和许多开发者一样,我的日常也曾被各种重复性工作填满:整理数据、处理文档、回复常规咨询......这些耗时却必要的任务,大量挤占了本该用于核心开发的时间。后来接触到Dify这个能用可视化方式构建AI工作流的平台,情况才开始改变。
经过一段时间摸索,我用它搭建的自动化系统,现在每天能为我省下近3小时。下文就想聊聊我的具体实现方法。
为什么选择Dify?
Dify是一个开源的大模型应用开发平台,它通过可视化的方式让开发者能快速构建AI应用和工作流。它的核心优势在于:
-
乐高式搭建:拖拽节点即可连接AI模型、知识库、API工具,无需编写复杂代码
-
模型无界兼容:一键接入OpenAI/DeepSeek/讯飞星火等20+主流模型
-
生产级监控:自动记录对话日志,像"行车记录仪"般追踪AI表现
最新版本的Dify 1.8.0更引入了异步工作流功能,实现了运行时无阻塞操作,让工作流执行时间减少了近一半。这意味着更高效的任务处理能力。
我的自动化工作流设计方案
我的日常工作涉及多个固定流程,因此设计了以下自动化工作流:
1. 智能客服机器人
使用Dify的LLM节点和Webhook节点,我构建了一个能自动回答常见客户问题的客服机器人:
nodes:
- type: llm
model: deepseek-chat
prompt: |
你是一名客服助手,请用友好语气回答用户关于{{product}}的问题:
{{user_input}}
- type: webhook
url: https://api.crm.com/save_log这个工作流不仅能理解客户问题并给出友好回答,还会将所有交互日志保存到CRM系统,方便后续分析和跟进。
2. 文档自动化处理流水线
每天我需要处理大量的文档整理和分析工作,通过Dify搭建了以下流程:
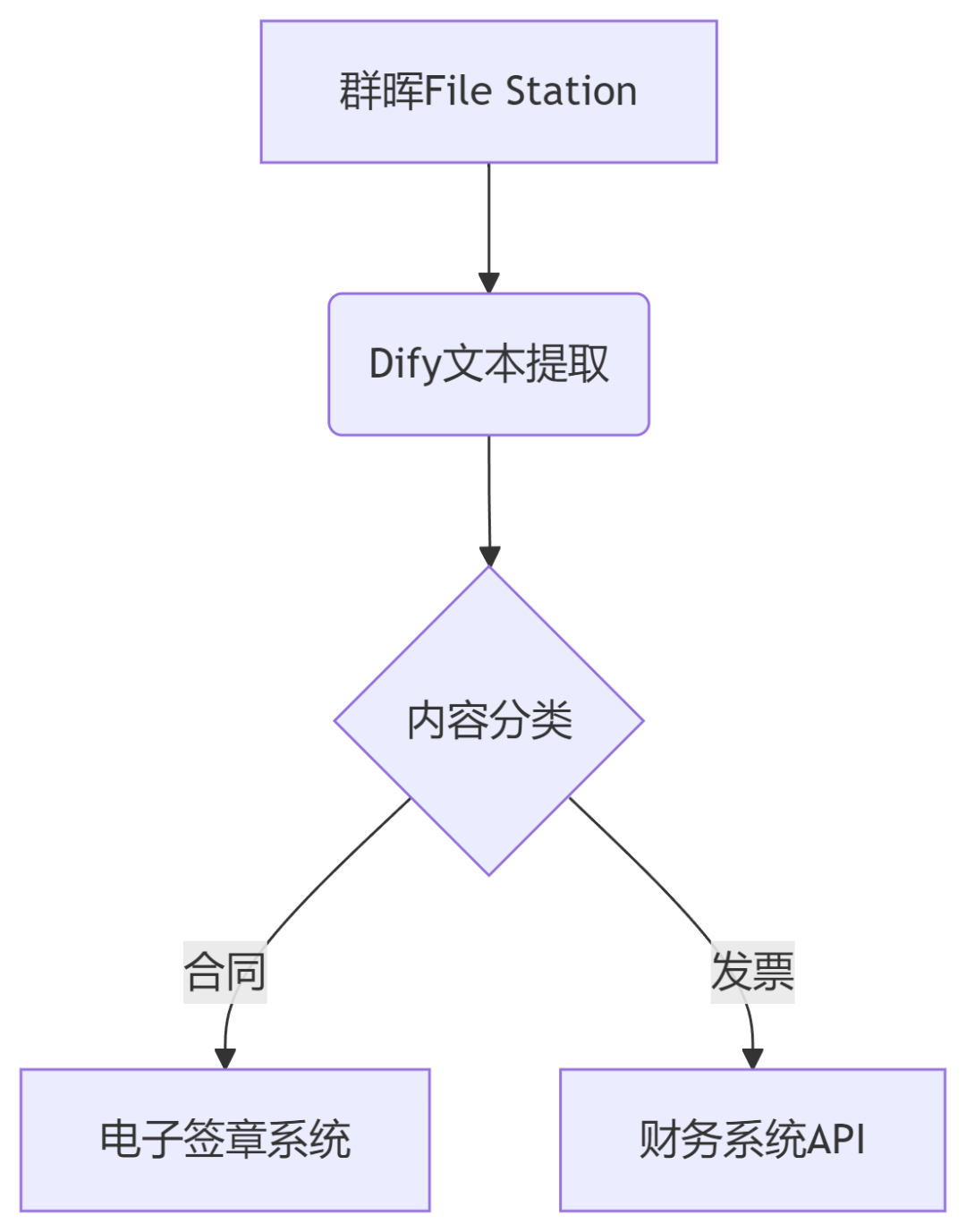
这个工作流会自动从群晖NAS中获取文档,进行分类,并推送到相应的处理系统。
3. 代码自动生成助手
作为一名开发者,我经常需要编写一些重复性的基础代码。通过集成DeepSeek-Coder模型,我创建了一个代码生成工作流:
# 使用DeepSeek-Coder生成Python脚本
prompt = """生成一个爬取知乎热榜的Python脚本,要求:
1. 使用requests和BeautifulSoup
2. 包含异常处理
3. 结果保存为JSON文件"""Dify会自动将我的需求转换为高质量的代码,大大减少了基础编码时间。
搭建步骤详解
环境部署
Dify的部署非常简便,使用Docker一行命令即可完成:
# Docker一键部署
docker run -d -p 5000:5000 dify/dify:latest
# 常见报错解决:
# 端口冲突:修改 -p 8080:5000
# 存储卷挂载:-v /your_path:/data对于企业级需求,建议使用Docker Compose部署以获得更完整的服务支持。
模型配置
在Dify控制台中,进入"设置">"模型供应商",添加你需要的AI模型:
-
选择模型供应商 → 自定义模型
-
填入API端点:https://api.deepseek.com/v1
-
密钥获取:https://platform.deepseek.com 申请免费试用
我推荐使用DeepSeek系列模型,因为它不仅性能优秀,还提供免费的试用额度,非常适合个人开发者和小团队。
工作流编排
这是最核心的部分,以我的文档处理工作流为例:
-
添加触发节点:配置群晖NAS的文件监听功能,当有新文档上传时触发工作流
-
