拉链表
拉链表的实现
sql
--拉链表:
show databases ;
drop database bigdata2;
create database bigdata2;
use bigdata2;
show tables ;
--设置本地模式:
set hive.exec.mode.local.auto=true;
--拉链表:
drop table if exists bigdata2.dw_zipper;
create table bigdata2.dw_zipper(
userid string,
phone string,
nick string,
gender string,
addr string,
starttime string,
endtime string
)row format delimited fields terminated by '\t';
load data local inpath '/opt/hivedatas/zipper.txt' into table bigdata2.dw_zipper;--加载本地文件中的数据到表中
select * from bigdata2.dw_zipper limit 5;
--增量表:
drop table if exists bigdata2.dw_update;
create table bigdata2.dw_update(
userid string,
phone string,
nick string,
gender string,
addr string,
starttime string,
endtime string
)row format delimited fields terminated by '\t';
load data local inpath '/opt/hivedatas/update.txt' into table bigdata2.dw_update;
select * from bigdata2.dw_update limit 5;
--临时表
drop table bigdata2.tmp_zipper;
create table bigdata2.tmp_zipper(
userid string,
phone string,
nick string,
gender string,
addr string,
starttime string,
endtime string
)row format delimited fields terminated by '\t';
--合并拉链表和增量表中的数据,放入临时表
insert overwrite table tmp_zipper
select userid,phone,nick,gender,addr,starttime,endtime from dw_update
union all
select a.userid,a.phone,a.nick,a.gender,a.addr,a.starttime,
--如果用户的id是空或者结束时间小于9999,就显示9999否则就让增量表中数据开始时间减一天,显示在历史数据上
if(b.userid is null or a.endtime < '9999-12-31',a.endtime,date_sub(b.starttime,1)) endtime
from dw_zipper a left join dw_update b on a.userid = b.userid;
--查询临时表数据:
select * from bigdata2.tmp_zipper;
--更新数据到拉链表:
insert overwrite table bigdata2.dw_zipper
select userid,phone,nick,gender,addr,starttime,endtime
from bigdata2.tmp_zipper order by userid;
--查询拉链表:
select * from bigdata2.dw_zipper;1、数据同步问题
在实现数据仓库数据同步的过程中,我们必须保证Hive中的数据与MySQL中的数据是一致的,这样才能确保我们最终分析出来的结果是准确的,没有问题的,但是在实现同步的过程中,这里会面临一个问题:如果MySQL中的数据发生了修改,Hive中如何存储被修改的数据?
例如以下情况
2021-01-01:MySQL中有10条用户信息
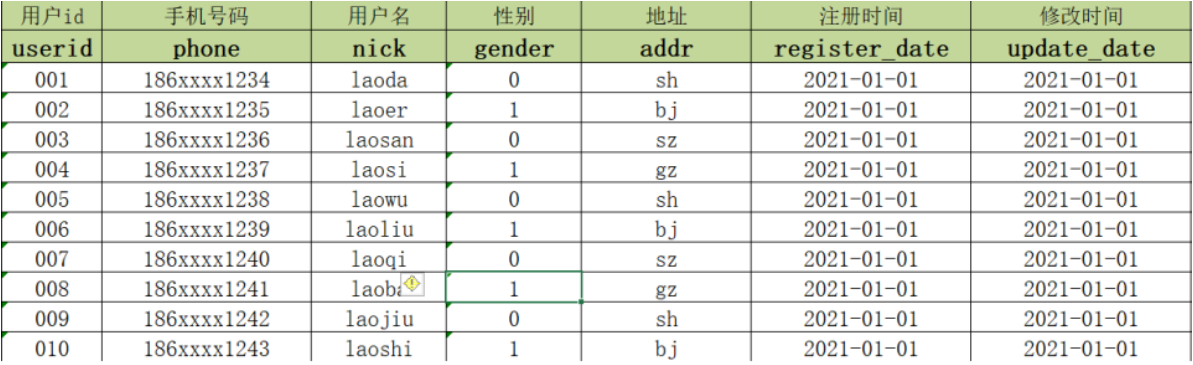
2021-01-02:Hive进行数据分析,将MySQL中的数据同步
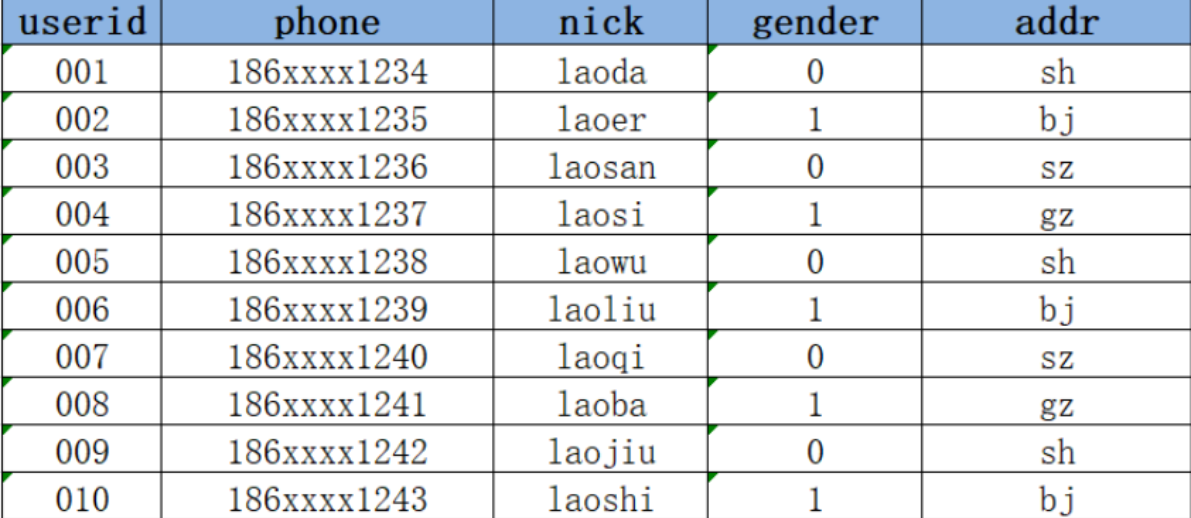
2021-01-02:MySQL中新增2条用户注册数据,并且有1条用户数据发生更新
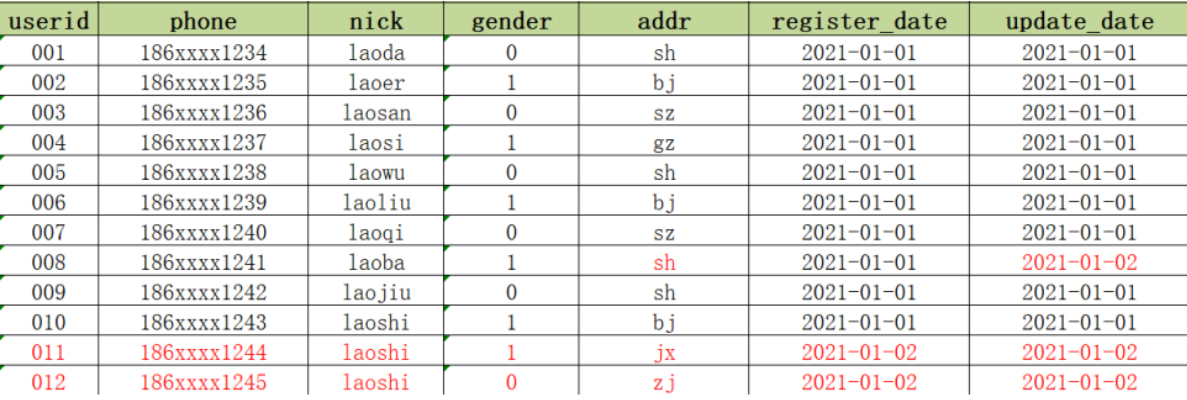
2021-01-03:Hive需要对2号的数据进行同步更新处理
问题:新增的数据会直接加载到Hive表中,但是更新的数据如何存储在Hive表中?
