目录
- 前言
- [1. 文本类模型(Text Models)](#1. 文本类模型(Text Models))
-
- [1.1 非对话模型(Non-Chat Models)](#1.1 非对话模型(Non-Chat Models))
- [1.2 对话模型(Chat Models)](#1.2 对话模型(Chat Models))
- [2. 嵌入类模型(Embedding Models)](#2. 嵌入类模型(Embedding Models))
- [3. 视觉类模型(Vision Models)](#3. 视觉类模型(Vision Models))
-
- [3.1 图像模型(Image Models)](#3.1 图像模型(Image Models))
- [3.2 视频模型(Video Models)](#3.2 视频模型(Video Models))
- [4. 多模态模型(Multimodal Models)](#4. 多模态模型(Multimodal Models))
- [5. 模型类别对比与应用总结](#5. 模型类别对比与应用总结)
- 结语
前言
在人工智能的快速发展浪潮中,**大模型(Foundation Models)**已经成为推动产业升级和创新的核心引擎。从早期的语言模型(Language Models)到如今具备多模态感知与推理能力的通用智能体(General AI Agent),大模型正在重新定义人机交互的边界。
本文将系统介绍大模型的主要分类,包括文本模型(非对话与对话) 、嵌入模型 、**视觉模型(图像与视频)*以及*多模态模型,并分析各类模型的特点、典型用途及发展趋势,帮助读者全面理解大模型技术的生态格局。
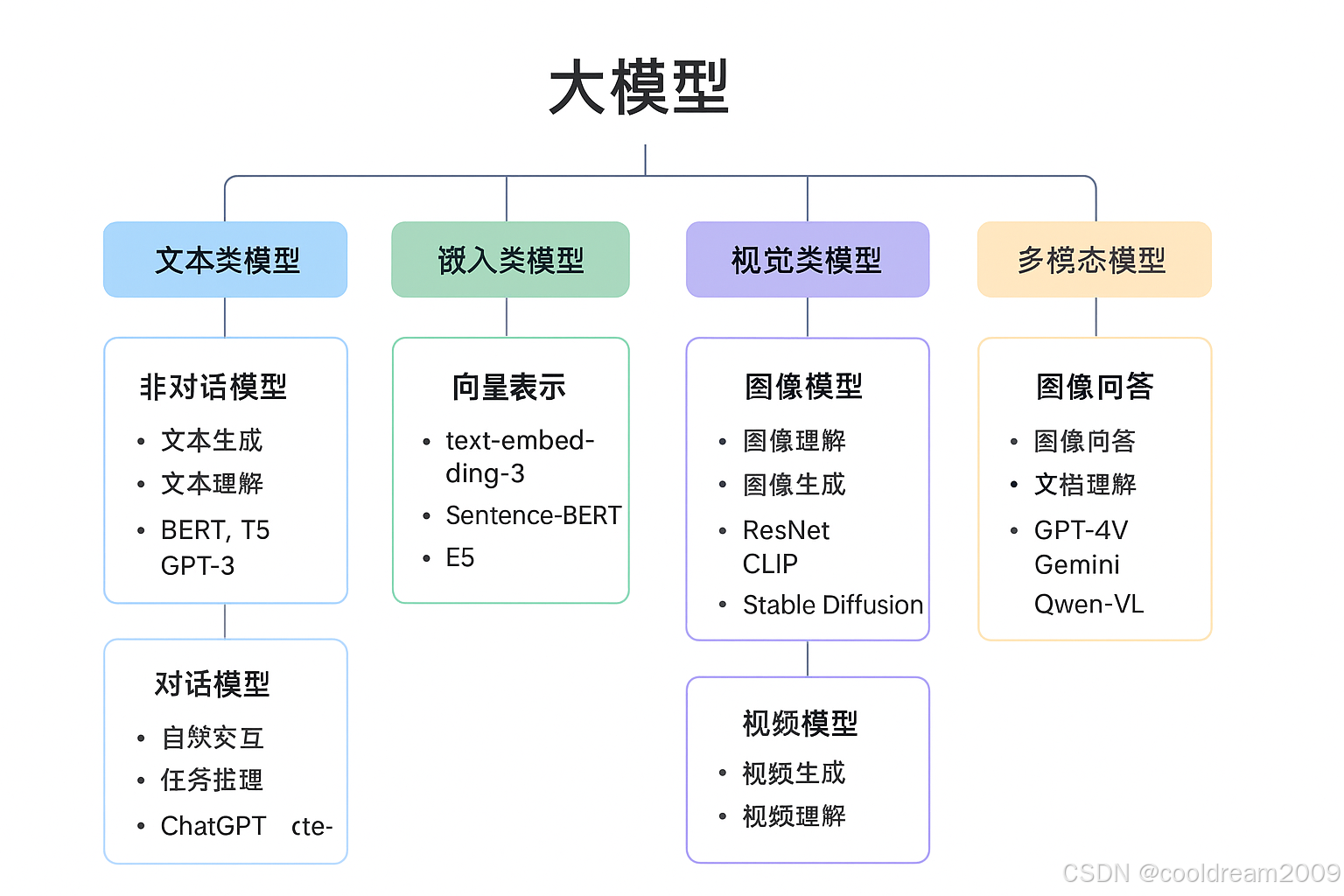
1. 文本类模型(Text Models)
文本模型是大模型体系中最成熟、最广泛应用的分支。它们通过理解和生成自然语言,成为众多AI应用的底层支撑。根据交互方式不同,文本类模型可以分为非对话模型 和对话模型两种。
1.1 非对话模型(Non-Chat Models)
非对话模型是早期语言模型的代表,主要用于文本生成与理解任务,但不具备多轮交互的上下文管理能力。
代表模型: BERT、T5、GPT-3(davinci)、OPT、LLaMA 基础模型等。
主要特点:
- 通过自回归或自编码方式建模文本结构;
- 能执行单轮输入的自然语言处理任务;
- 不具备人机交互逻辑和记忆机制。
典型用途:
- 文本补全与摘要生成;
- 情感分析与问答匹配;
- 文档分类与机器翻译;
- 搜索引擎语义理解与排序。
例如,BERT 采用双向Transformer结构,擅长理解类任务;而 GPT-3 则以单向预测为核心,能够流畅生成自然文本,是生成式AI的奠基者。
1.2 对话模型(Chat Models)
对话模型是在语言模型的基础上,结合人类反馈强化学习(RLHF)**与**多轮对话数据微调形成的高层智能体。它们能够理解上下文、保持连贯性,并以自然语言与用户交流。