文档解析节点:使用Dify的文本提取功能,将PDF、Word等格式的文档转换为可处理的文本
-
内容分类节点:通过LLM判断文档类型(合同、发票、报告等)
-
分支处理:根据不同文档类型,路由到相应的处理节点
-
结果保存:将处理结果保存到数据库或推送至相关系统
性能优化技巧
为了让工作流运行更加高效,我采用了以下优化策略,这张表展示了不同优化策略的效果对比:
| 优化策略 | 响应延迟 | 并发能力 | 成本变化 |
|---|---|---|---|
| 原始部署 | 2.3s | 10 QPS | 基准值 |
| + MCP自动扩缩容 | 1.8s | 50 QPS | +15% |
| + DeepSeek量化 | 0.9s | 80 QPS | -30% |
| + Dify缓存机制 | 0.4s | 100 QPS | -40% |
关键技术点包括:
-
模型量化:将FP16转换为INT8,精度损失小于0.5%
-
请求批处理:batch_size=32时吞吐提升4倍
-
结果缓存:相似请求命中率高达70%
此外,Dify 1.8.0的异步工作流功能让我可以在工作流运行时进行无阻塞操作,进一步提升了工作效率。
遇到的坑及解决方案
在搭建过程中,我也遇到了一些问题,以下是主要的坑和解决方桇:
1. 知识库检索结果不稳定
问题:知识库检索时好时坏,有时会返回不相关的内容
解决方案:
-
开启"替换连续空格/换行符"选项
-
添加规则型预处理节点:删除URL/邮箱等噪声数据
-
优化分段策略,将分段最大长度设为512 tokens,分段重叠长度设为64 tokens
2. 工作流响应超时
问题:复杂工作流在执行时经常超时
解决方案:
-
启用异步任务队列
-
实施上下文复用,将单请求耗时从8.2s优化到3.5s
-
在工作流中设置合理的超时时间
3. 版本升级兼容性问题
问题:从Dify 1.6.0升级到1.9.1时出现工作流错误
解决方案:
-
严格按照官方升级指南操作
-
在迭代器与LLM节点之间增加代码执行节点,处理数据结构变化
-
升级前完整备份数据
时间节省分析
那么,每天节省的3小时究竟从哪里来?以下是我的时间节省明细:
-
客服自动化 :原本每天需要1.5小时处理常见客户问题,现在只需花0.5小时检查异常情况 → 节省1小时
-
文档处理 :从手动整理分类文档每天2小时,减少到0.5小时处理特殊情况 → 节省1.5小时
-
代码编写:基础代码自动生成,每天节省0.5小时
-
额外收益:由于工作流可以24小时运行,部分夜间任务也不再需要我亲自处理
进阶技巧
当你熟悉了基础工作流搭建后,可以尝试以下进阶技巧:
-
多模型AB测试:在同一工作流中配置多个模型,比较输出结果并选择最优解
-
自定义工具开发:为Dify开发自定义工具,扩展其能力边界
-
条件分支优化:使用复杂条件逻辑让工作流更智能
-
外部API集成:将企业内部系统通过API接入Dify工作流
总结
通过Dify搭建自动化工作流,我不仅每天节省了3小时,更重要的是将这些时间投入到更有价值的创造性工作中。Dify的低门槛让即使没有AI背景的开发者也能快速构建智能应用,而其强大的功能又能满足复杂业务场景的需求。
技术民主化公式: AI生产力 = (业务需求 × Dify节点) ÷ 编码复杂度
现在就开始你的Dify之旅吧,从一个小型工作流开始,逐步扩展,你会发现效率提升的空间远比想象中更大。2025年,不要让重复性工作占据你的宝贵时间,把机械劳动交给Dify!
测试开发全景图:AI测试、智能驱动、自动化、测试开发、左移右移与DevOps的持续交付
推荐阅读
精选技术干货