Ubuntu-8*H20服务器升级nvidia驱动+cuda版本
契机
看到qwen3-vl-30b开源了,想测试下性能+资源占用,奈何部署sglang需要12.7版本的cuda?我目前手里的H20的服务器cuda版本最高只支持12.2所以需要升级驱动以及cuda版本,随使用官方.run还有apt install xx进行升级。之前用的火山官方ubuntu镜像,默认驱动535,后升级驱动550,570,580后,cuda也对应升级后,cuda都无法使用无论是在conda中,还是直接在宿主机上测试,最后发现是nvidia-fabricmanager问题,NVIDIA-Fabric---Manager主要用于支持多GPU之间的高速通信(如NVLink),遂记录下升级历程。
关联
- 显卡8*H20的Ubuntu服务器在cuda不可用
- 升级nvidia驱动580失败
- Detected GPU count: 0,No GPU detected!
- 驱动的 GPU 访问库(libcuda.so)未被 CUDA 程序正确识别
- cuInit 失败:system not yet initialized
服务器初始配置
火山服务器镜像:Ubuntu22.04 with GPU Driver 535.230.02
如果是新的服务器的话推荐安装Ubuntu 22.04,不带gpu版本,免去卸载之前相关驱动
bash
#查看驱动版本
nvidia-smi
NVIDIA-SMI 535.161.08 Driver Version: 535.161.08 CUDA Version: 12.2
#查看当前cuda版本
nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Mon_Apr__3_17:16:06_PDT_2023
Cuda compilation tools, release 12.1, V12.1.105
Build cuda_12.1.r12.1/compiler.32688072_0升级/安装
卸载之前
bash
#卸载之前的
sudo apt purge nvidia-* cuda-* cuda-toolkit-* -y
sudo apt autoremove -y && sudo apt autoclean -y
sudo rm -rf /usr/local/cuda* # 删除 CUDA 残留目录
sudo rm -rf /var/lib/nvidia* /etc/X11/xorg.conf.d/10-nvidia.conf选择驱动
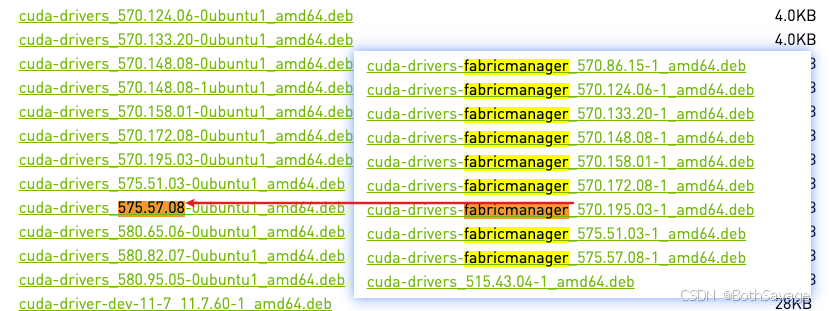
- 多显卡服务器一定要先选择fabricmanager,找到合适的fabricmanager,再去找对应版本驱动
- ubuntu2204对应fabricmanager+驱动查询网址:https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2204/x86_64/
- 截止25年10月16日,最新为cuda-drivers-fabricmanager_575.57.08-1_amd64.deb
- 对应去选择相应的驱动:cuda-drivers_575.57.08-0ubuntu1_amd64.deb
- 截止当前虽然nvidia线上发行版本为580,由于fabricmanager版本限制,不考虑源码编译安装等情况,还是最高只能安装575版本的驱动
- 官方网站驱动下载(可忽略,用作保底下载):https://developer.nvidia.com/cuda-toolkit-archive
安装驱动
bash
#下载deb格式的安装包
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2204/x86_64/cuda-drivers-fabricmanager-575_575.57.08-1_amd64.deb
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2204/x86_64/cuda-drivers-575_575.57.08-0ubuntu1_amd64.deb
#安装基础依赖:更新系统包索引+安装依赖(gcc编译器、内核头文件、dkms动态内核模块)
sudo apt update
sudo apt install -y gcc g++ make dkms linux-headers-$(uname -r)
#添加NVIDIA-CUDA官方仓库
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
echo "deb [signed-by=/usr/share/keyrings/cuda-archive-keyring.gpg] https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/ /" | sudo tee /etc/apt/sources.list.d/cuda.list
sudo apt update
#apt安装驱动
sudo apt install -y ./cuda-drivers-575_575.57.08-0ubuntu1_amd64.deb
sudo apt install -y ./cuda-drivers-fabricmanager-575_575.57.08-1_amd64.deb
#安装完成后必须重启
sudo reboot安装cuda
bash
#验证驱动
nvidia-smi
#fabricmanager:验证+启动+升级开机启动
sudo systemctl status nvidia-fabricmanager
