目录
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是transformer的代码部分,通过代码帮助理解transformer。
Transformer代码部分理解
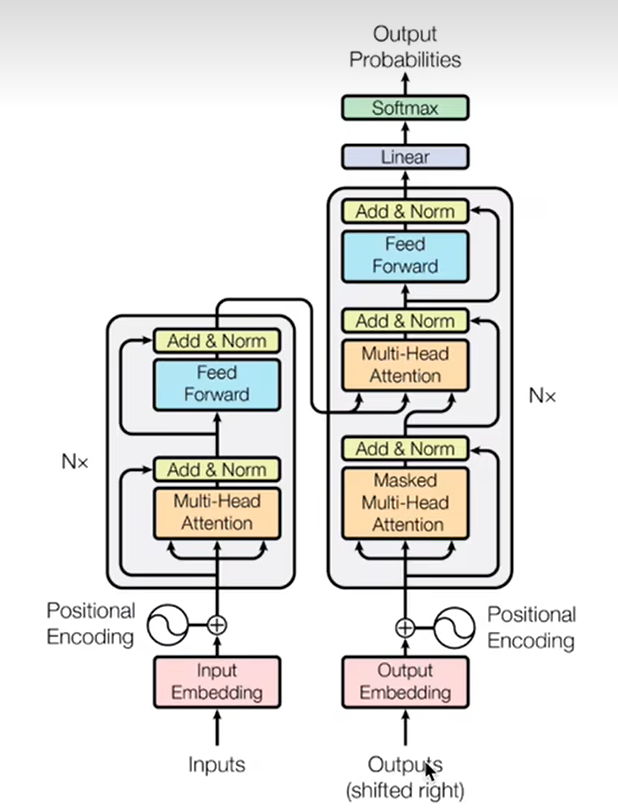
首先复习一下transformer的整体结构,如下图所示
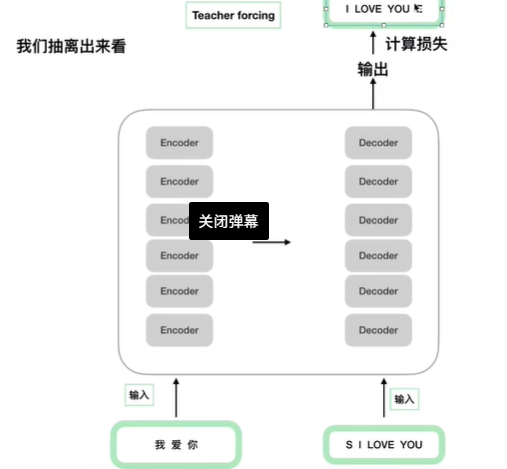
先看下面这张图左下角"我爱你"为encoder的输入,右下角的"S I LOVE YOU"为decoder的输入,
右上角的"I LOVE YOU E"为真实的标签(答案)。用于计算decoder输出的损失。
下图的代码部分与上图对应起来

就是这样
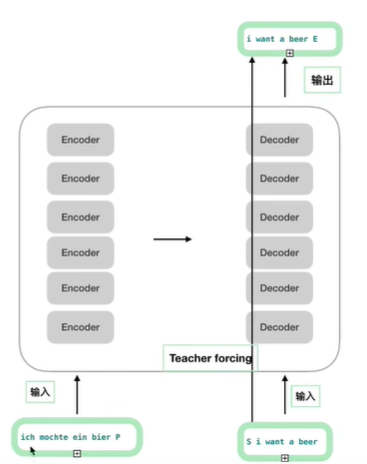
其中的特殊字符"S"表示开始信号,"E"表示END信号,"P"为填充字符,即不足最大长度的部分用"P"填充。参考下图的例子。
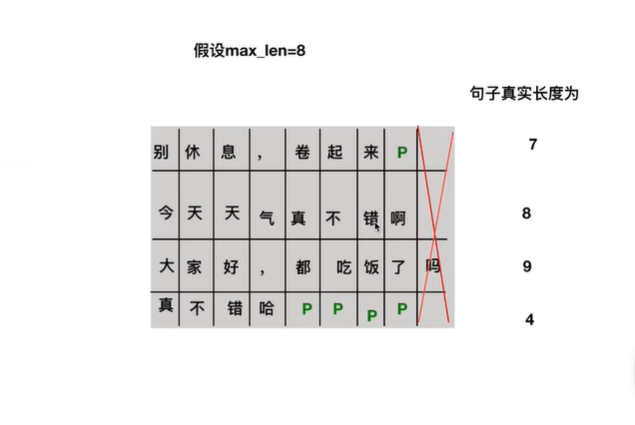
模型的相关参数如下,512为字符转换为embedding的大小,前馈神经网络映射维度为2048,K,V维度为64,encoder和decoder的个数,multi-head的head数为8。