2、解决方案
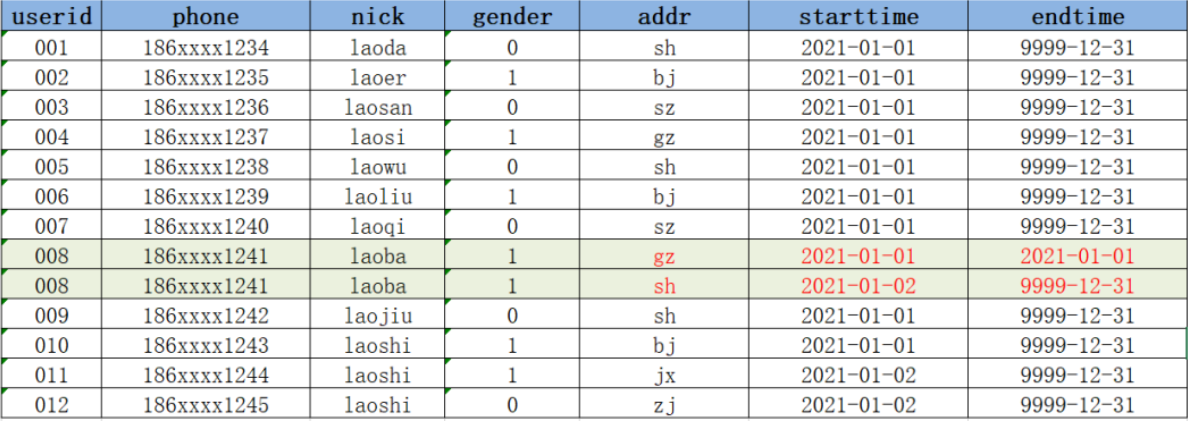
方案一 :在Hive中用新的addr覆盖008的老的addr,直接更新
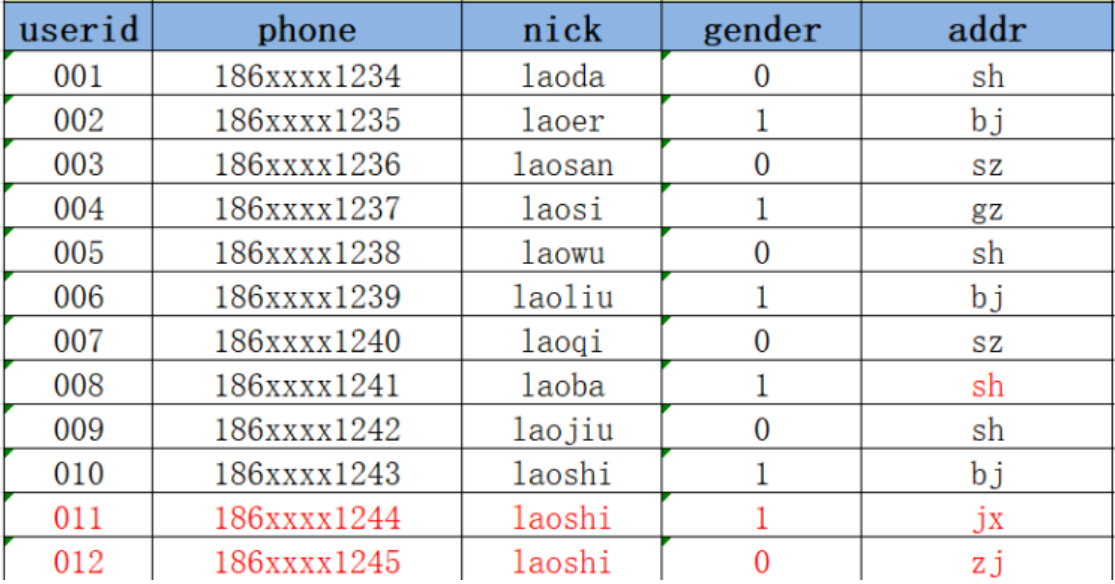
优点 :实现最简单,使用起来最方便
缺点:没有历史状态,008的地址是1月2号在sh,但是1月2号之前是在gz的,如果要查询008的1月2号之前的addr就无法查询,也不能使用sh代替
方案二 :每次数据改变,根据日期构建一份全量的快照表,每天一张表
优点 :记录了所有数据在不同时间的状态
缺点:冗余存储了很多没有发生变化的数据,导致存储的数据量过大
方案三 :构建拉链表,通过时间标记发生变化的数据的每种状态的时间周期
3、拉链表的设计与实现
3.1 功能与应用场景
拉链表专门用于解决在数据仓库中数据发生变化如何实现数据存储的问题,如果直接覆盖历史状态,会导致无法查询历史状态,如果将所有数据单独切片存储,会导致存储大量非更新数据的问题。拉链表的设计是将更新的数据进行状态记录,没有发生更新的数据不进行状态