sudo systemctl start nvidia-fabricmanager
sudo systemctl enable nvidia-fabricmanager
#安装cuda12.9
sudo apt-get -y install cuda-toolkit-12-9
#验证cuda是否成功安装
ll /usr/local/ | grep cuda
# 追加cuda到环境变量到 .bashrc
echo -e "\nexport PATH=/usr/local/cuda-12.9/bin:\$PATH" >> ~/.bashrc
echo -e "export LD_LIBRARY_PATH=/usr/local/cuda-12.9/lib64:\$LD_LIBRARY_PATH" >> ~/.bashrc
source ~/.bashrc
#验证nvcc
nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Tue_May_27_02:21:03_PDT_2025
Cuda compilation tools, release 12.9, V12.9.86
Build cuda_12.9.r12.9/compiler.36037853_0测试cuda程序
bash
#新建一个cuda验证程序如下
vim test_cuda.cu
#>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
#include <stdio.h>
#include <cuda.h>
#include <cuda_runtime.h>
int main() {
// 直接初始化,环境变量在外部设置
CUresult cu_err = cuInit(0);
const char* cu_err_msg;
cuGetErrorString(cu_err, &cu_err_msg);
if (cu_err != CUDA_SUCCESS) {
printf("cuInit 失败:%s\n", cu_err_msg);
return 1;
}
printf("✅ cuInit 成功!驱动已就绪\n");
// 后续步骤保持不变
cudaError_t rt_err = cudaDeviceReset();
if (rt_err != cudaSuccess) {
printf("cudaDeviceReset 失败:%s\n", cudaGetErrorString(rt_err));
return 1;
}
rt_err = cudaSetDevice(0);
if (rt_err != cudaSuccess) {
printf("cudaSetDevice(0) 失败:%s\n", cudaGetErrorString(rt_err));
return 1;
}
printf("✅ cudaSetDevice(0) 成功!运行时已绑定设备\n");
int device_count;
rt_err = cudaGetDeviceCount(&device_count);
if (rt_err != cudaSuccess) {
printf("❌ cudaGetDeviceCount 失败:%s\n", cudaGetErrorString(rt_err));
return 1;
}
printf("🎉 最终检测到 %d 个CUDA GPU!\n", device_count);
return 0;
}
#>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
#编译运行
nvcc test_cuda.cu -o test_cuda -lcuda
./test_cuda
#最终输出代表成功
✅ cuInit 成功!驱动已就绪
✅ cudaSetDevice(0) 成功!运行时已绑定设备
🎉 最终检测到 8 个CUDA GPU!conda环境测试
bash
#新建conda环境
conda create --name cuda_test python=3.10
#安装torch,自动匹配12.1cuda运行环境,系统cuda12.9向下兼容12.1
pip3 install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url
#执行测试脚本
python -c "
import torch
print('1. PyTorch 版本:', torch.__version__)
print('2. CUDA 可用:', torch.cuda.is_available()) # 需显示 True
print('3. PyTorch 绑定的 CUDA 版本:', torch.version.cuda) # 需显示 12.1
print('4. GPU 数量:', torch.cuda.device_count()) # 需显示 8(你的 H20 数量)
if torch.cuda.is_available():
print('5. 第1块 GPU 名称:', torch.cuda.get_device_name(0)) # 需显示 NVIDIA H20
else:
print('5. CUDA不可用')
"
#最终输出以下代表成功
1. PyTorch 版本: 2.3.1+cu121
2. CUDA 可用: True
3. PyTorch 绑定的 CUDA 版本: 12.1
4. GPU 数量: 8
5. 第1块 GPU 名称: NVIDIA H20总结
- CUDA12.9可向下兼容PyTorch依赖的CUDA12.1,无需额外安装低版本CUDA
- 多GPU场景下,fabricmanager版本决定驱动最高版本,必须匹配!
写到最后