代表模型: ChatGPT、Claude、Gemini、通义千问、文心一言等。
主要特点:
- 支持多轮对话与上下文记忆;
- 具备任务规划、推理和角色理解能力;
- 能执行复杂交互任务,如代码生成、内容创作、翻译与逻辑推理。
典型用途:
- 智能客服与知识问答;
- 办公自动化与内容创作;
- 教育、科研与编程辅助;
- 智能Agent系统与人机协作。
其中,ChatGPT(GPT-4 / GPT-5) 代表了通用对话智能的最新高度,具备跨领域推理与多模态理解能力;Claude 3 强调安全性与长上下文处理;Gemini 1.5 Pro 则融合文本与视觉,迈向多模态通用智能。
2. 嵌入类模型(Embedding Models)
嵌入模型的核心目标是将文本、代码、图像等内容映射为稠密向量表示(Embeddings),使计算机能够在语义空间中进行相似度度量与检索。这类模型不直接生成自然语言,而是为下游任务提供语义表示基础。
代表模型: text-embedding-3-large、Sentence-BERT、E5、SimCSE 等。
主要特点:
- 输出固定维度的语义向量;
- 可用于计算语义相似度与聚类;
- 支撑 RAG(检索增强生成)架构中的知识检索部分。
典型用途:
- 语义搜索与向量数据库查询;
- 文档聚类与主题识别;
- 推荐系统与知识图谱构建;
- RAG 应用中的检索阶段。
例如,OpenAI text-embedding-3-large 提供高维通用语义嵌入;E5 专注于中文语义检索;SimCSE 通过对比学习提升句向量质量。
这些模型构成了当前AI知识检索与信息匹配的核心基础设施。
3. 视觉类模型(Vision Models)
视觉模型处理和理解图像、视频等视觉信号,赋予AI"看"的能力。它们是从计算机视觉(CV)发展而来的另一大分支,可进一步分为图像模型和视频模型两类。
3.1 图像模型(Image Models)
图像模型负责对静态图像进行识别、生成或理解。早期以卷积神经网络(CNN)为主,近年来则以视觉Transformer(ViT)和扩散模型(Diffusion Models)为代表。
代表模型: ResNet、ViT、CLIP、Stable Diffusion、DALL·E、Midjourney。
主要特点:
- 支持图像分类、检测、分割与生成;
- 具备文本与图像对齐能力(如CLIP);
- 生成模型可根据文本指令创作图像。
典型用途:
- 图像识别与内容审核;
- 医学影像与工业检测;
- 创意绘图、艺术设计与广告生成;
- 图文检索与多模态交互。
| 模型 | 类型 | 应用场景 |
|---|---|---|
| ResNet | 视觉识别 | 图像分类与检测 |
| CLIP | 图文对齐 | 文本检索图像 |
| Stable Diffusion | 文生图 | 创意设计与绘图 |
| DALL·E 3 | 文本生成图像 | 高质量艺术创作 |
3.2 视频模型(Video Models)
