(mAP 72.30%)、HRSC2016(mAP 98.12%)数据集上表现出竞争力,验证了架构的通用性与有效性12。
-
优化特征细化机制(RFCALayer):
- 融合感受野协同卷积与注意力机制,通过分组卷积、形状调整、权重学习等操作,为大尺度卷积核提供有效注意力权重,减少无关信息干扰,生成高质量特征;同时权衡检测精度与计算复杂度,最终选择 3×3 卷积核尺寸,在保证性能的同时避免内存占用过高8。
四、备注
一、用旋转卷积核的原因:正常卷积核处理旋转问题的局限性
论文明确交代了使用旋转卷积核的核心原因 ------正常水平卷积核无法有效解决遥感图像中定向目标的特征错位问题,具体局限体现在以下 3 点:
- 特征对齐能力不足正常卷积核(水平卷积)的感受野是固定矩形,且方向与图像坐标轴一致。而遥感图像中的目标(如舰船、车辆)常呈任意角度旋转,水平卷积核的感受野难以与目标实际形状、方向匹配,导致提取的特征与目标 "错位"(论文 1. 引言部分提及 "fixed convolution 导致 feature misalignment")。例如,检测倾斜的舰船时,水平卷积核会同时包含大量背景像素,无法精准捕捉舰船的形状、纹理等 intrinsic 特征。
- 方向敏感性缺失正常卷积核对目标方向不敏感,无法区分 "水平车辆" 与 "倾斜车辆" 的方向特征差异。论文 3.4 节指出,现有方法中卷积核角度多为 "固定或无引导学习",导致对定向目标的特征提取不充分,尤其在复杂背景下易出现误检、漏检(如 baseline 方法因缺乏方向敏感性,对密集排列的旋转目标检测效果差,见图 1a 对比)。
- 多尺度与复杂场景适配差遥感图像兼具高分辨率、宽覆盖度特点,目标尺度差异大且背景复杂。正常卷积核的固定结构难以适配不同旋转角度、不同尺度的目标,而旋转卷积核可通过方向调整,在多尺度特征聚合中(如 ENFPN 模块)更好地保留目标关键细节,减少特征损失(论文 3.3 节提及旋转卷积与特征增强路径结合,提升多尺度检测性能)。
二、旋转卷积核的实现方式:从角度获取到权重匹配
论文 3.4 节(DARC 模块)详细阐述了 "基于目标姿态获取旋转角度后,实现旋转卷积核操作" 的完整流程,核心逻辑可拆解为 3 步:
1. 旋转角度的获取:基于目标姿态特征的引导
旋转角度并非随机设定,而是由目标自身姿态特征动态学习得到:
- 首先通过可变形卷积(DCN) 提取目标的姿态特征(如形状、方向):可变形卷积通过学习特征点偏移量,使感受野自适应目标的实际形态,避免方向变化对特征提取的干扰(公式 7);
- 再通过多层感知机(MLP)+ Sigmoid 激活 计算旋转角度:将可变形卷积输出的特征经 MaxPool 压缩后,输入 MLP 学习角度参数,Sigmoid 函数引入非线性以增强模型表达能力,最终输出适配目标姿态的旋转角度(公式 8:
Angle=σ(MLP(MaxPool(Y_out))))。
2. 旋转卷积核的构建:权重映射与空间调整
得到旋转角度后,通过旋转矩阵(RotateMatrix) 将水平卷积核转换为旋转卷积核,实现权重与图像的对应:
- 核心操作:论文公式 9(
RotateMatrix(W,θ))中,W为水平卷积核的原始权重,θ为上述步骤学到的旋转角度;旋转矩阵通过空间插值或数学映射 ,调整权重在空间中的分布,模拟卷积核绕中心旋转θ角的效果(参考论文引用的 30 中 "自适应旋转卷积" 思路); - 权重对应逻辑:旋转后的卷积核权重仍保持与原始水平核相同的参数数量,但空间位置随角度调整 ------ 例如,3×3 水平核旋转 30° 后,权重会重新分配到旋转后的网格中,确保与目标的方向对齐,避免背景像素干扰。
3. 卷积核的移动方式:保持平移操作,适配旋转后目标
旋转卷积核的 "旋转" 仅改变自身方向,卷积过程中的移动方式仍为平移:
- 与正常卷积核一致,旋转后的卷积核会在特征图上按固定步长(如 1 或 2)滑动(平移),逐区域进行特征提取(公式 10:
F=Conv2d(X, W'),其中W'为旋转后的卷积核); - 关键差异:平移过程中,
W'的方向始终与目标姿态对齐(由角度θ锁定),例如检测倾斜舰船时,旋转卷积核会以与舰船平行的方向平移,确保每一步滑动都能精准覆盖目标区域,提升特征提取的有效性。
三、补充说明:旋转卷积与通道注意力的协同优化
为进一步提升旋转卷积核的特征提取能力,论文在旋转卷积后引入通道注意力机制(参考 SENet 思路):
- 通过 AvgPool+MaxPool 融合通道特征,再经 MLP 学习各通道的重要性权重(公式 11);
- 将学习到的通道权重与旋转卷积输出的特征图进行逐元素乘法(⊙) (公式 12:
Y_final=M_c(F)⊙F),突出对目标检测更关键的方向通道特征,抑制无关背景通道,最终实现 "旋转适配 + 通道筛选" 的双重优化。