encoder部分代码

src_emb对应词表功能
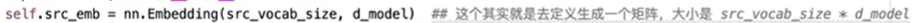
通过词表将字符转化为向量

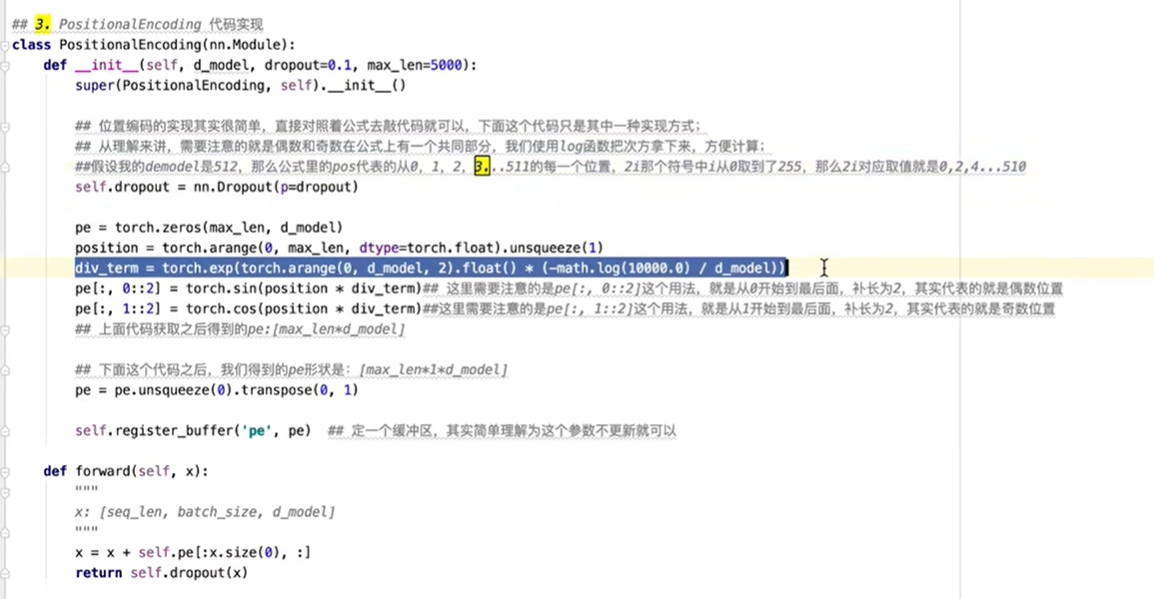
对于位置编码,基本公式如下图,对奇数偶数的位置不同也有不同的公式,pos为位置,例如维度为512时,pos为0-511之中的一个数。

位置编码对应实现代码如下图,div_term实现的是公式中共有的部分。最后的forward部分对应词向量与位置编码相加。
需要注意的是,下图的函数获取pad字符的位置。

为什么需要知道pad字符的位置?在下图的例子中,这个图可理解为两个字之间的相似性,pad符号原本是句子不存在的,所有在计算分数时应该去掉pad。
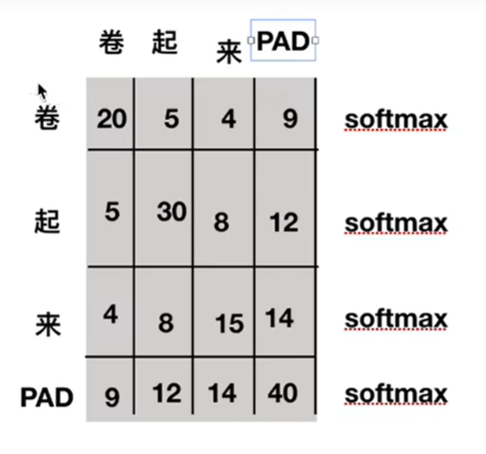
如何获取位置?使用一个符号矩阵,1表示为pad字符。
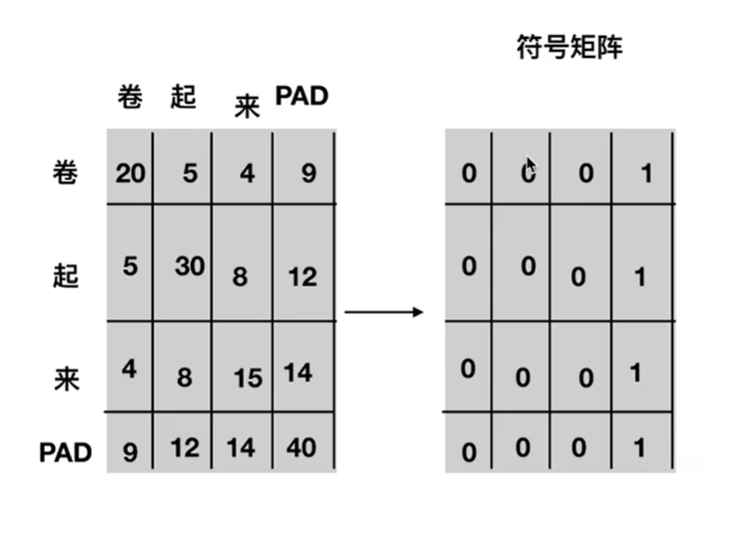
具体实现代码如下