视频模型在图像生成的基础上引入时间建模(Temporal Modeling),用于理解和生成动态场景。它们不仅关注每帧画面,还需保证运动连贯与物理一致性。
代表模型: Sora、Runway Gen-2、Pika Labs、VideoPoet。
主要特点:
- 可根据文本生成视频片段;
- 支持视频补全、编辑与风格化;
- 注重运动一致性和场景过渡自然度。
典型用途:
- 文本生成视频(Text-to-Video);
- 视频特效与虚拟拍摄;
- 动画预览与影视分镜制作;
- 数字人内容创作。
例如,OpenAI Sora 通过物理一致性建模生成逼真的视频画面,代表了视频生成的前沿方向。
4. 多模态模型(Multimodal Models)
多模态模型融合了文本、图像、音频、视频等多种输入模态,实现跨模态理解与生成。这类模型标志着AI从单一任务向通用智能迈进。
代表模型: GPT-4V、Gemini 1.5 Pro、Claude 3 Opus、Kosmos-2、Qwen-VL。
主要特点:
- 同时处理文字与视觉输入;
- 能执行图像问答、文档分析与视觉推理;
- 支撑"看图说话""图文互译""视频理解"等任务。
典型用途:
- 多模态问答(输入图片或截图进行解析);
- 文档识别与结构化理解(OCR + 语义分析);
- 跨模态检索与生成;
- 智能助手(集听觉、视觉与语言于一体)。
多模态模型是构建智能体(Agent)的关键,它们让AI能够"看见世界",并以自然语言进行解释与决策。
5. 模型类别对比与应用总结
| 类别 | 输入类型 | 输出类型 | 主要用途 | 代表模型 |
|---|---|---|---|---|
| 非对话文本模型 | 文本 | 文本 | 理解与生成 | BERT、T5、GPT-3 |
| 对话模型 | 文本(多轮) | 文本 | 交互与推理 | ChatGPT、Claude、Gemini |
| 嵌入模型 | 文本/图像 | 向量 | 语义检索、推荐 | text-embedding-3、E5 |
| 图像模型 | 图像/文本 | 图像 | 分类与生成 | CLIP、Stable Diffusion |
| 视频模型 | 文本/图像 | 视频 | 生成与理解 | Sora、Runway Gen-2 |
| 多模态模型 | 文本+视觉+音频 | 文本/视觉 | 综合认知 | GPT-4V、Gemini、Qwen-VL |
结语
大模型的发展轨迹展示了人工智能从**"语言理解"到"世界理解"**的演化过程。
- 文本模型为AI奠定了语义基础;
- 嵌入模型搭建了知识与信息的连接桥梁;
- 视觉与视频模型赋予了感知能力;
- 多模态模型实现了跨模态融合与通用智能。
未来,大模型将继续向以下方向演进:
🔹 模态融合 :实现语言、视觉、语音的深度统一;
🔹 任务泛化 :具备零样本、多任务的自适应能力;
🔹 智能体化:拥有记忆、推理与行动能力的自主智能系统。
随着技术与算力的持续突破,大模型正从"工具"走向"伙伴",成为未来数字世界的核心智能基础。