存储,用于存储所有数据在不同时间上的所有状态,通过时间进行标记每个状态的生命周期,查询时,根据需求可以获取指定时间范围状
态的数据,默认用9999-12-31等最大值来表示最新状态。
3.2 实现过程
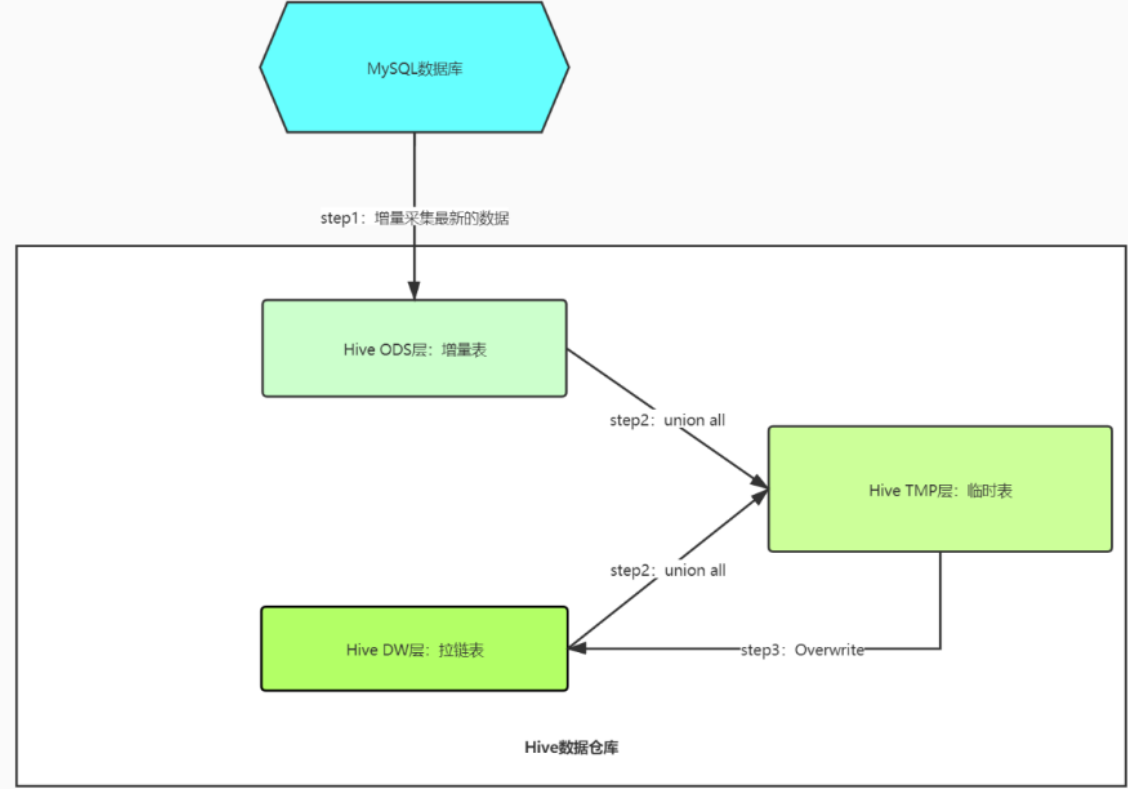
整体实现过程一般分为三步,第一步先增量采集所有新增数据【增加的数据和发生变化的数据】放入一张增量表。第二步创建一张临时表,用于将老的拉链表与增量表进行合并。第三步,最后将临时表的数据覆盖写入拉链表中。例如:
3.3 拉链表的实现
sql
--拉链表
--创建拉链表
create table dw_zipper(
userid string,
phone string,
nick string,
gender string,
addr string,
starttime string,
endtime string
)row format delimited fields terminated by '\t';