实现encoder的具体函数,一个实现前馈神经网络,一个实现多头自注意力层。

多头自注意力层如下,其中Q,K矩阵维度相同。
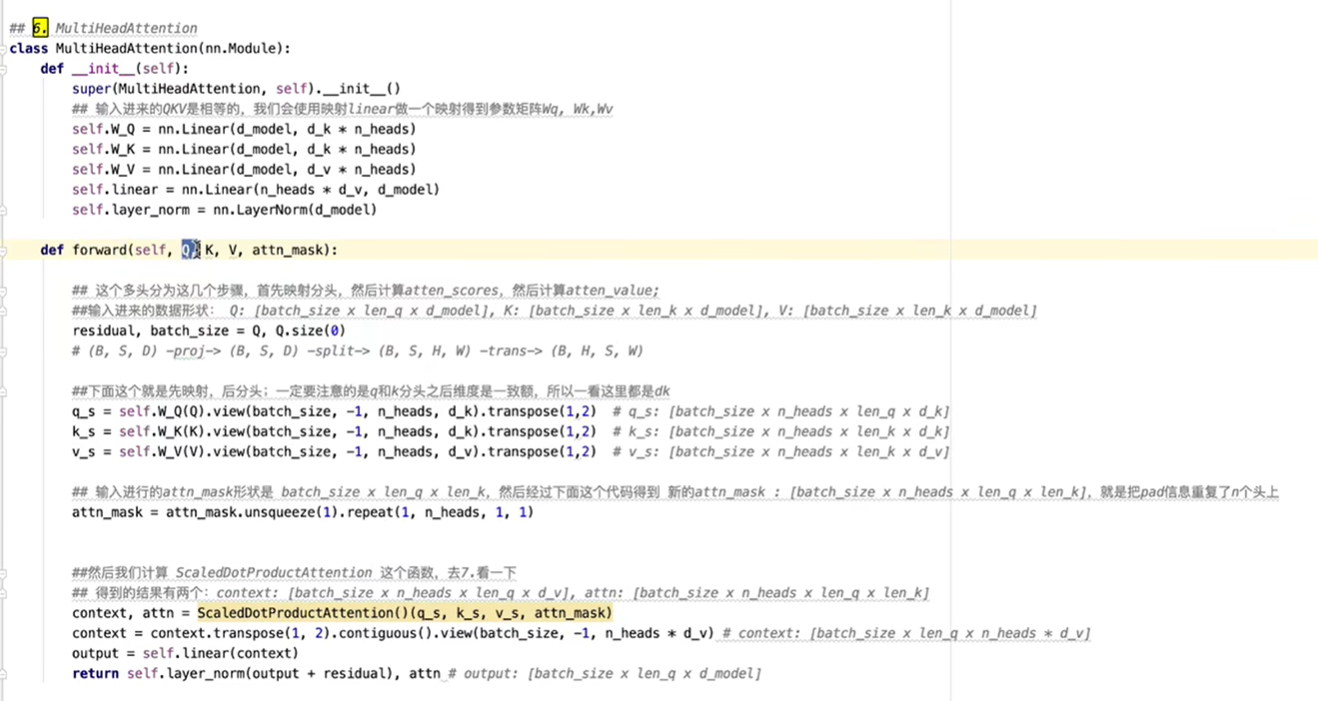
decoder部分代码,decoder与encoder类似。

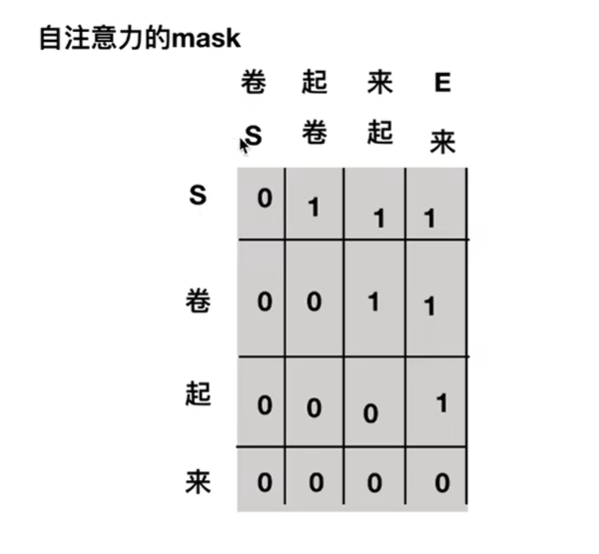
差别的地方在自注意力层的masked,实现时其实就是一个上三角矩阵,为1时就表示为pad,即被去除,所以在输入S时,只能看见S看不到"卷",在输入S和"卷"时,只能看见S和"卷"看不到"起"。